Efficace et pas cher, c’est le SAST que je préfère !
Dans le domaine des outils de sécurité applicative, notamment depuis l’arrivée du "shift security left" et du DevOps, plusieurs acronymes reviennent régulièrement :
- SAST (Static Application Security Testing) ;
- DAST (Dynamic Application Security Testing) ;
- RASP (Run-time Application Security Protection) ;
- ou encore SCA (Software Composition Analysis).
Parmi ces outils, certains s’exécutent directement sur le code source (SAST, SCA), tandis que d’autres nécessitent qu'il soit exécuté (DAST) ou même de s’intégrer au code de l’application (RASP).
Nous allons nous intéresser tout particulièrement au SAST. Si parmi ces outils, le SAST est le plus souvent cité et utilisé, c’est parce qu’il arrive en premier dans le cycle de développement, mais aussi parce qu’en apparence il est le plus simple à utiliser. S’il existe de nombreuses solutions propriétaires et payantes, et souvent lourdes, telles que Checkmarx, il en existe bon nombre open source, clés en mains et avec un temps d’exécution raisonnable (<5 min). Il est donc aujourd’hui facile de mettre en place un de ces outils sans effort (par exemple GitLab SAST, GitHub LGTM, etc.) pour se sentir en sécurité mais cela peut s’avérer trompeur et contre-productif.
Nous allons voir dans cet article à quoi sert vraiment un SAST et comment tirer partie au maximum de ses possibilités sans tomber dans les pièges les plus communs.
Pourquoi utiliser un SAST ?
L’objectif d’un outil de type SAST est d’éviter les erreurs de développement qui peuvent engendrer des failles de sécurité dans le code. Avec les concepts de défense en profondeur, qui poussent à ne plus se contenter d’une sécurité périmétrique, et de "shift security left", qui pousse à mettre en place de la sécurité au plus tôt, ce genre d’outils est aujourd’hui indispensable.
Il nous permet d’automatiser des contrôles pertinents et ainsi d’avoir des revues de code plus efficaces, en consacrant davantage de temps en revue à la détection de choses plus fines.
Ces outils sont généralement adaptés aux développeur.euse.s en mettant en avant la portion du code qui semble représenter un problème ainsi qu'une aide sur la correction à apporter au code. Ils sont configurables pour être lancés dans votre intégration continue ou de manière automatique (toutes les nuits par exemple).
On peut citer parmi ces outils find-sec-bugs (Java), bandit (Python), brakeman (Ruby), ESLint security plugin (Javascript), MobSF (Android), checkov (Infra as Code) ou encore Semgrep (multi langages).
Nous allons prendre tout au long de cet article l’exemple de Semgrep.
![]()
Quelles vulnérabilités rechercher ?
Faisons un pas de côté tout d’abord pour introduire ce que nous appelons la Secure Coding Policy. C’est le document qui formalise l’ensemble des bonnes pratiques de sécurité à respecter au quotidien dans votre code. Dans notre contexte, cela va correspondre à la sélection des règles à respecter.
Ce document peut prendre plusieurs formes (wiki, ADR, etc.) et va rassembler les choix techniques pour sécuriser l’application ; mais aussi les compromis nécessaires (sécurité / faisabilité / performance / compatibilité).
Elle doit être :
- adaptée à votre contexte ;
- partagée et acceptée par tous les membres de l'équipe ;
- revue régulièrement.
Le SAST va donc prendre le rôle d’un contrôle de conformité par rapport aux règles définies dans la Secure Coding Policy.
La gestion des règles dans les SAST est possible selon deux stratégies non exclusives : les règles déjà configurées et les règles personnalisées. Commençons par évoquer les règles “génériques”.
Les kits de règles déjà configurés
La plupart des outils présentent l’avantage d’avoir des règles déjà écrites pour permettre un usage rapide de l’outil sans configuration supplémentaire.
Dans le cadre de Semgrep, l’outil nous propose un ensemble de règles préparées pour une intégration continue que nous pouvons lancer avec la commande “magique” suivante :
semgrep --config p/ci

"Le tour est joué, mon code est sécurisé ! 🥳"
Bien que cela réduise le temps nécessaire à lancer l’outil et que les règles soient en général pertinentes, cette approche a ses limites et peut même s’avérer contre-productive.
Les règles étant génériques, elles peuvent s’avérer ne pas être adaptées à votre contexte et au mieux être inutiles, au pire générer des faux positifs. Dans le premier cas, vous allez avoir un faux sentiment de sécurité. Dans le second, votre équipe va passer du temps (non négligeable) soit à ignorer les règles soit à essayer de les respecter. Les sets prédéfinis comprennent souvent de très nombreuses règles, ce qui va rendre le processus difficile à gérer pour une équipe avec une maturité faible sur les sujets de sécurité. Tout cela entraînant du stress si les problèmes arrivent à des moments peu opportuns (avant une mise en production importante par exemple).
Si vous mettez en place un SAST en mode générique sans en maîtriser les règles, c’est mieux que rien, mais ce sera globalement assez peu efficace.
En conclusion, nous recommandons l’approche suivante : en début de projet sélectionner les règles auxquelles vous voulez vous conformer afin de maîtriser ces règles. Si elles n’existent pas dans votre outil, prenez le temps de les écrire (et capitalisez !).
Les règles personnalisées
Il est effectivement possible avec certains outils SAST d’écrire ses propres règles de détection. Cela est généralement assez laborieux (prise en main de l’outil et de son moteur de règles) mais peut s’avérer pertinent.
Au-delà du fait de sélectionner les règles que l’on veut contrôler, les écrire directement permet de limiter les contrôles à ce que l’on recherche. Ainsi, la recherche est plus rapide et on élimine la quasi-totalité des faux positifs.
Avec Semgrep, les règles s’écrivent en YAML. Il suffit ensuite de préciser le répertoire où se trouvent vos règles à Semgrep via l’option --config et le tour est joué !
Un exemple de règle simple pour interdire l’usage de requêtes SQL dans une application Javascript, afin de s’assurer que l’on utilise uniquement l’ORM pour nos requêtes en base :
rules: - id: sequelize-query patterns: - pattern: db.sequelize.query(...) severity: ERROR message: | query should not be used. languages: - javascript
Semgrep propose des pages pédagogiques pour apprendre à écrire ses règles ainsi qu’une page dédiée pour écrire et tester ses nouvelles règles.
Attention donc à bien vérifier si l’outil vers lequel vous vous orientez permet ou non de le faire et si vous maitrisez le langage utilisé.
En règle générale, nous recommandons de ne s’engager dans l'écriture de règles que si vous ne trouvez pas de règle pré-écrite qui correspond à votre Secure Coding Policy (ou si la règle est trop générique). Une fois écrites, pensez dans la mesure du possible à partager vos règles, que ce soit au sein de votre environnement de travail ou même à la communauté en open source.
Intégration dans le cycle de développement
Comme dit précédemment, et comme pour la plupart des outils d’analyse de code, il est recommandé d'initier sa mise en place dès le début du projet. Ainsi cela évitera d’avoir à traiter un nombre important de retours au moment de la mise en place de l’outil, et potentiellement de retarder la mise en application des correctifs à cause du stress, de la pression, etc. Le contexte technique évoluant, il sera cependant nécessaire de mettre à jour régulièrement vos règles de détection.
L’idéal est d’intégrer l’outil dans la pipeline de développement, pour qu’il soit exécuté par exemple à chaque commit ou au moins avant chaque merge. Cependant, cela implique que l’exécution de l’outil soit rapide (< 3 minutes) afin de ne pas trop augmenter la boucle de feedbacks côté développement (il est en général possible de paralléliser).
Pour reprendre notre fil rouge, Semgrep propose l’intégration suivante dans une CI (ici GitLab CI/CD) :
--- semgrep: stage: analysis image: returntocorp/semgrep-agent:v1 script: semgrep-agent variables: SEMGREP_RULES: >- p/security-audit p/secrets
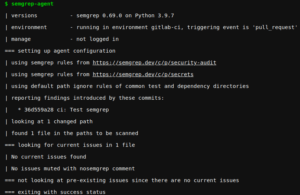
Cette intégration a l’avantage d’être clé en main et de ne s’exécuter que sur les lignes de code modifiées, pour améliorer la sécurité de son code petit à petit. C’est aussi idéal quand l’outil est mis en place au tout début du projet.
Dans le cas où l’outil serait lent, on pourra toujours planifier son exécution (une fois par jour / par semaine) mais le risque ici est une perte du suivi par l’équipe responsable du développement.
Enfin, il est possible avec certains outils propriétaires d’arriver dans une situation où tout le monde ne pourrait pas lancer l’outil, faute de licence. Cela va à l’encontre de tous les principes présentés précédemment, c’est donc à éviter. Privilégiez les outils open source, autant pour la confiance dans l’outil que pour la question des licences.
Est-ce que le SAST est suffisant en soi ?
Parmi les différents types d'outils présentés au début de l’article, deux d’entre eux nous semblent indispensables à mettre en place sur tous vos projets de développement. Le SAST tout d’abord, afin d’éviter les erreurs et de s’assurer que l’on suive l’ensemble des pratiques de sécurité définies par l’équipe dans le cadre du projet.
Ensuite, nous considérons que la mise en place d’un outil de type SCA est nécessaire pour conserver une maîtrise sur ses dépendances logicielles et leur niveau de sécurité. Parmi ces outils, nous pouvons citer : audit-ci (Javascript), DependencyCheck (Java), ou bien Trivy (Docker).
De par le coût élevé de leur mise en place ainsi que le résultat non garanti (à moins de bien maîtriser à la fois l’outil utilisé et le contexte de l’application ciblée), nous ne recommandons pas forcément l’utilisation d’un outil de type DAST, sauf si vous avez une maturité importante sur les sujets de sécurité.
Conclusion
En début de projet :
- commencez à rédiger votre Secure Coding Policy, la déclinaison sécurité de vos standards d’équipe ;
- choisissez un SAST pour s’assurer de l’application de ces règles ;
- mettez en place un SCA.
Si vous ne pouvez vraiment pas passer par l’étape Secure Coding Policy, vous pouvez toujours mettre en place un SAST avec l’ensemble des règles génériques en plus de votre SCA, mais vous risquez de perdre plus de temps sur le long terme.
Enfin, pour choisir votre outil SAST, l’OWASP recommande de s’attarder sur les critères suivants :
- L’adaptabilité au(x) langage(s) et framework(s) que vous utilisez
- La couverture de l’OWASP top 10
- Le taux de faux positifs et faux négatifs
- L’intégration à l’IDE
- La facilité de configuration et d’utilisation
- La possibilité à l’intégrer dans votre CI
- Les conditions d’utilisation (licence)