Edge Computing : apprenez à déléguer
Alors que l'intérêt pour l'Internet des Objets par les entreprises n'est plus à prouver, ce domaine continue de donner du fil à retordre aux experts, quant à la sécurité et l’architecture. En effet, la multiplication des sources de données amène une réflexion sur l'architecture des réseaux. A ce titre, voici ce que disait Satya Nadella (Directeur Général de Microsoft) sur scène en début d’année : "Quand j'ai rejoint Microsoft en 1992, la totalité du trafic sur Internet était de 100 gigabytes par jour. Aujourd'hui, c'est 17,5 millions de fois ce montant... par seconde!” et nous ne sommes qu’au début de cette augmentation exponentielle. C'est ainsi que naissent les débats sur l'intérêt de mettre en place une architecture où la donnée sera plutôt exploitée sur le Cloud (ou plus généralement de manière centralisée) ou au plus proche des nœuds terminaux du réseau.
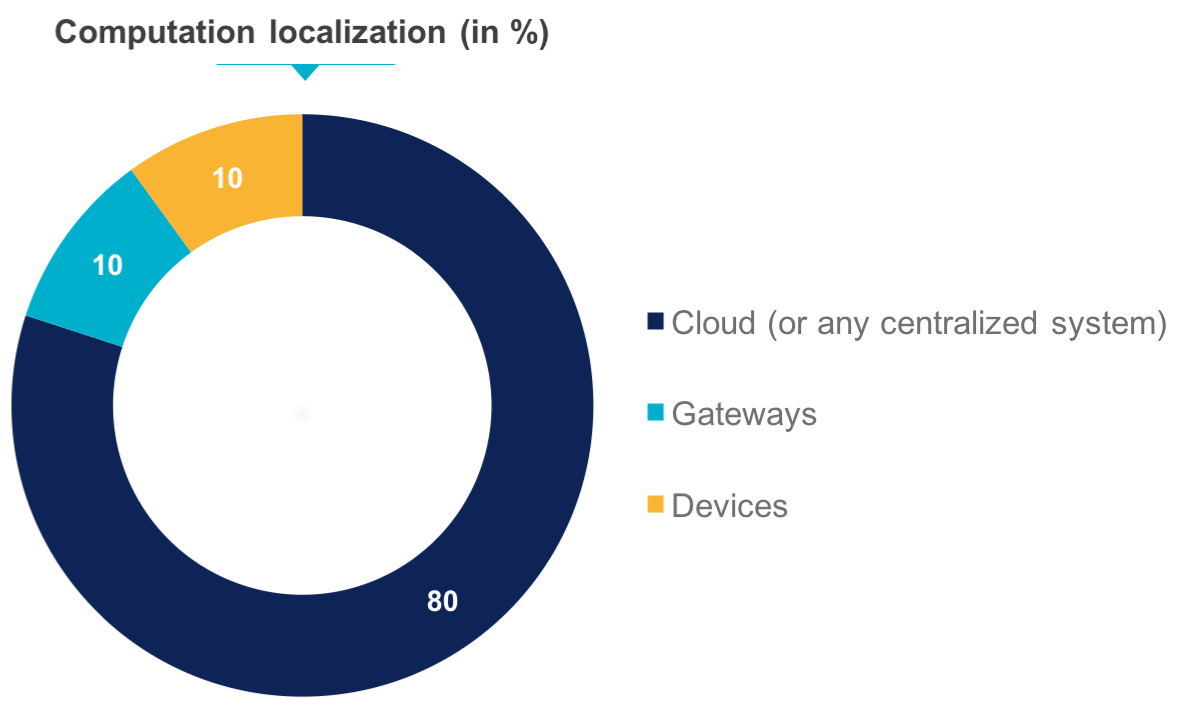
Dans une architecture Cloud Centric, on exploite au maximum les capacités de calcul des machines virtuelles distantes pour fournir à l'utilisateur final de nouveaux services. Cependant, lorsque les sources de données commencent à devenir extrêmement nombreuses (appareils IoT, smartphones, applications tierces, …) le réseau à tendance à se congestionner et la faible latence exigée des applications IoT ne sera plus respectée.
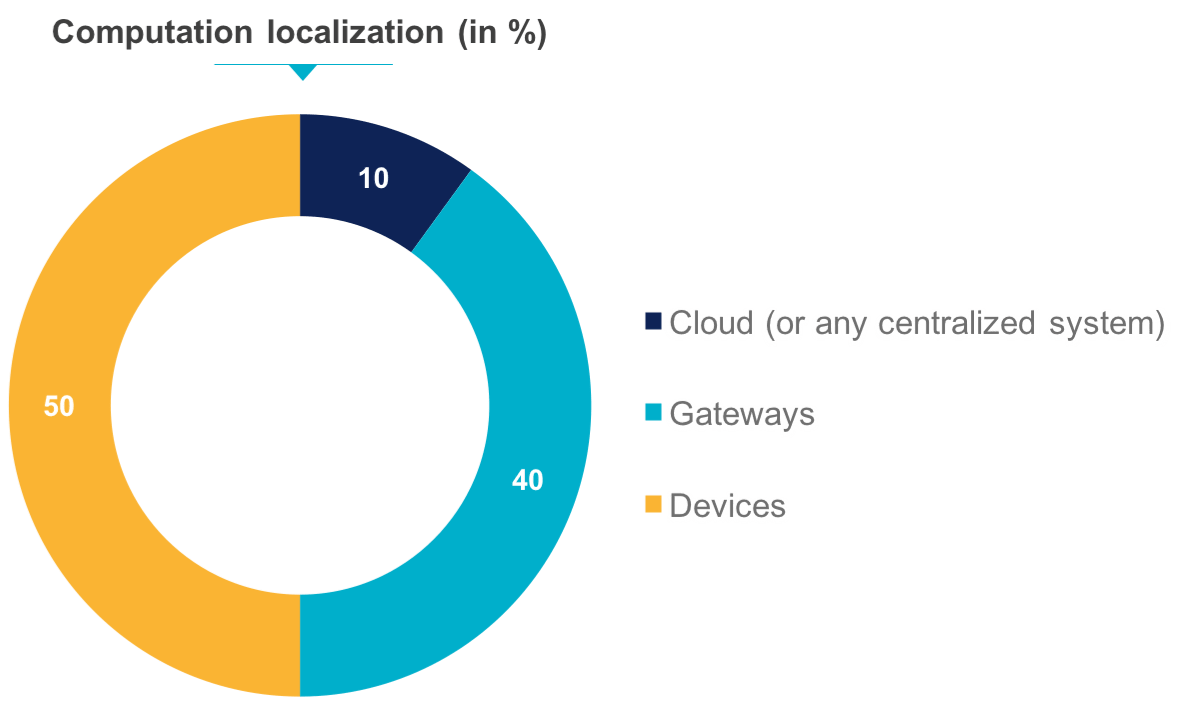
On observe donc l'émergence de l'Edge computing. D’après HPE, Edge Computing est une pratique consistant à traiter les données à proximité de la périphérie de votre réseau, là où les données sont générées, et non dans un entrepôt de traitement de données centralisé. On peut alors se demander si le Cloud et son énorme puissance de calcul est amené à disparaître au profit de serveurs plus légers qui n'auront qu'à redistribuer les données aux utilisateurs finaux.
Prenons deux exemples suffisamment parlants pour mettre en évidence les différences de ces architectures :
- Des appareils situés sur tous les lampadaires de la ville de New York (~250 000). Imaginons que ces appareils soient équipés d'un capteur de luminosité et d'un capteur de mouvement.
- Des caméras de surveillance 4K dans une ville comme Londres (~500 000). Imaginons alors que nous voudrions stocker le flux vidéo uniquement lorsque la caméra détecte un mouvement. Nous souhaiterions aussi que lorsque la caméra reconnaît le visage d'une personne recherchée par la police, une alerte soit levée pour permettre de géolocaliser la personne.
N.B. : Oui, il semblerait qu'il y ait deux fois plus de caméras à Londres que de lampadaires à New York …
Les architectures
L'architecture centralisée dans le Cloud (Cloud Centric Architecture / One to many)
Dans cette architecture, tous les nœuds du réseau vont parler en direct et à intervalle régulier avec le nœud central situé dans le Cloud.
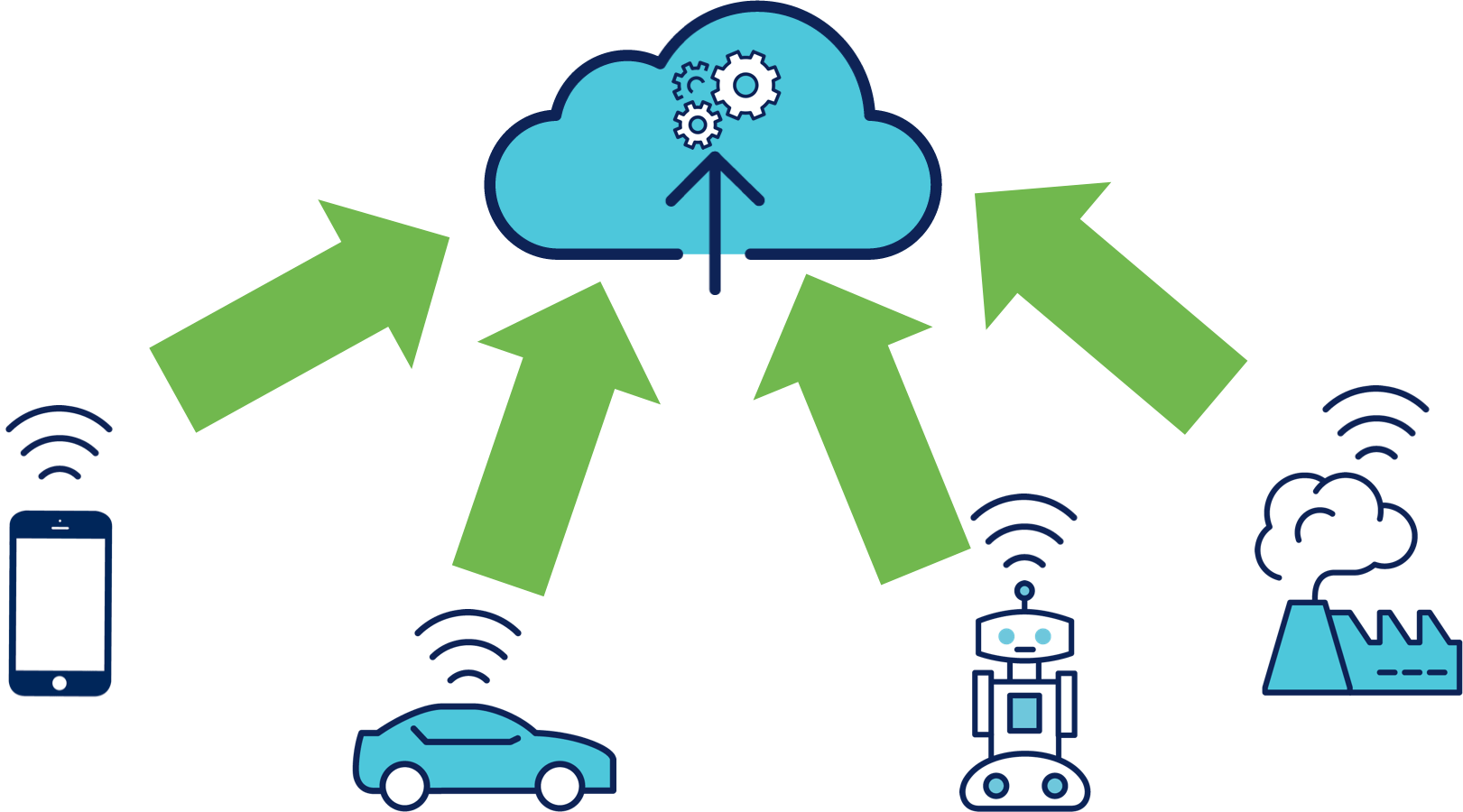
Dans le premier exemple, les lampadaires vont transmettre au Cloud, toutes les secondes, la luminosité ambiante et s'ils ont remarqué un mouvement. Le Cloud pourra alors par exemple extraire de la donnée brute de chaque lampadaire, la valeur de la luminosité. Enfin, en comparant cette données aux seuils qu'il connaît, il peut transmettre aux lampadaires concernés la commande d'allumage. Cependant, la force du Cloud réside dans le fait qu'il est assez simple d'aller plus loin.
Disons que la mairie de New York se rende compte qu’'allumer les lampadaires (même à LED) quand la luminosité ambiante diminue n'est pas suffisant pour faire des économies d'énergie. Etant donné que les appareils situés sur les lampadaires possèdent des capteurs de mouvement, il suffit d'extraire de la donnée brute le signal de mouvement pour n'allumer les lampadaires que lorsqu'un mouvement a été détecté.
Cela évite alors d'allumer une zone où il n'y a personne. Cette amélioration est assez simple à implémenter car la donnée de mouvement est déjà envoyée vers le Cloud qui n'a qu'à l'extraire et l'exploiter.
En revanche, vu le nombre d'appareils et d'évènements (250 000/s), il est assez difficile à croire que la commande d'allumage résultant du traitement de chacune de ces données brutes soit instantanée. Durant un un court laps de temps, la donnée brute de chaque appareil doit parcourir le réseau, être filtrée, stockée et analysée, puis une commande d'allumage doit ou non être envoyée. A cette échelle, il y aura forcément une latence non négligeable.
Dans le deuxième exemple, le flux vidéo 4K de 500 000 caméras de surveillance doit être envoyé en continu vers le Cloud. On se rend bien compte que ni le réseau ni l'infrastructure ne pourront supporter cette charge. En pratique, on utilise des passerelles qui vont servir de tampons et qui vont ensuite à leur tour transmettre les données qu'elles ont stockées. Une fois les données arrivées sur le Cloud, elles pourront être analysées finement pour permettre de déterminer pour chaque caméra si un mouvement a été détecté. Le cas échéant, il reste à enregistrer le flux ainsi que déterminer si une personne recherchée par la police a été détectée et transmettre sa position.
Le Cloud est donc capable de réaliser un traitement assez complexe sur des données volumineuses et si par hasard, la mairie de Londres ne souhaitait plus se baser sur un mouvement détecté dans l'image pour enregistrer le flux mais sur des horaires, ce changement serait assez simple à implémenter.
Dans ce cas, il est encore plus évident que la latence sera extrêmement importante vis-à-vis du temps de parcours de la donnée puis de son traitement qui sera le résultat d'algorithmes assez complexes (Computer Vision, Machine Learning…).
L'architecture distribuée (Edge computing)
Ici, le Cloud ne reçoit que les résultats des étapes de calculs réalisés par les extrémités du réseau et peut à son tour réaliser d'autres calculs ou simplement servir de relai vers les utilisateurs finaux. Déléguer du travail aux appareils en périphérie du réseau permet de diminuer la taille des données à envoyer et donc de désengorger les canaux de communication pour diminuer la latence. Cela contribue aussi à réduire la charge sur le serveur. Le travail d'un device maker est de trouver l'équilibre entre la durée de la batterie, la puissance de calcul de l'appareil et les communications. Aujourd'hui, nous sommes capables de doter les appareils de plus en plus de puissance de calcul car ces composants sont de moins en moins consommateurs en énergie et les prix deviennent abordables.
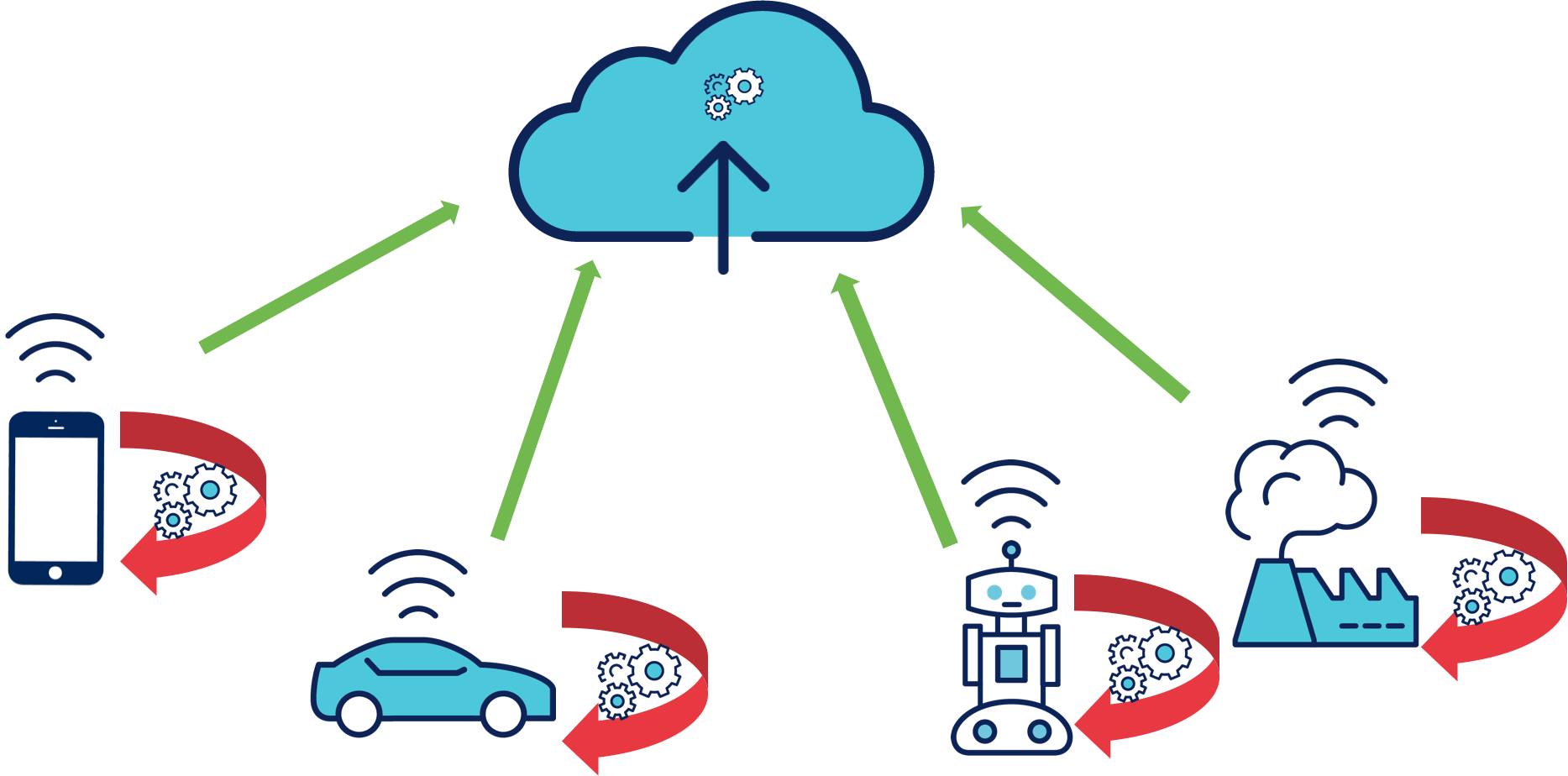
Dans le premier exemple, les lampadaires pourraient par exemple stocker localement les seuils de luminosité à partir desquels ils décideraient eux-même de s'allumer ou s'éteindre. On voit donc ici une première contrainte de l'architecture Edge computing. En effet, imaginons que pour une raison ou une autre, nous souhaitions changer les seuils de luminosité. La solution consiste à mettre en place un système de gestion des appareils centralisé avec une possibilité d'envoyer des données vers les appareils. Ce système doit alors se situer dans le Cloud et pourraient aussi permettre de configurer des seuils différents pour chaque lampadaire si on le désire. Le traitement n’est plus effectué à distance, mais localement. Seule la configuration et les règles métier sont déployées périodiquement depuis le Cloud.
Allons un peu plus loin. On peut décider de déléguer la détection de mouvement à l'appareil situé sur le lampadaire qui pourrait alors décider seul de l'allumer ou de s'éteindre et qui n'aura plus qu'à transmettre son état (seulement lorsqu'il change) au système de gestion centralisé. Cela ajoute une contrainte de sécurité supplémentaire. Dans l'architecture centrée sur le Cloud, l'appareil envoie régulièrement des données brutes (potentiellement chiffrées) qui sont ensuite analysées avant que des commandes ne redescendent au travers de communications sécurisées. Si l'appareil est corrompu, il cessera alors simplement de recevoir ses commandes et deviendra inutilisable. Une simple intervention permettra ensuite de le remettre dans son état de fonctionnement normal. Dans le cas où l'appareil possède des capacités de calcul, décide lui-même lorsqu'il s'allume ou non et n'envoie que son état lorsqu'il change, s'il est corrompu, l'attaquant pourra alors décider de lui implémenter un comportement totalement différent sans que cela soit remarqué par le système de gestion centralisé. Bien entendu, lorsque le seul matériel à disposition est une LED à allumer ou éteindre les conséquences d'une attaque ne sont pas dramatiques mais passons à notre deuxième exemple.
Les caméras de la ville de Londres peuvent, dans cette architecture distribuée, détecter elles-mêmes un mouvement dans leur champ de vision et démarrer la transmission vers le Cloud qui pourra automatiquement enregistrer le flux. Elles peuvent aussi faire de la reconnaissance de visage dans l'image et ainsi remonter une alerte automatiquement lorsqu'un visage correspond à celui d'un individu qu'elles ont en mémoire. On se rend donc compte ici de l'intérêt de ce genre d'architecture car les caméras ne sont alors plus obligées de streamer du contenu 4K en continu mais seulement ponctuellement. Le Cloud n'est même plus obligé de traiter l'image pour reconnaître quelqu'un car les caméras s'en chargent. Cependant, c'est ici que la notion de sécurité prend toute son importance. Si une caméra qui ne fait que transmettre son flux vidéo en continu est corrompu, l'attaquant n'aura alors accès "qu'à" ce flux qu'il pourra lui-même exploiter. Dans le cas où la caméra est plus autonome, sa prise de contrôle pourrait permettre de supprimer un visage de la base, d'en rajouter d'autres, de ne pas permettre au Cloud de détecter son dysfonctionnement car elle ne transmet plus en continu.
Ces contraintes ne sont pas bloquantes et des solutions de contournement assez simples existent mais il faut être conscient que rajouter des nœuds "intelligents" dans un réseau peuvent en augmenter la sensibilité.
Conclusion
Tentons alors d’extraire des recommandations parmis ces observations. Si la quantité d’appareils connectés augmente comme les prévisions le prévoient, le premier facteur à réguler sera la congestion des réseaux (et bien entendu la sécurité).
L'Edge computing est une solution extrêmement efficace pour faire face à ce problème. Les composants qui permettent d'effectuer les calculs sont de plus en plus abordables (ex : ATtiny, processeur 8-bits 20MHz < 3€) et de moins en moins consommateurs d'énergie. Il est donc possible de déporter certains calculs vers les extrémités du réseau pour le désengorger en n’envoyant que les données les plus pertinentes.
Cependant, cette tendance n'élimine pas l'intérêt du Cloud qui doit désormais dédier sa puissance de calcul et sa haute disponibilité à des interfaces de gestion des appareils et à des services nécessitant une très forte capacité de calcul (enregistrement des appareils, envoi de commande, gestion des configurations, maintenance prédictive, …). Dans le cas du Machine Learning, la phase d’apprentissage se fait sur le Cloud à partir de bases de connaissances volumineuses mais le traitement temps réel basé sur modèle généré reste local.
Il faut aussi faire preuve d'une plus grande rigueur quant à la sécurité dans ce genre d'architecture car on expose plus de failles dans un réseau qui comporte de plus en plus de noeuds intelligents. Lorsque les données brutes sont envoyées vers le Cloud, il est assez simple d'implémenter des nouveaux services en filtrant telle ou telle donnée. Lorsqu'on délègue du traitement aux appareils, le Cloud ne reçoit que le résultat de ce traitement et il faut alors garder la main sur les appareils pour apporter une modification (mise à jour, communications bidirectionnelles, …).
Une autre solution consiste à utiliser des passerelles qui servent d'agrégateur de connectivité et traduisent des protocoles IoT vers des protocoles plus standards ou servent à chiffrer ou déchiffrer des données. Dans ce cas, ces passerelles pourront aussi réaliser des étapes de calcul et traitement afin de réduire la quantité de données à traiter par les objets IoT. On appelle ces passerelles la couche de Fog Computing.
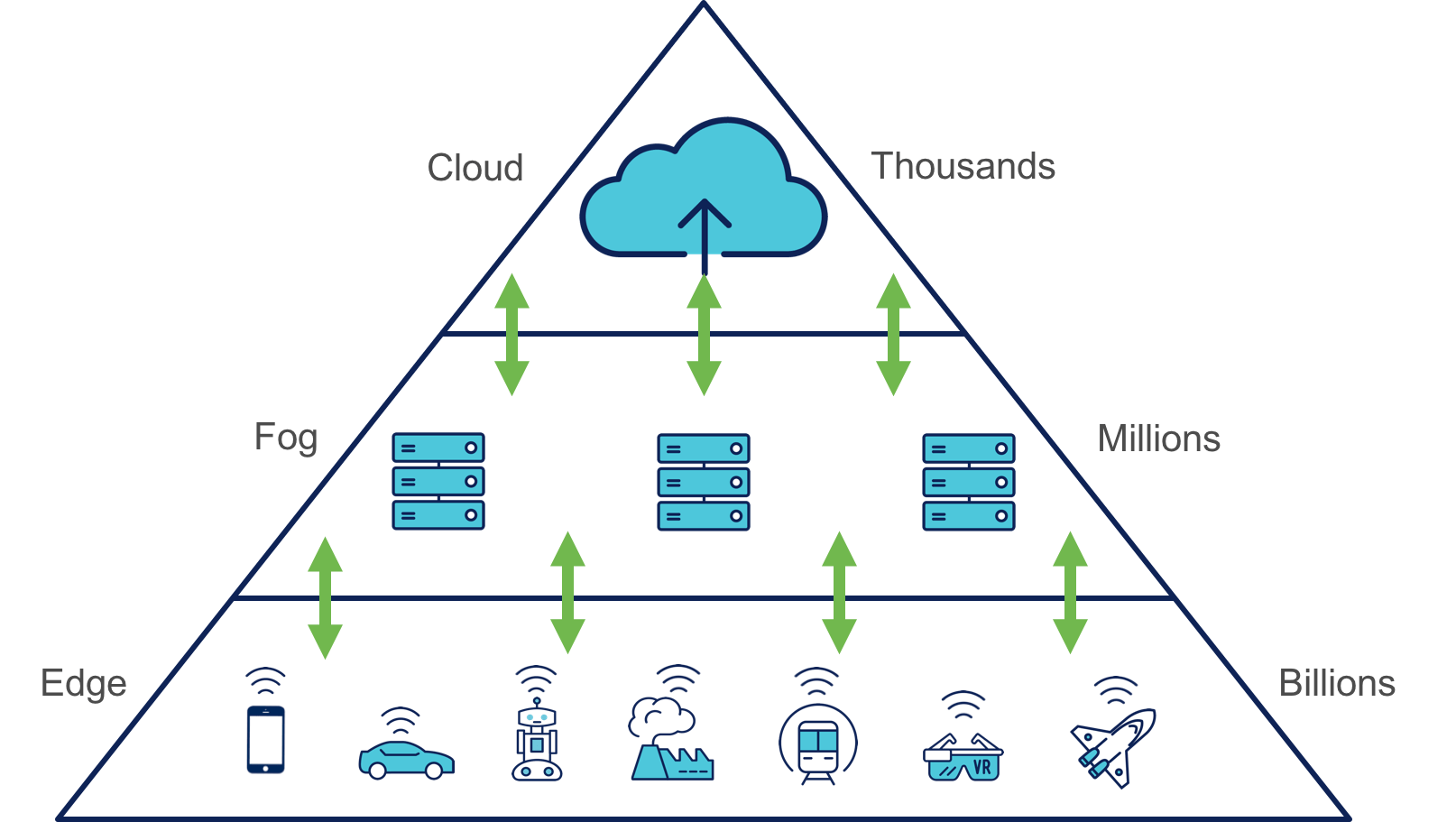
En bref :
L’Edge computing permet de désengorger les réseaux et ainsi d’en limiter les pannes.
La diminution de charge sur les serveurs centraux permet aussi de diminuer la latence.
Dans le cas d’une défaillance réseau ou d’une indisponibilité du système centralisé, les appareils peuvent continuer de fonctionner de manière autonome jusqu’au retour à la normale. On parle ici alors de résilience de l’architecture.
Les données qui arrivent au final vers le Cloud sont peu sensibles et chiffrées.
Lorsque l’on distribue les ressources dans un système d’information, on multiplie les vecteurs d’attaque et on augmente donc sa vulnérabilité aux attaques.
Il faut mettre en place un système de gestion des appareils puissant capable de gérer leurs états et leur mise à jour à distance.
Les firmwares embarqués doivent pouvoir (si besoin) communiquer entre eux sans l’intermédiaire d’un passe plat plus intelligent qui servirait à faire de la synchronisation et de l’archivage de ces échanges.
L’architecture idéale serait donc :
- Des appareils de plus en plus autonomes et intelligents sans que cela n’impute la consommation de batterie
- Un système centralisé avec une forte puissance de calcul que l’on exploite pour la mise en oeuvre d’algorithmes très complexes et pour la gestion à distance du parc d’appareils
- Un réseau suffisamment robuste et rapide pour assurer des communications fiables sans latence qui impacterait le service final