Du marécage à l'autonomie : redresser un projet data en tant que Tech Lead
Un data lake AWS en production depuis 7 ans. Un Tech Lead précédent en burn-out. 4 PO différents en 6 mois. Une équipe passée de 6 à 2 développeurs juniors sans encadrement. Un client frustré, souvent énervé, et qui a des raisons de l'être. Plus un marécage de données qu'un data lake.
18 mois plus tard : une équipe autonome, un client satisfait, 100 000 $ d'économies annuelles, et une plateforme data qui tient ses promesses.
Voici ce qui a changé, et comment.
Le diagnostic : tout est cassé, mais pas de la même façon
Le contexte : une entreprise du secteur de l'énergie qui opère un réseau de chauffage urbain alimentant plus d'un million de citadins. Le data lake, construit depuis 2019, centralise les données de consommation, de maintenance et de pilotage du réseau. Sur le papier, un projet à forte valeur métier.
En pratique, la timeline raconte une autre histoire :
| Période | Événement |
|---|---|
| 2019 | Démarrage du data lake, équipe de 6 |
| 2020 | Premier dashboard sur les données du data lake |
| 2022 | Premiers dashboards PowerBI |
| Début 2023 | Départ du PO leader côté client. Début de l'instabilité |
| Fin 2023 | 4 PO en 6 mois. Équipe réduite à 3, puis 2. Burn-out du Tech Lead |
| 2024 | Arrivée sur la mission du nouveau Tech Lead. Équipe : 2 juniors. Pas de PO |
Le burn-out du précédent Tech Lead n'était pas un problème de compétences. C'était le résultat prévisible d'une personne qui portait tout (technique, relation client, gestion de produit) sans soutien organisationnel, face à un client exigeant et sans PO stable.
Ce qui est cassé côté technique
- Plus de 10 repositories disparates, chacun avec ses conventions et ses dépendances. Un data swamp.
- 6 connecteurs externes fragiles (Salesforce, SIG, SFTP, Sharepoint…), chacun maîtrisé par un seul développeur. Un token expiré ou une API tierce qui change, et personne d'autre ne sait intervenir.
- Des Lambdas en Python 3.7, en fin de support depuis longtemps.
- Pas de tests. Ou si peu que ça ne compte pas.
- Pas de monitoring. Les bugs découverts en production, 1 à 2 semaines plus tard, quand le client s'en plaignait.
- Une dette technique de 7 ans accumulée par des équipes successives qui n'avaient ni le temps ni le mandat de la traiter.
Ce qui est cassé côté humain
- Pas de PO. Les développeurs reçoivent des demandes directement des métiers. Pas de priorisation, pas de backlog structuré.
- Un silotage fort. Chaque dev connaît "sa" partie du code. Si l'un part en vacances, personne ne peut reprendre.
- Un client frustré, et à raison : bugs récurrents, livraisons en retard, manque de visibilité. Sa frustration est légitime.
- "Nous, dans la DSI, on fait de l'agile très agile." Traduction : pas de processus, pas de rituels, pas de cadre. L'agilité comme excuse pour l'absence de méthode.
- Un manque de motivation profond. Citation d'un développeur : "À quoi bon développer une feature pour développer une feature ?"
Ce qui fonctionne encore
Il faut toujours chercher ce qui fonctionne, même dans le chaos :
- Les deux juniors ont une excellente connaissance des métiers et de bonnes relations avec la DSI. Capital précieux.
- Le produit a de la valeur : les dashboards alimentent de vraies décisions opérationnelles sur un réseau physique.
- Le client, malgré sa frustration, veut que ça marche. Ce n'est pas de l'indifférence. C'est de l'exaspération.
La question préalable : cette mission peut-elle encore avoir un intérêt ?
Avant de chercher comment redresser, une question plus fondamentale : est-ce que ça vaut le coup ?
Sur le papier, non. Et personne n'aurait tort de passer son chemin.
Ce qu'il faut voir au-delà :
- Un problème métier concret. Les données traitées servent à détecter des anomalies sur un réseau qui chauffe un million de personnes. C'est tangible.
- Un terrain d'apprentissage exceptionnel. Reprendre un projet en souffrance est l'exercice le plus formateur pour un Tech Lead. Pas d'architecte pour guider, pas de processus établi, pas de zone de confort.
- Une opportunité humaine. Deux juniors démotivés, c'est aussi deux personnes qui peuvent monter en compétences et retrouver du sens si le cadre change.
La décision : rester. Et transformer cette mission.
Les 4 leviers du redressement
Un Tech Lead mono-dimensionnel (qui ne fait que coder ou qui ne fait que manager) ne suffit pas dans ce type de contexte. Le redressement repose sur 4 rôles. Aucun n'est secondaire ; ce qui change, c'est lequel domine selon le moment.
Expert technique : assainir les fondations
Les premières semaines sont consacrées à rembourser la dette technique. Pas toute la dette (le temps manque) mais celle qui fait mal au quotidien.
Actions :
1. Consolidation en monorepo. Les 10+ repositories deviennent un seul monorepo. Migration de Jenkins (instable, mal maintenu) vers GitHub Actions avec déclenchement par chemin. Un seul endroit pour tout comprendre, un seul pipeline pour tout builder.
2. Migration Python 3.7 → 3.12 et modernisation de l'outillage. Toutes les Lambdas mises à jour. Adoption d'outils modernes : UV pour la gestion des dépendances (plus rapide, plus fiable que pip), Ruff pour le linting et le formatage (remplace flake8 + black + isort), Justfile pour l'automatisation des tâches courantes. Pas glamour, mais une version en fin de support est une bombe à retardement, et des outils modernes réduisent la friction quotidienne.
3. Ajout de monitoring et d'observabilité. Alertes CloudWatch, notifications Slack, métriques sur les appels API. Avant : bugs découverts par le client, 1 à 2 semaines plus tard. Après : détection et diagnostic en quelques minutes.
4. Audit FinOps. Ouverture d'AWS Cost Explorer. Découverte de 100 000 $/an de gaspillage (détails dans l'article dédié au FinOps). L'argent économisé = de la crédibilité gagnée auprès du client.
5. Infrastructure as Code. Migration du "ClickOps" (configuration manuelle dans la console AWS) vers Terraform. Migrations Snowflake versionnées avec schemachange. Code versionné, reproductible, maintenable.
Résultat technique :
| Métrique | Avant | Après |
|---|---|---|
| Coûts AWS annuels | ~78 000 $ | ~8 000 $ |
| Version Python | 3.7 (fin de support) | 3.12 |
| Repositories | 10+ | 1 monorepo |
| CI/CD | Jenkins (fragile) | GitHub Actions |
| Infra | ClickOps | Terraform |
| Monitoring | Aucun | CloudWatch + Slack + métriques API |
| Détection des bugs | 1-2 semaines (par le client) | Quelques minutes (alertes) |
Coach : le Collective Ownership comme philosophie
Le problème le plus urgent n'est pas technique. C'est le silotage. Si un développeur part en vacances et que personne ne peut reprendre son travail, l'équipe est fragile. Si un seul connaît Snowflake et un autre les Lambdas, ce sont deux individus, pas une équipe.
Le mantra : "Tout le monde doit pouvoir prendre n'importe quel ticket."
Actions :
1. Pair-programming quotidien. Pas "de temps en temps". Quotidien. Systématique. Un junior apprend Snowflake, l'autre apprend les API Lambda et les connecteurs externes (Salesforce, SIG, SFTP…).
2. Revue de code obligatoire. Tout n'est pas écrit en pair ; ce qui ne l'est pas passe obligatoirement en revue avant la pré-production. Ce n'est pas du flicage. C'est du partage de connaissance. Chaque revue est une occasion d'apprendre.
3. Cross-training organisé. Chacun forme l'autre sur "son" domaine. Des sessions dédiées et régulières, pas du "regarde par-dessus mon épaule".
Résultat : chacun peut partir en vacances sereinement. L'équipe a cessé d'être une collection d'individus.
Formateur : monter en compétences par la pratique
Les bonnes pratiques ne s'imposent pas par décret. Elles s'enseignent par l'exemple.
Actions :
1. Tests unitaires rendus obligatoires pour chaque nouveau développement. Pas en disant "écrivez des tests". En écrivant le premier test ensemble, en pair-programming, en montrant pourquoi c'est utile. Passage à plus de 5 000 tests.
2. Qualité de la donnée. L'équipe apprend à écrire ses propres dbt tests pour valider la cohérence des données dans Snowflake. Le déclic pédagogique : la qualité de la donnée n'est pas l'affaire d'une lointaine data quality team, c'est celle de l'équipe qui la produit. Une fois ce principe intégré, les tests ne sont plus une corvée imposée mais un réflexe.
3. Construction collective du datamart. Plus de 70 modèles dbt couvrant l'ensemble des domaines métier. Le datamart Snowflake construit avec l'équipe, pas pour l'équipe. Chaque choix d'architecture discuté, chaque modèle écrit en pair.
4. Autonomie sur le diagnostic. L'équipe apprend à utiliser CloudTrail, CloudWatch et les dbt tests pour diagnostiquer un problème elle-même, avant que le client ne le signale.
5. Introduction de patterns d'architecture. Les modules les plus critiques restructurés en Clean Architecture (Domain/Application/Infrastructure). Pas un cours théorique : chaque refactoring fait en pair-programming, en montrant concrètement la séparation des responsabilités. Et ce qui est codé seul passe en revue, où le respect du pattern est vérifié. Les juniors apprennent à structurer du code, pas juste à en écrire.
Facilitateur : reconstruire la relation client
C'est la dimension la plus difficile et la plus importante.
Le client est frustré. Et il a raison. Mais la frustration non adressée d'un client détruit la motivation d'une équipe. L'équipe perd confiance → le travail se dégrade → le client est plus frustré → l'équipe perd encore plus confiance. Cercle vicieux.
Comment casser ce cercle :
1. Transparence radicale. Un atelier pour lever les crispations. Rien d'exotique côté format : une rétrospective. Ce qui changeait, c'est le cadre : client et équipe dans la même salle, et la consigne d'être franc plutôt que poli. Pas de post-its gentils : chacun dit ce qui ne va pas, honnêtement. Résultat : ça a marché.
2. Présence physique accrue. De un demi-jour toutes les 2 semaines à 2 jours par semaine. Aucune résistance de l'équipe, au contraire : les juniors réclamaient eux-mêmes un encadrement plus présent et une relation client plus saine. La présence crée la confiance, côté client comme côté équipe.
3. Communication systématique :
- Photo de profil sur Teams (oui, ça compte)
- Client et équipe en copie de tous les mails
- Aller voir physiquement toutes les parties prenantes : relancer, partager, montrer
- Suivi hebdomadaire avec un Excalidraw récapitulatif
4. Sprint review hebdomadaire. Montrer ce qui a été fait chaque semaine. Pas un PowerPoint. Une démo live. Le client voit la progression, l'équipe voit que son travail a de la valeur.
5. Suivi quotidien avec les métiers. Les développeurs ne sont plus des exécutants qui reçoivent des tickets. Ils échangent directement avec les utilisateurs. Ils comprennent le "pourquoi" derrière chaque feature.
6. De vrais rituels agiles. Daily de 10 minutes centré sur les blocages (pas un tour de table d'avancement), sprint planning, rétrospective, backlog refinement. Ce qui manquait derrière l'"agile très agile" : un cadre. Pas pour la forme, mais pour donner du rythme et de la prévisibilité.
7. Gestion du backlog par l'équipe technique. Jira et priorisation portés par les développeurs eux-mêmes, en concertation avec le client. De l'agilité réelle.
Les résultats : rapides, concrets, durables
Résultats financiers
100 000 $/an d'économies :
| Poste | Économie annuelle |
|---|---|
| Optimisations AWS (KMS, S3, Lambda, logs) | 70 000 $ |
| Suppression de licences oubliées | 20 000 $ |
| Consolidation en monorepo | 10 000 $ |
| Total | 100 000 $/an |
Ce chiffre a changé la dynamique. Quand une équipe fait économiser 100 000 $ avant même de livrer une nouvelle feature, la crédibilité auprès du client bascule.
Résultats techniques
- Plus de 5 000 tests automatisés
- Monitoring proactif : détection des bugs en minutes au lieu de semaines
- Datamart Snowflake construit en équipe avec dbt et schemachange
- CI/CD moderne avec GitHub Actions (migration depuis Jenkins)
- Pipeline de déploiement multi-environnement avec promotion dev → intégration → production et gate d'approbation manuelle
- Infrastructure as Code avec Terraform
Résultats humains, les plus importants
- L'équipe est devenue autonome. C'est le vrai indicateur de succès d'un Tech Lead : quand l'équipe n'a plus besoin d'être encadrée.
- Le silotage a disparu. Chacun peut prendre n'importe quel ticket.
- Chacun peut partir en vacances sereinement. La connaissance est partagée.
- La motivation est revenue. Les développeurs ne font plus "une feature pour faire une feature". Ils comprennent l'impact de leur travail sur un réseau qui chauffe un million de citadins.
5 convictions forgées dans la difficulté
1. Les quick wins financiers changent tout
Les 100 000 $ d'économies FinOps ont transformé la relation client. Avant de parler de refactoring ou de bonnes pratiques, parler d'argent. C'est un langage universel, et c'est une preuve de valeur immédiate.
2. La dette technique est un symptôme, pas le problème
Le vrai problème, c'est l'organisation : pas de PO, pas de priorisation, pas de partage de connaissances, pas de pratiques de développement. Corriger la dette sans corriger l'organisation, c'est la garantie qu'elle reviendra.
3. Le Collective Ownership est non-négociable
Le silotage tue les équipes. Concrètement : le burn-out du précédent Tech Lead en est la preuve. Le pair-programming, la revue de code, le cross-training ne sont pas des "nice to have". Ce sont des prérequis pour une équipe résiliente.
4. Un client difficile est souvent un client légitime
La frustration du client n'était pas irrationnelle. Un produit qui ne fonctionne pas bien, une équipe qui change constamment, personne qui dit la vérité. La transparence (dire ce qui ne va pas, montrer ce qui est fait, être présent) est le seul antidote.
5. Le Tech Lead est un rôle à 4 dimensions
Expert technique, coach, formateur, facilitateur. Le secret : alterner entre ces rôles selon les besoins du moment.
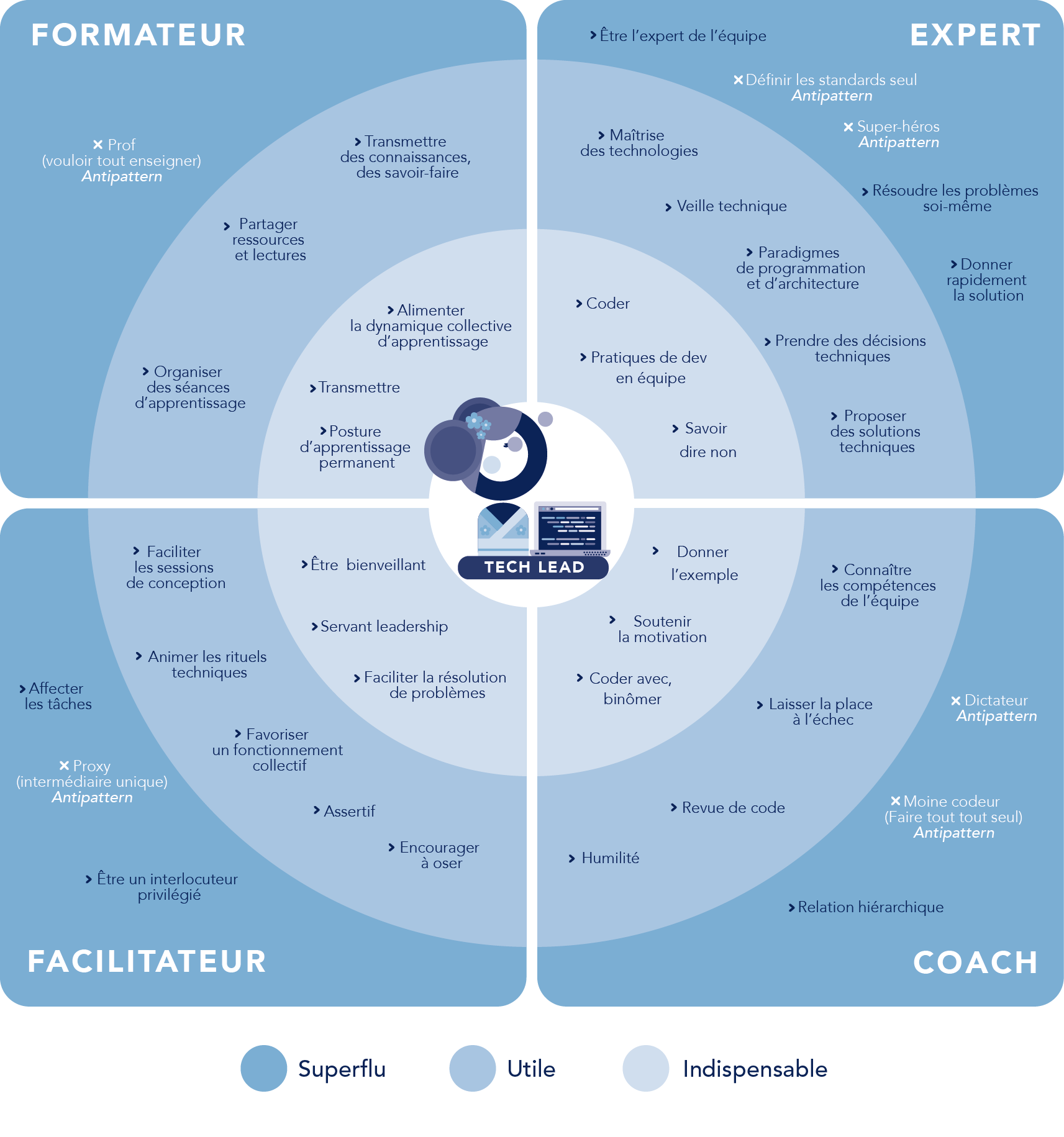
Schéma en quatre quadrants des dimensions du Tech Lead : Formateur, Expert, Facilitateur, Coach, avec pour chacune les pratiques clés et les antipatterns à éviter.
| Phase de la mission | Rôles dominants | Pourquoi |
|---|---|---|
| Premières semaines | Facilitateur + Expert technique | Reconstruire la confiance client, éteindre les incendies |
| Mois 1-3 | Expert technique + Formateur + Coach | Assainir, montrer, faire monter en compétences |
| Mois 3-6 | Coach | Autonomisation progressive |
| Aujourd'hui | Aucun | L'équipe porte elle-même les 4 dimensions |
La dernière ligne est le plus beau résultat.
Ce qu'on ne raconte pas
Dans le conseil en technologie, les articles portent souvent sur des projets greenfield, des stacks modernes, des architectures propres. Des migrations vers Kubernetes, des micro-services event-driven.
Les missions où tout va mal sont moins racontées. Celles où le client est en colère, l'équipe à bout, le code un champ de mines. Où la question n'est pas "quelle architecture choisir ?" mais "est-ce que cette mission a encore un sens ?".
Ces missions existent. Et elles sont formatrices, à condition d'être abordées avec méthode, empathie et pragmatisme.
Et si c'était à refaire aujourd'hui ? L'agentic coding n'existait pas encore quand cette mission a commencé, ou du moins n'était pas aussi accessible et efficace qu'aujourd'hui. Sur une équipe de 2 juniors, un agent IA capable d'écrire, tester et refactorer du code aurait été un multiplicateur de force considérable. Mais il ne remplace pas les fondations décrites dans cet article : sans tests, sans monitoring, sans collective ownership, un agent IA amplifie le chaos autant que la productivité.
J'ai quitté la mission. L'équipe, elle, continue sans Tech Lead pour la porter. C'est ça, le vrai indicateur de succès. Pas le nombre de tests, pas les économies, pas l'architecture. L'autonomie.
Pour aller plus loin : Le détail des 100 000 $ d'économies, étape par étape : FinOps : comment économiser 100 000 $/an en ouvrant simplement AWS Cost Explorer