Du dataset jetable au data product pérenne : comment le data mesh transforme notre rapport à la donnée
Dans les organisations où les données sont nombreuses, hétérogènes et stratégiques, leur mise à disposition efficace devient un levier clé de performance. L’approche data mesh, en décentralisant la gouvernance et en traitant la donnée comme un produit, promet une meilleure agilité et une appropriation renforcée par les équipes métier. Encore faut-il que ces produits de données soient visibles, compréhensibles et utilisables par tous du data scientist à l’utilisateur métier non technique.
C’est précisément ce défi que nous avons relevé dans le cadre d’une mission dans le secteur de l’énergie. Comment concevoir une expérience de découverte fluide dans une marketplace riche en data products ? Comment rendre ces produits accessibles sans expertise technique avancée ? Face à ces enjeux, plusieurs solutions concrètes ont été mises en œuvre et que nous partageons dans cet article.
Un socle : un data mesh dans l’énergie renouvelable
Le projet s’inscrit dans une transformation ambitieuse : construire une marketplace de data products partagés entre plusieurs entités d’un même groupe. Une première dans ce contexte.
Nous avons travaillé sur plusieurs data domains liés à l’énergie renouvelable, avec pour objectif de produire des data products de qualité, exploitables par des analystes, des data scientists, des équipes métiers. Le cadre était clair :
- Des données gouvernées par domaine,
- Des data products pensés comme des produits à part entière,
- Une plateforme self-service,
- Une gouvernance fédérée.
Les principes clés du data mesh
Le data mesh repose sur quatre piliers fondateurs qui changent radicalement notre façon de penser la donnée :
1. Propriété orientée domaine
Chaque domaine métier est responsable de ses données. Fini les silos techniques : la donnée vit là où elle est comprise.
2. Donnée comme produit
Chaque jeu de données est traité comme un produit, avec un cycle de vie, une documentation, des indicateurs de qualité, et une promesse de valeur pour ses consommateurs.
3. Infrastructure en libre-service
Les équipes peuvent publier, découvrir et consommer des data products sans dépendre d’une équipe centrale. L’autonomie devient la norme.
4. Gouvernance fédérée
Un cadre commun est défini (qualité, sécurité, interopérabilité), mais chaque domaine reste maître de ses règles internes. On parle de “constitution data mesh”.
Mais au fait… c’est quoi tous ces “data-trucs” ?
Lors de mes premiers mois en mission, je pensais que le data mesh consistait à rajouter le préfixe “data” à tous les termes : data product, data contract, data domain…Mais finalement, c’est plus profond que ça.
Et comme on n’est pas là pour faire du name-dropping, voici ce que ces concepts veulent vraiment dire :
Data Domain :
un périmètre métier cohérent dans lequel les données sont produites, comprises et exploitées. Chaque domaine est responsable de ses propres données, comme un mini-SI autonome.
Data Product :
un produit de données complet, pensé pour être utilisé. Il contient des datasets, des métadonnées, des règles de qualité, une documentation, et parfois des APIs. Il a un propriétaire, un cycle de vie, et une promesse de valeur.
Data Contract :
un accord explicite entre producteurs et consommateurs de données. Il définit ce qui est exposé, dans quel format, avec quelles garanties (fraîcheur, qualité, disponibilité). C’est le contrat de confiance du data mesh.
Petit focus sur le Data Product
Tous les data products ne se ressemblent pas. Dans un data mesh bien pensé, leur granularité dépend de leur proximité avec les systèmes sources, du niveau d’agrégation, et du type de consommation visé. Voici les trois grandes familles qu’on rencontre en mission :
Source-aligned data products
Ce sont les plus proches du terrain. Ils exposent les faits, événements et réalités métier d’un domaine, tels qu’ils sont enregistrés au moment de leur création. On y retrouve par exemple des logs ou des événements historisés. Ils ne sont pas conçus pour un cas d’usage particulier, mais pour représenter fidèlement la donnée brute dans sa durée.
Aggregated data products
Ces produits représentent des concepts métiers partagés, en agrégeant des données issues de sources différentes. Ils permettent de créer des vues consolidées, transverses, souvent utilisées pour des analyses ou des indicateurs globaux. Ils s’appuient fréquemment sur des data products source-aligned comme matière première.
Use case-aligned data products
Conçus pour répondre à un ou plusieurs cas d’usage précis, ces produits adaptent, enrichissent et modélisent les données pour servir une intention métier. Ils évoluent avec les besoins et s’appuient eux aussi sur des data products source-aligned ou agrégés pour construire une réponse ciblée.
Les douleurs du terrain (les data douleurs 🙂)
Trois constats ont émergé après le rush des premiers mois, où le build de data product était la priorité une du projet :
L’outil n’est pas toujours maîtrisé
Notre client a fait le choix de proposer les data products dans Databricks. Mais encore faut-il que les utilisateurs sachent s’en servir. Or, tous ne sont pas formés à l’outil. Résultat : des produits de qualité, mais sous-exploités.
Action mise en place :
Des sessions de formation Databricks ont été organisées pour accompagner les utilisateurs dans la prise en main de la plateforme. L’objectif : rendre l’accès aux données réellement self-service.
La documentation est souvent le parent pauvre
On l’a vu très concrètement lors d’un POC GenAI que nous avons mené pour faciliter la navigation dans la marketplace. Les agents intelligents que nous avons mis en place s’appuyaient sur la documentation pour guider les utilisateurs. Et là… silence radio. Peu de descriptions, peu de contexte, peu de métadonnées exploitables.
Action mis en place :
L’équipe data gouvernance a lancé des actions de sensibilisation, mais aussi des processus de contrôle pour garantir la qualité, la complétude et la cohérence de la documentation des data products. Désormais un data product ne peut être publié sans être dûment documenté.
Se repérer dans la marketplace devient un casse-tête
Avec la multiplication des data products, la navigation dans la marketplace est devenue un défi en soi. Trop de choix, trop peu de repères. Les utilisateurs se retrouvent perdus face à une offre riche mais difficile à explorer.
Ce qu’on a mis en place :
Pour répondre à ce besoin, nous avons conçu un système multi-agents. Il permet de guider l’utilisateur depuis son intention métier jusqu’à l’exécution d’une requête sur le bon dataset, en quelques secondes.
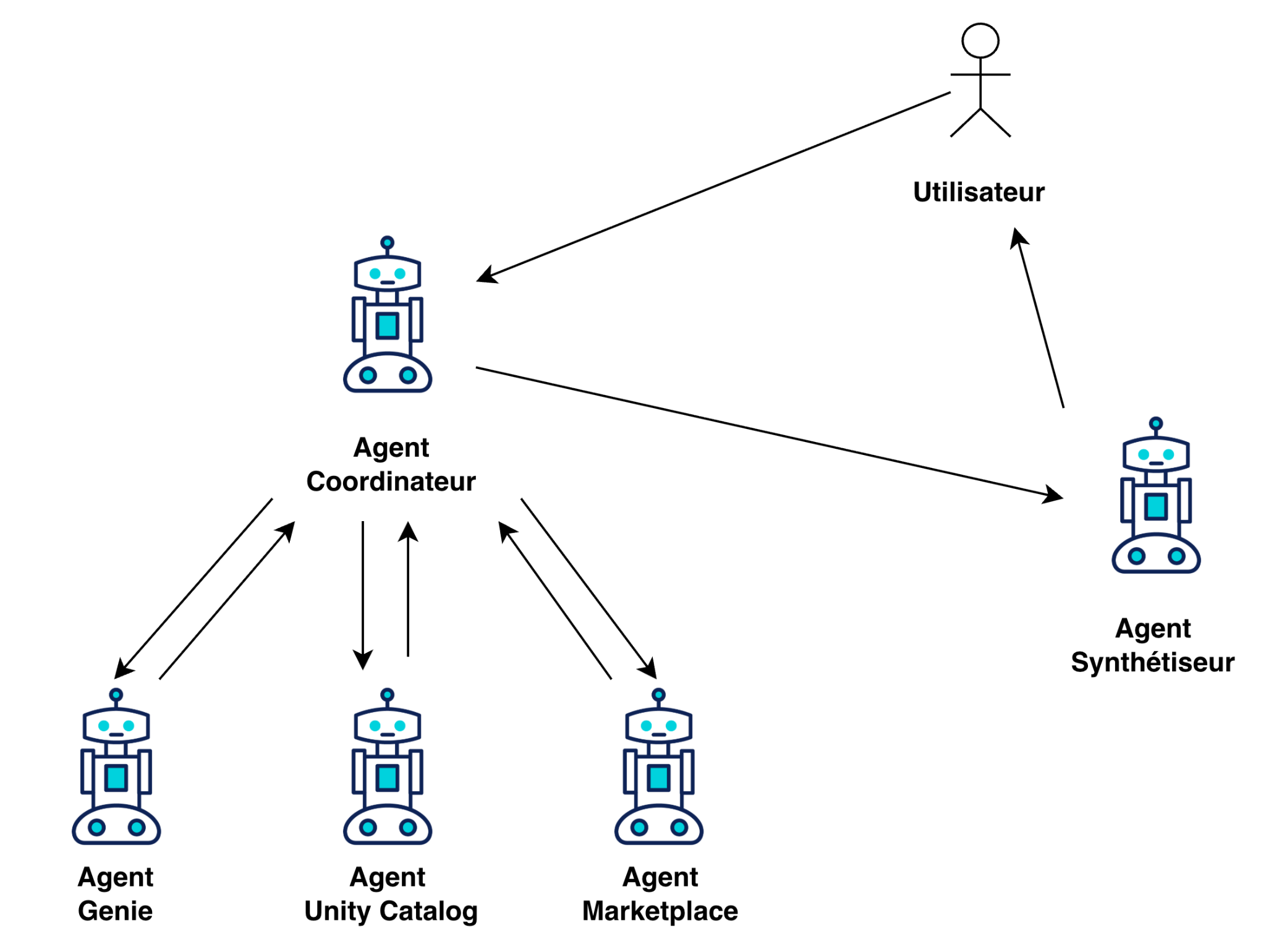
Une architecture multi-agents pour une exploration intelligente
Comme énoncé précédemment, l’idée derrière le système multi-agents est d’offrir à l’utilisateur un assistant intelligent capable de comprendre son besoin métier, de trouver le bon data product, d’identifier la bonne table, de générer la requête SQL… et de lui livrer le résultat, prêt à l’emploi.
Ce système est composé de cinq agents, à savoir:
1. Agent Coordinateur:
Le chef d’orchestre. Il reçoit la requête utilisateur, coordonne les autres agents, et s’assure que tout reste aligné avec l’intention initiale.
2. Agent Marketplace:
Il interroge l’API de la marketplace pour identifier les data products pertinents, en se basant sur les métadonnées disponibles sur la marketplace.
3. Agent Unity Catalog:
Il plonge dans le catalogue Databricks pour explorer les schémas, les tables, les colonnes. Objectif : trouver le dataset qui colle le mieux à la demande. Cet agent, comme celui de la marketplace, se base sur les métadonnées, mais cette fois-ci stockées sur Unity Catalog.
4. Agent Genie:
Il traduit la question métier en requête SQL, alignée avec le schéma du dataset, l’exécute dans Databricks, et renvoie le résultat. Databricks offre la possibilité de choisir son LLM parmi une large liste.
5. Agent Synthétiseur:
Il synthétise le tout dans une réponse claire, lisible, contextualisée. Il explique ce qui a été fait, sur quelles données, avec quels filtres, et quels résultats.
Pour le développement des agents, nous avons utilisé LangChain, avec le modèle databricks-claude-3-7-sonnet comme LLM. Le workflow multi-agent a été structuré à l’aide de LangGraph, permettant une orchestration fluide entre les agents. Grâce à UCFunctionToolkit, nous avons exposé des fonctions SQL permettant d’interroger les métadonnées de la marketplace et de Unity Catalog, sous forme d’outils LangChain. Ces outils sont ensuite utilisés par les agents Marketplace et Unity Catalog pour exécuter les requêtes et récupérer les résultats.
Un exemple concret : la consommation d’énergie verte en France
Demande utilisateur :
« Quelle est la consommation totale en énergie verte en France pendant septembre 2025 ? »
Ce qui se passe en coulisses :
- Le Coordinateur reçoit la requête
- L’agent Marketplace identifie un data product energy-usage sur la consommation d’énergie.
- L’agent Unity Catalog repère une table green_energy_consumption dans le data product energy-usage avec les colonnes country, month, consumption_mwh
- L’agent Genie génère et exécute la requête SQL suivante :
SELECT SUM(consumption_mwh) AS total_green_energy
FROM green_energy_consumption
WHERE country = 'France'
AND month = '2025-09';
- Le Synthétiseur répond :
« J’ai trouvé le dataset green_energy_consumption dans le data product energy-usage. La requête a retourné une consommation totale de 12 480 000 MWh pour la France au mois de septembre 2025. »
Et maintenant ?
Le data mesh nous a appris à penser la donnée comme un produit.
Le multi-agent nous pousse à penser l’accès à la donnée comme un service.
Demain, chaque utilisateur pourra dialoguer avec la donnée comme avec un collègue.
Et ça, c’est une révolution.