Discovering Flynn
Flynn is a Platform as a Service that allows to deploy and scale applications easily. It is based on containers, it is open-source, and its pitch is:
Throw away the duct tape.
The first impression
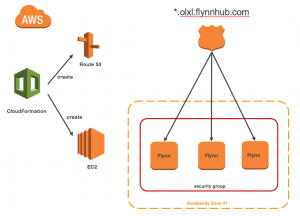
There are many ways to install the platform, using vagrant, or directly on a server. I chose to install it on AWS. The set-up is simple: through a custom web interface, you configure a CloudFormation template that is run on AWS:
- create the EC2 instances with the correct security groups and settings
- install Flynn on the instances
- setup the DNS record
- redirect a subdomain from the Flynn team (olxl.flynnhub.com in my case)
- create a hosted zone on route53 with all the setup for high availability
- create alarms on endpoints
From the Getting started, within 2 minutes, I could deploy an application that was previously on Heroku.
Needless to say, I was thrilled to create a PaaS platform able to scale and deploy applications in less than 30 minutes (mostly waiting for CloudFormation). Everything seems automagic, but is it dark magic or pure genius? Let's find out...
Can it live up to the hype?
How can we deploy an application?
First of all, it is necessary to develop the application following the 12-factor app guidelines. There are two ways of deploying an application after declaring it in Flynn.
Create an Application on Flynn
After cloning the repository https://github.com/ThibautGery/todomvc-mongodb, you can configure your application using the CLI:
Using the heroku buildpack
git push flynn
When using git, the code is pushed to a remote git repository. The buildpack will detect the application’s language and download its dependencies before running the server using the Procfile.
You can also use the GUI using the Github integration to deploy clicking on buttons.
Using Docker
The repository must contain a Dockerfile in order to build the Docker image
docker build . -t my_image flynn -a my_app docker push my_image Flynn scale app=1
Using Docker, the image is pushed to a remote Docker registry. Then, the image will be run as a container after you configure the scale option. But first you need to configure Docker on your CLI:
Databases
Flynn offers little or no configuration possibilities on the application. Rancher, for example, offers some kind of configuration with a config file (similar to docker-compose). Flynn doesn't, but it packages four ready-to-use databases: MySQL, PostgreSQL, MongoDb (not sure it qualifies as a "Database"...) and Redis. But there are some restrictions:
Flynn’s databases are currently designed with staging, testing, development, and small-scale production workloads in mind. They are not currently suitable for storing large amounts of data.
From: flynn.io/docs/databases
The developers don't give any information about their understanding of "small-scale workloads", thus you should run load tests to verify the stability of the platform in your context.
Using Flynn
There are four tools to use the Flynn platform: the developers will be using the GUI, the CLI, the API. The Ops have their own CLI to perform tasks on the cluster.
The developers can create the application, scale it, and remove it. They can manage their databases (MySQL, PostgreSQL, Redis, Mongodb), their HTML routes, their SSL certificates, their jobs and environment variables. Everything can be done using the GUI (great when starting) or using the CLI or the API (great for automation).
The Administrators can manage the cluster and the nodes (promoting or demoting them…). For example, they can list the nodes:
$ flynn-host list ID ADDR RAFT STATUS ip1002237 10.0.2.237:1113 peer ip1001170 10.0.1.170:1113 peer (leader) ip1006123 10.0.6.123:1113 peer
High availability
The best way to check the availability of a system is to run a benchmark.
The setup follows this configuration:
- Used a cluster of 3 nodes deployed on AWS t2.medium instances
- I deployed the todo App https://github.com/ThibautGery/todomvc-mongodb with MongoDB using Docker
- I deployed the application using three containers (scale = 3)
- Used 3 A records from todo-docker.vgry.flynnhub.com pointing to the 3 cluster's nodes
- Created a Gatling test available here
- Run a control assay on the cluster, the results can be found here
- Run a test and 3 min after starting, brutally stop one cluster node, the results can be found here
There were 8 users that had the following error:
j_ConnectException: Connection refused: todo-docker.vgry.flynnhub.com/52.62.245.207:80_
The DNS on Route53 records uses health checks and as soon the error was detected the DNS was changed. By the time the DNS was propagated, the faulty server was not accessible to the public.
The test shows that the current setup provides High Availability (HA) but there is a delay since it relies on DNS propagation. Depending on the use case, it might be sufficient. If you need a more aggressive HA, you can use a system in front to do it, like AWS Elastic Load Balancer or HAproxy.
A few notes:
- This test didn't take into account the database, therefore before deploying in production, run additional tests
- The sample application is really bad when it comes to web perf, please Concatenate, Compress and Cache.
Behind the hood
The platform is built in Go and has several components and everything is detailed in their documentation:
- flynn-host is the main daemon it is responsible for running the container of the host using libcontainer, a docker submodule. Every other internal or external services are running in containers.
- Discoverd: custom service discovery component
- flannel: virtual network developed by CoreOS
- postgresSQL: database to store the internal state of the cluster
- controller: custom component providing the HTTP interface for communicating with the scheduler
- scheduler: custom component responsible for starting stop and scale the different application in the cluster
- Router: custom component routing the HTTP/HTTPS request to the correct internal API or application
- Buildpack: using Heroku component to create application
- Log aggregator: custom component to centralize logs using TCP.
Do it yourself features
The missing features are:
- There is no account management, just a token to connect to Flynn, you cannot restrict the access to different applications. There is an active open ticket but it has been pending since November 2013…
- There is no centralized log, there is a component called logaggregator but there is no documentation about it. The hacky solution could be: using the CLI the data could be streamed to an external system. This solution might not scale. The better solution would be using a log aggregator like logstash or fluentd and let the administrator configure the tool to send the log to their favorite system like elasticsearch, S3… In my opinion, this is the main blocker of using the platform in production.
- There is no integration with the common supervision platforms (like New Relic or Datadog) for the cluster itself, you will need to install the agent yourself which is not a problem. (More info)
Conclusion
Flynn is a promising platform because of its ease of use however it is still a young framework and it is lacking some key features needed for enterprise deployment.
Flynn is not the silver bullet, here are some good reasons not to use it:
- If you deploy one application, no need for a platform, just use infra-as-code tools such as Ansible, Puppet or Chef.
- If you plan a heavy load on your databases, you can't use Flynn's ones
- If you are a big organisation and you want more granular access control
However, in the meantime, if you need to deploy several simple applications like an MVP to test ideas, the platform will help you to reduce your time to market.