Diagrammes d'architecture as-code avec C4 model - partie 2 : dans la pratique
Diagrammes d'architecture as-code avec C4 model - partie 2 : dans la pratique
Remerciement aux relecteurs, et les octos qui ont pratiqué l’exercice du Perfection Game en interne pour aider à l’améliorer : Sofía Calcagno, Sarah Ourabah, Borémi Toch, Thomas Pesneau
Cet article fait suite à la première partie qui traitait de l‘outillage (varié) permettant de produire des diagrammes à partir de code via des outils qui implémentent C4Model. Si ce premier article vous a peut-être aidé à construire vos premiers diagrammes en quelques minutes, il laisse néanmoins quelques questions en suspens pour celui ou celle qui souhaite pousser sa pratique plus loin :
- Parmi les outils présentés dans l’article précédent, lequel adopter ?
- Dois-je absolument documenter tous les niveaux de C1 à C4 ?
- Suffit-il d’initier un repo git nommé “architecture” et de demander à tout le monde de contribuer pour qu’une dynamique de documentation pérenne prenne dans mon équipe ?
- Même question, pour qu’une dynamique de documentation prenne à l’échelle de mon organisation ?
- Vaut-il mieux initier cette démarche de modélisation de l’architecture de l’entreprise dans un repo de code unique, centralisé (pour avoir tous les diagrammes consultables simplement en un même lieu mais plus loin des développeurs, potentiels contributeurs) ou dans les repos de chaque équipe de développement (plus proche des applications à documenter, mais éclatée)?
Ces questionnements touchent à des sujets variés, socio-techniques : il faut choisir un outil technique pour produire des diagrammes, et ce choix semble difficile à décorréler de la définition d’un cadre de collaboration, de gouvernance, de contribution.
Cet article souhaite apporter des éléments de réponse sous la forme d’un billet d’humeur : en compilant des avis et des convictions, non pas sur la base d’une étude, mais sur la base d’expériences vécues, d’échecs mais aussi de tentatives plus fructueuses de mettre en place une démarche de documentation de l’architecture as-code dans des secteurs variés (énergie, banque, services publics, assurance) et à des échelles variées : à la maille d’un individu, d’une équipe, de plusieurs équipes collaborant sur le même produit, et d’une organisation.
Ai-je intérêt à produire des diagrammes avec du code ?
Se poser cette question est en effet sain: si je suis satisfait de la documentation que je produis aujourd’hui sans code, quel gain puis-je espérer en mettant en place cette solution ? A quel problème cela répondrait ? Suis-je capable d’identifier une personne dans l’organisation qui en bénéficiera ?
Si les réponses à ces questions restent floues malgré les éléments de réponse évoqués dans le premier article (entres autres, l’attrait pour décrire des diagrammes avec un format text-based, et ce qui peut en découler en termes de comparaison, de versionning, d’automatisation), alors peut-être vaut-il mieux ne pas forcer les choses au risque d’introduire de la complexité accidentelle.
> If you aren’t aligned with a human need, you’re just going to build a very powerful system to address a very small — or perhaps nonexistent — problem – Jess Holbrook
On prendra aussi note, comme le souligne Simon Brown, que le C4Model a été conçu pour être mis entre les mains (en termes d’expérience utilisateur) d’une population avec une appétence pour la technique. Pas nécessairement des développeurs chevronnés, mais des personnes qui ne seraient pas rebutées par le format text-based, ou par le fait de manipuler un IDE, un terminal, ou la ligne de commande.
Il ne sera pas étonnant de constater un manque d’appétence pour ce genre d’outils auprès de certaines populations d’architectes qui conçoivent leur rôle loin de la technique ou de la fameuse engine room décrite par Gregor Hope car ces outils n’ont pas été pensés avec ce persona en tête.
Enfin, certains outils de diagrams-as-code ne laisse aucun choix à l’auteur pour positionner ses boîtes et ses flèches comme souhaité : le placement est automatique et cela peut être rebutant pour qui ce genre de considérations est signifiante dans le récit à raconter au travers de diagrammes. On notera en vrac, au moment d’écrire ces lignes, que :
- MermaidJS ne laisse pas de choix de positionnement,
- C4PlantUML offre la possibilité de forcer la direction d’une relation (en utilisant
Rel_UpouRel_Rightpar exemple, au lieu deRel), - Structurizr offre la possibilité de déplacer des éléments manuellement, en drag-and-drop dans son interface web.
C4Model pose 4 abstractions pour tout modéliser, ça va nous faire gagner du temps, non ?
De prime abord, on pourrait intuiter que C4Model servirait d’accélérateur : quatre abstractions ont été conçues pour modéliser toutes formes d’architecture, il n’y aurait alors plus qu’à se servir de ces abstractions et les assembler.
Tiré à l’extrême, ce raisonnement peut nous amener à penser que le coût d’alignement serait alors nul au début d’un projet ou au moment d’onboarder une personne dans une équipe car nous serions capables de capitaliser sur un ubiquitous langage sur étagère : un langage commun aux parties prenantes désireuses de discuter d’architecture, qui serait un acquis pour ces parties prenantes avant même leur premier échange.
Dans la pratique, en discutant avec plusieurs équipes dans une même organisation, ou d’une entreprise à l’autre, j’observe que même si les personnes autour de la table sont familières avec C4Model, il y a toujours besoin de s’accorder sur les termes au moment de modéliser un problème et penser des solutions.
Si le niveau le plus bas concernant le code (niveau C4) se passe d’explications, s’aligner sur la signification de ce qu’est un software system (dans un diagramme C1), un container (C2) ou un composant (C3) est toujours nécessaire pour s’assurer qu’on parle de la même chose ou qu’on en a tous une compréhension similaire : une même API peut être considérée comme un software system dans la documentation d’architecture d’une équipe qui la consomme, et comme un container dans la documentation d’architecture de l’équipe qui la maintient.
Je tire de ces expériences que C4Model peut en effet être un accélérateur : les 4 abstractions de ce modèle posent une base de travail qui peut rendre les échanges plus fluides car on ne part pas de zéro. Mais ces travaux ne peuvent pas se substituer à (au moins) une discussion pour s’aligner.
Les abstractions de C4 model ont la vertu d’apporter une base de vocabulaire commun et un nombre d’abstractions hiérarchisées et limitées : il peut ainsi être plus facile de converger sur ce qu’on considère être un container dans une organisation quand on doit réfléchir sur 4 niveaux abstractions plutôt que 10 ou 20.
Il faut aussi remarquer que le cadre posé par ces abstractions est volontairement souple : on peut se contenter de moins, ou ajouter des niveaux supplémentaires, mais attention à ne pas s’y perdre. Gardons en tête le théorème fondamental de l'ingénierie logicielle :
Tout problème peut être résolu par l’introduction d’un niveau d’abstraction supplémentaire … sauf le problème d’avoir trop de niveaux d’indirections ! – David Wheeler
Quelle saveur de C4Model est la meilleure 🍨🍦🍧 ? MermaidJS, C4-PlantUML ou Structurizr 🧜 ?
En bon consultant, je dirais simplement que la réponse n’est pas évidente et que ça dépend™️
Ma manière d’aborder cette question est généralement itérative, en commençant par la solution la plus simple et la plus rapide à mettre en place pour produire un premier diagramme avec MermaidJS, dans un fichier Markdown.
Cela me permet généralement d’introduire cette démarche facilement dans une équipe de développement, en introduisant de nouveaux concepts (diagrams-as-code, les abstractions C1 et C2 de C4Model) sans introduire de nouveaux outils. Si le code de l’équipe est versionné, il y a généralement du Markdown déjà présent dans la base de code, au moins sous la forme du sempiternel README.md qui sert désormais de point d’entrée universel et tacite à tous nos projets.
Je constate en pratique que je produis rarement des diagrammes sur les niveaux C3 et C4. Cela est peut-être dû au fait que ces niveaux évoluent plus régulièrement que les autres et peuvent demander plus d’effort à maintenir : il est moins rare de voir une nouvelle classe apparaître dans le code (niveau C4) que de voir un nouveau software system apparaître dans le paysage (au niveau C1). Aussi, les IDE capables de générer des diagrammes de classes ou de dépendances entre modules peuvent s’y substituer.
Au moment de faire évoluer ces premiers diagrammes (au bout de quelques jours ou semaines), je quitte généralement le Markdown et MermaidJS à cause des limitations de MermaidJS évoquées dans le premier article : notamment l’absence de la fonctionnalité permettant d’utiliser des sprites pour faire figurer des illustrations dans les diagrammes. Ce n’est certes pas une fonctionnalité cœur, mais c’est une fonctionnalité de confort qui aide à l’adoption et la prise en main des diagrammes.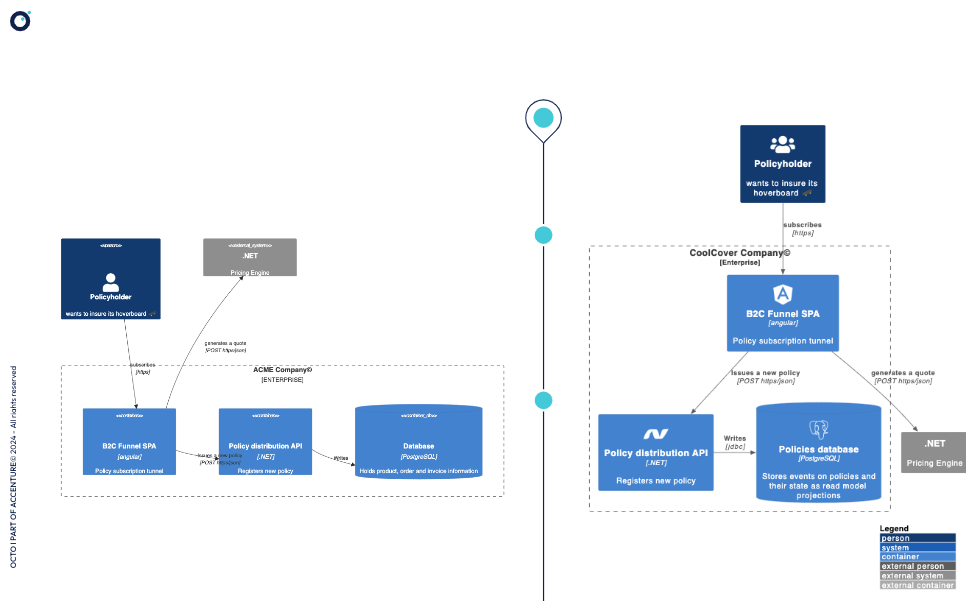
et avec C4PlantUML à droite (avec sprites pour mentionner des technologies)*
J’en profite aussi pour sortir le code du README.md pour le rédiger dans un fichier .puml dédié, en C4-PlantUML afin d’optimiser le ratio “signal-sur-bruit”. En effet, le README.md peut évoluer pour diverses raisons autres que documenter l’évolution de l’architecture. Avoir un fichier par diagramme permet de s’assurer que la modification d’un fichier, et donc son apparition dans l’historique git, traduit une évolution de l’architecture.
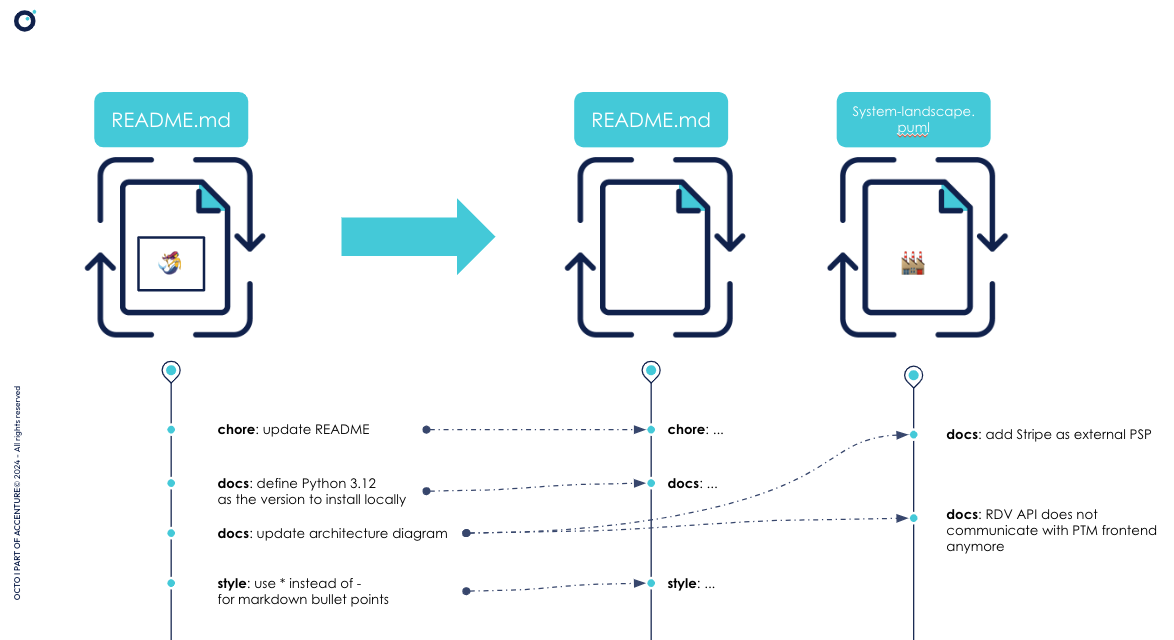
Il peut alors m’arriver de rester très longtemps (plusieurs mois ou années) avec C4PlantUML, voire ne jamais avoir besoin de changer d’outils, en modélisant un diagramme par fichier.
Si le patrimoine de fichiers .puml à maintenir commence à grandir, ou si j’observe que l’édition des fichiers devient douloureuse (quand certains concepts sont mentionnés dans plusieurs fichiers et que plusieurs diagrammes ont besoin d’évoluer pour un changement trivial, comme l’ajout d’une flèche), Structurizr commence à devenir une solution séduisante.
En effet, le DSL Structurizr permet de définir les éléments d’architecture une seule fois, dans un bloc model, et de créer autant de diagrammes que l’on souhaite raconter d’histoires dans un bloc views. L’édition d’une flèche ou d’une boîte se répercute alors immédiatement sur tous les diagrammes où cet élément intervient.
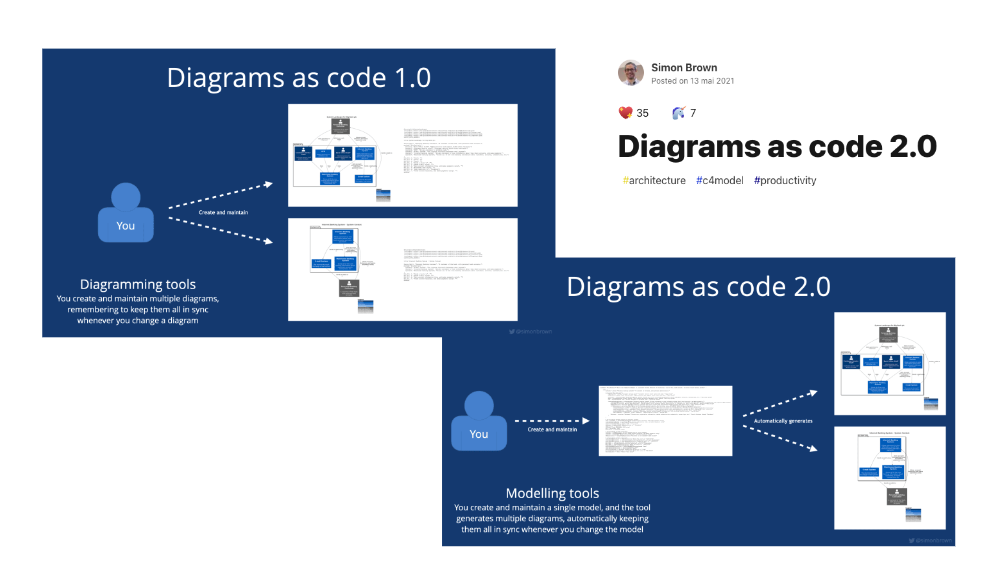
puis construire les vues souhaitées à partir de ce modèle
Cela peut aussi faire sens de dégainer tout de suite Structurizr si l’on a la certitude tôt que l’on va avoir à maintenir un patrimoine de diagrammes conséquents par exemple. Mais cela se fait au prix d’imposer tôt de la complexité aux personnes avec qui on va collaborer. Découvrir et s’approprier C4Model, manipuler Docker et des outils en CLI : la montée en compétences peut être ardue quand on ne connaît aucun de ces outils ou si l’intérêt de faire du diagrams-as-code reste à démontrer.
L’absence d’une fonctionnalité d’export automatique de tous les diagrammes en fichiers d’image (PNG ou SVG par exemple) avec la CLI Structurizr peut aussi être un frein à utiliser Structurizr, et ça ne semble pas prêt de changer. En effet, selon Simon Brown, il est dommage de se passer de l’interactivité apportée par Structurizr :
> At the moment, [...] whenever people ask for an architecture diagram they normally want a static png file [... so they] can put it in Confluence. And that kind of makes me sad ! Because we've got all this tech : the c4 model is hierarchical, it allows you to kind of zoom down the levels and do filtering … and people want a png file. So my recommendation is : please stop using png files ! – Simon Brown @ GOTO Copenhagen 2021
One-to-or-many repositories ? Ou l’opposition classique entre l’autonomie et l’autorité
Au moment de mettre en place C4Model avec votre outil préféré (voir la partie précédente), la question du lieu de sa mise en place se pose.
Étrangement similaire à la dualité “code applicatif/code d’infrastructure” que certains veulent absolument séparer dans des repos distincts et d’autres non, les options que je rencontre fréquemment sur le terrain sont les suivantes, sans prétention d’exhaustivité :
- Les architectes créent un nouveau repo de code, unique et central, généralement nommé “architecture”,
- Chaque équipe de développement produit ses diagrammes dans le repo qu’elle maintient, selon un mode distribué,
- L’organisation fonctionne en monorepo, les développeurs et les architectes s’accordent pour faire vivre dans le même repo le code C4Model et le code applicatif
Là aussi, à la question “quelle est la meilleure option”, il n’y a pas de réponse universelle. J’ai pu voir ces options fonctionner, et chacune d’entre elles nécessitent de faire des compromis.
Parcourons-les ensemble.
Option #1 | L’autorité: nouveau repo “architecture” central
Cette option est souvent motivée par les besoins d’avoir une vue consolidée de l’architecture de tout le SI en un même lieu, et d’avoir une source de vérité unique. On essaie alors d’obtenir ces garanties par la centralisation des initiatives de documentation en un seul lieu.
Ces besoins émanent généralement de populations d’architectes, ce sont donc généralement eux qui vont trouver de l’intérêt dans cette option et être à son initiative.
Cette option a généralement du mal à prendre auprès d’autres populations (développeurs, ops, …) : je constate souvent en consultant l’historique git qu’il y a peu de contributeurs, souvent 1 contributeur responsable de plus de 90% des commits. Je suis intervenu dans un dispositif d’une centaine de personnes et où l’architecte du programme était la seule personne à contribuer à ces diagrammes. Non pas qu’il interdisait à autrui de contribuer, au contraire.
Pour ma part, j’explique cela par la loi de proximité (aussi appelée de façon morbide “loi du mort kilométrique” dans le monde du journalisme) : il est difficile de susciter de l’intérêt pour les choses qui se passent loin de notre quotidien.
Il est ainsi difficile pour un développeur de se sentir concerné ou motivé naturellement par la mise à jour de fichiers de diagrammes C4Model quand ceux-ci ne sont pas placés sur son chemin critique (dans le repo de code applicatif dans lequel il contribue tous les jours, par exemple).
L’effet peut s’amplifier lorsqu’il s’agit de surcroît d’un repo dont il ne connaît pas l’existence, ou qu’il n’a peut-être même pas le droit de consulter ou de cloner, ce qui peut arriver dans les organisations où tous les repos de code sont inaccessibles pour tous par défaut, par exemple.
Option #2 | L’autonomie: les diagrammes vivent au plus proche du code qu’ils documentent, dans plusieurs repos
Dans ce scénario, le code pour modéliser les diagrammes d’architecture est versionné dans le repo de chaque équipe de développement travaillant sur son produit ou son service.
Dans la pratique, je constate que la proximité entre code de diagramme et code applicatif aide à activer une démarche de Living Documentation, où le code et les diagrammes peuvent évoluer au même rythme.
Cette proximité peut créer les opportunités suivantes :
- Avec les fonctionnalités de refactoring proposées par un IDE (comme VSCode, ou les éditeurs de code de la suite JetBrains), modifier le nom d’une classe peut être appliqué sur toutes les occurrences où ce nom de classe apparaît, dans le code applicatif, mais aussi dans le code de diagrammes,
- Le renommage est ainsi réalisé partout, dans une opération atomique capturée en un seul commit,
- On évite ainsi de renommer un élément structurant de l’architecture uniquement dans le code et pas dans les diagrammes (et vice-versa).
- Si les décisions d’architecture sont aussi documentées “as-code”, et dans le même repo, il est possible de rédiger une décision dans un journal de décisions (ADR), et mettre à jour dans le même commit le diagramme d’architecture et la décision qui justifie sa modification.
- Pour les plus aventureux, et si l’implémentation de la décision n’est pas incompatible avec le fait de travailler par petits lots (working in small batches), on pourra même imaginer capturer dans le même commit git :
- décision d’architecture,
- évolution du diagramme pour refléter la décision,
- évolution du code applicatif ou d’infrastructure pour être aligné avec le diagramme et la décision.
- Pour les plus aventureux, et si l’implémentation de la décision n’est pas incompatible avec le fait de travailler par petits lots (working in small batches), on pourra même imaginer capturer dans le même commit git :
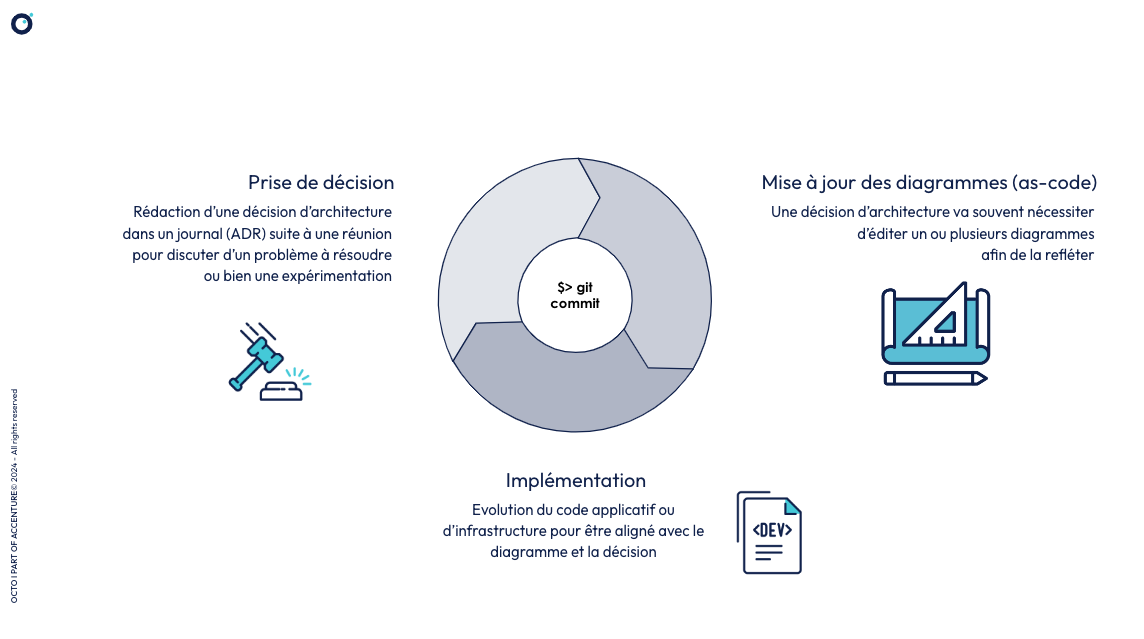
formant un tout cohérent dans un même commit
Comme les diagrammes sont éclatés sur plusieurs repos, on trouvera comme inconvénient à cette option la difficulté de pouvoir consulter une vue consolidée de l’architecture de tout le SI en un même lieu.
Ce n’est pour autant pas impossible d’obtenir cette vue d’ensemble, on peut toujours y parvenir au prix d’efforts et d’outillage supplémentaires.
Ainsi, on peut imaginer une approche fédérée de la documentation, où le code des diagrammes vivrait toujours au plus proche du code documenté, dans plusieurs repos, mais où chaque équipe en charge de chaque repo devrait mettre à disposition ses diagrammes en un lieu commun.
Une implémentation pourrait prendre la forme de tâches automatisées dans un pipeline de CI/CD où le code C4Model serait utilisé pour produire des artéfacts (les diagrammes, en PNG par exemple), et où ces artéfacts seraient déposés dans un dépôt commun (dans un stockage objet, ou directement dans une page de votre outil de Wiki d’entreprise si celui-ci fournit une API, comme Confluence ou Notion). Voici ce à quoi cela pourrait ressembler :
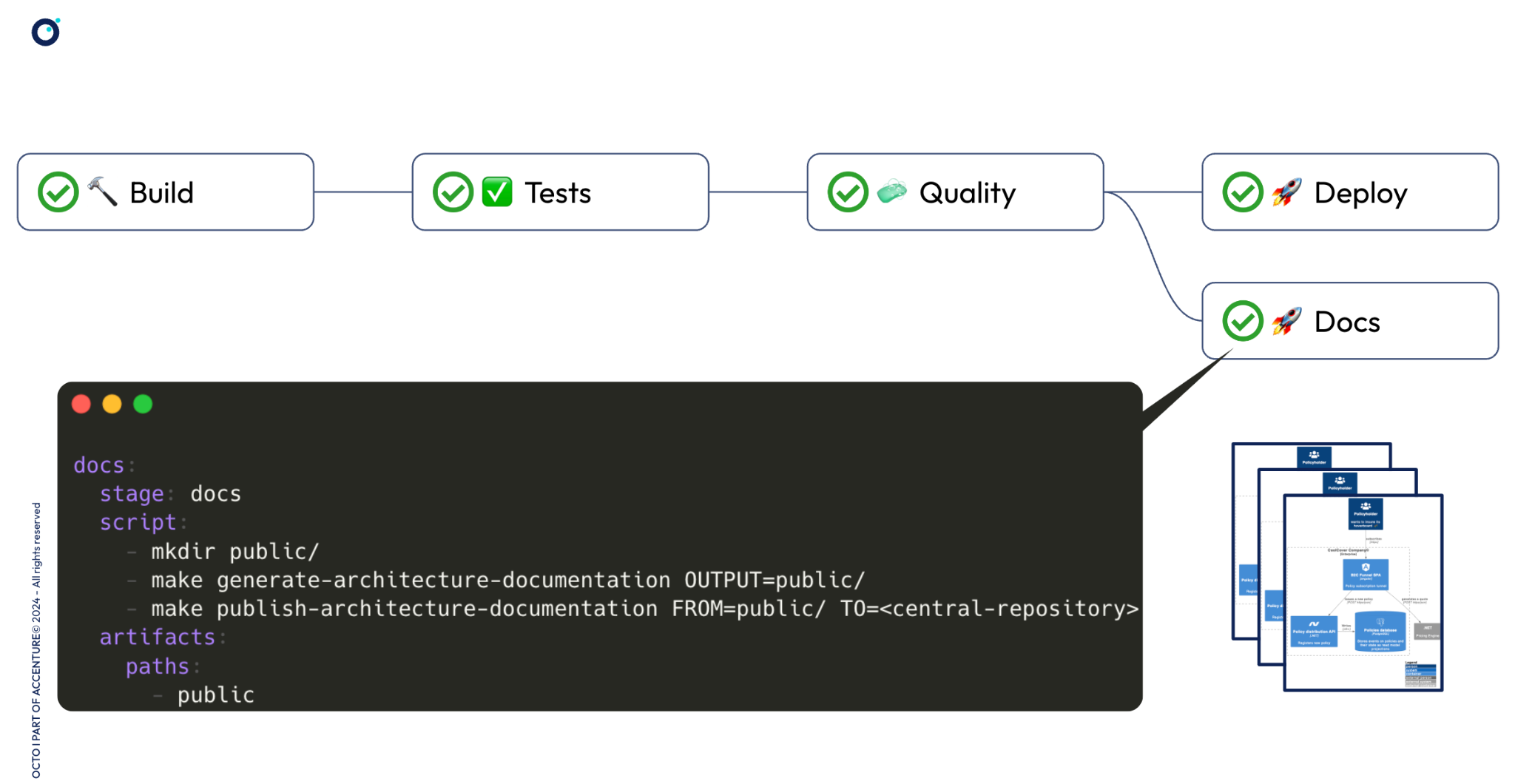
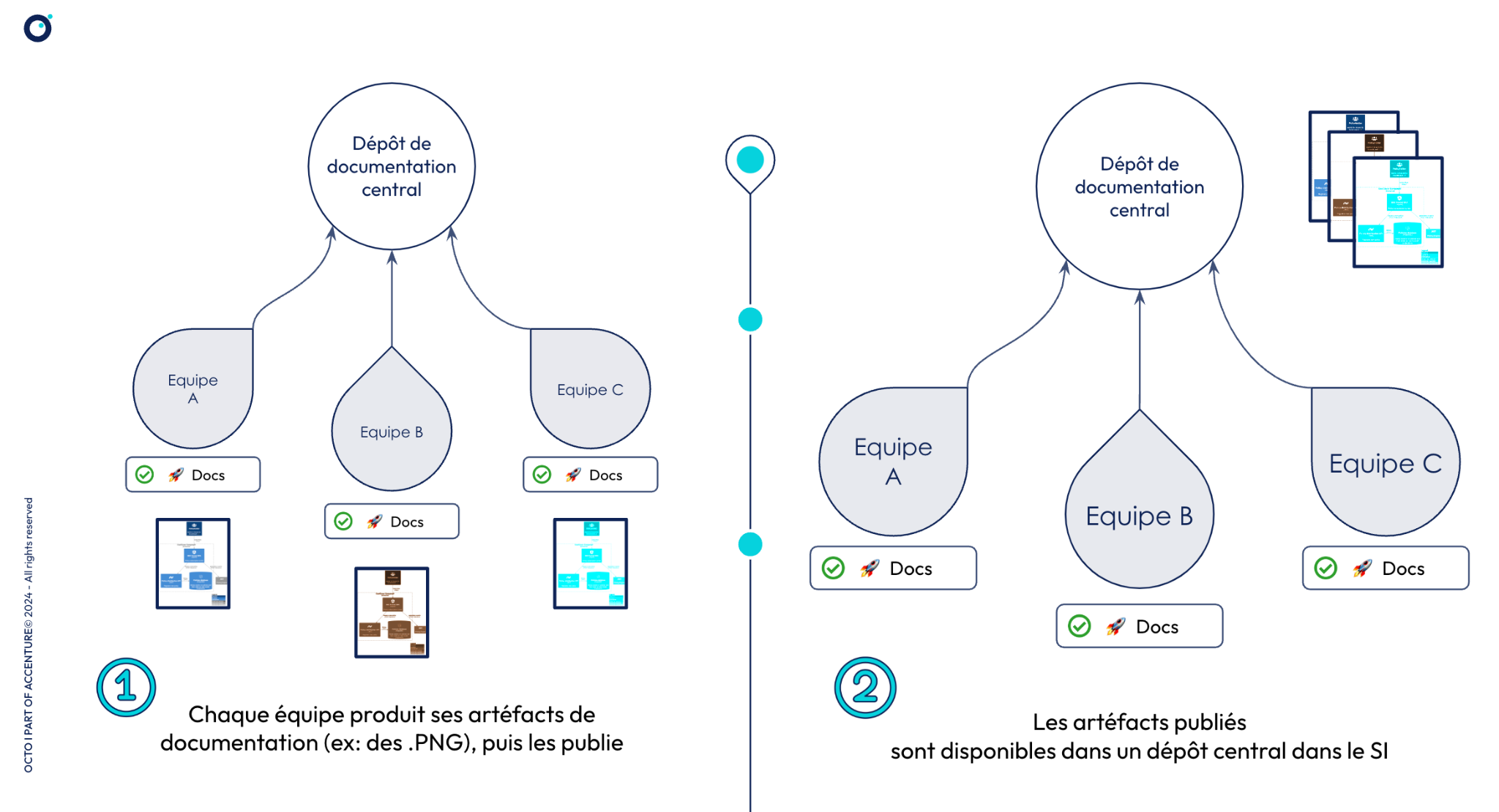
Option #3 | Autorité et autonomie: les diagrammes vivent au plus proche du code qu’ils documentent, dans le même repo
Jusqu’ici, on peut faire le constat que les avantages de la première option sont les inconvénients de la seconde, et vice-versa.
On peut évoquer alors cette 3e option : fonctionner en mono-repo, et faire vivre le code applicatif de tout le système d’information et les diagrammes as-code au même endroit.
Si cette option semble réunir le meilleur des deux premières, je ne m’étendrai pas dessus pour deux raisons. A ce jour, je n’ai jamais rencontré ce fonctionnement sur le terrain à grande échelle, et je ne pense pas qu’il soit souhaitable de réunir le code de toute une entreprise dans un seul repo uniquement pour des considérations de documentation.
On a investi pour mettre en place C4Model, mais tout le monde ne contribue pas à créer des diagrammes, est-ce que c’est grave ?
En pratique, je constate dans les différents contextes que j’ai traversés que même si un cadre est posé pour permettre à tout le monde de contribuer à la mise à jour de ces diagrammes, tout le monde ne contribue pas pour autant.
Cela peut être frustrant, mais il ne faut pas se sentir découragé pour autant. S’il est facile de mesurer la contribution à ces diagrammes (en comptant le nombre de commits ou leur fréquence, par exemple), il est plus rare de mesurer leur utilité.
Je constate qu’il y a souvent de la demande en lecture pour ces diagrammes : ils trouvent leur utilité à l’onboarding d’une nouvelle personne dans une équipe ou dans l’entreprise, ou pour avoir une vision d’ensemble d’un système au moment de prendre une décision structurante. Si ces diagrammes peuvent être utiles à tous, tout le monde ne va pas trouver l’intérêt ou se sentir légitime à éditer un diagramme.
Tout de même, il peut être sain de s’interroger sur les freins à la contribution. Au-delà de la loi de proximité évoquée plus tôt qui peut jouer un rôle, créer un repo central ou initier un fichier .puml dans un repo existant n’est pas suffisant pour qu’une dynamique de documentation prenne.
Il faut poser un cadre de gouvernance, expliciter les règles de contribution (si n’importe qui peut contribuer, levez l’ambiguité et explicitez-le pour éviter que les gens ne se censurent en cas de doute, par exemple), documenter quels sont les outils nécessaires pour contribuer et comment les installer, préciser si l’objectif de ces diagrammes est plus de poser une vision sur la cible à atteindre ou rétro-documenter ce qui a déjà été implémenté.
Créer de la confiance peut aussi aider à lancer cette dynamique. Avoir un badge connecté à un pipeline de CI minimaliste pour indiquer que le code .puml ou que le code Structurizr .dsl est actuellement dans un état syntaxiquement correct peut rassurer les potentiels contributeurs sur la qualité du code ou sur le fait que ce code n’est pas à l’abandon.
Enrichir ce pipeline pour produire automatiquement et fréquemment les diagrammes, les rendre consultables et adressables (au sens de localisé à une adresse permanente et unique, avec une url partageable à tous dans l’entreprise) peut aussi être une bonne incitation à contribuer.
Dit autrement, si le code présent sur la branche main n’est pas syntaxiquement valide quand je le télécharge, que je dois passer du temps à corriger des problèmes causés par d’autres contributeurs, et que mes efforts ne sont pas récompensés par la production automatique de diagrammes déployés et consultables via une URL, alors je trouverai peu d’énergie ou d’intérêt à collaborer dans ce cadre et je privilégierai des initiatives plus locales.
Conclusion
Avec ce second article, j’ai tenté d’examiner les questions laissées en suspens après la première partie concernant les outils pour produire des diagrammes via C4Model.
Si les questions portent initialement sur le bon outil à choisir, il est difficile de détacher cette question de celles portant sur la gouvernance ou la contribution.
Il est crucial de garder à l'esprit que la bonne approche est forcément contextuelle: nous n’avons pas tous la même échelle d’entreprise, la même culture d’entreprise, les mêmes pratiques techniques, les mêmes topologies d’équipe.
Si vous décidez d’emprunter le chemin du diagrams-as-code pour documenter votre architecture avec C4Model, j’espère que ce billet alimentera votre réflexion.
N’hésitez pas à me contacter pour échanger sur votre contexte en particulier !