Devoxx FR 2021 - Dans les 👟 de sega - Jour 1
Introduction - Dans mes 👟
Pour ce CR de la Devoxx, je parle en disant “je”, je donne mon ressenti à moi, j’essaie de retranscrire l’ambiance… De mon point de vue, l’intérêt d’un article exhaustif et objectif est réduit : il aurait fallu que j’assiste à 6 créneaux * 5 tracks * 3 jours = 90 talks ! Alors asseyez-vous confortablement, et écoutez mon histoire.
Imagine.
Nous sommes un jeudi matin de Septembre, je suis parti à 8h de chez moi, pour me frayer un chemin à vélo jusqu’au Palais des Congrès, dans le tumulte des klaxons parisiens.
Et surtout, il fait 10°C.
Une seule chose pouvait me donner l’énergie d’être là, à ce moment précis : le retour de Devoxx France.
Aparté - Devoxx, c’est quoi ?
Devoxx, c’est une conférence internationale, qui a lieu en Angleterre, en Ukraine, en Belgique, et donc également en France. Elle parle historiquement de Java, et de bien d’autres sujets tech (Big Data, DevOps, IoT, Mobile, Sécurité …) sous des formats également variés (keynote, university, quickie, tools-in-action, conférence).
8h45, à l’accueil, les visages des quelques motivés arrivés comme moi en avance sont fatigués, et laissent transparaître la même question.
“Ils sont où les croissants ??“
Pas de croissants, mais bien les grands sourires des nombreux bénévoles déjà présents.
Ne me laissant pas abattre par l’abandon de l’idée d’un petit-déjeuner, je file en Amphi Bleu, tout au bout du 2ème étage. L’objectif : avoir les meilleures places pour assister à la Keynote.
💡 Keynote - Pourquoi l'Open Data ne dispense pas de quelques notions de statistiques par Guillaume Rozier et Sacha Guilhaumou
Description du talk - Lien du replay
Jeudi est déjà le second jour de Devoxx France. Néanmoins, ce Jeudi 30 Septembre à 9h30, ce sont bien les 826 places de l'Amphithéâtre Bleu qui sont remplies.
Pourquoi ? En apprendre un peu plus sur ce projet qui a bouleversé la France durant la période COVID, et avec encore plus de force l’Open Data : covidtracker.fr
C’est tout devant, assis en plein milieu, que j’ai la chance de découvrir l’intro musicale de l’équipe des “gilets rouges” de Devoxx, remix de “Je rêvais d’un autre monde”. S’ensuit une présentation des speakers relativement inutile pour Guillaume, mais qui nous permet de découvrir Sacha, étudiant en pharmacie, et développeur Python, parce que pourquoi pas.
Sacha et Guillaume nous parlent données, donc, mais sous le prisme de leur interprétation, pour changer ! L’Open Data est fortement développée en France (cocorico), mais attention, son analyse peut parfois mener à des interprétations biaisées, et donc fausses.
Je découvre grâce à eux le biais lié aux échelles, la différence entre corrélation et causalité, le théorème de Bayes, le biais de confirmation, le paradoxe de Simpson, ou encore le biais de faible effectif.
Des maths, mais fidèles à eux-mêmes, expliqués avec pédagogie et exemples gagnants.
🍿 Conférence - L’intelligence artificielle au secours de l’accessibilité par Aurélie Vache et Guillaume Laforge
Description du talk - Lien du replay
30 minutes de pause, suffisantes pour aller dire bonjour aux copains du stand Accenture (coucou Nick !), et pour récupérer des bonbons par-ci par-là.
Et après m’être perdu dans les couloirs du Hall Paris et du Hall Neuilly, me voilà en 252 pour assister à la première conférence.
Aurélie débute le talk par une introduction sur l’IA, traduite en direct en langage des signes par Guillaume. Le ton est donné, nous parlerons accessibilité.
Le joli t-shirt Google de Guillaume et leur disclaimer “nous sommes des devs” viennent également confirmer que nous verrons aujourd’hui plus de pratique que de théorie sur l’Intelligence Artificielle.
Google donc, qui propose de nombreuses solutions sur-étagère, comme celles que Guillaume nous fait découvrir dans cette démo impressionnante de leur confection.
De son côté, Aurélie nous apporte la vision utilisateurs, à l’aide de cas d’usages intéressants et parfois surprenants.
L’Intelligence Artificielle apporte quatre outils pour aider les utilisateurs en situation de handicap, comme ceux pour qui ce n’est pas le cas (pensez rampe d’accès, ça aide tout le monde !).
- Speech-to-Text : pour transcrire un fichier audio en texte
- Text-to-Speech : pour transcrire un texte en fichier audio
- Vision : pour décrire une image
- Translate : pour traduire un texte dans une autre langue
Les cas d’usages sont tous extrêmement remarquables, mais certains me marquent plus que les autres :
- Speech-to-Text : certains téléphones récents (comme le Google Pixel) permettent de transcrire en live un appel téléphonique, à l’aide de sous-titres.
- Text-to-Speech : Numerama offre désormais sur la plupart de ses articles la possibilité de l’écouter plutôt que de le lire
Aurélie nous partage ensuite les “couacs” des outils modernes. Cela peut être une “fancy font” sur un tweet qui empêche sa lecture par un lecteur. Ou encore des appareils comme Alexa ou Siri qui reconnaissent plus facilement une voix d’homme plutôt qu’une voix de femme bègue (par exemple).
Des initiatives voient justement le jour pour contrer les biais de données : Common Voice (Mozilla), Project Euphonia (Google), SEP-28K (Apple), ou encore Voiceitt (Amazon). Le fait qu’Aurélie nous présente ces projets et les teste avec sa propre voix a un impact très fort.
🥪 BBL - Full-remote : comment réussir à travailler en équipe ? par Lise Quesnel
Description du talk - Lien du replay - Lien des slides
Retour aux stands, pour découvrir la file d’attente de 500 personnes qui attendent pour récupérer leur panier repas. Pas le temps de traîner, je file en Amphi Maillot pour le BBL qui me donnait l’espoir d’enfin bien travailler en remote.
Devant un public de 350 personnes mâchant leur sandwich, Lise se présente : développeuse chez Zenika, sur le projet de l’état Pix.fr, elle télétravaille depuis Nantes, et ce depuis 2019. Hors, 2019 c’est l’an -1 avant COVID-19, nous avons donc affaire à une pionnière !
En 15 minutes, Lise arrive à traiter les risques (solitude, flemme, équilibre pro/perso), et les clés (communication, confiance, qualité de l’environnement) classiques. Des choses simples comme dire écrire bonjour (et au revoir !), faire du pair programming, se voir de temps en temps, avoir un bon matériel sonore ...
Mais la valeur du talk réside en deux autres points.
Le premier, c’est la pyramide de la communication que nous présente Lise.
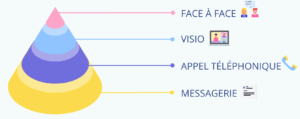
crédit : slide du talk (slides ici)
Le message derrière cette image, c’est que monter dans la pyramide est un levier pour améliorer la communication : si un quiproquo ou un malentendu s’installe, il faut monter.
Cela paraît évident, mais demande à être attentif à ceux-ci pour ne pas les laisser grandir.
Ce qui amène au second point …
… qui est l’effort nécessaire pour bien télétravailler. Oui le télétravail c’est du travail, et souvent même plus difficile, surtout au début. Le conseil de Lise est donc “faites l’effort” : de communiquer, de se rendre disponible, de mettre en place un bon environnement de travail, de jouer le jeu en fait.
🎓 University - Build a photo sharing application with Google Cloud serverless technologies par Guillaume Laforge
Description du talk - Lien du replay - Lien du codelabs
Vite vite ! En courant, j’arrive avec 30 minutes de retard au second talk de Guillaume Laforge. Bien sûr que 45 minutes n’étaient pas suffisantes pour un déjeuner au restaurant avec les copains de Vite Ma Dose ...
Heureusement, le format “Université” correspond à un TP de 3 heures, sur une technologie spécifique. J’arrive donc au début du second lab sur un total de six, et je me rassure en me disant que je pourrai rattraper le cours sur le codelabs de Google Cloud.
Pourquoi ce talk ? Parce que c’est un sujet que j’ai déjà exploré il y a deux ans, et je veux savoir où en est Google Cloud désormais.
En bon Developer Advocate et fier représentant de Google (attention, il sait aussi être critique parfois !), Guillaume fait du 100% Google Cloud durant ce talk.
Besoin d’un terminal avec les bons binaires ? Utilisons Google Cloud Shell !
Besoin d’un moteur de containers Docker et d’un registre d’images ? Utilisons Google Cloud Build et Google Container Registry !
L’application que nous produisons consiste en un site de partage de photos, qui analyse automatiquement celles-ci, entre autres traitements, tous serverless.
schéma d’architecture de notre application - source : codelabs
Cloud Functions
Le premier lab du cours a pour objectif d’analyser chaque nouvelle image ajoutée au bucket Cloud Storage, à l’aide de Cloud Functions. C’est le cas d’usage classique du serverless, celui du Functions-as-a-Service (FaaS pour les pros), bien entendu.
C’est simple, on écrit un bout de code en Node.js, qui récupère les metadata reçues en paramètre, et réalise un appel API à Cloud Vision, pour tout déposer dans une base de données Cloud Firestore.
Où est-ce que ça tourne ? Comment j’assemble mon image Docker ? Comment j’expose ma mini-API ? On s’en fiche, c’est Google qui régale. Simple, on a dit.
Attention par contre, je pense déjà à des inconvénients tout de même, comme par exemple le fait de n’avoir du feedback sur son bout de code qu’une fois déployé…
Cloud Run
Dès le second lab, on a besoin de plus de performance, plus de compute. Bref, plus qu’un bout de code qui tourne dans un mini container de 256Mb, avec un timeout au bout d’une minute.
Ici, on fait du traitement d’images, et c’est plus gourmand qu’un ou deux appels APIs. On utilise donc le service de Container-as-a-Service (CaaS, oui vous l’avez maintenant) de Google Cloud. Basé sur knative, l’outil est désormais utilisable en production, avec une haute disponibilité, depuis déjà deux ans.
Qu’avons-nous à faire désormais ? Toujours notre bout de code, et y ajouter un fichier Dockerfile qui décrit le contenu de l’image du container. Puis on mélange bien avec un gcloud run deploy, et c’est bon. Bon, ça demande un peu plus de travail, mais ça va.
App Engine
Finalement arrive le moment de faire un front pour l’application (ndlr, c’est dingue comme on néglige tout le temps le front…).
Guillaume a prévu une SPA en VueJS, parce qu’on est quand même en 2021, et la déploie à l’aide d’App Engine.
Qu’est-ce ? Un PaaS, comme le sont également Heroku, Scalingo, ou AWS Elastic Beanstalk. Et pour ceux qui ne connaissent pas le principe, c’est encore une fois très simple : tu lui donnes ton code, en précisant le langage utilisé (quoique parfois facultatif !), et le PaaS le fait tourner lui-même.
App Engine possède moins de fonctionnalités qu’un PaaS spécialisé, mais présente l’avantage d’être serverless dans sa version standard. Ce qui signifie de manière pragmatique, aucun frais si aucun visiteur n’accède au site.
Une commande plus tard, notre SPA est exposée au monde entier, en haute disponibilité.
🍿 Conférence - Choreography vs Orchestration in serverless microservices par Guillaume Laforge
Description du talk - Lien du replay - Lien des slides
Complètement amoureux du monsieur, j’enchaîne sur le dernier talk du “marathon Guillaume Laforge”. En plus, sans aucun remords, je l’assaille de questions à la fin de son university, ce qui fait que lui comme moi mangeons la maigre pause de 30 minutes.
Le premier exemple d’architecture est celui de tout bon noob des microservices : une succession d’appels à des APIs REST enchaînés. Dans ce cas-là, chaque service devient un SPOF, et il y a un couplage évident.
Je retrouve ensuite le concept de chorégraphie, relativement commun dans de nombreux projets informatiques modernes, et une solution extrêmement efficace pour découpler ses services.
Le premier service effectue sa tâche et publie un événement dans un message broker, et le suivant réagira à cet événement, pour effectuer sa tâche et publier un autre événement, et ainsi de suite.
Ça scale bien, mais il est difficile de monitorer le système dans sa globalité, et de savoir si tout notre processus métier a fonctionné.
Finalement, je découvre complètement le principe d’orchestration dans ce talk.
Alors oui, nos services sont indépendants, notre logique métier est suivie de bout en bout, on fait du REST tout simple. MAIS. Nous avons un nouveau SPOF : l’orchestrator.
Alors que choisir ? Et bien, Guillaume me répond avec un “ça dépend 🤷♂️”.
Dans tous les cas, pour l’outillage, nous sommes plus que servis sur la chorégraphie : SQS/SNS, Pub/Sub, Kafka, RabbitMQ …
En revanche, pour l’orchestration, je ne connais rien à part Apache Airflow… jusqu’à ce que Guillaume me présente Workflows.
L’outil semble très prometteur, dans l’éventualité où on veut bien faire du 100% GCP. En tout cas, Guillaume m’a convaincu avec sa démo, et avec le peu d’énergie qu’il lui restait à ce moment-là, cela en dit long sur les promesses de l’outil.
🛠 Tools-in-Action - Les phoques au secours des baleines - À la découverte de Podman par Benjamin Vouillaume
Description du talk - Lien du replay
Tout comme le speaker du talk précédent, mon énergie commence à baisser. Alors, forcément, lorsque le titre d’un talk parle d’animaux (et de devops), c’est celui-ci que je choisis.
Alors les baleines, ok c’est Docker, mais les phoques, je ne connais pas.
Pour introduire le sujet, Benjamin présente Podman : un concurrent de Docker, open source, en golang, poussé par Redhat.
J’ai instantanément l’eau à la bouche lorsqu’il nous dit que l’outil vise à être prochainement disponible sur OS X et Windows … (à l’inverse de Docker, qui devient payant sur ces systèmes).
NB : la rédaction a vérifié par la suite, Podman déclare sur le sujet
Podman presently only supports running containers on Linux. However, we are building a remote client which can run on Windows and macOS and manage Podman containers on a Linux system via the REST API using SSH tunneling.”
Puis, pour démarrer tranquillement, Benjamin nous fait une démonstration classique des fonctionnalités de Docker. docker build par-ci, docker run par-là.
Une fois celle-ci terminée, plot twist incroyable, il nous montre que sa machine n’a pas docker installé, remplacé par un subtil alias docker=”podman”...
On retrouve donc les mêmes fonctionnalités sur Podman que sur Docker, avec un CLI 100% compatible. Sur le comment, Podman s’appuie sur la spec OCI, et sur runc, son implémentation de référence.
Plus spécifiquement encore, Docker lance 3 services pour son moteur : dockerd, containerd et donc runc. De son côté, Podman n’a pas de daemon en arrière plan. Il est plus performant, et expose une surface d’attaque plus restreinte que Docker.
Et dans un dernier éclat de concentration, je retiens que Podman utilise buildah pour construire une image, et également qu’un podman generate kube permet simplement de déployer un pod avec son container.
Conclusion de la journée, et retour à la maison
A 18h, je me sens épuisé. Les talks sont tous extrêmement intéressants, on est bousculé dans ses idées, on a envie de tester plein de nouveaux outils.
Au bout de cette journée, j’ai l’impression d’en avoir vécu plusieurs.
Alors, je n’écoute pas la vicieuse culpabilité qui me rappelle qu’il reste encore un talk, je sors du Palais des Congrès en traînant les pieds et le sourire aux lèvres, et je rentre chez moi.
Sur mon vélo, je me promets une chose : je me suis assez fait plaisir avec des sujets devops sur ce premier jour, demain sera la journée des découvertes !
Mais demain, c’est un autre jour.