Développement parallèle pour des machines multi-coeur en .NET 4.0
Avec l’arrivée massive des processeurs multi-cœur, le parallélisme peut devenir une nécessité pour une application afin exploiter toute la puissance disponible d'une machine proposant ce type d'architecture. En effet, la loi de Moore, vérifiée depuis 1973, se heurte à une autre loi, celle des rendements décroissants. Le nombre de transistors à ajouter pour obtenir un gain de performance donné devient de plus en plus important, empêchant les fondeurs de continuer à augmenter la fréquence d’horloge des processeurs. Pour contourner ce problème, ils favorisent les architectures multi-cœurs. Le parallélisme peut être très impactant dans le développement d'une application, celle-ci devant être écrite et adaptée pour tirer parti du hardware.
Qu’est-ce que le parallélisme sur une architecture multi-cœur? C'est l'emploi des capacités de calculs en simultané dans un cadre déterministe. Cela consiste à prendre une tâche, la diviser en un ensemble de sous-tâches indépendantes à exécuter simultanément, le travail étant réparti sur plusieurs cœurs (la notion de concurrence, quant à elle traite de l'allocation d'une même ressource CPU pour plusieurs processus, chacun disposant à son tour d'un quantum de temps de calcul).
Dans cet article, je vais examiner comment il peut être relativement facile d’implémenter la programmation parallèle dans une application, en utilisant le Framework .NET 4.0 et sa librairie TPL (Task Programming Library).
Rappelons que l’idée principale est d’utiliser la puissance des machines multi-cœurs. Le challenge est donc de savoir comment diviser un fragment de programme en multiple unités et ce, de façon simultanée.
Je vous renvoie à un article rédigé par Olivier Roux en 2009, traitant du même sujet mais basé sur les Parallel Exentions. Le but de ce nouvel article est de faire un point sur le développement parallèle, deux ans après. Certains éléments sont rebalayés ici, d'autres clarifiés, de nouveaux sujets sont abordés ainsi que des tests de performance.
La solution existante depuis le Framework .NET 2.0 est l’utilisation d’un pool de threads. Il est composé d’un scheduler et d’une file d’attente de threads. Quand un thread a fini son travail, il est mis dans la file et est de nouveau disponible pour être capté par une opération à exécuter.
Quels sont les avantages et nouveautés de la programmation parallèle dans le Framework .NET 4.0 ? Comme premier élément de réponse, je poserai la question suivante :
- Combien de développeurs sont capables de développer une application multi-threads sans difficultés ?
Il est impossible de prédire le comportement d’un thread après sa création, d'où la complexité de ce type de développement, plutôt réservé aux développeurs chevronnés, spécialisés dans ce domaine. Les difficultés liées à la programmation parallèle sont évoquées dans un article de Sofian Djamaa.
Comment utiliser les tâches ?
Dans les version précédentes de .NET, il était complexe d'obtenir des informations sur ce qui se passait exactement après avoir mis un élément en attente dans le pool, c'était du "fire and forget".
En .NET 4.0, la librairie TPL est un moyen "simplifié" d'utiliser le pool de threads. Une tâche (Task) représente une opération asynchrone, et à certains égards, ressemble à la création d'un nouveau thread ou à un élément de travail du pool de threads (work item), mais à un niveau supérieur d'abstraction. Les tâches ont deux avantages principaux:
- Une utilisation plus efficace des ressources système: Il n'y a pas de relation 1-1 entre une tâche et un thread. Les tâches sont mises en attente dans le thread pool. Celui-ci a été amélioré à l'aide d'algorithmes (comme Hill-climbing) pour déterminer et ajuster le nombre de threads afin de maximiser le trafic. De plus, des algorithmes de type Work-stealing sont utilisés pour répartir la charge en fonction du nombre de processeurs (ou cœurs) disponibles. Le CLR 4.0 s'occupe donc de gérer le niveau de concurrence entre les threads.
- Un meilleur contrôle programmatique qu'avec les threads ou work items: La librairie TPL fournit un ensemble de fonctions de contrôle : mise en attente, annulation, gestion des exceptions et plus encore.
Exemple 1 : Création de tâches
static void Main(string[] args)
{
//Création et lancement de la première tâche
var t1=Task.Factory.StartNew(() => ProcessNumbers(10, 20));
//Création et lancement de la deuxième tâche
var t2=Task.Factory.StartNew(() => ProcessNumbers(20, 30));
//Création et lancement de la troisième tâche
var t3=Task.Factory.StartNew(() => ProcessNumbers(30, 40));
Console.ReadLine();
}
static void ProcessNumbers(int start, int stop)
{
for (int i = start; i < stop; i++)
Console.Write(" " + i);
}
Ci-dessus, je créé 3 tâches, exécutées en parallèle. Remarquons que la tâche t3 commence avant que la tâche t2 soit terminée, car l'exécution des tâches est asynchrone.

Exemple 2 : Attendre l’exécution de tâches
//Création et lancement de la première tâche
var t1=Task.Factory.StartNew(() => ProcessNumbers(10, 20));
//Création et lancement de la deuxième tâche
var t2=Task.Factory.StartNew(() => ProcessNumbers(20, 30));
//Attendons que t1 et t2 soient finies pour commencer t3
t1.Wait();
t2.Wait();
//Création et lancement de la troisième tâche
var t3=Task.Factory.StartNew(() => ProcessNumbers(30, 40));
Console.ReadLine();
}
Le code ci-dessus permet à la tâche t3 de commencer après que les tâches t1 et t2 soient finies. Ces deux tâches sont mises en attente dans le thread pool, l'appel à la fonction Wait() bloque les autres tâches jusqu'à ce que l'exécution de t1 et t2 soit terminée. J'aurais pu utiliser la méthode WaitAll() : Task.WaitAll(t1, t2), cela revient au même.

Exemple 3 : Tâche retournant un résultat
// La method MyMethod() retourne une chaîne de caractères
Task aTask = new Task(MyMethod);
aTask.Start();
Task.WaitAll();
string result = aTask.Result;
Pour que la tâche retourne une valeur, il faut utiliser la version générique Task<T>. Le paramètre T désigne le type de retour. Le type Task a une propriété "Result" qui bloque l'exécution en y accédant, je m'explique :
var task = Task.Factory.StartNew(() =>
{
Thread.Sleep(3000);
return "dummy value";
});
Console.WriteLine(task.Result);
La tâche s'exécute dans un thread séparé et prendra 3 secondes. Lorsque j'appelle "Console.WriteLine", une exception n'est pas levée même si le résultat n'est pas encore disponible. L'exécution est bloquée 3 secondes avant de continuer. Cela peut être nécessaire lorsqu'utilisé avec des tâches longues, sachant qu'elles utiliseront cette faculté de bloquer en attendant qu'elles soient terminées.
Remarque : la méthode WaitAny(t1, t2, t3...) permet d’attendre l'exécution de l'une des tâches sans se soucier laquelle.
Il est également possible d’utiliser la méthode ContinueWith(Action<Task>) pour réaliser la même chose, à savoir attendre la fin d’une tâche pour en débuter une autre. La méthode ContinueWhenAll(Task[], Action<Task[]>), quant à elle permet de spécifier quelle(s) tâche(s) attendre avant d’en commencer une autre. Plus généralement, TaskFactory contient un nombre intéressant de méthodes qui pourront vous aider dans de nombreuses occasions.
Comment paralléliser les boucles ?
L'idée est de traiter chaque itération indépendante de la boucle simultanément.
Exemple 4 : Parallel.For
Considérons une boucle for basique :
for (int i = 0; i < 200; i++)
{
if (i % 2 == 1)
Console.WriteLine(i + " ");
}
Remarquons que pour paralléliser cette boucle, la syntaxe change peu:
Parallel.For(0, 200, (i) =>
{
if (i % 2 == 1)
Console.WriteLine(i + " ");
});
Exemple 5 : Parallel.ForEach
Voici un exemple plus concret, il provient du projet CreditReview que fournit Microsoft. L’idée est d’identifier les comptes à risque s’ils ont excédé leur limite de crédit les mois précédents. Le statut de crédit de chaque client ne dépend pas du statut d’un autre.
Boucle séquentielle :
static void UpdatePredictionsSequential(AccountRepository accounts)
{
foreach (Account account in accounts.AllAccounts)
{
Trend trend = SampleUtilities.Fit(account.Balance);
double prediction = trend.Predict(
account.Balance.Length + NumberOfMonths);
account.SeqPrediction = prediction;
account.SeqWarning = prediction < account.Overdraft;
}
}
Boucle parallèle :
static void UpdatePredictionsParallel(AccountRepository accounts)
{
Parallel.ForEach(accounts.AllAccounts, account =>
{
Trend trend = SampleUtilities.Fit(account.Balance);
double prediction = trend.Predict(
account.Balance.Length + NumberOfMonths);
account.ParPrediction = prediction;
account.ParWarning = prediction < account.Overdraft;
});
}
Une telle construction gère de façon dynamique l’augmentation et la réduction du nombre de threads, suivant la charge disponible sur chaque cœur, impliqués dans les opérations de façon à déterminer le nombre de threads optimal pour une charge de travail donnée.
L’avantage par rapport à la gestion classique de threads pour le développeur est de lui épargner de coder des solutions de partitionnement des charges de travail, celui-ci pouvant se concentrer sur la logique métier.
Optimisation des boucles
Dans la pratique, quand plusieurs boucles sont imbriquées, il n’est pas nécessaire de paralléliser boucles externe et boucles internes, la boucle externe suffit. En effet, celle-ci offre de plus grandes unités de travail à paralléliser, diluant la surcharge due au mécanisme de synchronisation des threads.
Une autre optimisation est l’emploi d’une valeur locale. Le problème est le suivant : supposons que nous voulions additionner la racine carré d’un nombre dix millions de fois. Le calcul est parallélisable sans problème, mais additionner les valeurs devient gênant car nous devons verrouiller la mise à jour du total :
Exemple 6 : Lock, optimisation avec une valeur locale
object locker = new object();
double total = 0;
Parallel.For (1, 10000000,
i => { lock (locker) total += Math.Sqrt (i); });
Dans le code ci-dessus, le gain du à la paralléisation est contrebalancé par le coût de 10 millions de locks, dont nous n’avons pas besoin.
object locker = new object();
double grandTotal = 0;
Parallel.For (1, 10000000,
() => 0.0, // Initialisation de la valeur locale.
(i, state, localTotal) => // Le délégué invoqué pour chaque itération
localTotal + Math.Sqrt (i), // Il retourne la nouvelle valeur locale.
localTotal => // Ajout de la variable locale
{ lock (locker) grandTotal += localTotal; } // à la valeur globale.
Certes, il y a toujours des locks mais seulement pour la somme grandTotal += localTotal, ce qui est beaucoup plus efficace que la version précédente.
Exemple 7 : Degré de parallélisme
Il s'agit de limiter le nombre de cœurs à utiliser dans une exécution.
var options = new ParallelOptions();
options.MaxDegreeOfParallelism = Math.Max(Environment.ProcessorCount / 2, 1);
Parallel.For(0, pixelData.GetUpperBound(0), options, row =>
{
for (int col=0; col < pixelData.GetUpperBound(1); ++col)
{
pixelData[row, col] = AdjustContrast(pixelData[row, col], minPixel, maxPixel);
}
});
Bien souvent, la configuration par défaut convient, mais dans certains cas il peut être utile d’utiliser un sous-ensemble des cœurs disponibles. En pratique, cela limite le nombre d’opérations simultanées, qui peut être intéressant si nous exécutons un processus long, nous ne voulons pas multiplier les requêtes sur le serveur en même temps. Le serveur lui-même peut ne pas être en mesure de toutes les traiter et étonnamment se retrouver surchargé (le principe d’une attaque DOS).
PLINQ
L’une des autres avancées du Framework .NET 4.0 en matière de parallélisme est le Parallel LINQ (PLINQ). Son utilisation est identique à LINQ-to-Objects et LINQ-to-XML. Tous les opérateurs de requêtes du C# 3.5 sont disponibles. Les requêtes LINQ-to-SQL et LINQ-to-Entities sont toujours exécutées par les bases de données, donc non parallélisable par PLINQ.
PLINQ s’avère utile pour les requêtes nécessitant une grande quantité de calcul. Il est aussi possible d’interroger simultanément plusieurs sources de données (bases de données, fichier XML…) après avoir été chargées en mémoire.
Exemple 8 : de LINQ à PLINQ
Une requête simple LINQ
IEnumerable data = ...;
var q = data.Where(x => p(x)).Orderby(x => k(x)).Select(x => f(x));
foreach (var e in q) a(e);
En PLINQ
IEnumerable data = ...;
var q = data.AsParallel().Where(x => p(x)).Orderby(x => k(x)).Select(x => f(x));
foreach (var e in q) a(e);
PLINQ exécute les clauses Where, OrderBy et Select de manière transparente sur tous les coeurs disponibles. La technologie Parallel Linq, qui est un sujet à part entière, ne sera pas plus détaillée volontairement.
Comment débugger?
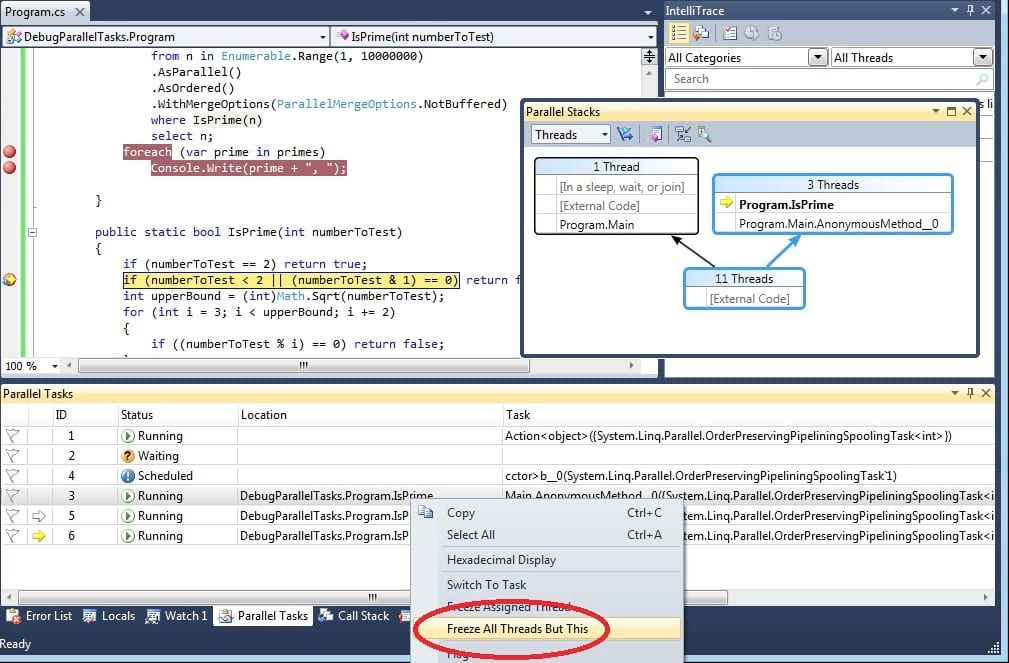
Pour parcourir unitairement en mode pas-à-pas chaque thread, Visual Studio 2010 possède une fenêtre dédiée : Debug -> Windows -> Parallel Tasks. Il est possible de freezer les tâches, de switcher entre-elles. Visual Studio identifiera les deadlocks et vous dira quelles sont les deux threads mis en cause et quel objet elles attendent.
Nous pouvons aussi afficher une représentation graphique des threads exécutés : Debug -> Windows -> Parallel Stacks.
Gestion des exceptions
Il est possible de gérer les exceptions, en effet, celles-ci sont stockées dans une tâche et sont levées lorsque toutes les tâches sont terminées. Les exceptions ne sont jamais perdues et correctement propagées. Pour les propager au thread appelant, elles sont encapsulées dans une instance AggregateException. Elle peut énumérer, examiner toutes les exceptions qui ont été levées individuellement.
Exemple 9 : AggreagateException
var task1 = Task.Factory.StartNew(() =>
{
throw new MyCustomException("mon exception");
});
try
{
task1.Wait();
}
catch (AggregateException ae)
{
foreach (var e in ae.InnerExceptions)
{
if (e is MyCustomException)
{
Console.WriteLine(e.Message);
}
else
{
throw;
}
}
}
Et les performances ?
La première démo illustrant le gain de performances de la programmation multi-cœurs en .NET 4.0 est une multiplication de deux matrices de même dimension et le calcul du résultat dans une troisième. Cet exemple est un bon candidat pour le parallélisme car nécessitant beaucoup de calculs.
Je fais cette opération tout d’abord en mode séquentiel, puis en mode parallèle et je compare le temps d’exécution de chacun des deux modes.
Exemple 10 : multiplication de matrices
Ci-dessous le code d’initialisation des matrices :
static double[,] InitializeMatrix(int rows, int cols)
{
double[,] matrix = new double[rows, cols];
Random r = new Random();
for (int i = 0; i < rows; i++)
{
for (int j = 0; j < cols; j++)
{
matrix[i, j] = r.Next(100);
}
}
return matrix;
}
La boucle séquentielle:
static void MultiplyMatricesSequential(double[,] matA, double[,] matB,
double[,] result)
{
int matACols = matA.GetLength(0);
int matBCols = matB.GetLength(0);
int matARows = matA.GetLength(0);
for (int i = 0; i < matARows; i++)
{
for (int j = 0; j < matBCols; j++)
{
double temp = 0;
for (int k = 0; k < matACols; k++)
{
temp += matA[i, k] * matB[k, j];
}
result[i, j] = temp;
}
}
}
Et la boucle parallélisée:
static void MultiplyMatricesParallel(double[,] matA, double[,] matB, double[,] result)
{
int matACols = matA.GetLength(1);
int matBCols = matB.GetLength(1);
int matARows = matA.GetLength(0);
// Multiplication des matrices
// Parallélisation de la boucle externe pour partitionner
//la matrice source par ligne.
Parallel.For(0, matARows, i =>
{
for (int j = 0; j < matBCols; j++)
{
double temp = 0;
for (int k = 0; k < matACols; k++)
{
temp += matA[i, k] * matB[k, j];
}
result[i, j] = temp;
}
});
}
La machine sur laquelle les tests sont effectués embarque un processeur Intel Core i7 Quad-Core HT.
Les résultats sont logiquement ceux espérés.
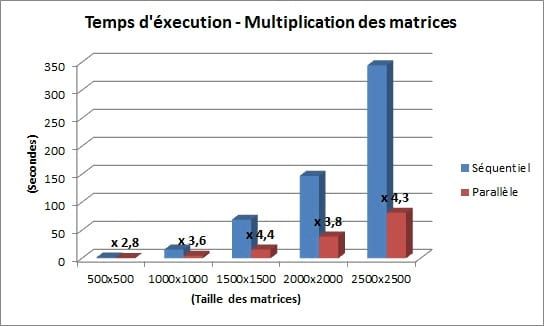
J'ai fait varier la taille des matrices [n,n], n prenant respectivement les valeurs 500, 1000, 1500, 2000, et 2500.
Dans les tests en mode parallèle, le pourcentage d’utilisation du CPU est toujours monté à 100% :
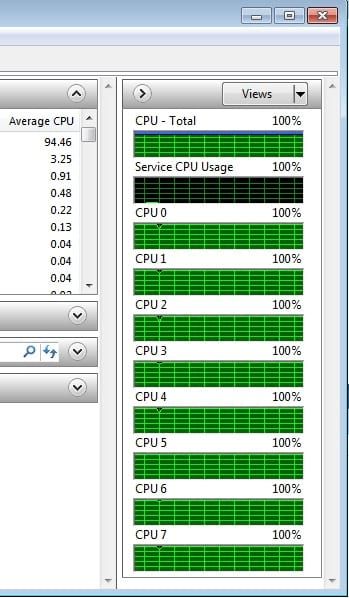
Il est resté bloqué à 12% en mode séquentiel. Cela s’explique par la nature du processeur, Quad-Core en effet, mais 8 threads (avec le support de l'HyperThreading).
En tirant parti de la librairie TPL du Framework .NET 4.0, le temps d’exécution peut même être divisé par un facteur supérieur à 4, en mode parallèle. Ce résultat peut sembler étonnant, nous devrions avoir un gain de performances théoriques inférieures à 4 (car quatre cœurs). En effet, dans l’OS, d’autres applications tournent en arrière-plan. Le mécanisme de synchronisation des threads doit aussi prendre un peu de puissance de calcul. Ceci reflète sans doute l’amélioration des performances due au mode HyperThreading du processeur.
Exemple 11 : BabyNames
La deuxième démo utilise PLINQ cette fois. C'est la démo BabyNames du training kit Visual Studio 2010. Les coordonnées d'individus d'une population sont chargées en mémoire (250 Mo), une requête LINQ ou PLINQ est exécutée suivant le mode désiré. Elle recense le nombre de naissances par année, pour un nom/prénom choisi.
J'obtiens les résultats suivants, en faisant varier le nombre de cœurs :
| Nombre de cœurs | LINQ (temps en secondes) | PLINQ (temps en secondes) | Amélioration |
| 0,5 (1 thread) | 12,55 | 13,71 | x 0,92 |
| 1 | 12,55 | 7,38 | x 1,70 |
| 2 | 12,55 | 4,27 | x 2,94 |
| 3 | 12,55 | 3,53 | x 3,56 |
| 4 | 12,55 | 2,91 | x 4,31 |
Les résultats sont à peu près du même ordre que dans l’exemple précédent. Il est intéressant de noter que notre processeur étant HT, le programme détecte 8 cœurs. Nous pouvons donc sélectionner très finement le degré de parallélisme voulu. Nous observons que la requête PLINQ exécuté sur un seul thread d’un unique cœur est presque aussi rapide que la même requête LINQ.
La programmation parallèle est longtemps restée le domaine de développeurs spécialisés. Il semblerait que cela soit en train de changer dans le monde .NET, et c’est plutôt une bonne nouvelle. En effet, le gain de performances que la librairie TPL peut apporter est à prendre en compte dans le développement d’une application ou d’un composant de celle-ci.
Le parallélisme à la sauce Microsoft inclus dans le Framework .NET 4éme mouture est certes une surcouche encapsulant elle-même les mécanismes plus bas niveau du parallélisme, j’entends déjà les puristes de la manipulation du thread crier au scandale. Néanmoins, le développement d'une application multi-threadée est grandement simplifié et peut demander peu d’efforts à condition que les algorithmes soient facilement parallélisable, y compris pour adapter un code déjà existant.
Notons que le C# 5 Async doit apporter un lot de nouveautés, qui, combinées avec la librairie TPL, devraient être intéressantes pour les opérations asynchrones.