Des alternatives aux bases de données relationnelles…

L’avènement du Cloud et la transparence (maitrisée) de ses acteurs nous permet de découvrir quelques-uns systèmes mis en œuvre chez des acteurs comme Amazon ou Google. Les offres de type SimpleDB, Google Data Store nous font certes rêver mais permettent également de découvrir des solutions utilisées en interne des grands sites web avec par exemple la BigTable du côté de Google ou bien Dynamo du côté d’Amazon.
Ces systèmes innovants ont été développés sur mesure pour répondre à des enjeux de charge quasi hors normes (à titre d’exemple, pour eBay, on parlait il y a quelques années de 1 milliard de pages vues et de 44 milliards de requêtes par jour) tout en étant fortement adaptés aux spécificités de chacune de ces plateformes et de leur utilisation : Amazon et eBay – avec des notions de stock, facturation, consultations et recherches de produits… - utilisant leur espace de stockage de façon différente de Google – qui propose un moteur de recherche - .
Ainsi et sous ces contraintes, ces systèmes n’ont eu d’autres choix que d’évoluer, d’innover et ces acteurs ont investi et développé des espaces de stockage surprenants et en rupture avec nos modèles de stockage relationnel : de « simples » structures distribuées dans lesquelles la donnée est globalement stockée sous la forme clé/valeur. Mais des systèmes équivalents ou du moins proposant des concepts similaires sont également disponibles sous la forme d’outils Open Source que l’on peut déployer dans nos SI.
« BigTable-like systems » ou une vision multidimensionnelle de l’espace de stockage : l’approche Google
Les systèmes de type « Big Table » également nommés « Column Oriented DataBase » permettent d’avoir plusieurs dimensions de stockage et d’analyse de la donnée tout en répartissant le stockage sur plusieurs machines. A titre d’exemple, BigTable peut être vue comme un map multi-dimensionnelle
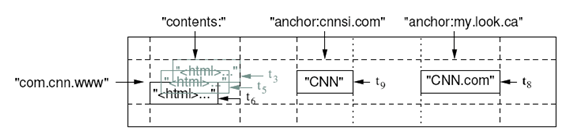
Source : http://labs.google.com/papers/bigtable.html
Une première dimension correspond à la ligne. Cette ligne est identifiée dans notre exemple par la clé com.cnn.www et l’ensemble des clés est trié par ordre lexicographique. Ainsi, le contenu associé aux clés les plus proches (ex. com.cnn.topics et com.cnn.www dans notre exemple) est regroupé. Les lignes sont ensuite regroupées en « tablets » qui sont une unité de répartition. La seconde dimension qui correspond aux colonnes (qui peuvent être regroupées en famille de colonnes) représente un autre axe de lecture (également indexé). Par exemple, le ou les langages dans lesquels la page a été écrite, les pages référençant l’élément courant (l’élément « anchor » dans notre exemple).
Le monde open source n’est pas en reste avec des alternatives comme (sans être exhaustif) HBase (en relation avec le moteur Map-Reduce Hadoop intégré chez AWS) ou Hypertable qui se veut une implémentation de la BigTable de Google.
Quand au monde du Cloud, Google offre son service de stockage BigTable au travers de leur Google DataStore. Un modèle non relationnel qui demande de prendre en compte les quelques éléments suivants :
- Google Data Store offre un modèle « fortement consistent » et se base sur un mode de concurrence optimiste; ie. pendant qu’une application met à jour la donnée, les autres mises à jour échouent immédiatement
- Chaque entité est représentée par une liste de propriétés qui peuvent être optionnelles et multi-valuées. Les entités sont regroupées au sein d’« entity group » et les entités peuvent être reliées entre elles dans un mode parent-child ; ce qui offre une modélisation hiérarchique.
- La gestion des transactions est assurée. Une limite tout de même puisque la transaction ne peut être garantie que sur un « entity group »
- La gestion des relations est supportée et distingue deux cas : (1) le cas « owned relationship » où les objets ne peuvent pas vivre l’un sans l’autre (une composition au sens UML) et où ces derniers seront stockés dans le même « entity group » et (2) le cas « unowned relationship » qui permet de référencer des objets d’autres « entity group ».
- Le dataStore de Google est accessible via JPA ou JDO (avec quelques subtilités néanmoins…)
« Key-value Stores » : l’approche Amazon
Sur un modèle plus simple à appréhender que le modèle précédent, ce type d’espace de stockage permet de voir les objets sous la forme de clé/valeur et de stocker, telles quelles (sous une forme binaire ou textuelle suivant les cas et les implémentations) et donc selon une dimension (la clé) les « instances ». Cette catégorie est riche de prétendants et l’on peut ainsi noter :
- Tokyo Cabinet dont la blogosphère parle de plus en plus et qui propose différents produits, une base de données key/value, un moteur de recherche full text et une partie (Tyrant) permettant la réplication entre serveurs et accessibilité via le protocole memcached et http.
- Cassandra qui est utilisé par Facebook.
- Simple DB. Simple DB est la réponse d’Amazon en termes de solution de stockage à forte scalabilité. A l’instar du Google Data Store, SimpleDB modélise ces entités en « Domain ». Chaque « Domain » est constitué de « Data Item » (que l’on peut apparenter à une ligne dans le monde relationnel) et chaque « Data Item » est composé d’un ensemble d’attributs (assimilable à une colonne d’une table dans les bases relationnelles). Une certaine souplesse est possible au niveau du schéma ce qui permet de stocker tout ou partie des propriétés, mais sous forme de chaîne de caractère uniquement.
- Voldemort : l’alternative Open Source. Il est difficile de savoir si SimpleDB est construit sur le système de stockage interne Amazon Dynamo mais dans l’hypothèse où ces alternatives vous fassent rêver au point ou vous voudriez un tel espace de stockage chez vous (déjà, appelez moi parce que ca me brancherait bien de bosser avec vous sur le sujet...), Voldemort est une alternative sérieuse. Cette solution dont le nom s’inspire peut-être (je n’ai pas su percer ce mystère) de la saga Harry Potter, est utilisée chez LinkedIn.
Mais les approches types SimpleDB et Voldemort se différencient de l’approche choisie par Google car. Tout d’abord, (1) ces solutions proposent un modèle éventuellement consistent . Autrement dit, ces systèmes sont architecturés pour garantir de bonnes performances en écriture (il faut que le client puisse valider sa commande le plus rapidement possible, quelques soient les pannes) sur des systèmes soumis aux charges évoquées précédemment, la réconciliation se faisant au moment de la lecture (mode « Read-Repair »). Il y a deux « inconvénients » ou plus exactement changement de « mindset » liés à cette approche. Le premier est le risque (ou la quasi certitude) d’avoir plusieurs versions du même objet. Le second est de ne pas garantir qu’une lecture consécutive à la mise à jour d’une donnée retourne la donnée à jour (d’où le caractère « éventuel » de la consistance). Ensuite (2) l’absence de gestion d’atomicité des opérations (et donc par extension de transaction). Enfin (3), SimpleDB est accessible par des APIs type REST ou SOAP (même s’il existe des Apis client Java masquant les accès ).
Des modèles non relationnels qui posent de nouveaux de nouvelles contraintes
Ces approches proposent un modèle moins structuré et bien entendu non relationnel. Des alternatives qui soulèvent de nouveaux points d’attention. Au niveau des développements tout d’abord :
- Là ou le modèle relationnel cherche à normaliser la donnée pour éviter duplication et faciliter la gestion des relations entre entités, le modèle clé/valeur n’offre rien. Autrement dit, les relations entre entités ne sont pas (ou peu) gérées - explicitement par le moteur de base - et rien n’exclut les possibles doublons de données. Autrement dit, impossible de s’appuyer sur le moteur pour garantir l’intégrité de la donnée ; il vous faudra la gérer au niveau de l’espace applicatif
- En terme d’API, le modèle clé/valeur est ultra simpliste puisqu’il ne propose pas d’équivalent au langage SQL. Ainsi les seules APIs dont vous disposerez sont PUT, GET, DELETE et les recherches multicritères seront à remplacer – ce n’est pas anodin en terme d’architecture - par des recherches « full-text ». Au mieux vous disposerez de quelques possibilités de filtres sur les valeurs des champs (par exemple = ; != < …). De même, pour les notions de jointures, triggers, procédures stockées…tout remonte dans l’espace applicatif avec comme impact sur les architectures une orientation vers plus d’évènementiel
- Quid de la génération des clés. En effet, tout est clé mais ces systèmes ne mettent à disposition aucun mécanismes de génération de clé…Au revoir belles séquences, bonjour service de génération d’identifiants.
Au niveau de l’administration des bases ensuite :
- Concernant les migrations de données. Ces solutions (sauf erreur de ma part) ne proposent pas de fonctionnalités d’extraction et la migration d’un système à un autre risque de ne pas être évidente. Cela risque d’être d’autant moins évident que sans parler de standard, SQL est supporté par l’ensemble des éditeurs (avec certes des limites, des fonctions spécifiques…). Ce n’est pas le cas de ces solutions qui ne partagent pas de « socle commun ».
- Gestion des backups. Là encore (et sauf erreur de ma part), ces solutions divergent de nos traditionnelles bases de données relationnelles en ne proposant, « out-of-the-box » , aucun mécanisme de backup. Pour les services Cloud fournis (type SimpleDB ou DataStore), on peut imaginer que le « provider » est garant de la réplication des données (entre Data Center ou « availability zone » notamment). Pour des solutions utilisables en interne et même si cela dépend des implémentations, il est possible de paramétrer différents moteur relationnel (BDB, MySQL…) pour le stockage physique de la donnée. On peut donc imaginer utiliser les mécanismes de backups classiques (la contrainte devenant le nombre d’instances qu’il faut « backuper »)
Mais paradoxalement, ces contraintes sur le modèle de données me semblent avoir des vertus sur les architectures applicatives. Nous l’avons évoqué à maintes reprises mais tous les objets sont identifiables par une clé et les seules APIs disponibles sont PUT/GET/DELETE. Pas très loin de certains préceptes REST en quelques sortes. Des contraintes qui finalement auront pour bénéfices de rendre vos services ultra –simples et limpides :
- Les signatures vont se limiter à un paramètre qui est l’identifiant de l’objet.
- L’absence de requêtes complexes qui imposera des recherches « full-text » va simplifier encore les signatures de services de recherches (plus de multi-critères qui évoluent dans le temps…).
- Des possibilités de versionning plus simple puisque la signature sera identique
De même, là ou le modèle relationnel impose un certain niveau de modélisation des concepts métiers, niveau de modélisation qui a permis à certains systèmes de partager l’espace de données, l’approche clé/valeur va pousser au développement d’un émissaire (APIs de service) visant à encapsuler un Domain Model propre et un minimum partageable (ie. pas trop adapté à une application unique), bref à vous mettre dans une dynamique de services pour conserver un minimum de maitrise sur ce modèle de données.
Pour conclure…
Il est intéressant de constater que ce type de stockage nous met d’office dans un modèle non relationnel : ce à quoi on arrive (dans une moindre mesure) lorsqu’on cherche à optimiser les performances d’une application (et notamment de ses requêtes). Cette dénormalisation à outrance imposée par ces systèmes permet d’avoir des requêtes efficaces, faciliterait le partitionnement et la réplication de la donnée au travers d’une ferme de serveurs de bases de données.
Remarquons néanmoins que nous utilisons déjà des systèmes non relationnels. Nos systèmes traditionnels mettent assez rapidement et systématiquement en œuvre des caches au dessus des modèles relationnels ; des solutions qui visent à optimiser les temps de réponse (a minima en lecture) et qui se limitent, au final, à un système de stockage clé/valeur.
Dès lors se pose la terrible question : « à quel moment faut-il se passer d’un modèle relationnel ? ». Difficile art que d’y répondre en ces quelques lignes mais l’on peut déjà noter les éléments suivants :
- Les niveaux importants de charge auxquels sont soumis les systèmes. Typiquement si vos systèmes tapent des limites en écriture, ont déjà mis en œuvre des mécanismes de réplication master/slave pour soulager le master des lectures, ce sont peut-être des alternatives à étudier et qui vous permettrons de dépasser vos limites de scalabilité tout en tentant de maîtriser vos coûts
- Les autres axes différentiants sont liés aux niveaux de relationnel du modèle. Par exemple un modèle en forme d’arbre ou qui propose énormément de relation many-to-many sera difficile à dénormaliser. A l’inverse, certaines applications se contentent se stocker de l’information non structurée (les dernières versions d’Oracle propose le type XML Type permettant de stocker des valeurs de types XML…). Ou encore dans le cas de certains cas d’utilisation (typiquement des Batchs) où des tables de travail et la dénormalisation sont souvent mises en œuvre.
- Enfin, le « confort des développements » et dans ce cadre, il s’agira de savoir jusqu’à quel point vous souhaitez vous appuyez sur la base de données pour gérer tout ce qui est contraintes d’intégrité, les mécanismes de backup…
Et puis se limiter aux approches « clé/valeur », c’est oublier d’autres types de base de données comme les systèmes orientés document qui permettent de stocker des informations structurées et offrent des fonctionnalités de requêtages plus riches (Base XML, Mongo DB ou bien encore les systèmes orientés graphe comme Neo4j qui sont à l’inverse optimisés pour des modèles hyper hiérarchiques…
Je reste néanmoins intimement convaincu que ces systèmes offrent de vraies alternatives à ce que nous connaissons. Mais dire que la migration sera simple serait mentir. C’est tout un univers qui s’ouvre, des compétences à développer, des limites et des cas d’usages à trouver. Puis comme dirait l’autre, vous n’avez peut-être pas de problèmes avec vos bases de données relationnelles. Alors pourquoi migrer ? A défaut de trouver ces solutions dans nos systèmes, les connaitre ne peut que nous nous aider à mieux utiliser les offres de stockage du Cloud comme SimpleDB ou Google Data Store et ainsi mieux comprendre les limitations et les impacts sur les architectures applicatives. Bref, un beau challenge…
Addendum : A peine ce document rédigé que Amazon annoncait son service RDS : une base de données relationnelle (mySQL) avec la possibilité de scalabilité verticale (AWS propose différente puissance de machines). Dans tous les cas, un service pertinent qui limitera fortement l’adhérence aux services spécifiques du providers.