Déployer ses application dans Kubernetes avec des secrets Vault
Dans cet article, nous allons tenter d’alimenter une discussion que nous entendons régulièrement et qui commence comme ceci : «
- Et du coup, on peut baser les secrets Kubernetes sur du Hashicorp Vault ?
- Heu, non, pas vraiment, soit on utilise les secrets Kubernetes pour mettre ses données sensibles, soit on s’appuie sur Vault pour ça.
- Ah, d’accord, du coup, si je veux mettre mes données sensibles dans Vault, je ne dois plus utiliser les secrets Kubernetes ?
- C’est ça, il y a clairement double-emploi.
- Et c’est facile à mettre en œuvre Vault dans mes applications dans Kubernetes ?
- Heu, ça dépend, elles sont déjà adaptées pour utiliser Vault ?
- Non. Ça veut dire qu’il faut adapter toutes applications ?
- Pas forcément, tu comptes gérer des secrets dynamiques ?
- Non, pas pour le moment.
- Alors dans ce cas-là, laisse-moi te montrer une façon de faire, sans toucher à tes applications…
»
Un peu de théorie
Pour mettre en œuvre ce mécanisme, nous allons devoir nous appuyer sur plusieurs concepts :
Kubernetes
Nous n’allons pas ici décrire ici le but de Kubernetes, simplement rappeler qu’il s’agit d’un orchestrateur de conteneurs (Docker en premier lieu). Son but est simplement d’exécuter des applications sur une flotte de machines. Les applications hébergées ont généralement besoin d’être configurées, et Kubernetes propose des mécanismes d’injection de paramètres, via des fichiers de configuration ou des variables d’environnement.
Hashicorp Vault
Pour simplement résumer l’objectif de Vault, décrivons-le comme un coffre-fort à secrets accessible au travers d’une API. Les secrets sont organisés dans des structures hiérarchiques et des mécanismes d’authentification et d’autorisation permettent d’en contrôler les accès. Des mécanismes d’audit permettent de tracer les accès (en lecture et en écriture) sur les secrets. Si vous ne connaissez pas du tout Vault, n’hésitez pas à jeter un coup d’œil à cet article qui décrit - dans sa première partie - son fonctionnement.
La méthode d’authentification Kubernetes de Vault (dite Kubernetes Auth Method)
« Montre-moi un token Kubernetes, je te donnerai un token Vault… »
Cette brique permet de faire le lien entre les identités Kubernetes et les identités Vault. Elle valide les tokens Kubernetes et offre en échange un token Vault. Ce dernier point est relativement important, un token Kubernetes n’est pas directement utilisable dans Vault.
Le token Kubernetes est un token JWT que chaque pod (le concept logique qui enveloppe des conteneurs applicatifs dans Kubernetes) peut obtenir simplement (un fichier déposé dans le pod). Ce token est associé à un serviceAccount qui au sein d’un namespace porte l’identité du pod.
La configuration de ce module implique de créer dans Kubernetes un compte (un serviceAccount à nouveau) qui est autorisé à valider les tokens Kubernetes.
Consul-template
S’il est un outil de la galaxie Hashicorp qui porte mal son nom, c’est bien celui-ci. Il serait bien plus judicieux de le nommer hashicorp-template. Et pour cause, l’usage que nous allons en faire ici n’a rien à voir avec Consul. Le principe de cet outil est de générer des fichiers à partir de templates. Les templates font référence à des données qui sont issues de Consul (d’où son nom), mais aussi de Vault et c’est cette dernière caractéristique qui nous intéresse pour la suite.
Architecture cible
Nous allons chercher à déployer une application dont un fichier de configuration est généré sur la base d’un template, dont le contenu est en partie issu de Vault (pour représenter les données sensibles), et en partie de configMap Kubernetes classiques (pour représenter la partie non sensible de la configuration de notre application). L’objectif est d’utiliser l’image d’une application sans la modifier. Pour ce faire, nous allons utiliser le mécanisme des initContainers qui permet de lancer des conteneurs en phase d’initialisation d’un pod, en vue d’en préparer le démarrage.
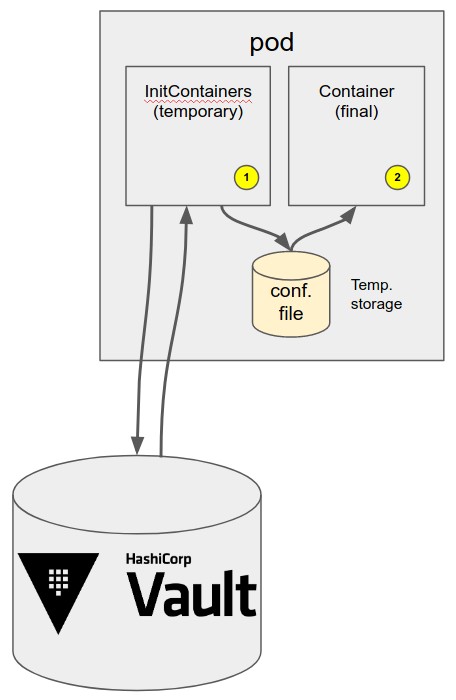
La cinématique (simplifiée) du démarrage se décompose comme suit :
- Un premier conteneur temporaire et à durée de vie limitée (un initContainer) s’authentifie auprès de Vault, récupère les secrets permettant de générer les fichiers de configuration et les dépose dans un répertoire de travail partagé avec le conteneur final. Les initContainers n’ont pas vocation à rester résidents (à l’opposition des sidecars) et s’arrêtent dès qu’ils ont fini leur travail.
- L’arrêt (avec un code de retour 0) de l’initContainer déclenche le démarrage du conteneur applicatif qui va trouver le fichier de configuration généré dans son système de fichiers comme si de rien n’était.
Mise en pratique
En pratique, les choses sont un peu plus compliquées car consul-template ne sait pas directement s’authentifier avec un token Kubernetes. Il faut une première étape pour échanger auprès de Vault un token Kubernetes en token Vault. Et ce n’est qu’après cette première étape que consul-template peut faire son travail.
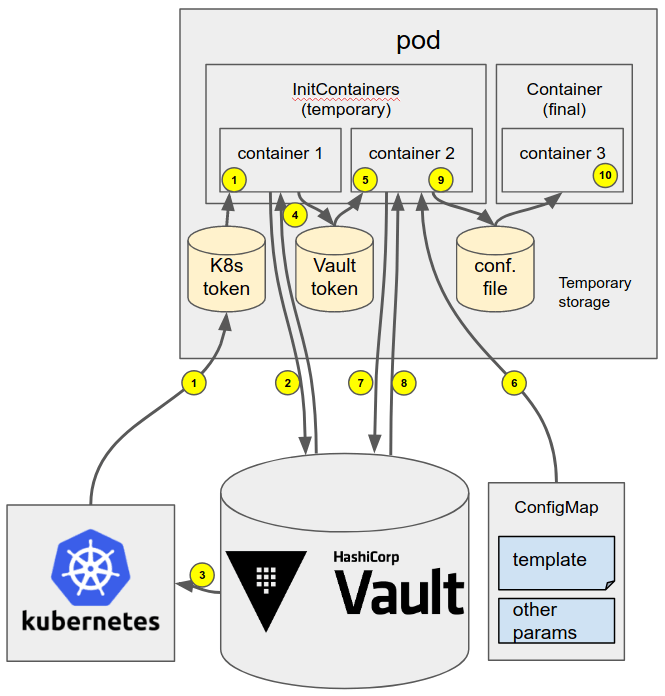
Si on regarde la cinématique complète, elle est composée des étapes suivantes :
- Kubernetes démarre le pod qui va faire tourner notre application. Il injecte un token correspondant au serviceAccount qui exécute le pod dans le système de fichiers de tous les conteneurs, mais c’est surtout dans le premier que cela nous intéresse.
- Le premier conteneur a pour unique objectif d’obtenir un token Vault valide en fournissant son token Kubernetes. Il soumet donc son token Kubernetes au serveur Vault qui a le module d'authentification Kubernetes activé.
- Vault vérifie la validité du token auprès de Kubernetes. À noter que Vault lui-même s’authentifie auprès de Kubernetes avec un serviceAccount lui permettent d’effectuer les vérifications de tokens. Vault obtient de la part de Kubernetes l’identité du demandeur (basé sur le nom du namespace et le nom du serviceAccount) et vérifie qu’un rôle Vault fait bien le lien avec cette identité demandée.
- Vault retourne un token Vault. Le conteneur écrit simplement le token retourné dans un fichier partagé avec le conteneur de l’étape suivante. Il s’arrête juste après.
- Le conteneur suivant (consul-template) démarre. Il a pour but de générer le fichier de configuration de l’application.
- Il récupère le template qui lui a été injecté par une configMap. Le template peut faire référence soit à des variables présentes dans la configMap, soit à des secrets stockés dans Vault.
- Le conteneur fournit à Vault le token stocké en étape 4 en vue de récupérer les secrets de l’application.
- Vault vérifie le token Vault fourni et le confronte aux autorisations Vault. Il retourne les secrets si une policy Vault autorise le détenteur du token Vault à accéder aux secrets demandés, via le rôle Vault validé en étape 3.
- Le conteneur récupère les secrets et peut finir de générer le fichier de configuration. Il s’arrête dès que celui-ci est généré dans une zone temporaire partagée avec le conteneur applicatif.
- L’application peut enfin démarrer et trouve son fichier de configuration.
À noter que deux options sont possibles pour effectuer la première étape d’échange du token Kubernetes en token Vault : Utiliser un simple cURL ou s’appuyer sur des images Docker spécialisées dans ce travail. La version cURL pourrait ressembler à cela :
<br>$ KUBE_TOKEN=$(cat "/var/run/secrets/kubernetes.io/serviceaccount/token")<br>$ VAULT_K8S_LOGIN=$(curl --request POST --data \<br> '{"jwt": "'"$KUBE_TOKEN"'", "role": "org1-app1-reader"}' \<br> https://vault:8200/v1/auth/kubernetes/login | jq -r '.auth .client_token')<br>$ echo "$VAULT_K8s_LOGIN" > "/data/.vault-token"<br>
Pour faire plus simple, il serait évidemment pertinent de combiner en une seule image Docker les fonctions utilisées dans les deux premiers conteneurs. Étonnement, aucune image officielle ne semble exister à ce jour…
À quoi ça ressemble en vrai
Pour l’exemple, nous avons utilisé un simple NGINX pour jouer le rôle de l’application. Le fichier de configuration généré est en fait une page index.html qui est servie par le serveur Web. Les manifestes représentant les configMap et deployment de notre application ressemblent aux fichiers qui suivent.
Une première configMap décrit le template que nous allons utiliser pour configurer notre application :
<br>---<br>apiVersion: v1<br>kind: ConfigMap<br>metadata:<br> name: nginx-templates<br>data:<br> index.html.ctmpl: ><br> <html><br> {{ with secret "secret/org1/app1" }}<br> { .Data.var }}<br> {{ end }}<br /><br> PLOUPI: {{ env "A_SPECIFIC_VAR" }}<br> </html><br>
Vient ensuite la configMap en charge de porter les paramètres de configuration non sensibles :
<br>---<br>apiVersion: v1<br>kind: ConfigMap<br>metadata:<br> name: app-config<br>data:<br> A_SPECIFIC_VAR: FOOBAR<br>
Enfin, notre deployment :
<br>---<br>apiVersion: apps/v1<br>kind: Deployment<br>metadata:<br> name: nginx-app<br>spec:<br> selector:<br> matchLabels:<br> app: nginx<br> template:<br> metadata:<br> labels:<br> app: nginx<br> spec:<br> volumes:<br> - name: vault-token<br> emptyDir:<br> medium: Memory<br> - name: generated-conf<br> emptyDir:<br> medium: Memory<br> - name: nginx-templates<br> configMap:<br> name: nginx-templates<br> - name: vault-ca<br> configMap:<br> name: vault<br> items:<br> - key: vault_ca_file<br> path: vault_ca_file<br> initContainers:<br> - name: vault-authenticator<br> image: sethvargo/vault-kubernetes-authenticator:0.1.2<br> volumeMounts:<br> - name: vault-token<br> mountPath: /home/vault<br> - name: vault-ca<br> mountPath: /home/vault/ca<br> env:<br> - name: VAULT_CACERT<br> value: /home/vault/ca/vault_ca_file<br> - name: TOKEN_DEST_PATH<br> value: /home/vault/.vault-token<br> - name: VAULT_ROLE<br> value: org1-app1-reader<br> - name: VAULT_ADDR<br> valueFrom:<br> configMapKeyRef:<br> name: vault<br> key: vault_addr<br> - name: consul-template<br> image: hashicorp/consul-template:0.19.5-alpine<br> volumeMounts:<br> - name: vault-token<br> mountPath: /home/vault<br> - name: vault-ca<br> mountPath: /home/vault/ca<br> - name: nginx-templates<br> mountPath: /tmp/nginx-templates<br> - name: generated-conf<br> mountPath: /tmp/gen-conf<br> env:<br> - name: HOME<br> value: /home/vault<br> - name: VAULT_CACERT<br> value: /home/vault/ca/vault_ca_file<br> - name: VAULT_ADDR<br> valueFrom:<br> configMapKeyRef:<br> name: vault<br> key: vault_addr<br> envFrom:<br> - configMapRef:<br> name: app-config<br> command:<br> - "consul-template"<br> - "-once"<br> - "-template"<br> - "/tmp/nginx-templates/index.html.ctmpl:/tmp/gen-conf/index.html"<br> containers:<br> - name: nginx<br> image: nginx:alpine<br> volumeMounts:<br> - name: generated-conf<br> mountPath: /usr/share/nginx/html/<br>
Une configMap supplémentaire est utilisée : vault. Elle contient deux informations permettant de se connecter à Vault :
- vault_addr : l’URL du serveur Vault,
- vault_ca_file: le certificat de l’autorité qui a signé le certificat du serveur Vault.
Consul-template est lancée avec l’option -once. L’objectif est de générer une fois le fichier et de s’arrêter immédiatement après.
Deux volumes temporaires nommés vault-token et generated-conf sont créés en vue de servir de répertoire d’échange entre les conteneurs du pod :
- vault-token contiendra le token Vault généré par le premier initContainer et utilisé par le second
- generated-conf contiendra le fichier de configuration généré par le second initContainer et utilisé par l’application.
Ces deux volumes sont configurés pour être en mémoire uniquement. Ceci a pour objectif de minimiser les chances que ces données (sensibles) soient écrites sur disque. Ce mécanisme n’empêchera toutefois pas des administrateurs - ou tout utilisateur autorisé à exécuter les commandes kubectl cp ou kubectl exec - de récupérer le contenu des secrets.
Conclusion
Nous l’avons vu, ce modèle d’implémentation permet l’utilisation de secrets stockés dans Hashicorp Vault dans des applications déployées dans Kubernetes. Comme cela se fait sans modifier les applications, le couplage entre les technologies reste très faible. Du point de vue de l’application, un fichier de configuration est simplement présent au démarrage, sans avoir connaissance de la façon dont il a été généré.
Cette approche basée sur des initContainers fonctionne exclusivement dans le cas de secrets statiques, autrement dit, qui ne changent pas souvent dans le temps. Dans cette approche, si un secret est modifié, il faut provoquer le redémarrage des pods. C’est bien souvent une approche tout à fait suffisante pour la plupart des cas.
Dans le cas de secrets dynamiques et/ou à durée de vie courte, deux approches doivent être envisagées : déployer un sidecar à côté de l’application ou modifier le conteneur de l’application. Cette dernière solution semble dangereuse car elle introduit un couplage fort. L’article de blog suivant vous en dira plus sur le principe de mise en œuvre…
En phase de mise au point, même s’il est possible de découper les étapes pour les tester localement (sur un poste de développement, avec Minikube par exemple) il est nécessaire d’être dans un environnement avec Vault et Kubernetes réellement intégrés pour s’assurer que l’ensemble du mécanisme fonctionne correctement.
La complexité dans la mise en œuvre n’est pas à minimiser, en effet, la syntaxe des fichiers de description du deployment Kubernetes est très largement étoffée par rapport à une application qui utiliserait simplement des configMaps et des secrets Kubernetes.
Est-ce que pour autant il faut systématiquement rejeter cette intégration ? Certainement pas. Il existe des contextes (en particulier dans des grosses organisations) où la gestion des données sensibles dépassent largement le cadre d’un cluster Kubernetes et justifient leur externalisation. Vault peut en effet jouer un rôle pivot majeur entre plusieurs technologies (dont Kubernetes, mais pas uniquement et c'est une de ses forces), plusieurs équipes, avec une très forte rigueur dans la traçabilité.