Edge AI industriel : déployer des modèles IA localement, en temps réel

Introduction
L'intelligence artificielle (IA) a connu un essor fulgurant ces dernières années, en grande partie grâce à la démocratisation des capacités de calcul et grâce à la facilité à déployer en production dans le cloud. Cependant, certaines contraintes opérationnelles imposent de repenser le lieu de déploiement des modèles d'IA. C’est ici qu’intervient l’Edge Computing, un modèle qui consiste à exécuter les traitements directement sur des dispositifs locaux plutôt que de dépendre du cloud.
Cet article explore pourquoi et comment déployer un modèle d’IA à l’Edge, en s’appuyant sur un cas concret : l’automatisation du contrôle qualité sur une ligne de production de canards en plastique.
Pour un panorama plus large des usages industriels de l’IA embarquée, vous pouvez consulter notre article EdgeAI dans l’industrie.
Pourquoi un atelier sur l’IA à l’edge ?
L'IA à l'edge(1) permet d'automatiser et d'optimiser des processus complexes au plus près de l'action, tout en garantissant temps réel, autonomie et sécurité. Plus une de ces trois contraintes est forte, plus le besoin de déporter notre modèle d'IA à l’edge, au plus proche de l'opérationnel, sera fort.
Cette approche présente plusieurs avantages clés :
- Temps réel : Réduction de la latence liée au traitement des données.
- Sécurité : Limitation des risques liés à la transmission de données sensibles vers des serveurs distants.
- Autonomie : Fonctionnement indépendant en cas de perte de connexion internet.
Proche d’une ligne de production industrielle, l’Edge permet d’assurer une prise de décision instantanée et locale, sans interruption en cas de défaillance réseau, ni exposition de données sensibles.
Cas d’usage : Automatiser le contrôle qualité de canards en plastique
Problématique
Dans l’usine imaginaire Canario, la production de canards en plastique approche un canard par seconde 24h/24. Il n’est possible de vérifier la conformité d’une telle production que par batch car les qualiticiens effectuent un contrôle manuel de ces canards, vérifiant l’absence de défauts. Ce processus est chronophage, très énergivore et sujet à erreurs. Une équipe de qualiticien doit se relayer pour réduire l’effet de la fatigue sur la qualité des contrôles. Enfin, former le personnel prend du temps et l’attrition est forte.
Solution
Un système de contrôle automatisé basé sur l’IA permet d’inspecter 100% des canards en temps réel avec une fiabilité constante. Il repose sur des composants hardwares bon marché :
- Un Raspberry Pi qui exécute localement les traitements sans dépendance au cloud ;
- Des caméras installées sur la ligne de production qui capturent les canards sous différents angles ;
- Un modèle de vision par ordinateur chargé d’analyser les canards en plastique et de détecter les éventuels défauts.
Cette solution va permettre de :
- Inspecter 100% des canards produits en continu ;
- Réduire les erreurs humaines (liées à la fatigue) ;
- Améliorer le rendement de la ligne de production ;
- Renforcer la traçabilité des défauts ;
- Déployer facilement à grande échelle dans l'usine à un faible coût ;
- Valoriser le rôle des qualiticiens, qui peuvent se recentrer sur des missions à plus haute valeur ajoutée (passage de l’usine au bureau d’étude).
La mise en œuvre
Déployer un modèle d’IA à l’Edge est une tâche complexe, elle nécessite beaucoup d’étapes différentes pour créer un service reliant les outils de prise de photo, d’analyse, de mise à jour et de restitution des résultats. Il existe heureusement des outils qui vont permettre d’accélérer un certain nombre de ces étapes, notamment le Framework VIO – Visual Inspection Orchestrator ainsi que du hardware de commodité^ ^(2).

Côté logiciel d’IA : le framework VIO
Ce projet open-source est un framework modulaire pensé pour faciliter et accélérer le déploiement de cas d’usage d’inspection visuelle, directement sur des dispositifs Edge. L’objectif : rendre l’IA embarquée accessible, réplicable, et simple à orchestrer.
Ce framework repose sur trois briques logicielles principales :
- Edge Orchestrator : le cerveau de l’inspection. Il orchestre l’ensemble du pipeline : capture des images, envoi des images au modèle IA, prise de décision à partir des prédictions, puis publication de la décision.
- Edge Model Serving : ce service expose le modèle d’IA embarqué pour obtenir des prédictions en temps réel.
- Edge Interface : une interface locale pour visualiser ce qui se passe sur le dispositif Edge — utile pour le débogage, le monitoring ou l’analyse des résultats.
Des scripts de déploiement accompagnent le framework pour automatiser l’installation sur un Edge cible, que ce soit en local ou à grande échelle. Le système est pensé pour être scalable : il est possible d’imaginer un déploiement distant sur des dizaines d’appareils, piloté depuis un Hub central (3).
Enfin, chaque service est packagé en conteneur Docker, ce qui garantit à la fois portabilité entre environnements ("Build Once, Run Everywhere") et simplicité de déploiement.
Côté Hardware : un Raspberry PI et des caméras
Côté matériel, l'utilisation de composants standards (commodity hardware) suffit pour rapidement démontrer l’apport de valeur : un Raspberry Pi, une caméra USB classique, et une caméra IA Raspberry(4).

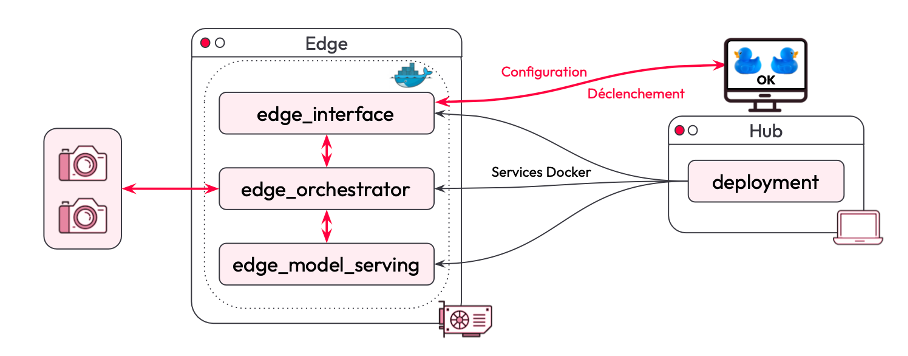
Architecture de la solution
Le Edge Orchestrator se connecte directement aux caméras et échange avec les deux autres services via une communication interne. Le Hub, un ordinateur central, joue un rôle clé pour gérer les déploiements sur plusieurs Edge en parallèle.
Livecoding
Baptiste O’Jeanson a ensuite réalisé une démonstration en livecoding, présentant pas à pas l’implémentation des briques fondamentales de la solution, en mettant en avant les choix techniques et les bonnes pratiques de développement.
Focus sur l’edge orchestrator
Edge Orchestrator, qui utilise FastAPI, une bibliothèque Python permettant de créer des serveurs asynchrones. Cette approche est essentielle pour traiter en temps réel : étant donné la cadence de la ligne de production, nous devons être capables de traiter les inspections en parallèle, car chaque canard doit être inspecté en une seconde. L’asynchronisme, et l’utilisation de tâches de fond avec Starlette (une bibliothèque Python pour gérer les tâches asynchrones), permettent cette performance.
Focus sur le Edge Model Server
Edge Model Serving est le composant chargé de servir les modèles d’IA. Chaque modèle d'IA peut être hébergé ici, permettant de s'adapter aux différents cas d'inspection. Il est exposé localement via FastAPI, recevant une image et le nom du modèle à utiliser.
Pour assurer un fonctionnement léger et rapide, le Model Server s’appuie sur LiteRT, une librairie qui permet de charger et exécuter des modèles optimisés, prenant en charge une panoplie de formats pour les livrer de façon plus compacte. Une fois converti, le modèle est chargé via un interpréteur LiteRT qui gère la préparation des entrées, le redimensionnement de l’image, le bon typage, et l’exécution de l’inférence.
-💡 Ce format allégé repose sur la quantization (ex. passage de float32 à float8) afin de réduire la taille mémoire et accélérer l'inférence*.*
De plus, des solutions peuvent être encore explorées pour servir des modèles d’IA optimisés :
- Implémentation de délégués de la librairie pour optimiser les commandes au processur sous-jacant.
- HATs (Hardware Attached on Top) pour ajouter de la puissance de calcul à un Raspberry.
- S’appuyer sur des GPU Nvidia et TensorRT.
Packaging & déploiement du framework à l’Edge : simple, multiplateforme et automatisé
Le packaging des différents modules est facilité par l’utilisation de Dockerfile multiplateforme, capable de cibler aussi bien un Raspberry Pi (architecture ARM) qu’un ordinateur classique (x86/Intel). Celui-ci va décrire la configuration pour packager les 3 services du framework.
- 💡 Pourquoi Docker Compose ? C’est simple, léger, et parfaitement adapté pour des démos ou des déploiements sur un appareil unique. Pour des usages à plus grande échelle ou plus robustes, vous pouvez envisager K3S*, une version allégée de Kubernetes pensée pour l’Edge.*
Ansible est utilisé pour déployer les services sur l’Edge, un outil d’automatisation très utilisé dans le monde DevOps. Une seule commande est exécutée pour lancer le playbook — une sorte de recette dans laquelle les étapes que doivent être exécuter par Ansible sont listées— sur l’appareil cible :
- Création des répertoires nécessaires
- Copie d’un Makefile facilitant le démarrage des services Docker
- Copie du fichier docker-compose.yml décrivant les services à exécuter
- Lancement des services
Takeaway
L’IA à l’edge permet de répondre à des cas d’usage auparavant inaccessibles, en tenant compte des contraintes fortes de temps réel, de sécurité et d’autonomie. Grâce à VIO, et du matériel standard, Docker et Ansible, le déploiement de modèles en production devient rapide et reproductible.
Reste que le passage à l’échelle n’est pas anodin : si démontrer l’apport de valeur est possible rapidement et à faible coût, la gestion d’une flotte distribuée d’équipements edge pose des défis techniques importants. Il est donc crucial d’anticiper ces enjeux en fonction de vos priorités métier pour faire le bon choix entre développement interne (build) et solution existante (buy).
Définitions
(1)Edge : Ensemble des dispositifs situés à la périphérie du réseau, au plus proche des sources de données et des actions
(2)Hardware de commodité : Un hardware peu coûteux et facilement remplaçable.
(3)Hub Central : entité de pilotage qui coordonne, supervise et contrôle à distance un ensemble de dispositifs.
(4)La caméra AI Raspberry est équipée d’un accélérateur hardware qui permet de traiter les images en temps réel.