Déploiement d'une application sur l'infrastructure AMAZON (2/3)
Nous poursuivons notre aventure AMAZON avec ce second billet qui termine la description technique des principaux services AWS.
Localisation des données et des instances
Contrairement à GOOGLE, AMAZON permet de définir l’emplacement géographique de certaines ressources. Pour cela, les concepts de régions et zones de disponibilités ont été introduits. Une région est une zone géographique – Europe, Asie, Etats-Unis Est et Ouest– composée de plusieurs zones de disponibilités. Les zones de disponibilités sont des emplacements distincts conçus pour ne pas être impactés par un dysfonctionnent d’une zone de disponibilité voisine. Néanmoins, les connexions entre les zones de disponibilités d’une même région sont optimisées pour fournir une faible latence.
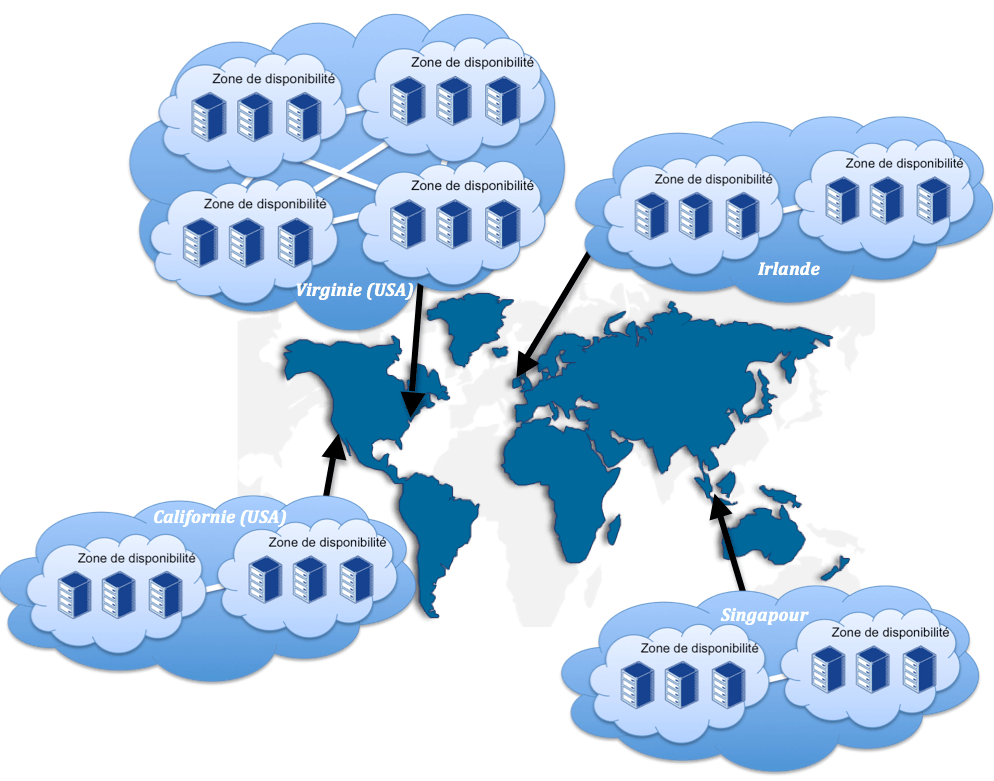
L’emplacement des ressources déployées est à considérer selon différents axes. En effet, l’utilisation de différentes régions et zones de disponibilités augmentera le niveau de disponibilité d’une application en la rendant plus robuste aux pannes. En terme de performances, plus la zone d’exécution sera proche des utilisateurs, moins la latence sera importante. Enfin, concernant la confidentialité des données : les règlementations des pays où se trouvent les zones de disponibilités sont à prendre en considération. Typiquement, depuis l’entrée en vigueur du Patriot Act, la confidentialité des données situées aux Etats-Unis a fortement diminué.
Voici un récapitulatif des relations entre les services AMAZON et le concept de localisation
- EC2 : au lancement d’une instance, une région doit être spécifiée. La zone de disponibilité est optionnelle.
- S3 : un objet est stocké dans un bucket (sorte de répertoire) qui est associé à une région. S3 implémente nativement des mécanismes de backup faisant intervenir plusieurs zones de disponibilités.
- AMI : qu'elle soit de type instance store ou EBS backed AMI, elle est stockée dans S3 - donc attachée à une région.
- EBS : un volume EBS existant est lié à une zone de disponibilité tandis qu'un snapshot EBS appartient à une région.
- SQS : une file de messages est liée à une région.
- RDS : associée à une zone de disponibilité. Il est possible d’activer une option Multi deployment pour avoir en permanence le dernier backup de la base (standby) prêt à être lancé dans différentes zones de disponibilités d’une même région. Ainsi, lorsqu'une erreur est détectée, une nouvelle instance de la base est lancée à partir du standby.
- AutoScaling : pour une même région, il est possible de répartir les instances EC2 d'un même groupe entre plusieurs zones de disponibilités. Dans le cas d’une panne d’une zone de disponibilités, le service lance de nouvelles instances au sein des autres zones actives.
RDS – la base de données
Ce service permet de s’affranchir des tâches courantes liées à l’administration des bases de données. AMAZON propose en effet un service de backups automatisés dont l’heure et la profondeur de stockage peuvent être modifiées. Enfin, l’un des atouts de RDS est de permettre une modification de la configuration matérielle de l’instance en cours sans interruption de service. Il existe cinq profils matériel qui vont de 1.7 Go de RAM, un processeur mono-cœur équivalent à un XEON à 1 GHz jusqu'à 68 Go de RAM et 8 cœurs chacun équivalent à 3.25 fois un XEON à 1 GHZ. Concernant l’espace disque, c’est à l’utilisateur de choisir – de 5 Go à 1 To.
S3 – le service de stockage d’AWS
S3 est le service de stockage d’AMAZON. Un système de redondance et d’auto détection des erreurs permet à AMAZON de mettre en avant une disponibilité de 99.9% sur un an. Les objets sont enregistrés dans des dossiers (buckets dans le langage AWS) et associés à des clés uniques. Il est possible de préciser la région dans laquelle vous souhaitez stocker un bucket. Chaque élément peut avoir une taille de 1 octet à 5 Go. Les protocoles supportés sont SOAP, REST requests avec support SSL, ou encore bit torrent. Les objets stockés sur S3 peuvent avoir une visibilité publique ou privée, auquel cas des permissions par utilisateur peuvent être définies. Cependant un utilisateur doit avoir un compte client AMAZON.
SQS – le middleware par messages
Il s’agit d’un service web qui fait office de middleware typé MOM. Fonctionnant sans logiciel particulier, ni configuration de pare-feu à mettre en place, SQS peut être utilisé indépendamment d’EC2 et n’importe quel ordinateur relié à Internet pour poster ou lire des messages. SQS ne garantit pas que les messages soient publiés selon une logique FIFO puisque lorsqu’un message est lu, il devient invisible pendant une certaine durée (visibility timeout).
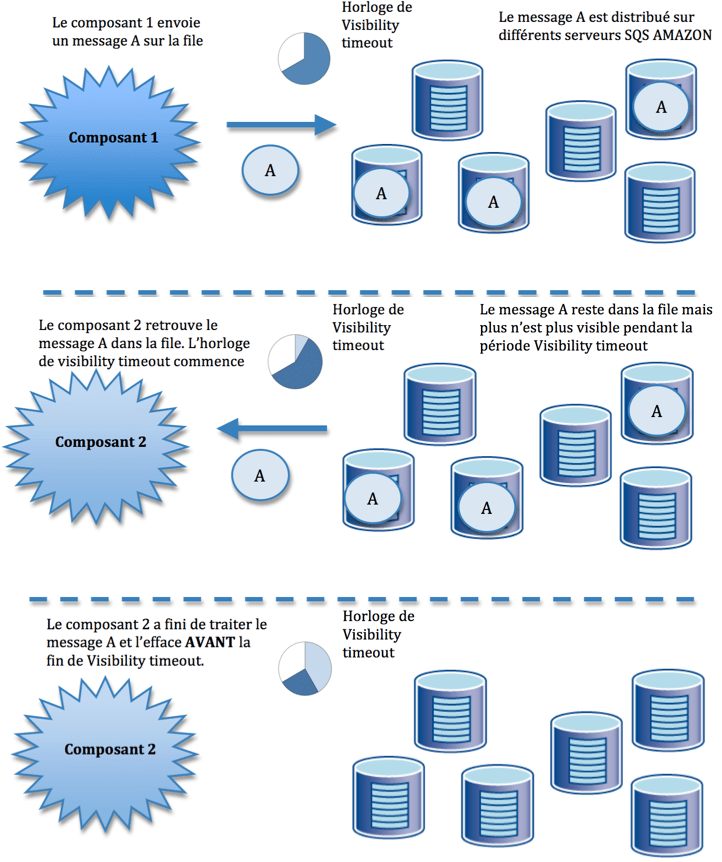
Les messages peuvent contenir jusqu’à 8Ko de texte et sont conservés au maximum pendant 4 jours. Aucune limite n’est imposée que ce soit sur le nombre de files de messages ou sur le nombre de messages qu’elles contiennent.
CloudWatch - le monitoring
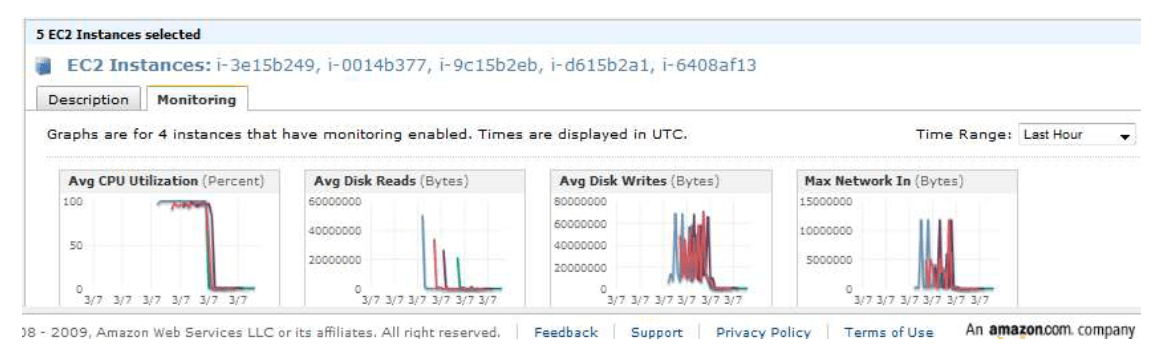
Il s’agit d’un web service qui permet de surveiller les ressources déployées sur l’infrastructure AMAZON. CloudWatch introduit la notion de namespace pour définir les catégories de ressources que l’on supervise. Il y a aujourd’hui trois namespaces différents puisqu’il est en effet possible d’avoir des informations sur les instances EC2 mais aussi le service de Load balancing (Elastic Load Balancing) ainsi que RDS. En fonction du type de ressources que l’on supervise, les données (appelées metrics dans la terminologie AWS) sont différentes. Par exemple le monitoring sur des instances EC2 fournira des indications sur le trafic réseau, ce qui n’est pas possible avec RDS qui pourra en revanche nous informer sur le nombre de connexions à la base ou encore l’espace disque disponible. Dans la suite du document, nous nous sommes focalisés sur les instances EC2
CloudWatch n’effectue pas seulement de l’agrégation de données ; il calcule aussi des statistiques, ce qui permet d’avoir des moyennes, des sommes ou bien des valeurs minimum et maximum déterminées pour des fenêtres temporelles – au minimum une minute.
Concernant les instances EC2, l’activation de CloudWatch ne doit pas se faire obligatoirement au lancement de la machine, mais elle peut avoir lieu plus tard.
En terme d’utilisation, CloudWatch propose une API très simple ListMetrics pour connaître la liste des données qui sont actuellement agrégées et GetMetricStatistics. Cette dernière fonction propose de filtrer les résultats selon des critères tels que l’ami-id ou encore la configuration matérielle de l’instance.
L’utilisation de CloudWatch seul a un rôle informatif mais une fois associé à AutoScaling, il permet de répondre au problème de scalabilité.
Auto Scaling
Ce service permet de modifier selon certaines conditions, le nombre d’instances EC2 en exécution. Il est possible d’augmenter la taille d’un groupe d’instances EC2 pour répondre à un pic de charge ou au contraire de diminuer le parc en exécution dans le cas d’une baisse de trafic.
AutoScaling introduit trois concepts : trigger, autoscalingGroup et launchConfiguration.
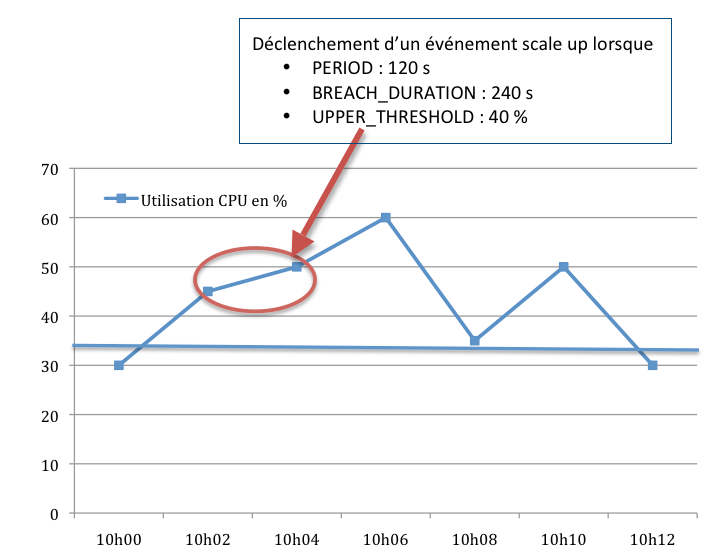
- Les événements lancés selon des critères d’augmentation et de diminution d’un groupe de Machines Virtuelles – aussi appelés triggers portent sur tous les éléments qui peuvent être agrégés par le service de monitoring CloudWatch pour des statistiques : CPU, réseau, disques… La définition d’un trigger passe notamment par les paramètres suivants : period, breachDuration, valeur du seuil bas et valeur du seuil haut de la statistique. La période exprime l’intervalle de temps entre deux évaluations de la statistique faites par CloudWatch. Le paramètre BreachDuration indique le temps pendant lequel la statistique doit dépasser la valeur limite haute ou basse, avant que l’événement ne soit lancé.
- Une LaunchConfiguration définit l’AMI à lancer mais aussi le profile matériel de l’instance ainsi que le groupe de sécurité associé.
- La création d’un AutoScalingGroup nécessite de fournir un identifiant de LaunchConfiguration, les tailles minimales et maximales du groupe ainsi que les zones de disponibilités où les instances EC2 seront lancées ou arrêtées. Comme indiqué plus haut dans la partie "localisations des données et des instances", il est possible voire judicieux de lancer des instances dans plusieurs zones de disponibilités.
Voici comment mettre en place l'auto-scaling (exemple avec l'AMI : 0992b97d)
- Création d’une launchConfiguration. La configuration contient l’ID de l’AMI, le type matériel des instances EC2 à utiliser ainsi que des paramètres de sécurité (clés, utilisateurs ...)

- Nous créons un autoScalingGroup, c’est à dire une collection d’instances EC2 sur lesquelles s’appliquent des conditions de dimensionnement. Typiquement, un groupe comporte un nom et des paramètres pour le nombre de machines minimal et maximal. Dans l'exemple, le groupe a une taille qui varie de 1 à4 instances réparties sur deux zones de disponibilités

- Nous définissons les conditions de dimensionnement (triggers) du groupe de machines EC2. Dans notre exemple, les conditions sont :
- Contrôler chaque minute l’utilisation CPU moyenne pour tout le groupe.
- Si l’utilisation CPU a été supérieure à 80% pendant les dix mesures (minutes), ajouter une machine.
- Si l’utilisation CPU a été inférieure à 40% pendant les dix mesures (minutes), retirer une machine
- Il est possible de suivre l'activité du service auto-scaling
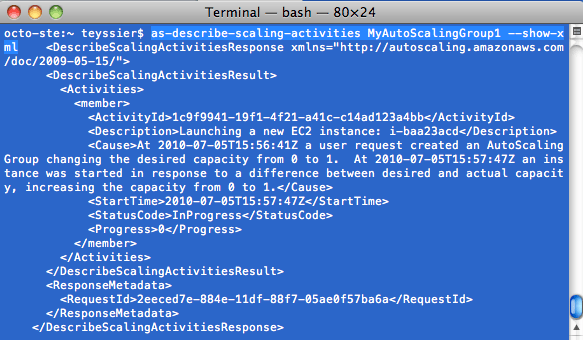
L'arrêt d'un groupe d'instances contrôlées par autoScaling, se fait de la manière suivante :
- Destruction du trigger

- Affectation des tailles minimales et maximales du groupe à 0

- Destruction du groupe

Les outils
L'usage des services AMAZON peut se faire de plusieurs manières puisqu'ils reposent sur des web-services. Tous les services détaillés dans l'article : EC2, EBS, S3, SQS, RDS, AutoScaling et CloudWatch sont accessibles par des web-services SOAP et REST. On trouve donc des outils en ligne des commandes, des consoles web ou encore des plugins pour ECLIPSE et FIREFOX.
Le tableau suivant ne se veut pas exhaustif, mais recense néanmoins un certain nombre de possibilités. Il est à noter que seules les librairies JAVA sont listées bien qu'ils en existent pour divers autres langages tels que PHP, RUBY, ou encore .Net.
| Nom de l’outil | Catégories | Service ciblé | Description |
| AWS Management Console | Interface Web | EC2, EBS, S3, RDS, CloudWatch, ElasticLoadBalancing, CloudFront, ElasticMapReduce, sécurité (clés, groupes d’utilisateurs …) | La console Web est l’outil le plus complet pour une gestion des services AWS au travers d’une interface graphique. Elle permet notamment d’obtenir des graphiques CloudWatch pour suivre l’activité des instances EC2.<br><br>Elle est cependant assez lourde d’où une certaine lenteur. |
| EC2 api tool | Lignes de commandes | EC2, EBS | |
| EC2 AMI tool | Lignes de commandes | Création et gestion des AMI | |
| CloudWatch api tools | Lignes de commandes | CloudWatch | |
| AutoScaling api tools | Lignes de commandes | AutoScaling | |
| AWS JAVA SDK | SDK java | EC2, S3, RDS, SQS, CloudWatch, AutoScaling, SNS, ElasticMapReduce, ElasticLoadBalancing, Simple DB | Le SDK contient avant tout une librairie JAVA dont le périmètre couvre de nombreux services AWS. De plus, le SDK contient des exemples. Point négatif : pas de repository MAVEN. |
| AWS Toolkit for Eclipse | Plugin Eclipse | EC2, EBS, AMI, SimpleDB | Le plugin ECLIPSE inclut la librairie AWS JAVA du SDK. Il permet donc de créer des projets utilisant les services AMAZON. En outre, le plugin permet de gérer les instances EC2 depuis l’IDE : lancement et arrêt d'instances EC2 mais aussi création de volumes EBS. Enfin, le debug est facilité puisqu’il est possible de déployer une application web sur une instance EC2. L’instance peut être basée sur une AMI par défaut comportant un TOMCAT ou bien une AMI spécifique avec un autre conteneur d’applications. |
| Typica | Librairie java | EC2, SQS, Simple DB, DevPay | Accessible depuis un repository MAVEN |
| jetS3t | Librairie java | S3, CloudFront | Accessible depuis un repository MAVEN |
| Elastic Fox | Plugin Firefox | EC2, EBS, AMI, VirtualPrivateCloud | Permet d’accéder aux fonctionnalités de VirtualPrivateCloud et VPN qui ne sont pas dans la console de management AWS. |
| S3 Fox | Plugin Firefox | S3 | Permet de créer des buckets et de copier, déplacer, effacer des éléments depuis ou vers des buckets.<br><br>Léger et assez rapide. |