ProGuard sur Android : Astuces et stratégies pour des builds efficaces
Si vous êtes développeur Android, vous avez forcément entendu parler de ProGuard, cet optimiseur de bytecode Java. Quelques conférences de développeurs influents ou bien une discussion avec un bon tech-lead vous ont sûrement laissé un jour cette impression « Ça a l’air d’être un truc bien, il faut l’activer pour les builds de prod, c’est important ».
Le problème est qu'entre avoir entendu parler, et maîtriser l’outil, il y a de nombreuses étapes que peu de développeurs franchissent. C’est bien dommage car avec ProGuard, la sanction est immédiate : le build sera généralement cassé une fois l'outil activé, jusqu’à ce qu’une configuration correcte soit écrite. Et là, par manque de compréhension de l’outil, c’est souvent un grand bidouillage.
Que vous vous considériez comme débutant sur le sujet, ou comme un utilisateur un peu plus avancé, prenons le temps de revenir sur ProGuard et son fonctionnement, afin de démystifier son utilisation.
Cet article dispose d'une seconde partie qui traite des problèmes communs rencontrés après l’activation de ProGuard et de leur résolution.
Intégration dans Android
ProGuard est un outil open-source, issu du monde Java, qui se définit comme un optimiseur de bytecode. Google supporte officiellement son intégration dans le processus de build d’une application Android.
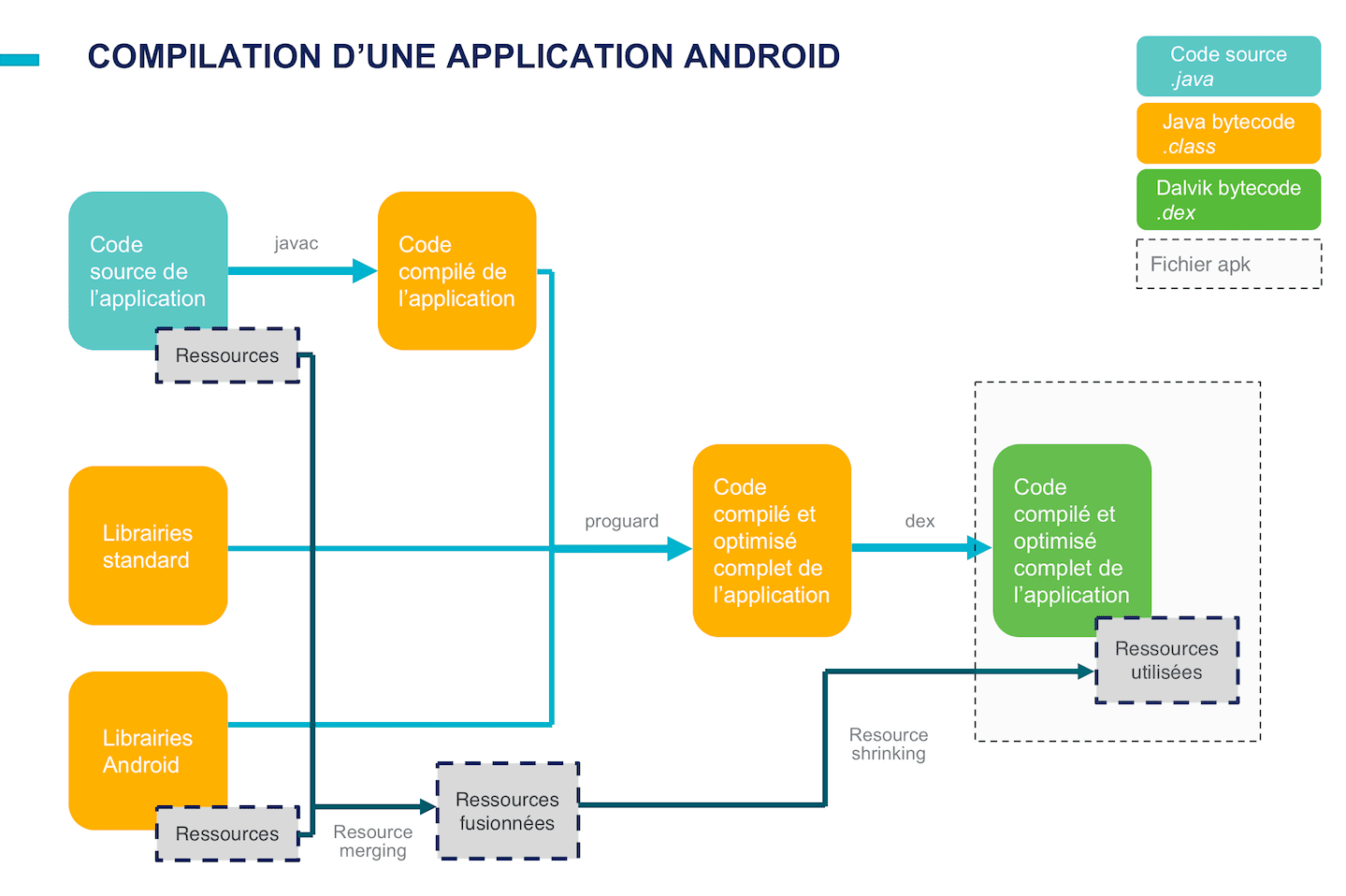
Comme on peut le voir sur le schéma, ProGuard agit après la compilation des sources Java de l’application en bytecode standard (.class), et sur l’ensemble du code compilé de l’application. Il va donc traiter indifféremment le code écrit par le développeur, celui éventuellement généré par des librairies, et le code des différentes librairies embarquées*.
Après le « passage » de ProGuard, on retourne au process traditionnel de compilation Android : le bytecode Java résultant est compilé en dex. Ce fichier dex, associé aux ressources de l’application, permettra à l’APK Packager de créer le fichier .apk final.
ProGuard nécessite deux éléments pour fonctionner : le code de l’application et une liste de « points d'entrée » (entry point dans la documentation). Ces derniers sont des éléments du code qu’il faut impérativement garder intacts : ils ne doivent être ni supprimés, ni modifiés, ni renommés (« obfusqués »).
Qu’est-ce qu'un point d'entrée ?
Dans une application « command-line » Java basique, c'est assez simple : un exemple de point d'entrée est la méthode statique <br>main<br>. C'est elle qui, par convention, sera appelée par la JVM lors de l'exécution du binaire. Bien qu'elle puisse sembler « inutilisée » car aucun élément de notre code ne l'appelle directement, il est impensable de la supprimer, de limiter sa visibilité (ex: la passer en private) ou de la renommer : l'application ne fonctionnerait plus.
Sur Android, les applications sont beaucoup plus modulaires : le système peut interagir à tout moment avec nos activités, services, receivers, content-providers… Tous ces éléments, ainsi que leurs méthodes de « cycle de vie » doivent être considérés comme des points d'entrée.
Lors de la compilation d'une application, l'outil <br>aapt<br> se charge de générer une liste de ces points d’entrée, en parcourant notamment le Manifest et les layouts. Toutes les classes répertoriées dans ces fichiers (Activités, Services, vues custom…), sont listées dans un fichier (visible dans le dossier <br>build/intermediates/proguard-rules<br> du module), en tant que points d'entrée.
À ce fichier s'ajoute un fichier de règles plus « haut-niveau », déclarées directement par Google dans le SDK Android. Deux fichiers sont disponibles : <br>proguard-android.txt<br> et <br>proguard-android-optimize.txt<br>.
À la racine de chacun des modules gradle Android, il existe généralement un fichier <br>proguard-rules.pro<br> qui sert à définir vos propres points d'entrée de « fine-tuning ».
Dans le processus de build, le fichier de base du SDK se retrouve fusionné avec la configuration « automatique » générée par <br>aapt<br>, puis enfin avec le fichier de configuration <br>proguard_rules.pro<br>.
Si vous référencez dans le <br>build.gradle<br> des dépendances vers des bibliothèques Android (distribuées au format .aar), il est possible que leur développeur ait défini un fichier ProGuard, qui se retrouvera lui aussi fusionné avec le reste des « règles ».
Les différents types de spécification de points d'entrée sont listés et documentés sur le manuel de ProGuard.
Dans l’exemple d’une application command-line Java classique, une manière de décrire le point d'entrée dans le format de configuration compris par ProGuard est :
-keep public class com.octo.example.MainClass {
public static void main(java.lang.String[]);
}
Le mot clef <br>keep<br> est le plus restrictif : il indique à l’outil qu’il faudra conserver le point d’entrée et qu’il ne faudra pas le renommer.
Il existe plusieurs autres mots clés permettant de spécifier uniquement qu’un élément de code doit être conservé (mais peut être renommé), ou bien qu’un élément ne doit pas être renommé (s’il est conservé par ailleurs).
Exécution de ProGuard
L’exécution à proprement parler de ProGuard s’effectue en quatre étapes.
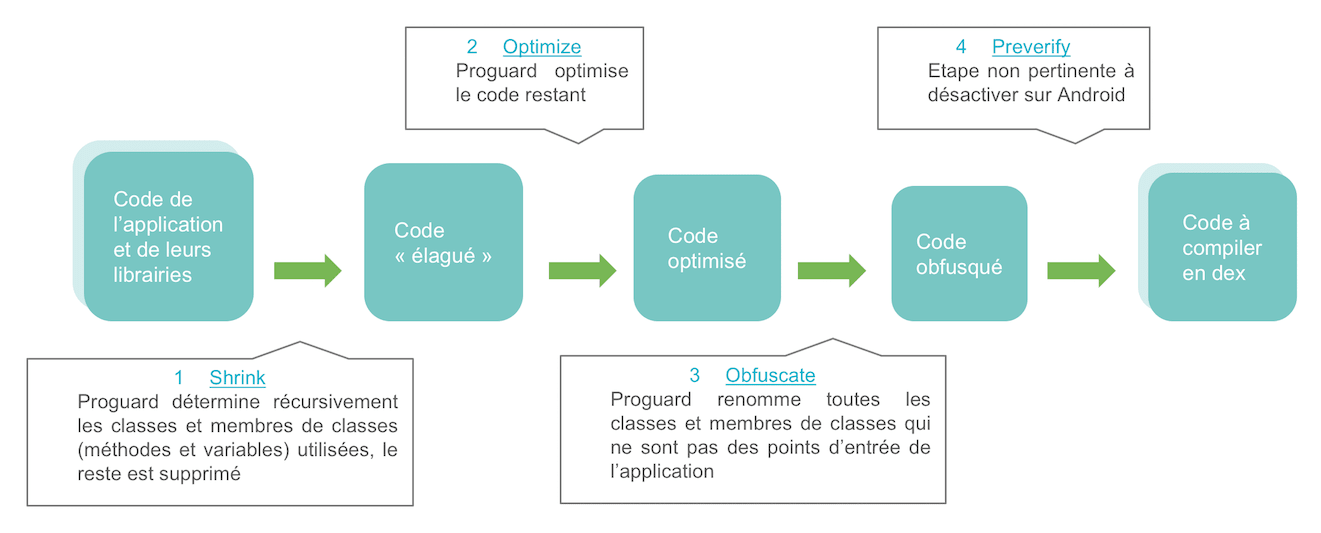
1. La première phase est l’étape de « shrink », ou élagage
Depuis chacun des points d'entrée, ProGuard analyse récursivement le code et répertorie les classes et membres de classes (attributs, méthodes…) qui sont susceptibles d'être exécutés au runtime.
Cet ensemble représente le code réellement « utilisé » par l'application, qui doit obligatoirement se retrouver dans le binaire final. Le reste est considéré comme du code « mort », il est supprimé.
2. La seconde phase de l’exécution de ProGuard est l'« optimize »
Cette phase ne se lance que si vous avez référencé le fichier du SDK : <br>proguard-android-optimize.txt<br>. Attention, par défaut, Android Studio crée votre fichier build.gradle en référençant l'autre fichier à la ligne <br>proguardFiles<br>.
Elle consiste en un certain nombre d'« optimisations ».
Une première partie de ces optimisations peut être considérée comme un « shrink » évolué : l'outil détecte les paramètres inutilisés des méthodes, le code mort à l'intérieur des méthodes, les appels inutiles…
La seconde partie est un ensemble d'optimisations plutôt bas niveau : ProGuard « inline » les membres de classe qui peuvent l'être, essaie de descendre la visibilité des méthodes et des classes, optimise les instructions (peephole optimization)…
Il est impossible de limiter l'exécution de la phase optimize à certaines classes : on active ou on désactive une optimisation pour l'ensemble du code.
3. La troisième phase est l’« obfuscate », le renommage des noms de classes et de leurs membres.
Tout ce qui n'est pas déclaré comme point d'entrée est renommé (classe, méthode, paramètre et attribut) en une séquence de caractères la plus courte possible ("a", "b"… jusqu'à "z", puis "aa", "ab"…).
Un fichier de référence <br>mapping.txt<br> est généré, afin de pouvoir retrouver le nom originel des éléments transformés. Il est important de conserver ce fichier. Dans le cas contraire, il devient impossible d'exploiter les stacktraces remontées par les outils de crash-reporting. Si Fabric et son plugin gradle sont utilisés dans le projet, le fichier de mapping est automatiquement uploadé sur leur serveur pour « désobfusquer » les traces de manière transparente.
4. La dernière phase est le pre-verify
Elle est désactivée sur Android par les fichiers de configuration du SDK.
Pour résumer
À l'issue de la phase de shrink, la base de code de l'application (cœur + librairies) est considérablement allégée.
Tout ce qui n'est pas utilisé dans notre propre code est supprimé, c'est appréciable mais ça n'est pas énorme. L'impact est beaucoup plus important au niveau des librairies référencées (qui n'a jamais utilisé une librairie apache commons pour une ou deux méthodes ?).
Grâce à la phase d'optimisation, la base de code élaguée est encore légèrement réduite et est optimisée au niveau du bytecode.
Pour finir, le code restant est « obfusqué », tout est transformé en noms courts et incompréhensibles.
On obtient donc un bytecode plus léger, plus efficace, et moins susceptible d'être rétro-ingénieré.
Impact sur un projet
Sur un projet bancaire, développé par OCTO, d’environ 180kLOC, embarquant un nombre important de librairies tierces sur lesquelles nous n’avons pas de contrôle, le build de production, sans ProGuard, pèse 40,2Mo. Après le passage de ProGuard, le fichier diminue de 14% et pèse 34,4Mo.
Sur un beaucoup plus modeste de 30kLOC, le build de production sans ProGuard pèse 9,2Mo. Le même build après ProGuard pèse 7,3Mo, soit 20% de réduction.
L’impact sur la taille du binaire final n’est donc pas négligeable.
L'idéal sur un projet est de mettre en place ProGuard sur le build de « release » et de recette dès le début (mais pas sur le build de « debug » du développeur, à cause du temps de compilation supplémentaire qu’il nécessite).
Cela permettra au Product-Owner et aux testeurs de faire leur recette sur le build « ProGuardisé », afin d'éviter de mauvaises surprises sur lesquelles nous reviendrons dans un prochain article. Cela vous permettra surtout à vous, développeurs, de traiter les erreurs d'exécution de ProGuard au fur et à mesure de vos développements, plutôt que juste avant la mise en production.
Pour essayer de gagner du temps, ou bien par manque d'intérêt, la plupart des développeurs Android (on le voit très bien sur StackOverflow) sautent cette étape de compréhension des concepts de base de ProGuard et des différentes étapes d'exécution. Avec les quelques explications précédentes en tête, vous êtes mieux armés pour affronter ProGuard jusqu’à la suite de cet article, qui traitera des problèmes fréquemment rencontrés et proposera une méthode de résolution.
Si cet article vous motive à aller discuter de l’outil avec vos collègues développeurs, n’oubliez pas : ProGuard se prononce « pro garde », et non « pro gouarde » ;)
Note :
* ProGuard est en réalité conçu pour traiter différemment le code de l'application (input jars), et les dépendances déclarées par l'application (library jars). Dans une utilisation Java "classique", ProGuard limite son exécution aux input jars. Dans le cas d'Android, Google a décidé de considérer le binaire "total" de l'application comme "input jars".