Démystifier l'intelligence artificielle une fois pour toutes
En tant que technical lead d’une équipe qui produit des applications utilisant l’intelligence artificielle, il me tient à cœur de démystifier ce domaine. Je suis convaincu que la réussite de telles équipes passe par le partage de compréhension entre les data scientists d’un côté et le reste de l’équipe de développement, product owners et UX designers de l’autre.
Si les mots suivants sont obscurs pour vous dans le contexte d’un projet data, cet article est fait pour vous ! Il va justement les démystifier :

Le besoin de prédire
Nous avons toujours aimé avoir des prédictions et, curieusement, préféré les faire faire par une tierce partie. La tierce partie (que l’on appellera le Modèle) utilise des données (input data) et répond à notre question par une prédiction.
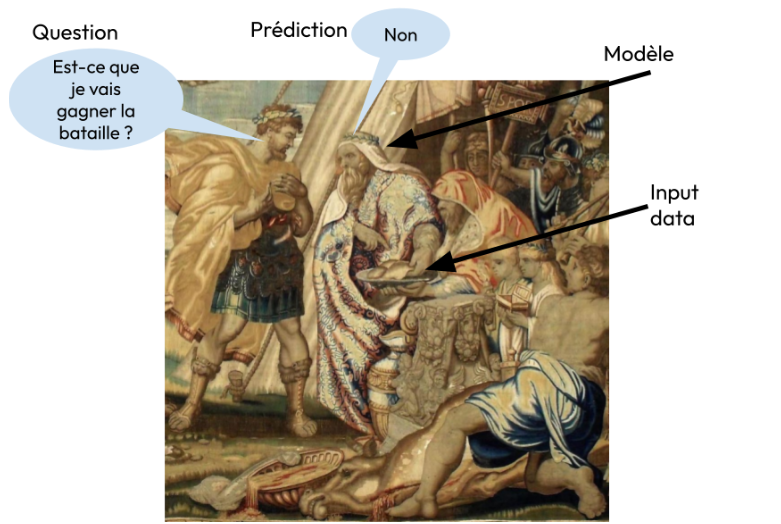
Tapisserie (Jan Raes) du tableau de Rubens (17ème siècle) représentant le général romain Publius Decius Mus consultant les aruspices qui lisent l’avenir dans les viscères de l’animal sacrifié. Source de l’image : Wikimedia
{kind=link}
La prédiction de nos jours
L’activité de publicité et de vente a propulsé à un autre niveau cette propension de l’humanité à faire des prédictions.
Imaginez une personne qui a toujours vécu sur une île déserte devenir un vendeur ambulant de roses. Après quelques sorties, elle apprend qu’un couple de promeneurs amoureux a plus de probabilité de lui acheter une rose qu’une personne seule. Afin de ne pas perdre son énergie et son temps à aborder tout passant pour proposer ses services, elle ciblera les passants selon leurs caractéristiques.
Ayant fait les observations suivantes et constaté le résultat, notre vendeur apprend :
- Le mardi, un vieux monsieur promenant son chien a dit non à la proposition d’acheter une fleur ;
- Le jeudi soir, un couple se tenant la main, souriant et marchant lentement, a acheté une fleur ;
- Le dimanche matin, un homme qui semble pressé, portant une valise, n’a même pas répondu ;
- Toujours le dimanche matin, un couple avec un enfant a décliné poliment.
Les données d'entraînement (train data) de notre vendeur ressembleraient à ça (une ligne pour chaque jour et une case vide si l’information est absente) :
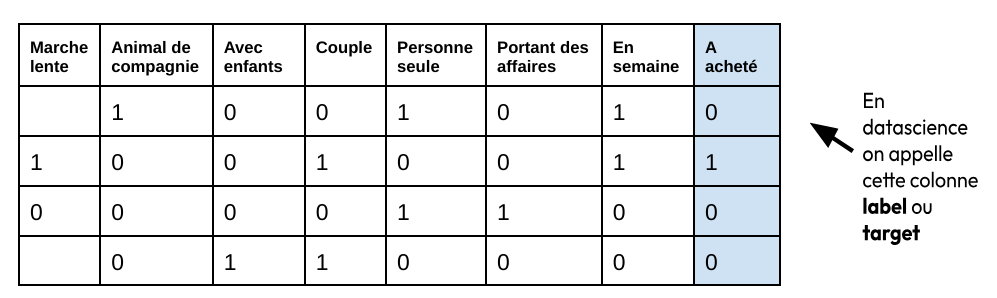
Avec ses données, notre vendeur a entraîné un modèle (mental), qui lui permettra la semaine suivante devant des situations nouvelles (new input data) de réaliser la semaine d’après 1 vente avec un peu moins d’efforts :
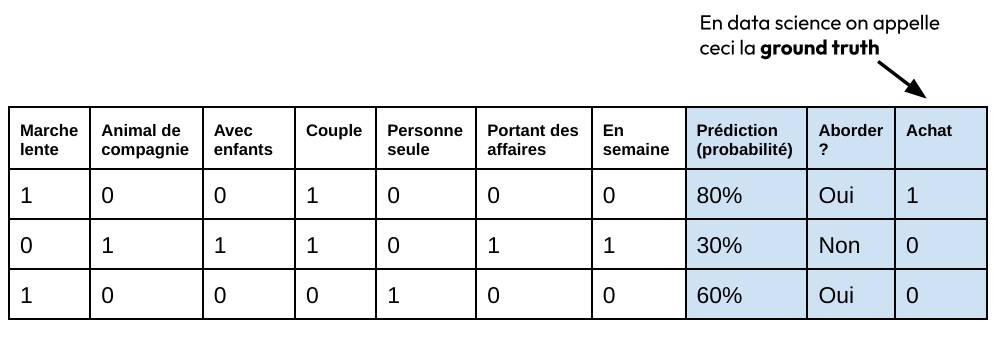
On pressent que cette façon de faire ne passe pas à l’échelle et a une efficacité médiocre lorsque les descendants de ce vendeur de roses ont ouvert une entreprise de vente par correspondance employant des agents commerciaux et investissant dans la publicité.
Un peu de sérieux avec la Statistique
La suite de l’histoire se raconte avec les diverses techniques statistiques. Il s’agissait de collecter de la donnée d’une manière plus méthodique (par des questionnaires par exemple) et de modéliser la relation entre l’information et le résultat que l’on souhaite prédire grâce à des formules mathématiques.
On remplace ainsi le jugement et le bon sens humain par les mathématiques. La phrase “d’après mes équations” est après tout bien plus convaincante que la phrase “d’après mon expérience”. Bien entendu, il fallait convertir l’information en nombres (input data), et appliquer des algorithmes pour trouver les paramètres qui donnent la bonne prédiction dans la majorité des observations de l’input data.

La collection de données par des questionnaires terrain pour modéliser la probabilité d’achat. Source de l’image : Wikimedia
{kind=link}
Cette approche statistique a ajouté de la rigueur à l’approche humaine de la prédiction. Cependant, nous étions dans l’ère du Small Data, avec quelques dizaines de points d’observation. Aussi, les prédictions n’étaient pas souvent réalisées, tout simplement parce que les modèles statistiques ont besoin de beaucoup de données.
Nouvelle échelle avec le Data Mining
L’essor de la poste, des communications téléphoniques et plus tard internet a permis de collecter les réponses aux questionnaires plus facilement et à plus large échelle. C’est l’ère du Data Mining, où les mêmes techniques statistiques commençaient à donner de meilleurs résultats. C’est aussi l'essor du métier de Data Analyst, dont le but est d’analyser la masse de données pour mieux comprendre les processus métier ou les utilisateurs, sans nécessairement devoir faire une prédiction…
Le modèle est passé du stade mental au stade d’une formule mathématique.
Avec quelques centaines de points d’observation, on pouvait répartir la input data en 2 parties :
- La train data que l’on va donner à l’algorithme statistique pour qu’il trouve la bonne formule mathématique ;
- La validation data qui va nous permettre de tester cette formule.
Le Big Data et la Data Science réconcilient prédiction et informatique
La Data Science et le Machine Learning ne sont que le résultat de la démocratisation de cette approche, avec :
- Le Big Data : des données encore plus massives (dizaines, voire centaines de milliers de points d’observation)
- Des structures mathématiques plus complexes
- Et surtout : des librairies logicielles (code informatique fait par d’autres) qui permettent de manipuler facilement les nouveaux algorithmes
- Et bien entendu la facilité de disposer de la puissance de calcul nécessaire

Meme répandu dans la communauté de la data science représentant cette discipline comme un simple gain en notoriété de la statistique
Le modèle ne pouvait plus tenir dans des formules mathématiques, il devient un objet informatique (un code, un exécutable, un zip…), en quelque sorte une boîte noire.
Mais ce qui n’a pas changé, et ne changera jamais, c’est que la boîte noire a été entraînée avec la train data (où la prédiction est connue), validée avec la validation data (où la prédiction est connue) et sera appelée pour donner une prédiction (une probabilité plus exactement) à partir de la new input data.
Notons que ce modèle généralement :
- Est peu volumineux, même si les données d’entraînement sont très volumineuses
- Prend peu de temps à être construit, de quelques secondes à quelques minutes
- Doit être reconstruit si de nouvelles données d’entraînement sont disponibles, ce qui n’est pas bien grave puisque ça se fait facilement et rapidement
Data scientist et Data engineer
Pendant longtemps les Data Scientists ont créé ces modèles dans leur coin, notamment en utilisant des Notebooks (brouillons de code). Cependant de nos jours, cette approche n’est plus acceptable : les Notebooks sont mal reproductibles, non intégrés au reste de l’application et surtout peu maîtrisés par le reste de l’équipe de développement.
Aujourd’hui, nous disposons de tout ce qu’il faut pour que la data science se conforme à toutes les autres règles d’un projet informatique : clean code, infra as code, unit testing, devops, etc…
Aussi, de nos jours, les Data Scientists sont des informaticiens qui travaillent étroitement avec les Data Engineers, notamment parce qu’une grande partie de leur travail est de mettre en forme les données pour préparer la fameuse train data.
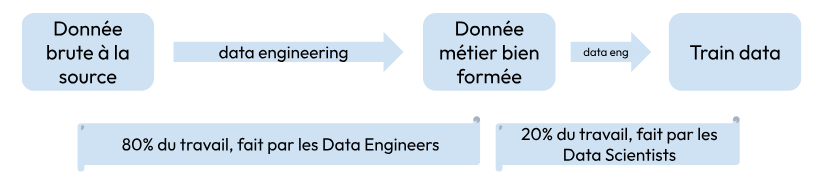
Qu’est-ce qu’une bonne prédiction ?
Revenons à la prédiction.
Jusqu'ici, nous ne nous sommes pas préoccupés de l'accomplissement de la prédiction, mais tôt ou tard vient le moment de la vérité : est-ce que la prédiction est vérifiée ? Est-ce que le prospect a acheté notre produit ? Cette information nous est de prime abord inutile puisqu’elle arrive tard. Cependant elle est cruciale pour évaluer le modèle. Un modèle est meilleur qu’un autre si ses prédictions ont plus tendance à se vérifier dans le futur.
Pour prendre une analogie, l’évaluation d’une jeune ingénieure serait sa capacité à résoudre les nouveaux problèmes qu’elle va rencontrer dans le monde du travail. Alors que son entraînement serait les leçons apprises en école d’ingénieur, et sa validation les examens qui portent sur le même type de problèmes vus en leçons.

Il existe plusieurs façons standardisées d’évaluer un modèle. La plus connue pour un modèle de prédiction est la matrice de confusion :
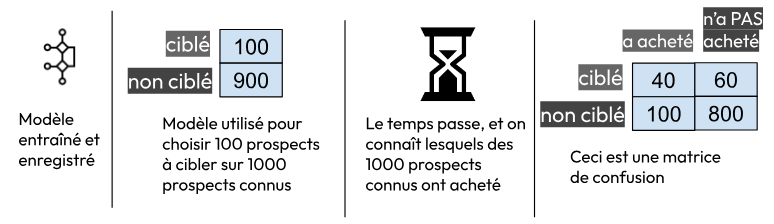
Devant cette matrice, un data scientist vous dira que le modèle a une performance médiocre :
- Il a “eu bon” sur seulement 40 / (40 + 60) = 40% des ciblages. C’est ce qu’on appelle le taux de vrais positifs ou précision ;
- Il n’a permis d’identifier que 40 / (40 + 100) = 29% des acheteurs. C’est ce qu’on appelle le taux de rappel (recall).
Le Deep Learning permet de prédire à partir d’images et de texte
Jusqu’à ce stade, les data scientists ont maîtrisé la prédiction à partir d’input data structurées, c'est-à-dire qui peuvent rentrer dans un tableau Excel.
Comment faire prédire à un assistant virtuel si un long texte contient une intention positive ou négative ? Comment faire prédire à une voiture autonome si un panneau de signalisation contient une limitation de vitesse, et si oui laquelle ?
C’est là que le Deep Learning est entré en jeu pour proposer :
- Des façons de convertir cette donnée en nombres - après tout, une image est un tableau de pixels, chacun défini par trois nombres : les degrés de rouge, vert et bleu ;
- De nouvelles structures mathématiques, les réseaux de neurones : des milliers d’équations mathématiques interdépendantes ;
- Des librairies logicielles pour les manipuler facilement.
Le Deep Learning propose aussi une infinité de façons de chaîner les réseaux de neurones en plusieurs couches (layers), afin de spécialiser le modèle pour une tâche précise, comme par exemple :
- La reconnaissance d’image (computer vision) ;
- La compréhension de la sémantique d’un texte (Natural Language Understanding) ;
- La complétion ou la production de texte (Natural Language Processing).
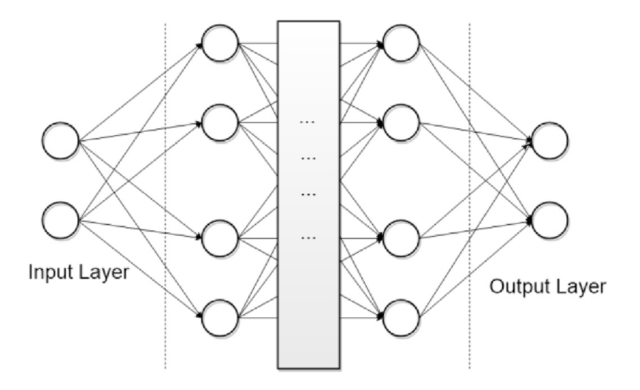
Illustration des couches d’un réseau de neurones. Source de l’image : Wikimedia
{kind=link}
Et comme une image contient beaucoup plus d’information qu’une ligne Excel, on comprend aisément qu’avec le Deep Learning, le modèle (objet informatique) :
- Est plus volumineux ;
- Est plus long à entraîner ;
- Nécessite une puissance de calcul supérieure, notamment des processeurs graphiques (GPU) ;
- Peut être amélioré sans repartir de zéro, en ajoutant une couche ou en re-calculant les paramètres d’une seule de ses multiples couches.
Ce qui n’a pas changé cependant, c’est qu’il faut toujours collecter de la donnée de bonne qualité (train data et validation data), et qu’il faut prendre soin d’évaluer le modèle une fois utilisé en conditions réelles. La matrice de confusion reste utilisée, à condition de bien collecter au fil du temps les prédictions du modèle, ce qui permet de savoir s’il s’est trompé ou pas (ground truth).
Enfin, comme pour le machine learning, de nos jours la construction et l’utilisation de ces nouveaux modèles peut se faire sans entraves dans les règles de l’art d’un projet informatique moderne.
La révolution générative
Jusque là, la prédiction (faite avec des outils de plus en plus puissants et de mieux en mieux maîtrisés) restait une donnée chiffrée : une probabilité, voire un nombre - par exemple le prix de vente d’une maison. Peut-on prédire un type de donnée moins classique ?
Les années 2010 ont vu des avancées substantielles :
- Encore plus d’accumulation de données utilisables (Big Big Data. Cette source donne une mise en perspective historique) ;
- Encore plus de puissance de calcul disponible ;
- Et surtout une nouvelle génération de structures mathématiques, encore plus complexes : les auto encodeurs, puis les transformers, une espèce survitaminée de réseaux de neurones.
Les transformers sont entraînés à l’avance (pré-entraînés) avec des textes de référence produits par le savoir humain. Ils sont capables de prédire, à partir d’un texte ou d’une phrase, la suite la plus probable que le langage humain lui donnerait ! La prédiction devient une valeur parmi une infinité de possibilités, une nouvelle donnée générée.
Mais comment est-ce que les transformers peuvent manipuler des textes de longueurs et structures infiniment variées ? Comme dans le deep learning, les mots et les textes sont convertis en liste de nombres : les vecteurs. Ceci permet d’appliquer des opérations mathématiques sur le texte et aussi de comparer un texte à un autre (mesure de similarité).
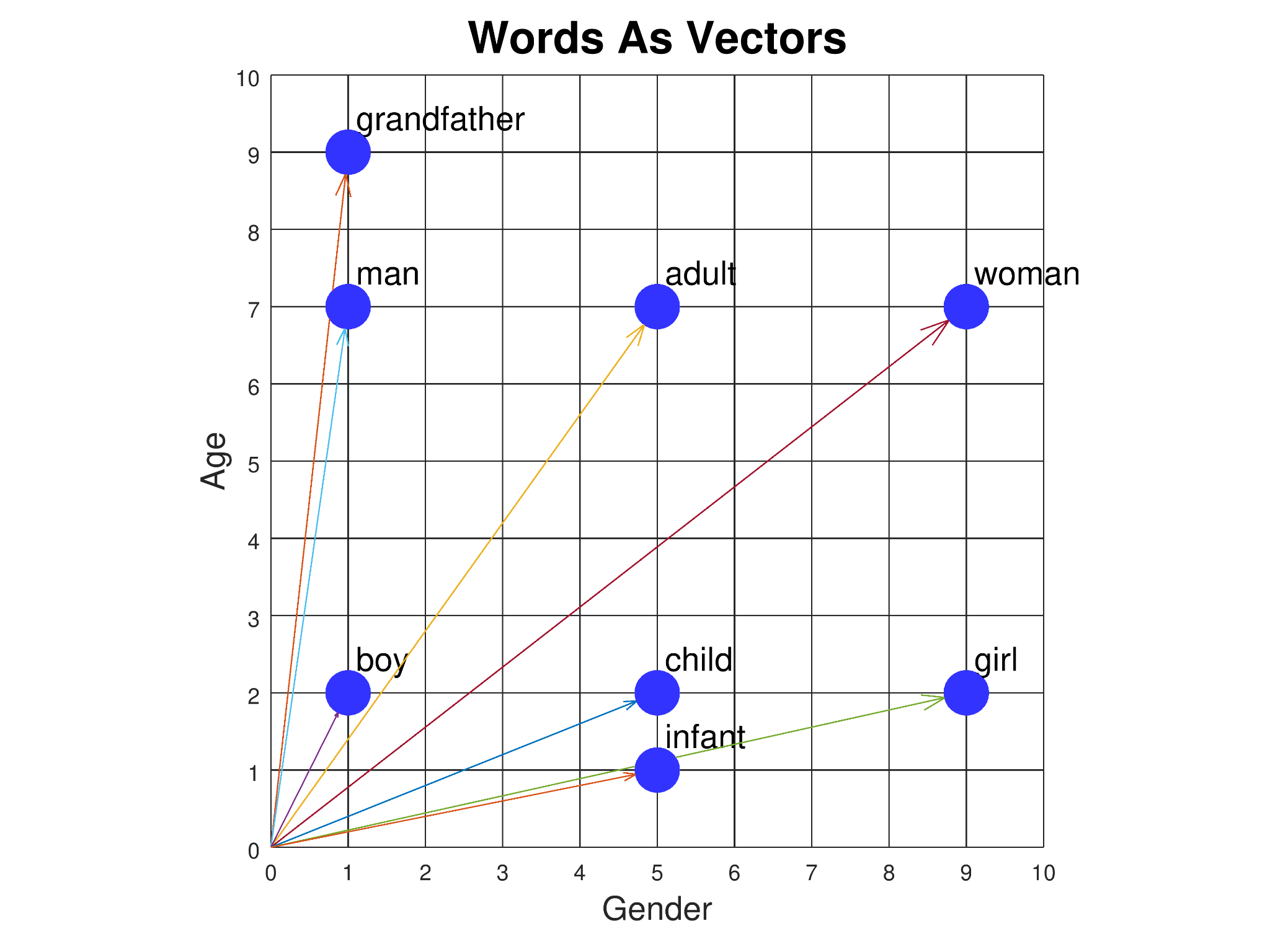
Exemple de vectorisation de mots sur 2 dimensions. On voit que les mots “child” et “infant” sont sémantiquement proches, alors que les mots “girl” et “grandfather” sont éloignés. Source cs.cmu.edu.
La vectorization (appelée aussi embedding) du texte se fait sur des milliers de dimensions, elle permet d’avoir une représentation du texte sur plusieurs domaines sémantiques.
Par un mécanisme appelé Attention, les transformers peuvent pondérer l’importance des différents mots ou domaines sémantiques. C’est un peu comme si vous étiez dans une soirée cocktail où tout le monde parle avec tout le monde mais vous arriviez étonnamment à vous concentrer sur la parole de votre acolyte malgré le bruit ambiant !
La sortie du modèle Chat-GPT (Generative Pretrained Transformer) à partir de 2020 met cet outil aux mains de tous. C’est un modèle de prédiction de langage : un LLM (Large Language Model).
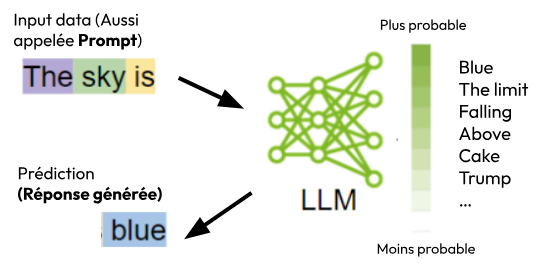
Source des pictogrammes : Blog Nvidia
On ne construit plus un modèle, on le consomme
Comment a été construit le modèle ChatGPT ? Et à quoi il ressemble ?
- Comme son nom l’indique, il a été pré-entraîné avec une quantité gigantesque de données publiques : des trilliards de mots (publications, encyclopédies, livres…) transformés en vecteurs
- Ce pré-entraînement a nécessité des semaines, consommé une énorme puissance de calcul et l’objet informatique qui matérialise le modèle est gigantesque (plusieurs milliards de paramètres)
- Il a donc été construit et mis à disposition par un tiers (la société privée OpenAI) sur le cloud
Pour la majorité des organisations, il est pratiquement impossible de construire à partir de zéro son propre LLM : cela nécessiterait un savoir-faire pointu, une collection et une curation de données et un environnement de calcul sur-puissant.
Elles sont donc amenées à consommer les modèles mis à disposition par les tiers, à travers le réseau, en payant à chaque prédiction - plus exactement au nombre de mots (= token) que contiennent l’input et l’output du modèle.
De nouveaux outils pour adapter le modèle
Consommer les LLM sans pouvoir les entraîner sur les données spécifiques de notre domaine métier constitue en apparence une perte de maîtrise. Aussi puissant soit-il pour générer des conversations naturelles, comment adapter un LLM pour répondre à mes besoins ?
Il est vrai que le LLM a quelques paramètres, notamment la température, qui contrôle le degré de créativité dans la réponse générée, mais ce n’est pas suffisant. Heureusement, deux boîtes à outils sont disponibles :
1- Le retrieval augmented generation (RAG)
Il s’agit d’injecter dans le prompt des données spécifiques au besoin (qu’on appellera contexte), que le LLM n’a probablement pas vu en pré-entraînement. Ceci adapte facilement et souvent avec grand succès le modèle de langage généraliste à notre cas d’usage métier.
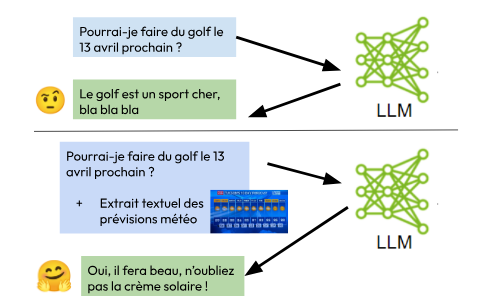
Illustration de comment le contexte ajouté au prompt améliore la réponse du LLM
La clé du succès est donc de mettre à disposition de notre application une collection de documents dont elle va choisir des morceaux pour les juxtaposer au prompt avant d'interroger le LLM avec ce prompt.
La préparation préalable de cette collection inclut :
- Le traitement et le découpage des documents en morceaux textuels (appelés chunks, généralement de quelques centaines de mots maximum) ;
- La transformation de ces morceaux dans le format numérique que comprennent les réseaux de neurones, c’est à dire des vecteurs ;
- L’enregistrement de ces vecteurs dans une base de données que va interroger (retrieval) l’application. D’où le nom que l’on donne à cette collection : Vector Store.
2- Le prompt engineering
Il s’agit tout simplement de trouver la meilleure formulation à l’input data (le prompt) afin que le texte généré par le LLM convienne à l’utilisation que l’on souhaite en faire. Le prompt engineering inclut des principes de bon sens, comme formuler des questions précises avec un rôle à jouer et des exemples de bonnes réponses. Il inclut aussi des techniques de structuration, comme le découpage du raisonnement en plusieurs étapes (Chain of Thoughts). Certaines de ces techniques sont générales, d’autres spécifiques au fournisseur de LLM.
Dans une application aux mains des utilisateurs finaux et faisant appel à l’IA générative, le prompt engineering va aussi s’occuper de combiner dans le prompt une structure fixe (template) avec l’input utilisateur.
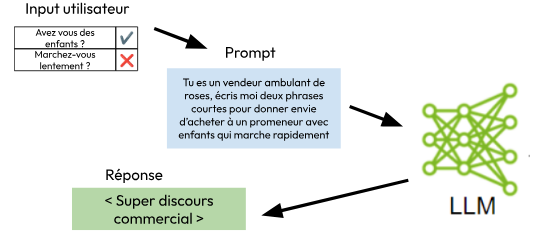
Exemple de prompt engineering qui combine l’input utilisateur avec une structure fixe (template)
Mais comment converger vers la bonne formulation du prompt ? Tout simplement avec des itérations et des essais !
De nouveau, l’évaluation
L’adaptation d’un LLM dans une application nécessite donc des itérations, dans lesquelles seront utilisées les deux outils ci-dessus (1- RAG et 2- prompt engineering). Il est indispensable de disposer, à la fin de chaque itération, d’une mesure de performance afin de décider si les modifications apportées vont dans le bon sens.
Dans le machine learning et le deep learning, nous devions constituer une input data suffisante, où la prédiction est connue et ce afin de valider le modèle. Nous devions aussi collecter la réalité future afin d’évaluer le modèle.
Dans l’IA générative, nous devons, dans le même esprit, constituer en nombre suffisant des couples d’exemples “input utilisateur + réponse souhaitée du LLM”. La constitution de cette collection est critique et il faut que sa qualité soit irréprochable. Elle permet de tester notre application et, par exemple, de voir dans quelles proportions l’application donne une réponse semblable à la réponse souhaitée.
Dans l’exemple suivant, nous voyons comment la première itération réalise un “score” de 0% sur la collection.

Après quelques itérations, le score peut être amélioré.
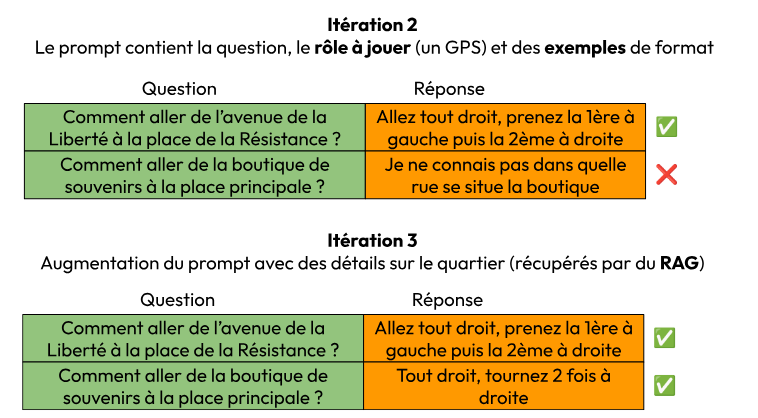
Notez que les réponses de la dernière itération ne sont pas strictement identiques aux réponses attendues, mais leur similarité nous permet de leur attribuer un succès.
La difficulté à trouver des exemples et à comparer les réponses du LLM à travers les itérations constitue le défi principal des applications d’IA générative.
En machine learning, il suffisait de relever les données structurées par une extraction plus ou moins automatisable. Ici, il faut faire appel davantage à l’expertise métier, verbaliser et parfois chercher un consensus d’experts.
L’intelligence artificielle générative a bel et bien besoin du regard fin de l'œil humain pour s’appliquer à nos cas d’usage métier. On revient donc à notre vendeur ambulant de roses et à sa bonne capacité d’observation des promeneurs !
Dernier mot
Quelle que soit la sophistication et la puissance des méthodes employées, l’intelligence artificielle se résume finalement à la génération d’une output data à partir d’une input data. Mais elle a besoin d’une bonne intégration dans l’écosystème d’un produit digital, sans quoi elle ne peut résoudre les problèmes métier. J’espère que ce texte apportera une compréhension partagée afin que cette intégration se fasse dans les meilleures conditions.
Pour aller plus loin
https://blog.octo.com/octo-vision-ai
https://blog.octo.com/cr-marine-dussaussois--la-recette-secrete-pour-echouer-vos-projet-de-data
https://blog.octo.com/le-produit-au-service-de-l'ia
Publication OCTO Culture Data et Industrie Vol. 1 par Frédéric Duvivier
Remerciements
Merci à Christelle Bergé, Frédéric Duvivier et Nora Kabbani pour leur relecture attentive.