Deep Learning à l’échelle : mieux annoter pour mieux scaler
Après quelques mois d’exploration et autres proofs of concept, notre restitution devant le sponsor fait un carton ! On a fait un PoC d’une architecture de réseaux de neurones à l’état de l’art pour détecter des défauts de fabrication sur des objets à partir d'images. Pour y arriver, on a conçu une application Python pour servir ce modèle de deep learning, et on a déployé le tout sur un serveur de démonstration, branché à un écran de restitution et une caméra, au 2e étage de notre digital factory.
Tout est validé sur la technique, nous avons eu le go business et le budget, y a plus qu’à passer à l’échelle !
Mais, ça veut dire quoi “passer à l’échelle” quand on fait du Machine Learning ?
Que se passe-t-il après le PoC ?
Par quel chantier est-ce que je dois commencer ?
Au travers de cet article, nous proposons de parcourir des questions essentielles à se poser à l’issue de la phase exploratoire pour aborder sereinement l’industrialisation d’un projet de data science et son passage à l’échelle.
🏭 Ça veut dire quoi "industrialiser" un projet de data science ?
Jusqu’à présent, notre projet d’IA, qui dure déjà depuis quelques mois, est à l’état exploratoire. C’est une phase par laquelle on a l’habitude de démarrer afin de dérisquer un tel projet: on souhaite valider son utilité et son utilisabilité auprès d’utilisateurs, peaufiner le business case, s’assurer de l’existence et de la possibilité d’exploiter des flux de données, vérifier la présence de signal et bien d’autres choses.
Parmi les livrables techniques de cette phase, on trouve généralement une étude au format Jupyter Notebook, dont voici un exemple, alternant entre blocs de code et descriptions textuelles: c’est un format dynamique et visuel, pratique en contexte exploratoire, qui permet au data scientist d’explorer plusieurs hypothèses et de les valider ou infirmer rapidement avec du code.
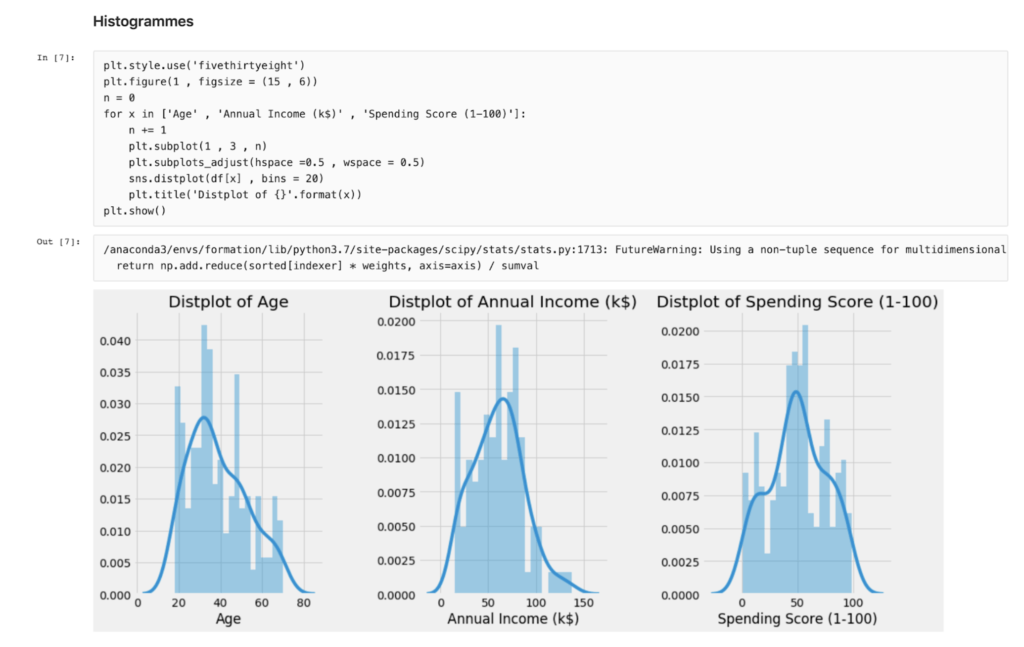
Extrait d’un notebook d’analyse de données en phase exploratoire
Généralement, un GO à l’issue de la phase exploratoire permet de poursuivre vers une phase d’industrialisation où les objectifs changent sur les plans business et technique: nous ne voulons plus juste répondre à des questions et lever des incertitudes mais désormais créer de la valeur pour les utilisateurs en allant jusqu'à proposer un service en production.
En l’état, le code issu du Notebook peut être vu comme de la dette technique car des hypothèses et des raccourcis ont été pris pour répondre à des questions, et ainsi le code résultant du POC ne nous permet pas d’aller en production. L'industrialisation est la phase de projet dédiée à traiter cette dette (tests automatisés, refactoring, …), mettre en place le monitoring de notre système de data science, automatiser les actions qui sont pour l'instant manuelles: récupération des données, leur nettoyage, feature engineering, entraînement des modèles, leur déploiement…
🏭🏭🏭 Ça veut dire quoi passer à l’échelle ?
Passer à l’échelle est plus ambitieux encore : il s'agit de proposer un service de data science en production, non pas pour une organisation, mais pour plusieurs à la fois. C’est un challenge technique et organisationnel auquel vient s’ajouter la complexité du machine learning.
Il ne s’agit pas ici de livrer uniquement du software auprès de plusieurs organisations: il y a aussi d'autres artéfacts à prendre en compte. Le code s’appuie sur un ou plusieurs modèles de machine learning à livrer. Cet ensemble (code + modèle(s)) doit fonctionner avec divers flux de données de production de qualité variable, aux distributions hétérogènes (car provenant de plusieurs organisations) et qui évoluent au cours du temps.
Un autre défi est qu'en plus de livrer notre application auprès de différentes organisations, nous devons livrer une application de Machine Learning qui y sera pérenne.

Les 3 dimensions du changement dans une application de ML - CD4ML
🧘 Qu'est-ce qu'une application de Machine Learning pérenne ?
Une application est pérenne si on peut la maintenir et la faire évoluer facilement, et surtout si elle continue à apporter de la valeur à ses utilisateurs au fil du temps. Cette définition, valable pour tout type d’applications, présente certaines particularités lorsqu’on parle de produits embarquant du Machine Learning. Il est essentiel de se rappeler que le modèle n’est qu’une petite partie du produit final ! Avoir un modèle pérenne ne garantit pas une application pérenne.
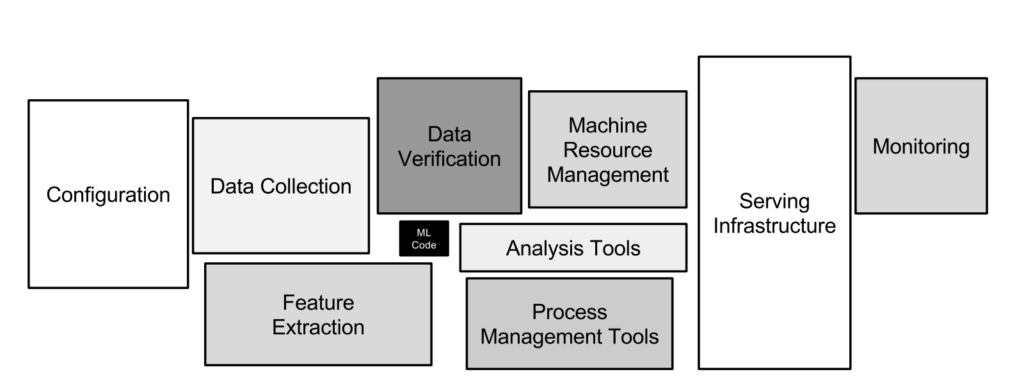
Le modèle n’est qu’une petite partie du produit final
Un modèle de machine learning est performant s’il peut être évalué, et pour lequel la métrique relevée est jugée satisfaisante.
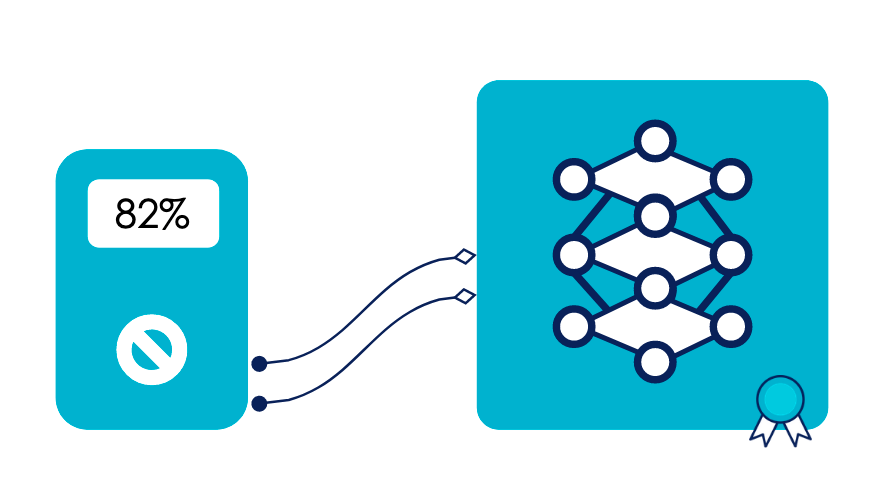
Un modèle pérenne est un modèle qui peut être évalué
Dans cet article, on qualifie de pérenne un modèle qui continue à être performant sur la durée. Cela sous-entend qu’il peut être évalué fréquemment sur de nouvelles données sur lesquelles il n'a pas été entraîné.
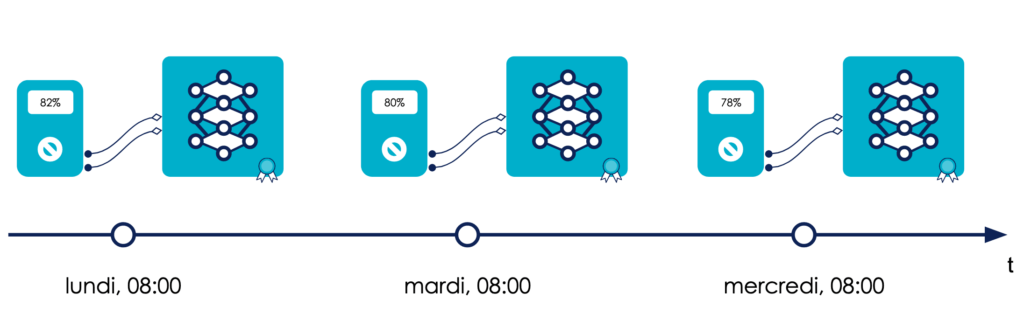
Un modèle pérenne est un modèle qui peut être évalué fréquemment.
Dans notre contexte de passage à l’échelle, nous souhaitons déployer notre système de détection de défauts sur des objets assemblés en usine. S’il y a 20 usines dans notre périmètre, nous les considérons comme 20 organisations indépendantes pour lesquelles il faudra individuellement déployer notre système de data science (code et modèle de Machine Learning), mais aussi mettre en place du monitoring afin de s’assurer que le système est pérenne, c’est-à-dire s'assurer qu’il a le comportement attendu dans chaque organisation sans exception, et dans la durée.
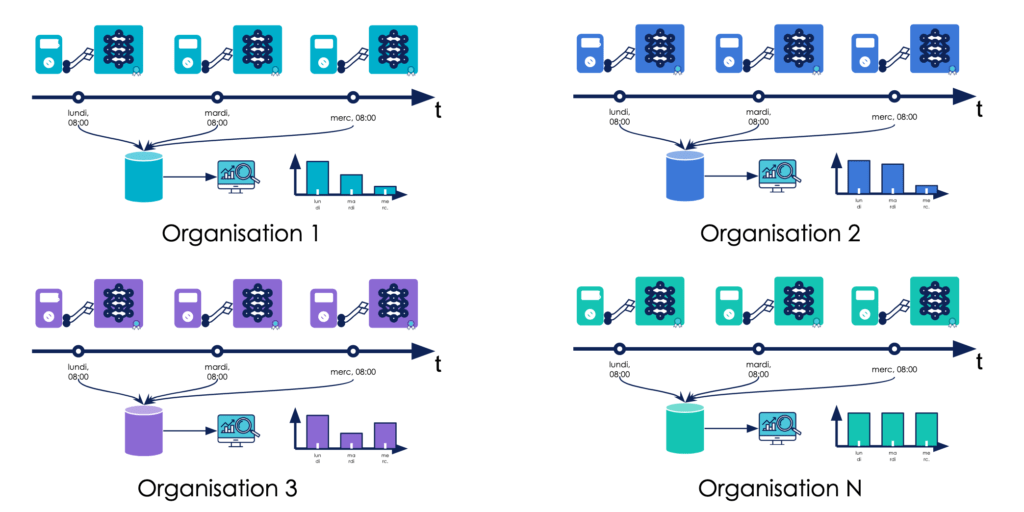
Un modèle pérenne “à l’échelle” est donc un modèle dont les performances peuvent être monitorées dans chaque organisation où il est déployé et sont jugées satisfaisantes partout
Une méthodologie pour aborder le monitoring de modèles de Machine Learning et identifier des métriques pertinentes à suivre au cours du temps est disponible sur le blog OCTO, ici.
Evidemment, ce dernier schéma se veut assez démonstratif et générique: il pourrait être plus intéressant d’avoir une unique base de donnée pour centraliser les mesures provenant des différentes organisations ou même de déployer un modèle de ML différent, spécialisé selon les besoins d’une organisation. Ce sont des considérations d'architecture que nous n'abordons pas dans cet article.
😞 Mon modèle n’est plus bon, qu’est-ce que je fais ?
Il est assez ambitieux de s’engager à livrer un modèle de Machine Learning pérenne: le résultat d’un modèle est fonction de la donnée qu’il rencontre en production, volatile par nature. Il existe toute une littérature sur les drifts permettant d’investiguer pourquoi nos modèles ont de mauvaises performances. Celles-ci peuvent avoir pour cause la nature changeante des données de production:
le concept drift, quand la cible à prédire évolue au cours du temps (un exemple de label concept drift détaillé ici),
le data drift, quand les propriétés statistiques des variables explicatives évoluent,
ou encore l’upstream drift quand des changements opérationnels sur les pipelines de traitement de données ont des répercussions sur la qualité du modèle.
O’Reilly propose une première piste d’investigation sur son blog. On peut y trouver un article complet sur le sujet du debugging de modèles pour comprendre pourquoi un modèle de machine learning ne fonctionne plus comme souhaité. De nombreux outils y sont présentés comme l’analyse de sensibilité, l’analyse de résidus, diverses techniques d’audit ou d’interprétabilité. Ainsi, remédier aux mauvaises performances d'un modèle en éditant ses poids identifiés comme fautifs devient alors une solution envisageable avec de telles techniques, quand la structure du modèle s’y prête.
Une autre technique permettant d'adresser ce problème de performance est celle du réentraînement de modèle : relancer une phase d'entraînement à partir d’un modèle existant et de données nouvellement acquises dans l'espoir de parvenir à un nouveau modèle plus robuste et plus adapté aux données de production récentes. Appliquée régulièrement, c’est une technique efficace pour pallier à la nature changeante que la donnée peut avoir en production.
📸 De quelles données ai-je besoin pour réentrainer mon modèle ?
Notre contexte projet étant tourné vers la computer vision, nous pouvons restreindre le champ des possibles à des images. Mais, est-ce suffisant ? Pouvons-nous utiliser n'importe quelle image pour réentrainer un modèle et améliorer ses performances ?
En production, notre système de computer vision réalise des prédictions sur des images prises en usine avec une caméra au format PNG. Il convient donc de réentraîner notre modèle avec des images prises dans cette même usine, avec cette même caméra, dans le même format, avec la même compression, idéalement en conditions de prise de vue maîtrisées: c’est-à-dire avec le même angle de caméra et une luminosité similaire. Il est important de limiter les écarts entre les données que nous allons utiliser pour un réentraînement et les données que le modèle rencontrera en production si nous souhaitons obtenir des résultats concluants.
On pensera aussi à proscrire les données temporaires issues d’un générateur d’images custom ou bien encore les photos prises sur place avec son smartphone “pour dépanner, en attendant de pouvoir se brancher sur les flux de données réels qui arriveront le mois prochain”. Malgré la bonne volonté qui peut amener ce genre d'initiatives, ces données temporaires sont généralement peu exploitables, et peuvent même être contre-productives car trop éloignées des données de production (caméra différente, format différent, compression différente de la réalité terrain, …).
On cherchera aussi à obtenir des images exploitables: qui ne soient pas floues, qui ne soient pas obstruées (par une personne qui passe devant l'objectif au mauvais moment), où l'on discerne clairement les objets d'étude et où l'on discerne clairement les spécificités à prédire sur ces objets (du texte, des défauts de fabrications, …).
Néanmoins, avoir des images de qualité ne suffit pas, il est nécessaire que ces images soient aussi annotées.
📝 Qu'est-ce qu'une annotation ?
Une annotation peut prendre des formes bien différentes:
une valeur continue pour une régression,
une valeur discrète pour une classification,
un rectangle pour de la détection d'objet,
une série de pixels pour de la segmentation sémantique.

Une image accompagnée d'une annotation pour la classification
Dans notre contexte de détection de défauts sur des objets, nous chercherons donc à annoter des photos centrées sur ces objets, en dessinant un rectangle autour de chaque défaut identifié. Cela permettra, lors de la phase d'entraînement d'indiquer au modèle les zones de pixels contenant un défaut et qu'il devra apprendre à détecter.
🙋 Qui annote ?
La réponse à cette question dépend du cas d'usage à traiter.
Dans certaines situations, la donnée porte elle-même l’annotation. C’est le cas par exemple pour des problèmes de prédiction (forecasting) de séries temporelles : on peut considérer comme entrée les valeurs de la série temporelle jusqu’à l’instant t, et chercher à prédire la valeur à l’instant t+1. L’annotation est alors cette valeur à t+1, dont on dispose déjà si on a continué à mesurer notre donnée temporelle.
Dans d’autres situations, typiquement pour la détection de défauts sur des objets, l’annotation peut demander une connaissance métier spécifique. Il faut donc qu’un humain, avec cette connaissance métier suffisante, observe un certain nombre de photos et fournisse une annotation pour chacune d’elles.
Un point essentiel pour passer à l’échelle un modèle supervisé est donc de passer à l’échelle l’activité d’annotation. Il faut anticiper la disponibilité des annotateurs ayant la connaissance métier suffisante ainsi que leur nombre.
Il faut également bien cadrer les modalités de cette activité : nombre de personnes, nombre d’images à annoter par personne, fréquence à laquelle de nouvelles images sont annotées… En effet, une solution de deep learning pour réaliser de la computer vision en milieu industriel, déployée sur un seul site et qui produit le même type de pièces, sera moins gourmande en annotations qu’une solution déployée sur 20 sites fabriquant des produits variés.
Plus globalement, le besoin en annotations est très lié à la variabilité et à l’évolution de la distribution des données d’entrée. Il est donc indispensable, en amont du projet, de bien cadrer le périmètre du projet :
nombre de sites où il faudra déployer, et les échéances associées,
fréquence d’évolution du type de pièces produites sur un même site,
changements prévus au niveau de la configuration de la ligne de production: déplacement de la station d’acquisition de photos, changement de luminosité, déplacement des postes des opérateurs…
En fonction des résultats de ce cadrage, on peut essayer d’estimer le nombre d’annotateurs nécessaires et la fréquence à laquelle ils doivent produire de nouvelles annotations. En effet, dans la plupart des cas, l’annotation ne doit pas être un effort à produire une fois au début du projet, mais une activité en flux, continue et régulière tout au long de celui-ci, comme nous l'abordons dans cet autre article. Cette vision de l’annotation comme une activité à part entière du passage à l’échelle a pour objectif de pallier aux problèmes de data drift évoqués précédemment.
On notera qu'il est aussi possible d'outsourcer les équipes d'annotations, mais cette décision demande généralement de faire un compromis entre la quantité des annotations produites, qui va certainement augmenter, et la qualité des annotations, qui risque de baisser puisqu'on ne fait plus appels à des experts métiers pour les réaliser.
✍️ Comment annoter ?
La réponse peut paraître simple: il suffit d'envoyer une photo à un annotateur et il n'a plus qu'à entourer les zones oú il voit des défauts avec son stylo. Toutefois, le modèle, pendant son entraînement, a besoin d'accéder aux coordonnées de pixels des points constituant le rectangle dessiné de manière programmatique.
L'annotation est donc généralement réalisée au travers d'une application dédiée, un outil d'annotation d'images, pour lequel on attend au moins les fonctionnalités suivantes:
Pouvoir y charger des images à annoter, et extraire les annotations réalisée par API,
Dessiner des rectangles (ou autre forme) sur des images,
Pouvoir déplacer et redimensionner ces rectangles simplement.
Dans une optique de passage à l'échelle, oú le nombre d'annotateurs peut fortement croître, on attend aussi:
De la gestion d'identité pour que des annotateurs puisse s'y connecter et accéder aux images de façon sécurisée,
Pouvoir répartir des annotations selon des règles métier au sein d'un pool d'annotateurs via une vue d’administration,
Permettre à des annotateurs de faire de la revue sur les annotations des autres, dans une démarche d'amélioration de la qualité des données,
Potentiellement, de la gestion de droits et de la ségrégation de contenu si on ne veut pas que tous les annotateurs ait accès à toutes les données.
Il est possible de développer soi-même un tel d'outil d'annotation, mais des services proposant ce genre de fonctionnalités existent déjà et peuvent nous faire gagner du temps, comme Labelbox, Hive Mind ou encore Supervise.ly. C'est un compromis build vs buy : vaut-il mieux investir dans la fabrication d’un outil d’annotation taillé au mieux pour ses besoins ou bien s’appuyer sur un outil sur étagère, pré-packagé mais plus générique ?
🧰 Comment récupérer les annotations ?
En se servant de cet outil, les annotateurs vont l'alimenter en annotations, mais encore faut-il pouvoir récupérer ces annotations dans un format qui sera exploitable par notre modèle.
Plus tôt, nous énumérions les fonctionnalités essentielles que nous attendons d'un outil d'annotation, et exposer une API permettant de récupérer des annotations à la demande en fait partie. C'est le cas par exemple de Labelbox, que nous avons pu tester, et qui propose une API en GraphQL ou en Python permettant de récupérer une ou plusieurs annotations réalisées dans l'outil via HTTP, au format JSON, par exemple:
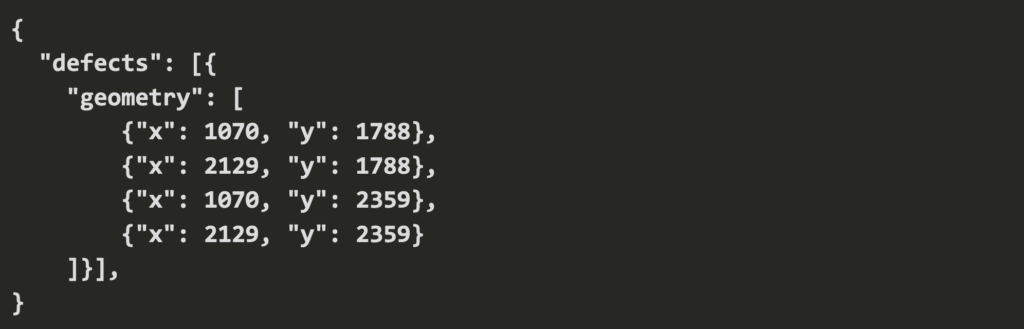
Annotation d'un défaut de fabrication sous la forme de coordonnées d'un rectangle
Avoir une API à disposition est d'autant plus crucial dans un contexte de passage à l'échelle oú les annotateurs, les organisations et leurs besoins se multiplient. Un tel niveau d'automatisation est nécessaire pour réagir rapidement aux besoins d'évaluations et de réentrainement de modèles, par opposition par exemple à un système de ticketing oú l'on demanderait à quelqu'un de bien vouloir nous extraire des annotations manuellement sous un délai d'une semaine.
📈 Comment mesurer l’avancement des annotations ?
A mesure que le nombre d'annotateurs augmente, il peut devenir difficile de suivre l'avancement des annotations.
Il peut être judicieux de construire des dashboards permettant de monitorer l'avancement d'une campagne d'annotations, avec des indicateurs tels que:
le nombre d'images annotées par jour pour chaque annotateur ou par équipe d'annotation,
le nombre d'images que les annotateurs n'ont pas réussi à annoter, par jour. Cet indicateur peut aider à identifier en aval des soucis de qualité de données.
Le nombre total d'images annotées sur la campagne en cours, à comparer avec l'objectif cible, ex: je peux voir aujourd'hui que les annotateurs ont produit 800 annotations sur les 1500 attendues.
L'objectif de ces indicateurs est de pouvoir vérifier dans la durée si les annotateurs arrivent à avancer au bon rythme ou si quelque chose bloque leur avancement. Il est toujours intéressant d'obtenir ce feedback en avance plutôt que de découvrir le jour de la livraison que nous n'aurons pas suffisamment d'annotations pour effectuer un réentraînement.
✔️ ❌ C’est quoi une bonne annotation ?
Nous arrivons enfin à produire des annotations au rythme souhaité, mais comment savoir si ces annotations sont exploitables ? Est-ce que des annotations produites pour une même image sont exploitables si plusieurs annotateurs se contredisent (ex: 2 annotateurs voient un défaut sur un objet dans une image, et 8 annotateurs jugent qu'il n'y en a pas) ?
Il peut être intéressant de consacrer du temps, régulièrement, à une phase d'exploration de ces données annotées pour voir si de telles situations se produisent. Cet article propose des métriques intéressantes pour mesurer à quel point les annotateurs arrivent à s'accorder sur les annotations produites comme le score du kappa de Cohen pour mesurer la cohérence entre des observations.
⚙️ Il y a beaucoup de choses à faire, comment ne rien oublier ?
En résumé, pour faire du deep learning de façon pérenne, il faut :
Savoir mesurer la performance des modèles déployés en production et détecter quand ils ont besoin d’être mis à jour,
Récupérer régulièrement de nouvelles données (images) dont les propriétés sont proches de ce que le modèle va rencontrer en production,
S’assurer de la qualité de ces données,
Récupérer des annotations de bonne qualité, en nombre suffisant, de façon régulière, produites par des personnes qui ont la connaissance métier nécessaire,
Mesurer l’avancement de l’activité d’annotation pour ajuster le travail demandé aux annotateurs,
Réentraîner les modèles sur les nouvelles données annotées,
Déployer ces nouvelles versions des modèles en production.
Effectuer l’ensemble de ces tâches manuellement est chronophage et propice aux erreurs humaines. Cela est encore moins gérable si l’on doit faire ce travail “à l’échelle”, c’est-à-dire pour plusieurs organisations en même temps. Il est donc indispensable d’automatiser autant que possible ces processus afin de s’assurer de leur reproductibilité et que le passage à l’échelle se fasse sans douleur.
On peut par exemple planifier des flux réguliers pour récupérer les données et les annotations, en les associant pour qu’elles soient facilement exploitables par un modèle. On peut aussi s’outiller pour fournir aux annotateurs, à la demande, de nouvelles images à annoter. On peut planifier une évaluation systématique des modèles actuellement déployés, sur la base des dernières données annotées disponibles. On peut aller encore plus loin et déclencher un réentraînement automatique dès que la performance des modèles passe en dessous d’un certain seuil.
Selon l’organisation et la criticité des modèles dans la prise de décision métier, on pourra aller plus ou moins loin dans l’automatisation. L’important est d’automatiser les étapes du processus qui s’y prêtent, pour pouvoir se concentrer ensuite sur les tâches à forte valeur ajoutée.
Conclusion
Passer à l'échelle un système de Machine Learning n'est pas chose aisée. Il y de nombreux sujets à cadrer, développer, déployer et automatiser.
En plus des bonnes pratiques de développement logiciel en général, il y a plusieurs aspects spécifiques à la data science à prendre en compte : la récupération de données de qualité, la production d’annotations, l’évaluation des modèles prédictifs sur la base du feedback utilisateur et selon des métriques métier pertinentes, l’évolution des modèles via le réentraînement ou d’autres techniques.
Cette diversité de sujets implique de mobiliser plusieurs métiers : des data scientists certes, mais aussi des experts métiers, des annotateurs, des développeurs, des OPS.
Avant de se lancer dans l’industrialisation d’un projet de data science, nous vous proposons donc de vous poser les questions suivantes, à la manière d'une checklist. Celle-ci est le produit de nos réflexions et de nos expériences, dans un contexte industriel avec des contraintes spécifiques. Bien que n’étant pas exhaustive, nous espérons qu’elle vous donnera des idées pour mieux cadrer les projets d’industrialisation de Machine Learning, et aborder sereinement le passage à l’échelle :
🏭 Ça veut dire quoi "industrialiser" un projet de data science ?
🏭🏭🏭 Ça veut dire quoi passer à l’échelle ?
🧘 Qu'est-ce qu'une application de Machine Learning pérenne ?
😞 Mon modèle n’est plus bon, qu’est-ce que je fais ?
📸 De quelles données ai-je besoin pour réentrainer mon modèle ?
📝 Qu'est-ce qu'une annotation ?
🙋 Qui annote ?
✍️ Comment annoter ?
🧰 Comment récupérer les annotations ?
📈 Comment mesurer l’avancement des annotations ?
✔️ ❌ C’est quoi une bonne annotation ?
⚙️ Il y a beaucoup de choses à faire, comment ne rien oublier ?