Découpler son architecture de ML pour en accélérer le delivery
Cet article fait partie de la série “Accélérer le Delivery de projets de Machine Learning**”, traitant de l’application d’Accelerate [1] dans un contexte incluant du Machine Learning. Si vous n’êtes pas familier avec Accelerate, ou si vous souhaitez avoir plus de détails sur le contexte de cet article, nous vous invitons à commencer par lire l’article introduisant cette série**. Vous y trouverez également le lien vers le reste des articles pour aller plus loin.
Accelerate présente la capability "Loosely Coupled Architecture" comme un mode d'organisation du code qui accélère la vitesse du delivery tout en entretenant la qualité de ce qui est livré. Dans un projet de Machine Learning (ML), différents éléments de code peuvent être organisés. Nous allons voir comment peut évoluer un projet de ML, et pourquoi il est pertinent de découpler et découper à mesure de son évolution.
Si l'on situe ces éléments de code d'un point de vue opérationnel, nous avons :
- Le service d'entraînement : c’est le code qui reçoit en entrée des données et qui produit en sortie un modèle
- le code applicatif : manipulable par une interface graphique ou programmatique
- le code d’inférence : le code qui, à partir de données et d'un modèle, permet d’avoir des prédictions
- le code d’infrastructure : décrivant l'organisation opérationnelle de nos artefacts
- la configuration : permettant de changer le comportement d'une application sans la reconstruire
Ce n’est pas toujours aisé d'organiser ce qui fait partie du code d’entraînement, d’inférence ou du code applicatif, car les contours sont souvent flous. Définir les contours est ce que l’on appelle de l’architecture logicielle. Lors de l’évolution d'un projet, ces éléments de code devront être régulièrement réorganisés. Cependant cette réorganisation peut être complexe quand les éléments de code dépendent les uns des autres. Comment alors faire en sorte que l'évolution et le déploiement de l'un d'eux n'impacte pas ou peu les autres ? Au fond, qu’est-ce qu’il faut coupler ou découpler pour améliorer notre vitesse de développement en garantissant la qualité du projet ?
Avant de débuter, quelques remarques pour accompagner la lecture :
- Des éléments sont couplés lorsqu'ils dépendent l'un de l'autre. Par exemple, dans une base de code, deux classes sont couplées lorsque la modification de l'une impacte l'autre. Le couplage permet notamment de faciliter la gestion en permettant que chacun "connaisse" directement des attributs internes à l'autre sans passer par des abstractions.
- Des éléments sont découplés lorsqu'ils peuvent évoluer sans s'impacter. Par exemple, dans une base de code, deux classes sont découplées lorsque la modification de l'une n'impacte pas l'autre. Le découplage éléments permet plus de modularité et d’évolutivité, et donc moins de friction lors de l'évolution entre des éléments, notamment en limitant les accès par des abstractions. (ex: des contrats d'interface)
- Découper un élément signifie le diviser en plusieurs éléments. Par exemple, on pourrait répartir le code d'une classe dans deux classes. En revanche, découper une classe n'implique pas que les classes résultantes seront automatiquement découplées. Prenons comme exemple une classe avec deux fonctions, l'une d'elles permet d'aller chercher des utilisateurs dans une base, et l'autre fonction utilise la première puis dresse une liste ordonnée des utilisateurs en fonction de leurs attributs. En répartissant simplement ces deux fonctions entre deux classes, nous aurons toujours une fonction qui dépend de l'autre, donc un couplage.
Dans la suite de cet article, nous allons approcher le sujet du découplage par les besoins de découpage des éléments de code.
Pour illustrer nos propos, nous prenons le cas simple d’une application qui affiche des actualités et propose des articles à la fin d'une lecture. Dans cet exemple, la fonctionnalité “Recommandation d’articles” est un algorithme de machine learning* qui propose des articles à l’utilisateur.*

Une application qui affiche des actualités
Ce que l'on voit le plus souvent sur le terrain quand on démarre un projet de ML
Afin de déterminer la forme que prennent les projets de ML, nous avons demandé à différentes équipes ce qu'elles ont mis en place. Ce qui est ressorti des interviews, c'est qu'à moins que la partie ML du projet soit directement à l'usage de plusieurs consommateurs, les projets débutent en embarquant leurs artefacts de ML avec le code qui a besoin de la fonctionnalité de ML. En effet, au début d'un projet, le cycle de vie des artefacts de ML est très proche de celui du reste du projet vu que cette fonctionnalité n'a qu'un consommateur. Ce sont donc les besoins métiers liés à ce consommateur qui rythmeront les évolutions de l'application et de sa partie ML.
Analogies avec les architectures micro-services
Ces choix en début de projet rappellent les stratégies d'organisation de services entre une architecture monolithique et micro-services : à moins d'un besoin d'évolutivité à un rythme différent du reste de l'application, pas besoin de le détacher en un service du reste du projet, même en prévisionnel. Martin Fowler pressentait déjà cette approche monolith-first en 2015, en proposant de partir d'un bloc pour en découvrir la complexité métier d'une application. Au début de son développement, la découverte des différents domaines, de leur complexité et de leur interdépendance provoquera de nombreux refactoring et discussions. Ce qu'il y a de pratique avec un monolithe, c'est qu'il est simple de changer les contrats d'interface entre les fonctions et classes d'une même base de code, puis de gérer le déploiement d'un bloc de ces différentes parties puisqu'elles font partie de la même application. Cela permet aussi que chaque expertise (data-scientist, dev front, back, UX, ...) fasse partie du même tout lors des prises de décision pour orienter le projet dans son ensemble.
Cependant, même si la partie ML est regroupée avec le reste du code de l'application, chaque fonctionnalité implémentée dans le code est bel et bien découplée pour assurer la maintenabilité de chaque partie. Dans le cas du ML, c'est-à-dire que des interfaces claires entre la partie production de données ML et consommation de ces données sont définies. Il en résulte qu'au sein de la base de code, si la partie ML fournit toujours le même contrat d'interface, elle peut évoluer techniquement sans impacter le reste du projet.
Un exemple d'architecture de début de projet de ML
Le schéma ci-dessous représente un exemple d’architecture d’un projet de ML en début de cycle de vie que nous avons pu rencontrer. On remarque que le pipeline d'inférence est séparé de l'application lors de l'exécution et que les prédictions produites sont déversées dans une base à disposition de l'application. Cependant, le code d'inférence et le modèle se trouvent dans le même repository git que le code du reste du projet, et ces deux parties sont gérées par la même équipe. D'ailleurs, le pipeline de déploiement prend en charge ces deux parties et les déploie simultanément.
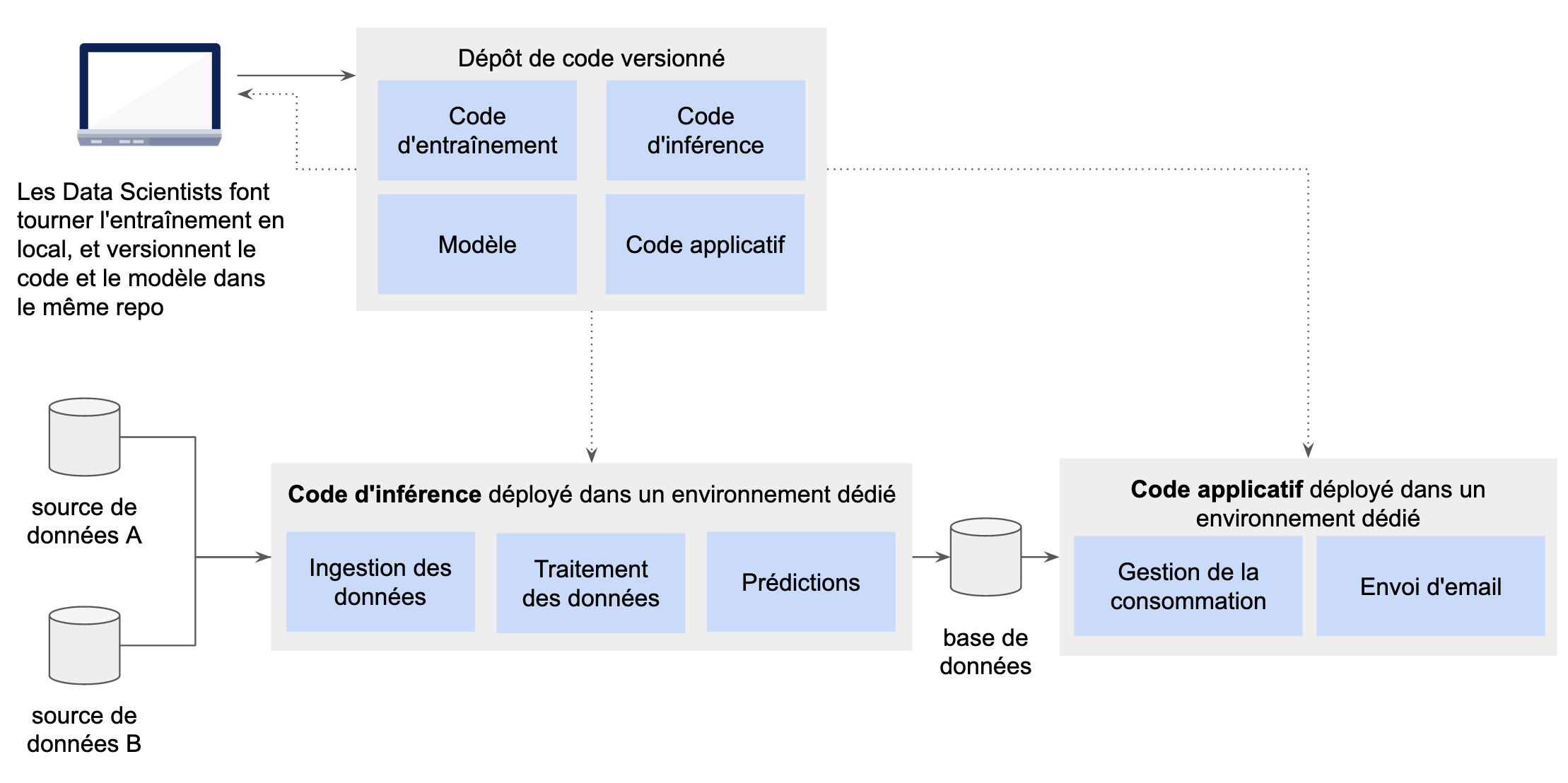
Le code de ML, le modèle et le code applicatif sont couplés au sein de la même base de code, et du même pipeline de déploiement donnant lieu au déploiement de 3 artefacts : le pipeline d'inférence, son modèle et le reste du code applicatif
Ici, la frontière entre le code d'inférence et le reste de l'application se situe au niveau de la base de données : le code applicatif consomme directement les produits du code d'inférence dans sa base de données. Dans ce cas, ces deux parties du code (producteur et consommateur) partagent la même structure de données. Cependant, avec une approche telle que la clean architecture, les aspects techniques de la partie ML sont suffisamment découplés pour permettre la maintenance technique du code d'inférence sans impact sur le reste du code applicatif. En revanche, dans le cas d'une évolution métier, c’est-à-dire dans le cas où la nature des attributs de la structure de données change, les impacts iront du code d'inférence au code applicatif, mais bien entendu aucune forme de découplage ne permettrait de se prémunir de ce type d'impact, même si la partie ML était dans un micro-service. En conclusion, pour un projet de ML avec une fréquence de réentraînement quotidienne, tout regrouper dans une base de code et un pipeline de déploiement est une solution qui simplifie la gestion des artefacts et qui convient à une équipe de petite taille. Cependant, au sein du même repository, on prend soin de découpler tout de même les différents contextes.
Si vous avez saisi l'intérêt du découplage, vous vous posez certainement la question : quelles techniques utiliser pour découpler ? Cette question ne sera pas traitée dans cet article car elle n'est pas spécifique au Machine Learning. En revanche, vous trouverez ce que vous cherchez à travers des outils comme Domain Driven Design, l'Architecture Hexagonale, ou encore la Clean Architecture, qui vous donneront des pistes sur comment organiser votre code d'inférence et les consommateurs des produits de ce pipeline.
Dans le cadre de notre exemple de site d'actualité, le métier souhaiterait dans un premier temps avoir des recommandations avec une fraîcheur d’une fois par jour. Pour ce besoin métier, on choisit de tout coupler au sein de la même base de code pour simplifier la gestion de nos artefacts et des déploiements. Le produit de notre pipeline d'inférence qui génère les recommandations se trouvera dans la base de données de l'application et le résultat sera partagé entre tous les utilisateurs.
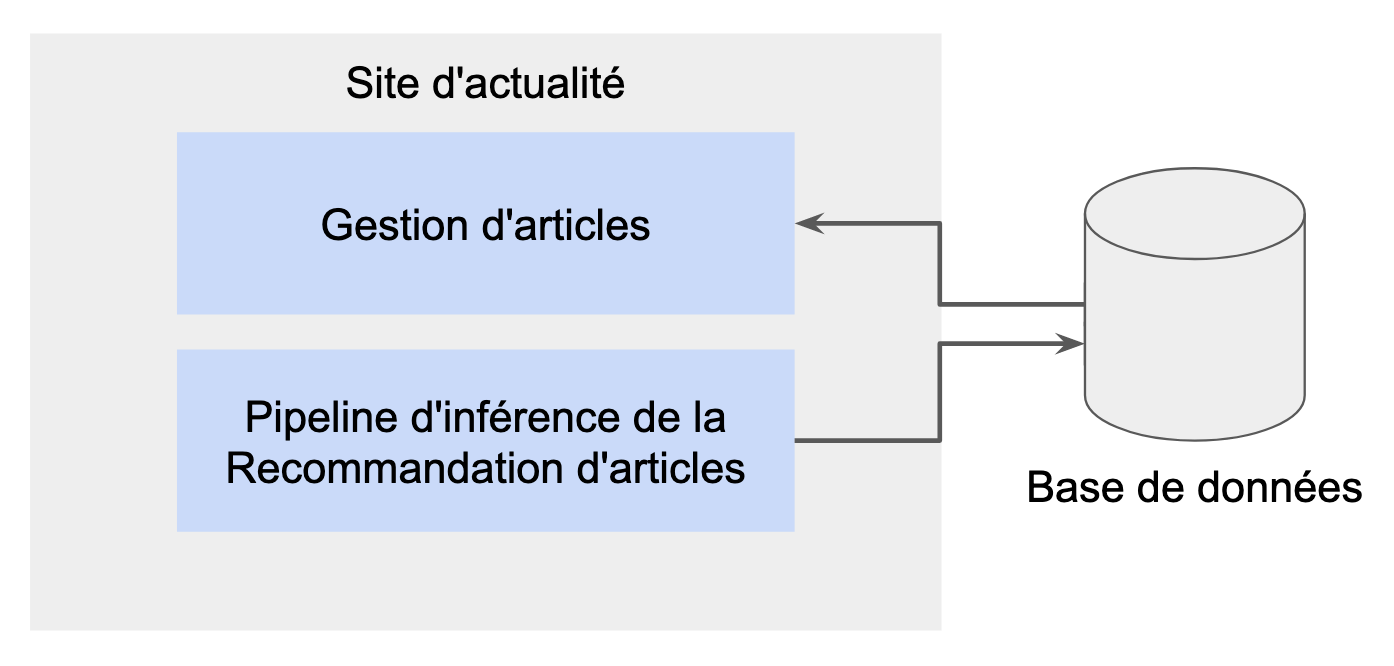
Le pipeline d'inférence est interne à l'application et met à disposition ses résultats à travers la base de données
Quelles évolutions pour la suite de notre projet de ML ?
Après une campagne de tests utilisateurs, le métier s’est rendu compte que les utilisateurs se plaignaient d’avoir les mêmes recommandations lorsqu’ils se connectent plusieurs fois par jour. Il souhaite donc faire évoluer l’application afin qu’à chaque affichage d'article, de nouvelles recommandations soient proposées.
Jusque-là, nous avons vu qu'au début de la vie d'un produit son découpage technique en plusieurs services peut être prématuré, mais cette question se repose souvent lorsqu'un monolithe évolue. Dans notre fil rouge, un nouveau besoin métier émerge : la nécessité pour les utilisateurs d’avoir des recommandations à la demande et non plus journalières, c'est-à-dire à chaque connexion à l’application. Le service va donc nécessiter plus de ressources que dans sa première version. À ce moment-là on peut se poser la question : est-il pertinent de découper le pipeline d'inférence du reste de l'application ? La réponse à la question du découpage n'est pas évidente car si ses promesses de scalabilité organisationnelle et technique font rêver, maîtriser l'évolution d'une telle architecture est plus complexe que celle d'un monolithe (plus d'explication dans cet article). Pour s'orienter lors de ce questionnement, voyons 3 cas de figure :
Pas de découpe organisationnelle ni technique
Si lorsque l'on fait évoluer une partie d'une application, son développement et son déploiement ne gênent pas l'évolutivité et la disponibilité des autres parties de cette même application, alors leurs cycles de vie n'entrent pas en conflit. On a déjà peut-être une bonne vitesse d'évolution et une bonne fiabilité. Ce pourrait être un cas idéal de découpage dans un autre service voir même avec une nouvelle équipe car celui-ci serait déjà indépendant des autres. Pourtant, gérer l'infrastructure d'un composant supplémentaire n'a rien d'anodin et complexifie la maintenance du système au global. Le mieux est donc au final de ne pas découper, et de continuer de faire grossir le monolithe en préservant le découplage des parties.

Chaque fonctionnalité évolue sans impact majeur sur le reste de l'application. L'équipe conserve son organisation et son architecture tant que ça convient
Découpe organisationnelle
Si dans le même cas que précédemment le cycle de vie des services de l'application ne sont pas en conflit, mais que le métier demande de plus en plus d'évolutions et que le goulot d'étranglement se situe au niveau de la capacité à faire de l'équipe, alors une découpe et une augmentation de la taille de l'équipe peut être pertinente.
La fonctionnalité A gagne en complexité et devient un domaine métier à part entière. Le découplage permet de concentrer une équipe sur celle-ci sans changer d'architecture
En effet, si ce service est indépendant des autres et qu'il est correctement découplé de ceux-ci, il est possible d'avoir une équipe exclusivement sur cette partie dans la même application sans ralentir le reste du projet, voire même en accélérant son développement. C'est un des effets du découplage analysé par Accelerate : une architecture correctement découplée permet le passage à l'échelle. Ce conseil semble être à l'opposé de la loi de Brooks : "Ajouter des personnes à un projet en retard accroît son retard". Dans l'étude d'Accelerate, il est pourtant démontré que les projets dans lesquels l'architecture est faiblement couplée peuvent augmenter à mesure qu'une équipe grandit, ce qui n'est pas le cas des projets avec un couplage fort. On pourrait alors préciser le conseil par "Ajouter des personnes à un projet en retard, et avec un couplage fort entre ses parties, accroît son retard".
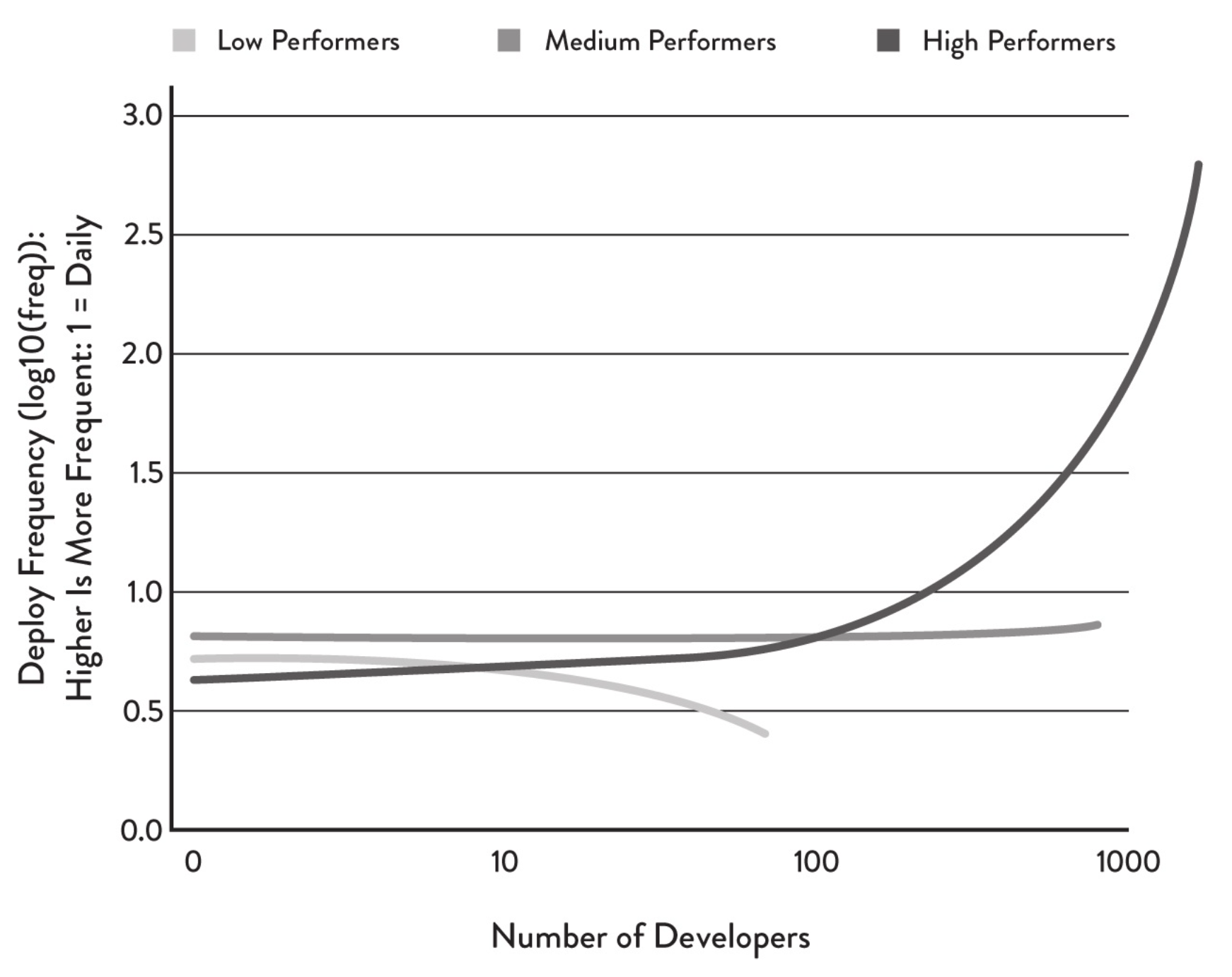
Nombre de déploiements par développeur par jour (source: Accelerate)
Découpe technique
Si lors de son exécution l'un des services découplés du reste de l'application consomme la plupart des ressources de la machine et qu'il dégrade les performances des autres services, il est possible de le découper du reste de l'application pour en gérer le scaling. Possible, mais pas systématique car lorsque l'on développe une application stateless on peut simplement la scaler dans son entièreté pour augmenter la capacité à recevoir les demandes (gare cependant à d'autres ressources comme les connexions ouvertes sur les bases de données). Mais dans le cas où ce service gourmant en ressources n'est utilisé que ponctuellement, scaler l'ensemble en permanence n'est probablement pas une solution économiquement viable. Dans ce cas, il peut être pertinent de profiter de l'élasticité d'un cloud pour que l'infrastructure de ce service ne soit déployée qu'au moment de son usage. Cette découpe est d'ailleurs effective dans le schéma plus haut qui montre que l'inférence est détachée du reste de l'application, alors même qu'ils se trouvent dans la même base de code.
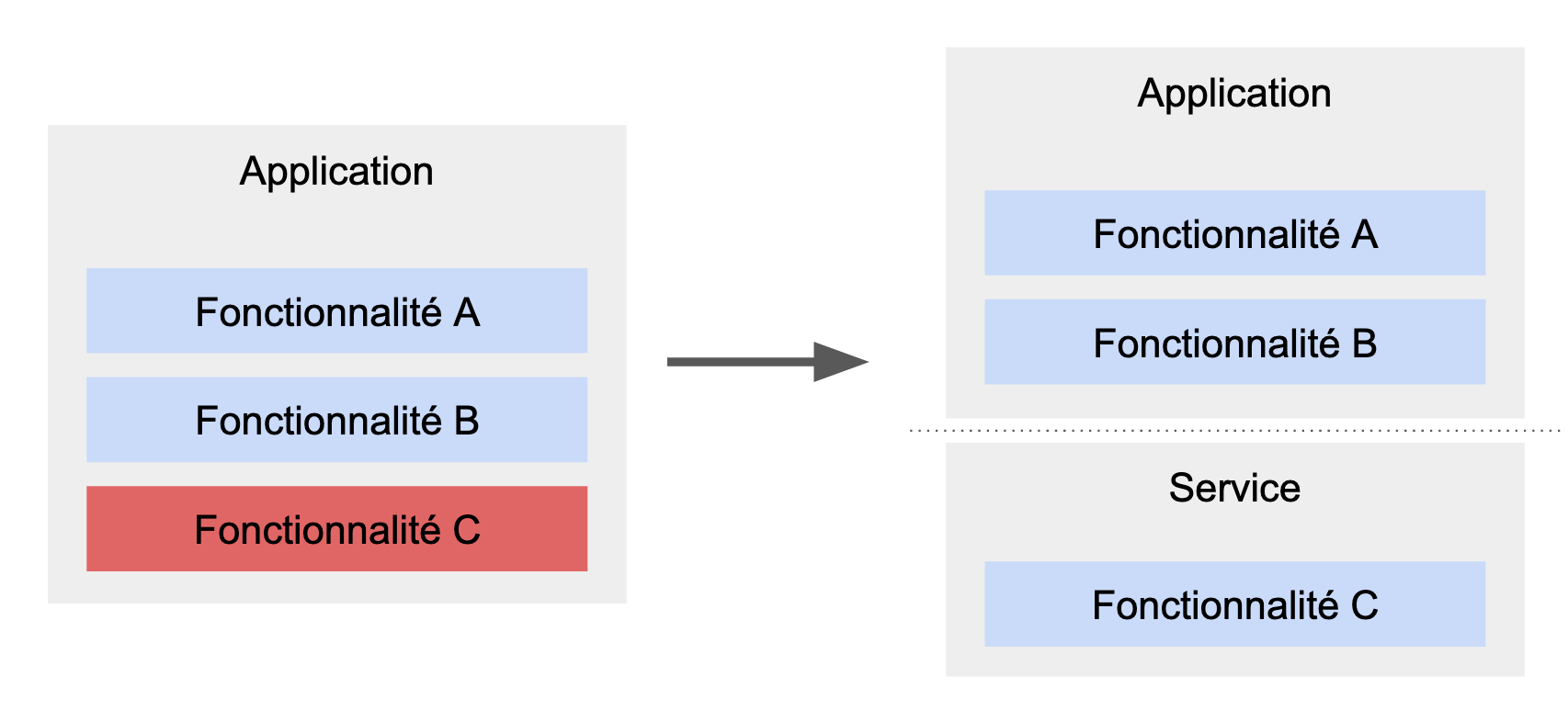
La fonctionnalité C a des besoins en ressources incompatibles avec les besoins du reste de l'application, on la sépare dans un service avec sa propre infrastructure
Dans tous les cas, la nécessité du découplage
On voit que, dans les cas de la découpe organisationnelle et de la découpe technique, on répète un prérequis : le découplage. Mais il est en réalité aussi nécessaire pour le cas où il n'y a pas besoin de découpe de l'application ni de l'équipe. Si on considère que chaque module est fortement couplé, c’est-à-dire que des évolutions sur un module implique systématiquement des évolutions sur un autre, cela signifie qu'il sera plus courant qu'à chaque évolution, tous les développeurs doivent interagir ou en tout cas modifient le même code et donc multiplient les cas de conflits.
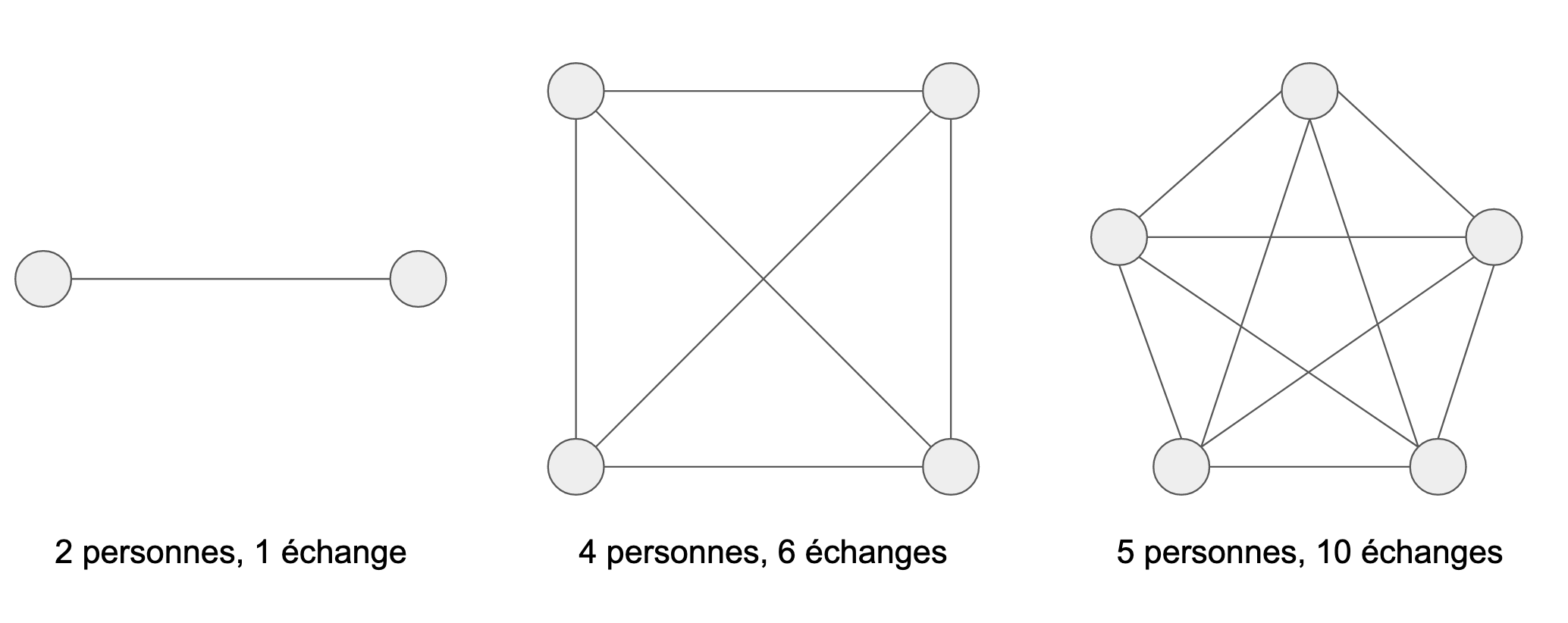
Si tout le monde interagit, combien d'échanges existe-t-il ? réponse: n(n-1)/2
Pour illustrer ce propos, si dans une équipe de quatre développeurs nous augmentons leur nombre d'un ou une développeuse devant travailler sur des modules fortement couplés, le nombre d'interactions nécessaire dans la plupart des cas passe de 6 à 10. Il est alors encore plus difficile et lent de faire évoluer le produit en ajoutant une personne. Au milieu de cette complexité, il faut ajouter que le risque d'erreur augmente également, car la coordination sera plus complexe. Et qui dit erreur, dit travail non planifié, donc moins de temps encore pour les évolutions qui étaient prévues.
Imaginons alors que nous partions sur un découpage des parties de notre application en services indépendants avant même d'avoir correctement découplé notre application. Si la charge cognitive est due à des problèmes d'intégration entre modules, comme une dépendance forte du cycle de vie d'un objet d'un module à l'autre, alors ce découpage en plusieurs unités de déploiement empirera le problème. En effet, là où après une évolution le déploiement des modules était coordonné de fait par l'approche monolithique, le découpage en service amplifierait les besoins de coordination pour l'évolution des modules avec une coordination dans les déploiements et les tests d'intégration. De plus, il faudra s'assurer que chaque module est équipé pour son déploiement avec : son pipeline (test, packaging, déploiement), son code d'infrastructure, des outils pour l'observer (monitoring, logging, alerting), de la configuration du reste du système pour l'accueillir (ex: réseau), ... Le nombre d'outils et d'interactions augmente alors et la maintenance de ceux-ci vient s'ajouter à la charge de travail.
On comprend alors que le découplage est nécessaire entre des fonctionnalités qui devraient être indépendantes, que l'on découpe son application en plusieurs services ou non. Découper ou non sera en revanche un curseur à placer entre les gains d'un service mutualisé au sein d'une application et d'un service indépendant, mais aussi des contraintes de ces deux possibilités.
Pour revenir à notre fil rouge, le besoin d’avoir des recommandations personnalisées à chaque connexion pour les utilisateurs augmente la charge sur notre service de prédiction et entraîne une dégradation de notre application de gestion d’articles. Donc la solution de découpe technique conviendrait bien à notre cas d'usage. Dès le début du projet, nous avons choisi de faire de la clean architecture pour découpler notre code. Ainsi on peut aisément découper notre service de recommandation dans un service à part et par la même occasion grossir l’équipe si les besoins sur le service de recommandation augmentent.
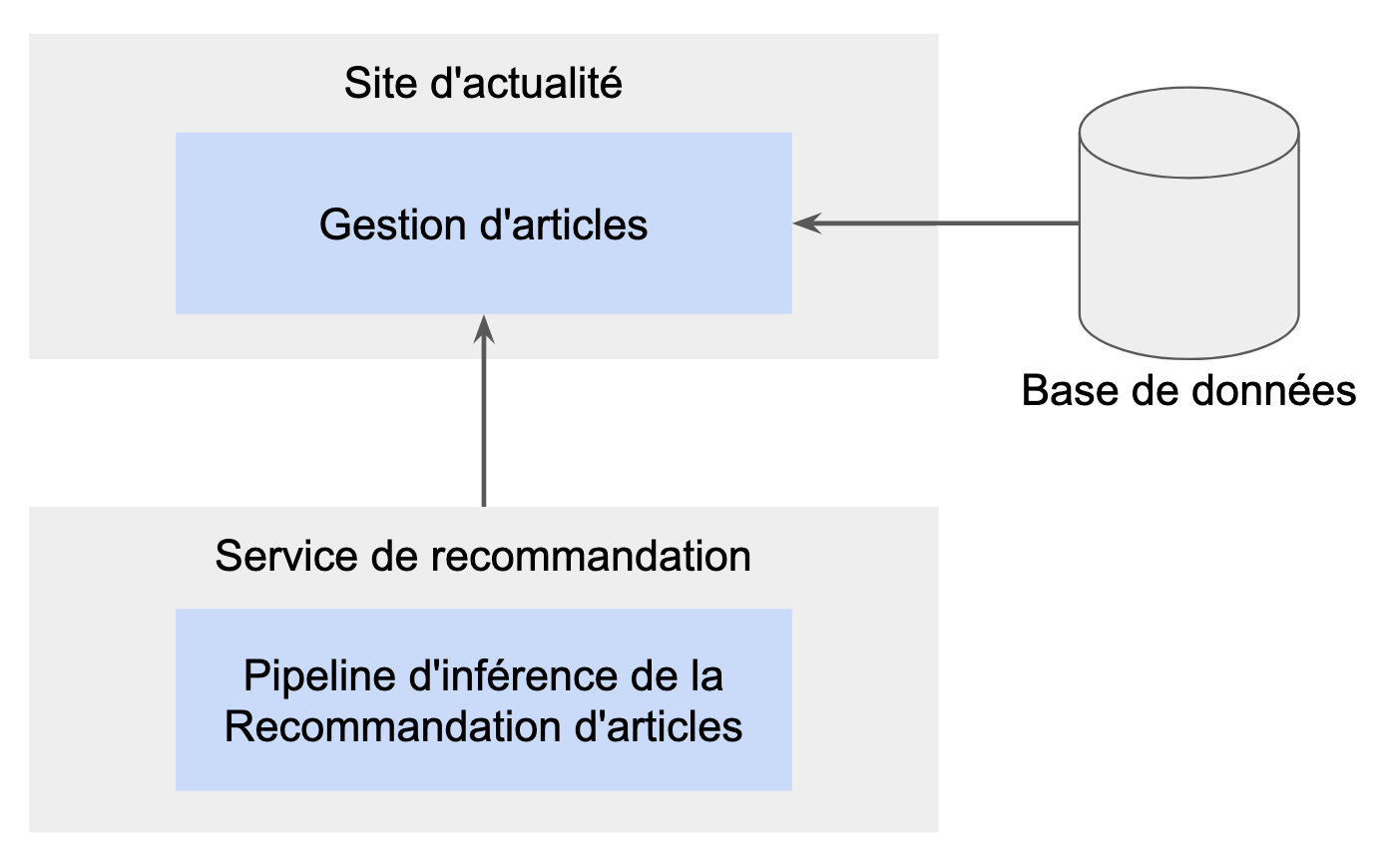
La prédiction est externalisée dans un service dédié pour ses besoins de performance et ses résultats sont produits à la demande
Take aways
- Au début du projet, pas de séparation a priori entre la partie ML et le reste de l'application pour éviter les surcoûts d'infrastructure, mieux vivre le refactoring et impliquer toutes les expertises sur le projet au global
- Découplage des composants pour permettre l'évolution autonome de ceux-ci et des découpages futurs
- Possibilité d'agrandir une équipe sans ralentir le projet lorsque les composants d'une architecture sont bien découplés
- Découpage de la partie ML en service (Model-as-a-Service) lorsque la fonctionnalité doit être consommée par d'autres applications ou lorsque ses besoins de performance sont très différents du reste de l'application
- On peut détacher facilement la partie ML dans un service dédié quand elle est déjà découplée
Sources et pour aller plus loin
- MonolithFirst
- L’architecture microservices sans la hype : qu’est-ce que c’est, à quoi ça sert, est-ce qu’il m’en faut ?
- Découplage, découplage, découplage !
- Découpage, lisibilité et dilution : refactorer ou pas ?
- Les architectures microservices, c’est un peu trop fort pour toi mon p’tit gars !
- Histoire d’une architecture émergente – Compte-rendu du talk de Emmanuel-Lin Toulemonde à La Duck Conf 2021
- Application / Domain / Infrastructure : des mots de la Layered Hexagonal Clean Architecture ?
- MLOps : Continuous delivery and automation pipelines in machine learning