Découplage, découplage, découplage !
En informatique, on adore le découplage : quel bonheur ce serait, d’avoir des morceaux de système évoluant librement chacun dans leur coin.

Il existe malheureusement deux ombres à ce tableau idyllique :
- le découplage présente des avantages mais aussi des inconvénients ;
- il n’existe pas un découplage mais des découplages, qui ont chacun leurs caractéristiques propres, parler de découplage sans préciser duquel il s’agit, c’est donc prendre le risque de ne pas se comprendre et de faire de mauvais choix.
Un exemple simple de découplage
Dans l’architecture logicielle, la plutôt que d’utiliser des GOTO.
Encapsuler du code dans des sous-routines exposées par des APIs formalisées — plutôt qu’une masse de code informe — a permis d’améliorer la lisibilité des programmes et la qualité des développements.
Cet exemple intègre les trois caractéristiques qu’on retrouvera dans les cas de découplage au niveau du SI :
- un besoin : améliorer la lisibilité et la qualité du code ;
- un moyen : des nouvelles syntaxes spécifiques ;
- un inconvénient : une baisse notable de performance avec les ordinateurs et les compilateurs de cette époque, au point qu’utiliser des fonctions a longtemps été une pratique controversée.
Les trois types de découplage de SI
À l’échelle d’un SI, il existe trois grands types de découplage :
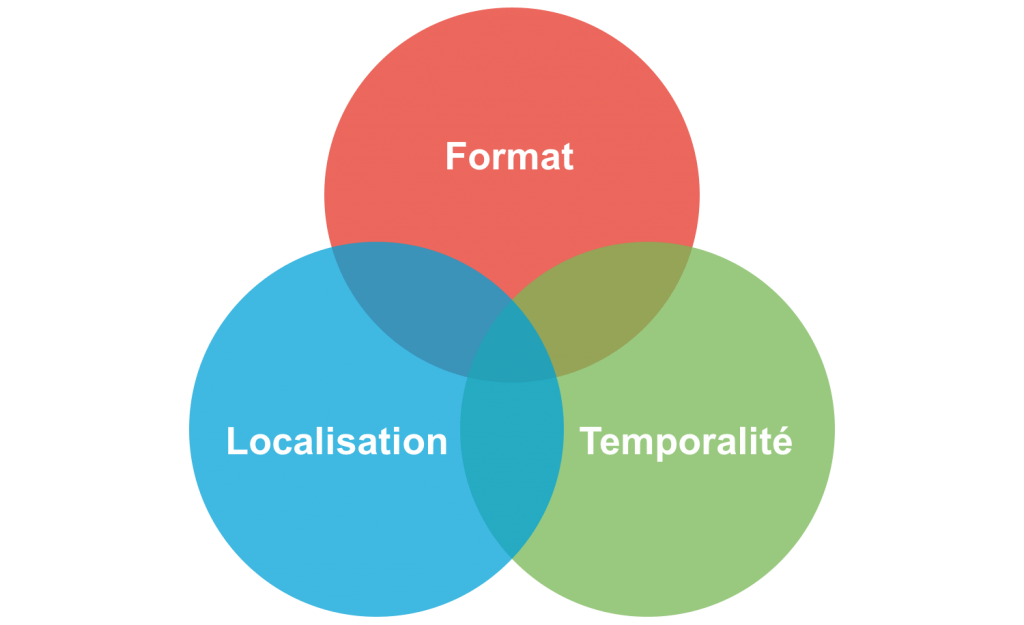
- le découplage de format : quand l’exécution d’une fonctionnalité passe par l’utilisation d’un contrat d’interface stable ;
- le découplage de temporalité : quand l’exécution d’une fonctionnalité se fait plus tard de manière asynchrone ;
- le découplage de localisation : quand l’exécution d’une fonctionnalité se fait ailleurs.
Ces découplages présentent des zones de recouvrement mais sont différents.
Le découplage de format
C’est celui auquel on pense le plus souvent quand on parle de découplage dans le domaine du SI. Il est fondamental dans une organisation d’une certaine taille car il répond à deux grands besoins :
- maîtriser les conséquences d’une modification d’une partie du système ;
- permettre à différentes équipes de travailler de manière indépendante en limitant les efforts de coordination.
Le moyen consiste à définir certains contrats d’exposition comme étant stables et utilisables à l’extérieur, à l’opposé de contrats "à usage internes" qui ne font pas l’objet de ces garanties.
L'inconvénient est le surcoût créé par l’effort de formalisation, et le risque si ce découplage est mal fait : en effet, le prérequis pour réaliser ce découpage est que les fonctionnalités à exposer soient matures et évoluent peu, ou d’une manière qui ne demande pas de faire évoluer le format d’exposition. Si les fonctionnalités que vous voulez exposer ne sont pas encore bien maîtrisées, vous risquez d’exposer une mauvaise interface. Dans ce cas, le surcoût de mise en place et de maintien du format pourra être plus important que le gain qu’il apporte, car chaque changement entraîne des coûts et/ou des délais : communication, tests d’intégration, gestion de compatibilité…
L’utilisation de bonnes pratiques et d’outils comme le DDD peut faciliter la définition d’interfaces, mais le plus difficile pour exposer des API stables relève de la connaissance métier.
Les bénéfices d’un découplage de format se font sentir même entre sous-modules d’une même application car il rend le code plus lisible et limite les besoins de refactoring lors des évolutions. C’est une des bases de la réutilisation.
Rappelez-vous cependant qu’un découplage de format n’est presque jamais total mais qu’au mieux, il s’agit d’un couplage faible : avec le temps tous les services évoluent, et donc aussi leurs contrats.
Le découplage de localisation
Il est à la base de l’informatique distribuée : il répond au besoin de pouvoir accéder à une fonctionnalité distante sans avoir à connaître précisément le ou les dispositif(s) qui en ont la charge. Cela permet de remplacer, déplacer, ajouter ou supprimer les machines qui rendent cette fonctionnalité de manière transparente lors d’un appel.
Le moyen est la mise en place d’une couche d’indirection entre les systèmes comme un DNS ou des proxys : au lieu d’accéder à un système directement par son nom, on utilise un intermédiaire.
Cela couvre les différents types de service distribué comme CORBA, SOAP ou REST, mais aussi les bases de données non locales et les systèmes de fichiers distants.
Un découplage de localisation sans découplage de format peut être utile à l’intérieur d’un même système car il permet de déployer séparément différents composants et de pouvoir gérer la résilience. C’est le cas par exemple des bases de données où une bibliothèque cliente expose une API pour requêter le serveur.
L'inconvénient du découplage de localisation est qu’il ajoute
- de nouveaux types d’erreurs et d’incertitudes ;
- de la complexité pour suivre et débugger les traitements ;
- de la latence pour la sérialisation / désérialisation et les transferts réseau.
Ainsi, si votre besoin est un découplage de format et pas un découplage de localisation, travailler sur des modules d’un même applicatif est une stratégie tout à fait valide.
Cependant, le cas le plus courant, qui correspond à ce qu’on entend généralement quand on parle de découplage, correspond à un découplage de localisation et de format. C’est lui qui permet à des équipes de travailler et de déployer leurs composants en encadrant et en limitant les dépendances.
La méprise la plus courante sur le découplage consiste à penser qu’un découplage de localisation entraîne nécessairement un découplage de format. Il est vrai qu’exposer des fonctionnalités via des services force à définir un contrat de service, autrement dit une interface formelle, mais rien ne garantit que ce contrat de service permette par lui-même un réel découplage. C’est l’erreur classique des SI de services mis en œuvre sans gouvernance.
Par exemple on peut penser qu’exposer des fonctionnalités en REST et fournir une documentation Swagger permet un découplage de format car il est alors possible de les appeller avec un minimum de connaissances et d’interractions avec les personnes qui en sont responsables. Mais si ce contrat d’interface évolue toutes les semaines, le fait d’avoir un contrat de service formalisé ne vous sauvera pas d’avoir à modifier votre code à chaque fois.
Le découplage de temporalité
Il s’agit d’exécuter un traitement plus tard de manière asynchrone. Il se fait souvent au moyen d’une file de messages, d’un envoi de fichier, ou d’une base de données.
Il permet de répondre à deux besoins :
- rendre plus rapidement la main à l’appelant en remettant à plus tard une partie des traitements ;
- gérer plus facilement les pics de charge, tant que l’outil en charge de gérer les demandes d’exécution en attente n’est pas submergé.
Il a trois inconvénients majeurs :
- il faut être certain de ne pas perdre de demande de traitements, et de ne pas en traiter en double (ou s’arranger pour que ça n’entraîne pas de conséquences néfastes) ;
- il rend plus difficile la gestion des erreurs et de la cohérence des données ;
- il rend plus difficile le monitoring du système, nécessitant souvent la mise en place d’outils de monitoring de flux.
Un découplage de temporalité sans découplage de format rend plus complexe les montées de version. En effet, il faut alors gérer la compatibilité entre les versions, ou attendre que les demandes en cours soient traitées avant de migrer l’ensemble du système. Ceci-dit, lorsque l’asynchronisme est utilisé à l’intérieur d’une seule et même application, cette approche peut être la bonne car elle évite d’avoir à se préoccuper de la gestion de compatibilité.
La mise en place d’un découplage de temporalité passe, dans la plupart des cas par l’utilisation d’un outil tiers externe à l’application (file de message, base de données…). Suivant son implémentation et sa configuration, cet outil peut fournir une forme "naturelle" de découplage de localisation. Si, dans ce cas, elle est facile à mettre en œuvre du point de vue infrastructure, cela ne veut pas dire qu’elle est gratuite car le surcoût en complexité engendrée par les nouveaux comportements à prendre en compte est bien là.
Pour conclure
À travers les trois types de découplage et leurs intersections, nous avons vu que découpler n’est pas une fin en soi mais bien un moyen de répondre à certains besoins, ce moyen ayant aussi des inconvénients, notamment des effets de bords à l’endroit où le découplage prend place. Nous avons noté aussi qu’accumuler les découplages, c’est cumuler les avantages mais aussi les inconvénients.
Le plus difficile, et qui ne peut être résumé dans un article, est de déterminer comment et à quel endroit découpler en fonction des besoins à satisfaire : cela fait plus de 30 ans que la question est ouverte. Si ajouter une certaine quantité de découplage est nécessaire dans les grands systèmes, mal s’y prendre mène parfois au désastre.
P.S. : J’ai eu l’idée de cet article après avoir lu ce texte qui est une très bonne analyse de l’utilisation de middleware de message pour gérer des tâches asynchrones.