Décommissionner sans paniquer

Un monolithe c’est un bloc de pierre de grandes dimensions constitué d’un seul élément. Il semble figé dans le temps, imperturbable : il sera là dans mille ans. La révolution informatique est aux antipodes de ce bloc de pierre. Elle se doit d’être évolutive, flexible, …
Pourtant, au cœur de nos parcs applicatifs nous retrouvons ces monolithes. Une application sous forme de monolithe implémente l'ensemble des activités nécessaires au métier.
Un monolithe offre une forte consistance au niveau métier. C'est un type d'architecture adapté à des produits indépendants qui servent un seul métier.
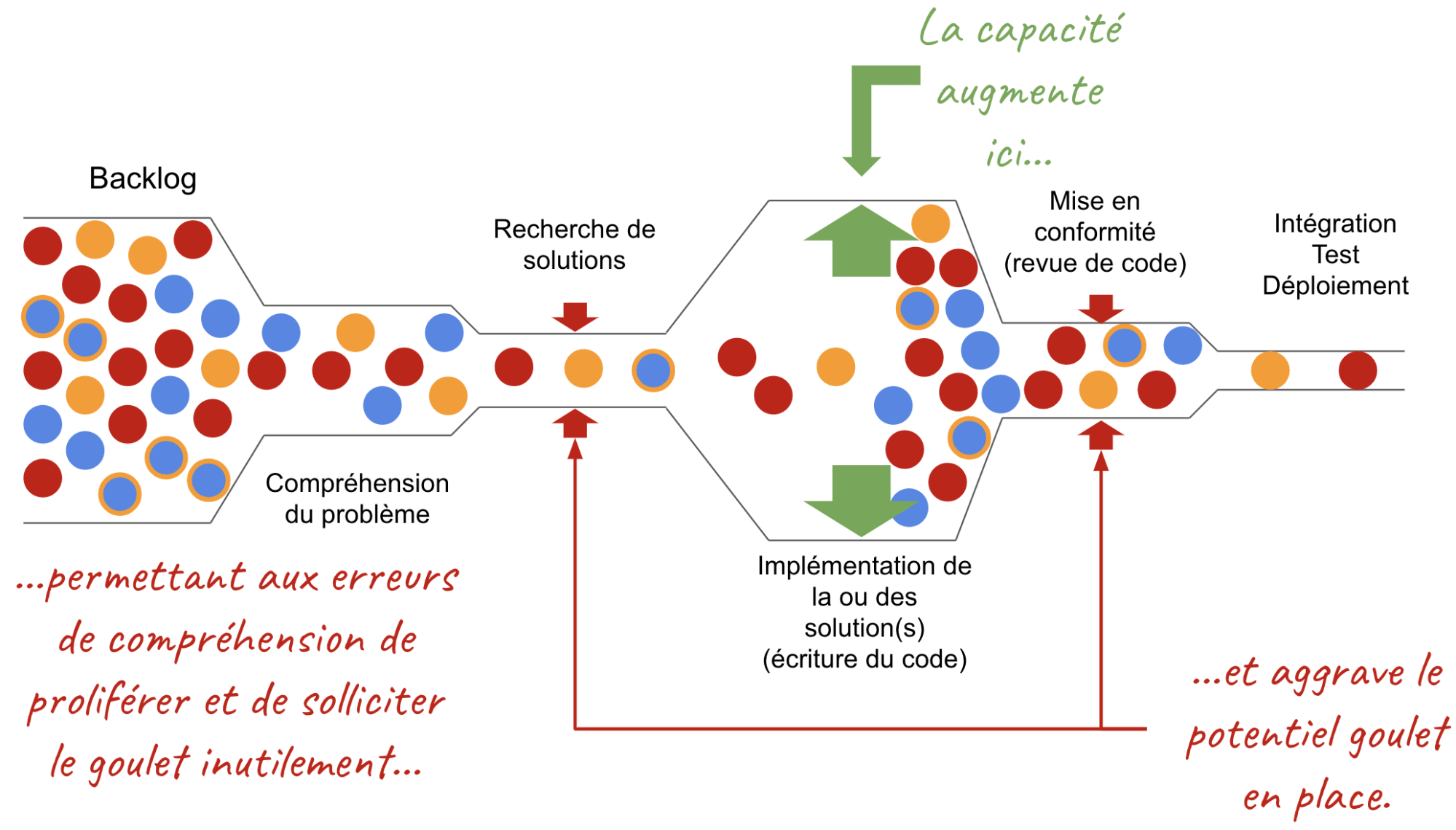
Une base de code partagée entre plusieurs équipes est souvent une des caractéristiques douloureuses d'un monolithe. Il est difficile de savoir qui travaille sur quelle partie de l’application. Cette situation se détériore avec le temps. C’est pourquoi il est délicat pour les équipes de faire des changements dans le code avec le risque d’impacter une autre équipe.
L'impact est un durcissement des process et une augmentation du time to market.
Malgré ces défauts, il vaut mieux faire évoluer ces monolithes plutôt que les réécrire car ils sont complexes à développer et qu’ils fonctionnent (ils sont en production). Néanmoins, il arrive parfois que le seul moyen de découper passe par une réécriture, un jeu de tests sûr devra alors vérifier qu’aucune fonctionnalité n’a été perdue.
Le dé-commissionnement passe nécessairement par une phase de transition qui est une étape cruciale pour éviter les arrêts de service. Nous allons utiliser le cas fictif d’une banque qui cherche à dé-commissionner son monolithe.
Dans cet article, l’objectif est de proposer une stratégie pour suivre la refonte d’un monolithe par la mise en place de l’observabilité. Un petit investissement sur le monolithe qui s’apprête à disparaître permettra d’éviter la panique au moment du dé-commissionnement.
Cet article omet volontairement la phase de migration entre le monolithe et les nouveaux services. Les stratégies de découpage du monolithe ne seront pas non plus abordées.
La Monobanque, après vingt ans de développement a construit un monolithe qu’elle projette de fracturer.
Le système d’information de la Monobanque est notamment responsable de 5 opérations métier qui tournent sur ce même monolithe :
- La gestion des virements internes
- La gestion des virements externes
- La gestion de l’opposition carte bleue
- La consultation du solde et des mouvements
- Le plafond de la carte bleue
Monobanque souhaite fragmenter ces opérations sur différentes briques applicatives et prévoit une durée de transition de 3 ans. La bonne réussite de ce découpage dépend notamment du bon niveau d’observabilité du système.

Monobanque a une faible observabilité : il existe une cartographie de l’existant mais elle n’a pas été mise à jour depuis deux ans, il y a donc potentiellement de nombreuses inconnues. Pour assurer la transition, la première étape est de découvrir les différents acteurs du SI utilisant ces opérations.
Trois acteurs sont connus pour consommer les services du monolithe :
- Le portail web particulier
- Le web service grand compte
- Agence connect, un outil pour les collaborateurs en agence.

Figure 1 : Schéma applicatif avec le monolithe
Les interfaces du monolithe utilisent toutes le protocole HTTP, mais elles sont hétérogènes dans leur façon de fonctionner, on trouve :
- Des opérations HTTP par passage de l’opération voulue en paramètre de l’URL
- Des opérations via HTTP REST
- Des opérations HTTP avec passage de paramètres dans le payload
- Des opérations HTTP avec un body en XML
Les ingrédients
La réalisation de la méthode d’observabilité décrite nécessite :
- Des journaux d’accès
- La modification des header de requête et notamment du user agent en le remplaçant par un user agent spécifique à chaque acteur.
- Un id de requête généré par le serveur mandataire
- Une stack ELK pour la gestion des journaux
Figure 2 : Schéma d’architecture général
Prendre le temps de l'observation
Avant d’établir un plan de dé-commissionnement, il faut identifier les requêtes exécutées sur le monolithe afin de faire le lien entre les acteurs, les requêtes et les opérations. Une même requête peut par exemple aboutir à deux opérations différentes, car l’opération se trouve dans le body. Ceci permettra par la suite de faire le lien avec le nouveau service que la technique d’appel change ou non.
Le monolithe génère des logs d’accès au format apache à chaque tentative d’accès à un service par un acteur. Pour analyser ces journaux, Monobanque utilise une stack ELK (ElasticSearch, Logstash, Kibana). Les journaux sont directement envoyés sur logstash via un flux TCP qui les transforme puis les indexe sur Elasticsearch. Kibana permet de créer des vues (tableau de bord) pour observer notre SI.
On observe (Figure 3) que seule l’opération de virement externe est récupérable depuis l’URL. Dans ce cas, l’opération demandée est écrite juste après « ? op= ».
D’autre part, les API REST ne permettent pas toujours de mettre en valeur l’opération finalement appelée. Par exemple pour l’URL: “api/carteService/[id_client]/opposition/[id_carte]”, la notion de type de ressource est mélangée avec les identifiants, donc difficile à extraire.
De même, lorsque l’opération est dans le body de la requête, sa récupération est impossible, car il est encodé pour le service apache.
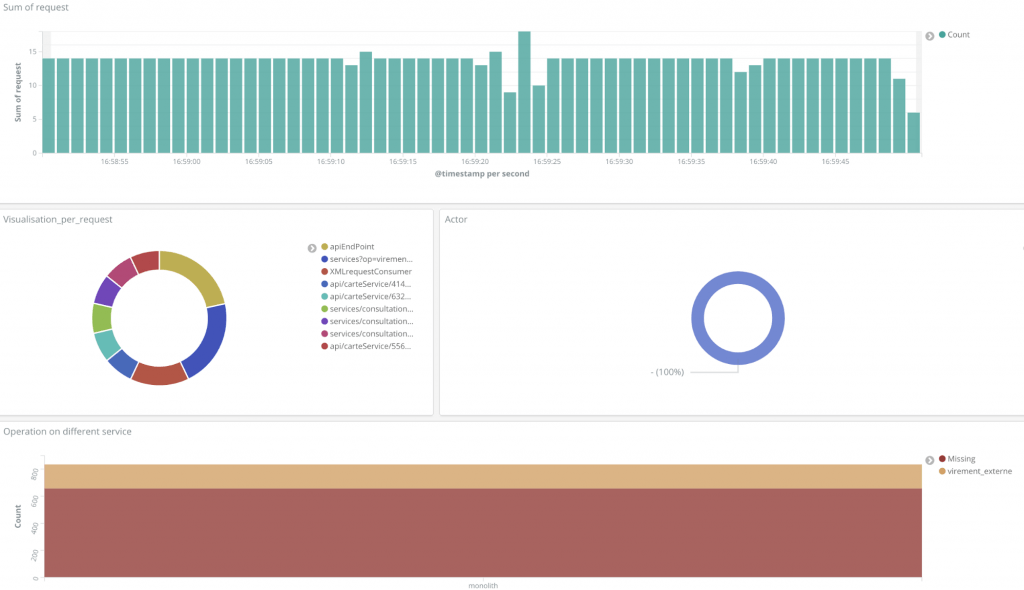
Figure 3: Tableau de bord avant la consolidation avec les logs applicatifs
Pour cela plusieurs solutions peuvent être mises en place :
- Ajouter un log applicatif, indiquant l’opération invoquée, qui consolidera le log d’accès via une agrégation par ID de requête.
- Ajouter dans les headers HTTP l’opération que l’on souhaite utiliser
Monobanque a choisi d’utiliser des journaux applicatifs, car il est possible de modifier le code source. L’avantage de cette méthode est de ne pas faire confiance aux headers envoyés par les clients.
Le log applicatif est généré au moment où la fonction d’entrée dans l’opération est appelée. La présence de ce journal ne garantit pas le bon fonctionnement de l’opération, mais le fait qu’elle ait été invoquée.
L’identifiant de requête est généré par le serveur mandataire inverse, si la requête n’en possède pas déjà un. Il est ajouté au log d’accès et transmis dans la requête.
Une fois en place, les opérations utilisées et les routes qui les appellent sont clairement identifiées. Par exemple, la route “api/carteService/[id_client]/opposition/[id_carte]” est associée à l’opération opposition carte.
Pour agréger les logs selon l’identifiant de requête, la configuration de logstach est la suivante :
Attention, cette stratégie d’agrégation fait porter une contention sur Logstash, si la volumétrie dépasse la capacité de traitement de ce dernier, il faudra opter pour une autre stratégie. On pourra par exemple consolider les journaux en amont dans un kafka avec comme clé de partitionnement l’id de requête. Nous pourrons alors avoir un Logstash par partition.
Une fois les journaux agrégés (journal apache + journal applicatif de l’opération), chaque journal contient un champ « opération ». Le tableau de bord (Figure 4) montre bien les 5 opérations du monolithe et les différentes routes utilisées pour les appeler.
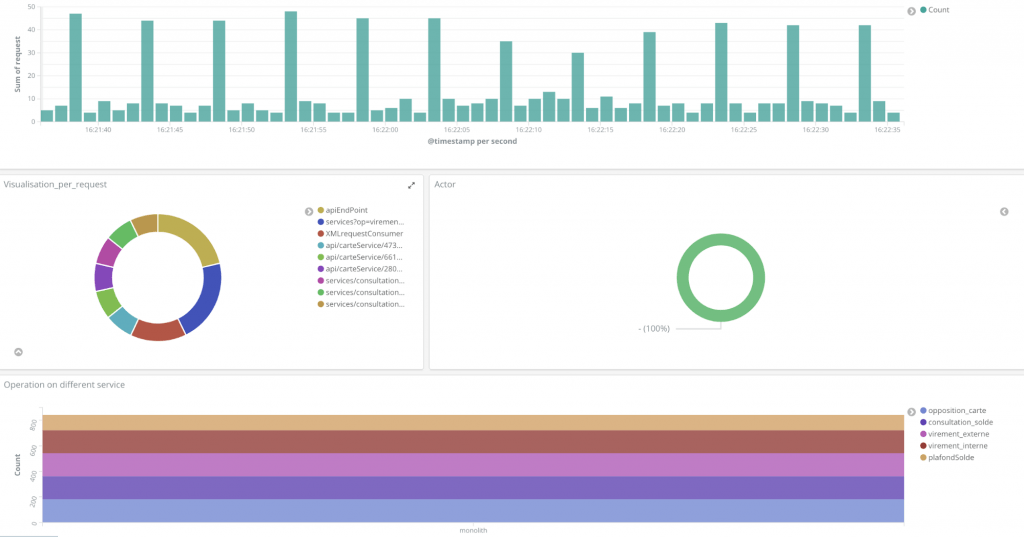
Figure 4: Tableau de bord après la consolidation avec les logs applicatifs
Il s’agit ensuite d’identifier les acteurs sur chacun des endpoints appelés. Différentes stratégies sont possible comme la mise en place d’un header ou la modification du user-agent. Pour Monobanque, c’est cette dernière stratégie qui va être mis en place car le user-agent arrive directement dans les journaux d’accès, elles est donc plus rapide à mettre en place. Le résultat est le suivant :
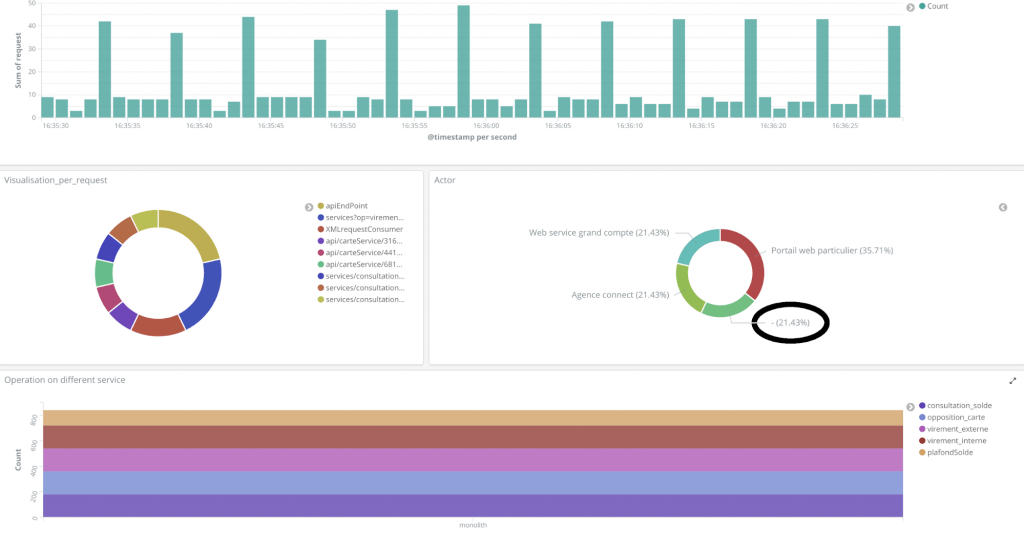
Figure 5: Tableau de bord avec la répartition des acteurs, 21% manquants.
Pour Monobanque, l’étude des adresses IP a permis de cibler deux machines internes exécutant des scripts bash appelés « bash opposition » et « bash virement ». Deux décisions doivent être prises pour donner suite à cette découverte :
- Identifier les opérations réalisées par ces bash en les marquant avec un user-agent.
- Après le dé-commissionnement, il faudra continuer de monitorer les points d’accès du monolithe afin de s’assurer qu’ils ne sont plus appelés.
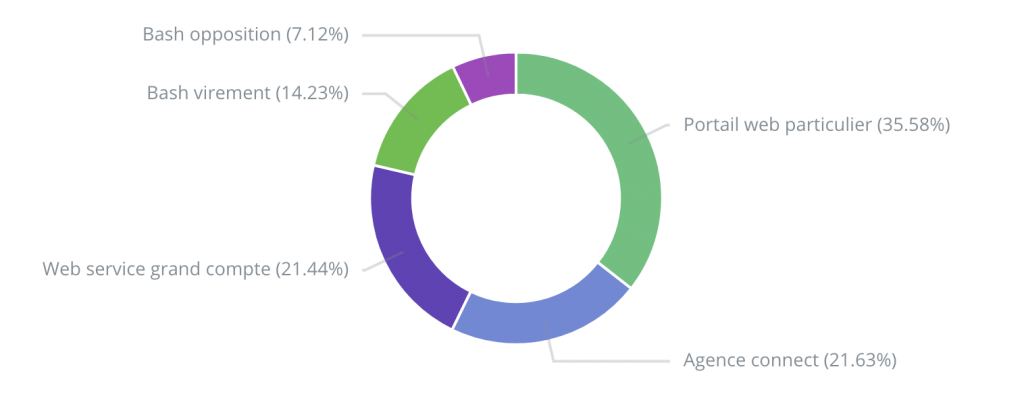
Figure 6: Répartitions de tous les acteurs suite à l’ajout du user-agent sur les batchs
Le découpage commence
On y est, le système est maintenant suffisamment observable pour être dé-commissionné. Il s’agit de développer les briques applicatives les unes après les autres. Monobanque a décidé de commencer par son système de virement externe pour des raisons de risques de saturations imminentes.
En premier lieu, un panneau de contrôle qui permet d’analyser la transition des flux a été mis en place. Ceci afin d’observer l’évolution du dé-commissionnement : suivre les acteurs sur chacun des services, le monolithe ou une brique applicative.
Il est composé de 4 éléments :
- Un diagramme en bâton mettant en valeur les opérations sur les différents services, que ce soit le monolithe ou bien les différents services résultant du découpage.
- Un diagramme circulaire montrant le pourcentage des différents acteurs permettant de suivre la mise en place du dé-commissionnement par acteur.
- Un diagramme circulaire pour voir le pourcentage de requête sur chaque service
- Le nombre de requêtes reçu sur chaque point d’accès du monolithe
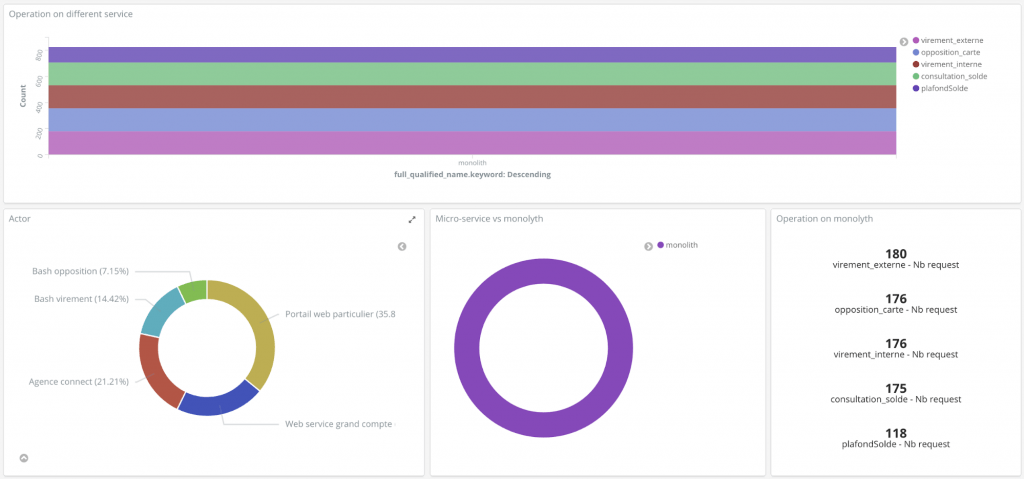
Figure 7 : Panneau de contrôle du dé-commissionnement avant la migration
Cet article omet volontairement la phase de migration entre le monolithe et les nouveaux services. Les stratégies de découpage du monolithe ne seront pas non plus abordées.
Une fois le dé-commissionnement des virements externe réalisé, l’ensemble des requêtes sont effectuées sur le service dédié. Le tableau de bord ci-dessous montre que le monolithe ne reçoit plus de requête pour un virement externe.
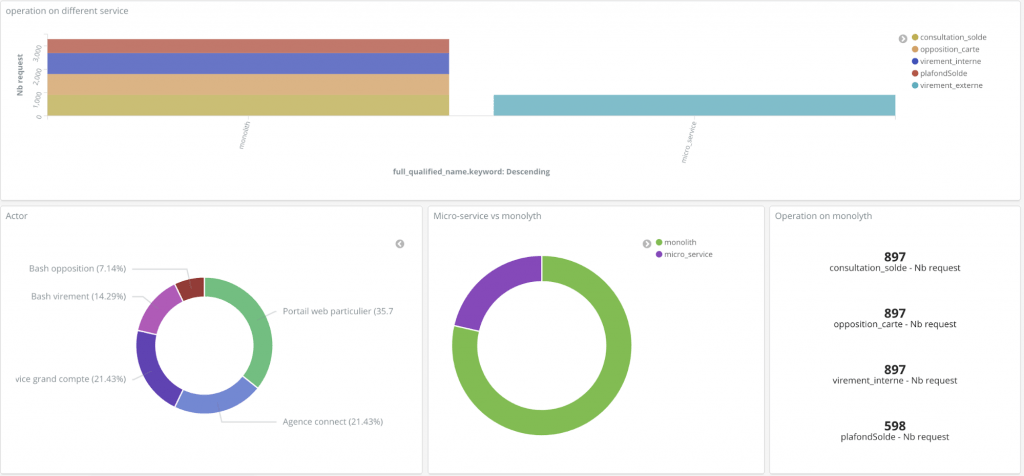
Figure 8 : Panneau de contrôle du dé-commissionnement après la migration du virement externe
Néanmoins, il est nécessaire de continuer à surveiller le point d’accès du service sur le monolithe. Pour cela une partie du tableau de bord est dédiée aux nombres d’appels par opération sur le monolithe.
Après plusieurs semaines, un virement externe apparaît sur le tableau de bord (Figure 9).
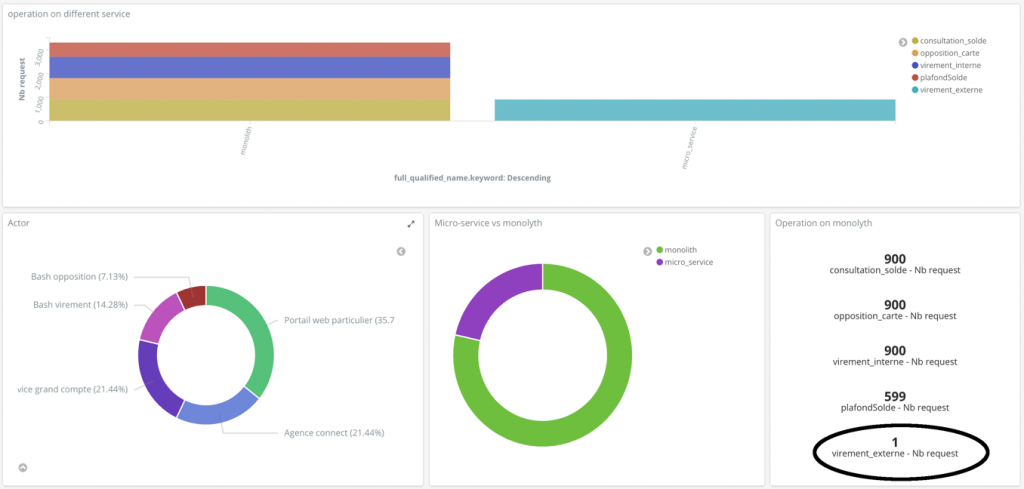
Figure 9: Une requête anormale sur le monolithe
Rapidement, on peut trouver le journal associé et commencer à chercher l’acteur qui a émis la requête à partir de son IP.

Figure 10 : Le journal de la requête anormal
Après recherche, il s’agit d’un bash mensuel collectant des données sur le nombre de virements externes effectué. L’erreur peut être corrigée.
Le dé-commissionnement peut continuer avec les virements internes.
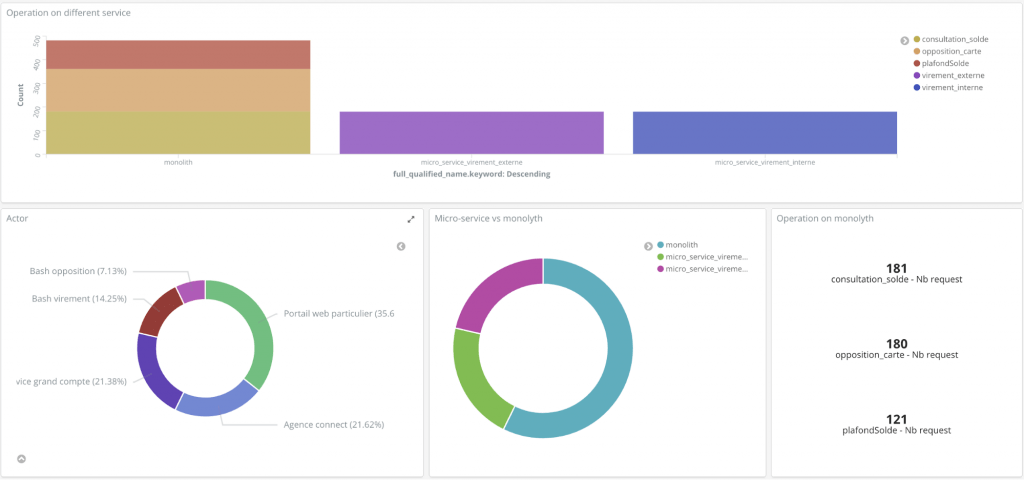
Figure 11 : Panneau de contrôle du dé-commissionnement après la migration des virements externe et interne.
Puis pour l’ensemble du monolithe...
Une fois le dé commissionnement de l’ensemble des services du monolithe terminé, plus aucun appel n’est réalisé sur le monolithe. Cependant, le système est capable d’observer les appels résiduels qui pourraient rester.
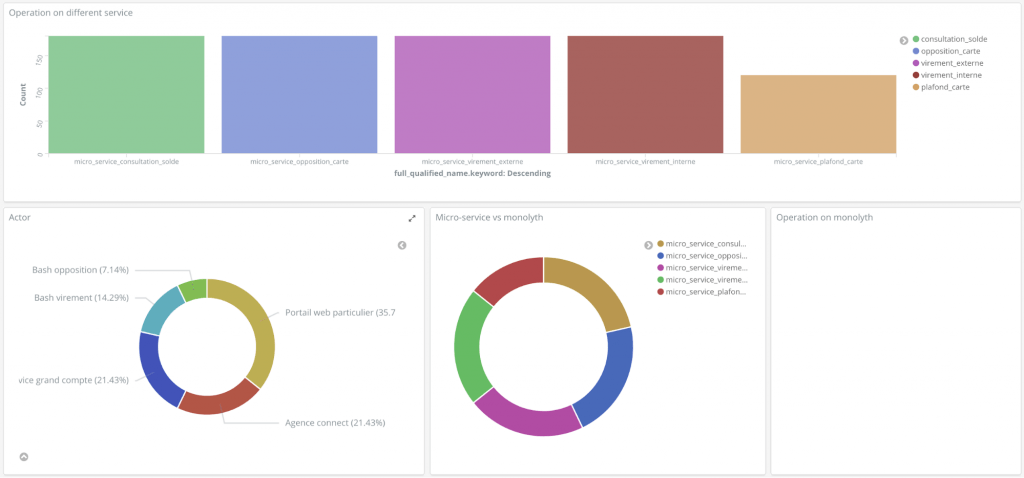
Figure 12 : Panneau de contrôle du dé-commissionnement après la migration de toutes les opérations
Après trois ans de travail, le dé-commissionnement est terminé, néanmoins, les anciennes routes du monolithe restent sur écoute pour s’assurer qu’il n’est plus appelé. Monobanque a maintenant une architecture en plusieurs briques et une meilleure observabilité.
Avec la participation de la tribu ARCHI
Articles connexes architecture monolithe
http://microservices.io/patterns/monolithic.html