Data science : La shadow production pour vérifier le bon fonctionnement d’un modèle avant son déploiement
Avant de déployer un nouveau modèle en production il est difficile de savoir précisément comment il va se comporter. La shadow production est une technique qui permet de se rassurer sur les performances du modèle avant de le déployer.
Dans notre précédent article sur les alternatives aux monitoring de distributions, nous évoquions brièvement le concept de shadow production.
La shadow production (également appelée shadow deployment, dark mode ou shadow mode) est une technique qui consiste à faire prédire un modèle sur les données de production, sans exposer ses prédictions aux utilisateurs. Puis d’en évaluer la performance.
Fortement inspirée des techniques de déploiement du monde du développement logiciel, cette pratique permet de s’assurer qu’un modèle, un pipeline ou un système fonctionne bien avant d’exposer ses résultats aux utilisateurs. C’est une dernière boucle de feedback avant le déploiement.
Dans cet article, nous allons voir d’abord les aspects théoriques de la shadow production, ensuite une implémentation simple de celle-ci, et finalement nous vous donnerons un retour d’expérience.
Théorie
Dans cette partie nous allons voir la théorie sous forme de questions.
Pourquoi faire de la shadow production ?
Le premier intérêt de la shadow production est la vérification de la validité des hypothèses formulées. C’est la dernière boucle de feedback avant le déploiement.
Durant la phase de construction du système des hypothèses sont formulées. Par exemple :
- Les données historiques utilisées pour entraîner le modèle sont similaires à celles que l’on aura en phase d’inférence.
- Il n’y a pas de leakage dans les données d’entraînement. (Le leakage a lieu lorsque l’on utilise des données en phase d’entraînement qui ne seront pas disponibles en phase d’inférence).
Il arrive que ces hypothèses soient fausses. Dans ce cas, l’évaluation sur le test set n’offre alors aucune garantie sur les performances en production.
Le deuxième intérêt de la shadow production est la vérification de l’intégration des artefacts dans l'environnement de production :
- Cela valide l’intégration avec d’autres composants, via des interactions réelles (et non testées) notamment grâce à l’utilisation de données de production (plutôt que des tests avec un extract de celles-ci).
- Cela représente un test en condition de charge réelle.
Quels artefacts mettre en shadow production ?
La shadow production peut évaluer différents artefacts : le modèle ou le système au complet. Selon l’artefact, l’implémentation pourra varier.
Pour évaluer uniquement le modèle : récupérer les données de production après le feature engineering et les fournir au shadow model. Faire cela permet d’éviter de refaire l’étape de feature engineering pour chaque shadow model, l'inconvénient est que cela n’est pas adapté si le code de feature engineering change. Cette approche (illustrée sur la figure 1) est intéressante lorsqu’il y a de nombreux ré-entraînements sans évolutions de la base de code.

Cette solution est peu coûteuse à mettre en place mais pas exhaustive, elle ne tests / mesure que le modèle.
Pour évaluer le système dans son ensemble : récupérer les données brutes fournies en entrée du système, puis les fournir au système en shadow production. Faire cela nécessite un peu plus de développements et de ressources machine mais permet de tester de bout en bout le système avec des données de productions. Cette approche (illustrée sur la figure 2) est intéressante lorsque le code de feature engineering évolue régulièrement.

Cette solution est plus coûteuse à mettre en place et en temps machine mais réalise des tests / mesures exhaustifs.
Que suivre ?
La métrique à évaluer en shadow production est idéalement la métrique métier de votre système (ex: nombre de patients vraiment malades sur un problème de prédiction de maladie).
La métrique métier peut-être difficile à suivre dans le cas où elle nécessite une interaction avec l’utilisateur. Par exemple, en marketing, la métrique ‘taux de vente par contact client’ n’est pas calculable sans contacter les clients. Dans ce cas on peut se tourner vers des métriques de data science.
La plupart des métriques de data science nécessitent de récupérer la prédiction idéale dont la récupération peut s’avérer difficile.
En dernier recours, une comparaison de la distribution des prédictions entre le modèle en production et celui en shadow production peut permettre d’avoir un feedback pertinent. Attention, le suivi de cette distribution nécessite d’être précautionneux puisque la distribution peut :
- changer de manière souhaitable (ex: on a significativement amélioré le modèle)
- ou ne pas avoir changé de manière anormale (ex: même distribution de prédictions au global, mais les individus statistiques sur lesquels est prédit un label sont complètement différents).
Ce suivi de distribution de prédiction permet donc uniquement de lever certaines alertes, pas de dire que la mise à disposition des utilisateurs se passera bien.
Dans le cas où les interactions avec des utilisateurs sont nécessaires pour obtenir un feedback, la shadow production ne pourra pas aider. Cependant des techniques de déploiements telles que le canary deployment peut permettre d’obtenir des résultats en limitant l’impact sur les utilisateurs.
Quand s’intéresser à la shadow production ?
Dès que l’on a un modèle / système que l’on souhaite déployer en production :
- Soit avant la première ouverture du système aux utilisateurs afin d’observer son comportement.
- Soit lorsque l’on a un nouvel artefact candidat prêt à être déployé (après un réentraînement, après l’ajout de nouvelles variables, …) afin de comparer le comportement du nouvel artefact par rapport à celui déjà en production.
Quand réaliser la shadow production ?
La shadow production est une forme de monitoring et n’est pas un composant indispensable à la livraison des prédictions aux utilisateurs. Il convient de faire la shadow production de manière asynchrone pour ne pas risquer de ralentir ou de casser le système.
Pour faire cela, il y a deux solutions :
- Faire cela après les prédictions,
- Faire cela en même temps mais sur une autre machine.
Combien de temps ?
Le temps qu’un artefact doit passer en shadow production est le temps nécessaire pour se donner confiance. Il faudra le laisser rencontrer une majorité des situations qu’il peut rencontrer en production (il est rarement possible de les rencontrer toutes).
Par exemple si vous avez une saisonnalité sur les jours de la semaine, il convient de laisser l’artefact en shadow production le temps de voir toutes les saisons. Pour une saisonnalité annuelle attendre un an ralentit beaucoup trop la boucle de feedback. Il faut donc trouver un compromis entre complétude du feedback apporté et délai pour l’obtenir.
Une fois que vous avez suffisamment confiance, vous pouvez alors vous tourner vers différentes stratégies de déploiement telle que le canary deployment. Cette stratégie consiste à envoyer d’abord 10% du trafic vers la nouvelle version, vérifier que le système se comporte normalement avant d’envoyer la totalité du trafic. Elle peut permettre la mesure de métriques métiers qui dépendent de l'interaction avec les utilisateurs.
Quid de l'environnement de pré-production ?
En développement logiciel, l'environnement de pré-production (appelé également de qualification) est un environnement qui ressemble le plus possible à celui de production. Il vise à tester le fonctionnement du système au global dans des conditions de productions.
A-priori cela ressemble beaucoup à l’objectif de la shadow production.
Ainsi, une question se pose : est-ce que la shadow production a sa place en pré-production ou en production ? Je n’ai pas de réponse tranchée, mais des arguments pour les 2 options :
- Si l’on voit la shadow production comme un test end-to-end du système de Data Science alors elle a probablement sa place en pré-production.
- Si l’on voit la shadow production comme un monitoring de la brique d’entraînement des modèles ou si l’environnement de pré-production n’a pas accès à la totalité des données de production, alors elle a probablement sa place en production.
Les défauts de cette technique ?
Cette technique a quatre principaux défauts :
Récupérer la prédiction idéale peut être ardu. L’article Data science en production : les difficultés pour récupérer la prédiction idéale. vous permettra d’approfondir ce point.
La boucle de feedback peut être longue dans le cas où récupérer la prédiction idéale est long. Par exemple dans un système de prédiction d’achat à 1 mois il faut attendre 1 mois avant de savoir si c’était une bonne prédiction. Dans ce cas, cela nous éloigne des principes du déploiement continu (CD) et de l’entraînement continu (CT). Pour creuser les aspects de CI/CD/CT appliqués à la Data Science vous pouvez lire cet article sur le blog de Google.
La shadow production ne donne pas de feedback sur la façon dont les utilisateurs utiliseront la prédiction et donc l’impact sur le business. Sur un exemple de modèle de prédiction d'appétence en marketing, en ne contactant pas les potentiels clients appétants vous n’aurez probablement pas d’achat.
Scalabilité : si la méthode de prédiction est complexe, réaliser plusieurs prédictions sur un même jeu de données peut s’avérer long voire coûteux (en termes de machines).
Une implémentation
Avant d’implémenter une shadow production nous avons un pipeline d’inférence classique, comme illustré par la figure 3. Il tourne en production, c’est à dire que régulièrement il est sollicité pour avoir des prédictions.

Dans cet exemple, nous souhaitons mettre en place une shadow production uniquement sur le modèle. Nous souhaitons évaluer deux shadow modèles.
Pour cela nous ajoutons une première brique de sauvegarde des données préparées. Pour des données tabulaires le format parquet permet de gagner en efficacité et en espace de stockage.
Ensuite nous ajoutons la shadow production, qui réalise des prédictions et des évaluations pour chaque shadow modèle. Le pipeline résultat est représenté sur la figure 4.
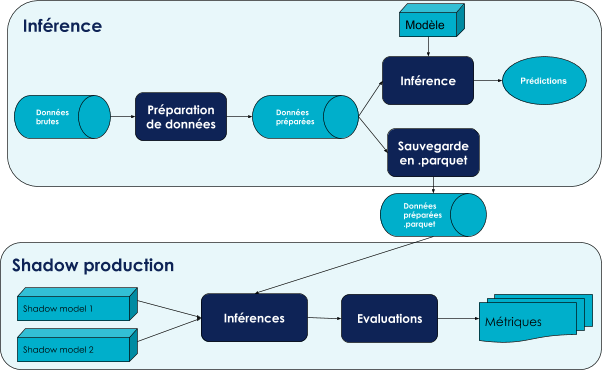
Cette implémentation simple, permet de découpler complètement l'inférence et la shadow production et ainsi pouvoir exécuter la shadow production de manière asynchrone.
Un retour d’expérience
Nous avons eu l’occasion de mettre en place l’implémentation décrite ci-dessus dans le cadre d’une mission. Cette partie donne plus de détail sur comment on a fait cela, et ce que l’on a appris.
Le contexte :
Sur un projet de Data Science appliqué à l'efficacité opérationnelle, l’objectif est de limiter la réintervention de techniciens. En effet, les techniciens doivent souvent ré-intervenir car ils n’avaient pas le bon diagnostic du problème à résoudre, pas le bon matériel, etc.
Pour réduire ces réinterventions nous prédisons, chaque jour, sur toutes les interventions planifiés le lendemain le risque de ré-intervention. Cela permet aux chefs d’équipes d’adapter la tournée du technicien, le matériel emporté ou le technicien assigné à la tâche.
La solution est désormais en production : il s’agit d’un modèle de type forêt aléatoire basé sur l’historique des interventions contenant un descriptif des interventions, du matériel, etc.
Nous ré-entraînons régulièrement le modèle car les équipements et la typologie d’intervention évoluent. Nous avons donc besoin d’évaluer les nouveaux modèles produits.
Stack technique :
Nous avions à disposition :
- Airflow avec un DAG d’entraînement, un DAG d’inférence, un DAG de monitoring (distinct du DAG d’inférence afin d’être asynchrone),
- Une base Postgresql pour stocker nos métriques de monitoring,
- Un Grafana pour visualiser nos métriques de monitoring.

Le choix d'implémentation :
Pour s’intégrer à l’existant, nous avons mis en place une tâche de shadow production dans notre DAG de monitoring.
Dans cette tâche nous avons utilisé l’implémentation proposée dans la partie précédente. Cela nous permet donc de valider le bon fonctionnement des modèles candidats.
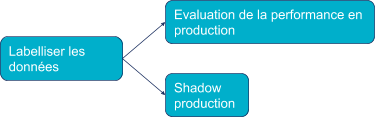
Nous avons évalué notre modèle en utilisant notre métrique de data science (l’AUC) qui nécessite la récupération de la prédiction idéale (réalisé par la tâche “Labelliser les données” sur la figure 6).
Voici le code python de la tâche de shadow production :
for model in shadow_model: X = load(prepared_data_path) predictions_ideales = load(labels_path) try: predictions = model.predict(X) metric = evaluate(predictions, predictions_ideales) except: metric = 0 save_metric_in_data_base(metric)
Remarque : De manière générale un “try, except” générique n’est pas une bonne pratique. Dans notre contexte, on se permet cela car un modèle qui n’arrive pas à prédire ou à s’évaluer ne doit pas aller en production on lui donne donc la pire évaluation possible (avec notre métrique c’était 0).
Résultat :
Les résultats de la tâche shadow production sont stockés dans la base Postgresql, puis nous avons créé le graphique présenté sur la figure 7.
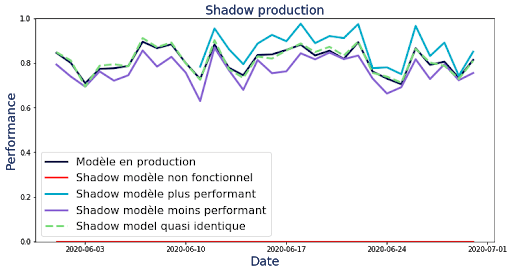
Voici quelques enseignements que l’on peut tirer de ce graphique :
- En bas, en rouge, le modèle a donné uniquement des évaluations à 0, cela signifie que ce modèle ne fonctionne pas, ce n’est pas un bon candidat au déploiement.
- En violet, le modèle a des performances systématiquement inférieures aux autres modèles évalués, ce n’est pas un bon candidat au déploiement.
- Le modèle bleu clair commence son évaluation uniquement le 10 Juin car il n’était pas en shadow production avant. Il est systématiquement meilleur que le modèle en production, c’est un bon candidat au déploiement.
- Le modèle en pointillé vert donne des performances très similaires au modèle en production. C’est le même type de modèle que celui en production et il a été entraîné sur des données qui n’ont pas significativement changé.
Les problèmes que l’on a identifiés grâce à la shadow production
Nous avons identifié deux types de problèmes :
- Les modèles qui ne fonctionnent pas (dont le rouge). La shadow production nous a servi de tests end to end.
- Les modèles qui sur-apprennent des données historiques et performent en moyenne moins bien en phase d’inférence.
Bonnes pratiques que nous avons apprises :
- Afficher les performances réelles du modèle en parallèle des modèles candidats pour mettre les résultats de la shadow production en perspective,
- Les modèles issus de réentraînement sont similaires si les données n’ont pas significativement changé, les courbes vont se superposer sans se distinguer. C’est ce qui se passe si vous implémentez un continuous training trop fréquent.
- Plutôt qu’utiliser la métrique de Data Science c’est le bon moment pour utiliser une métrique métier.
Conclusion
Dans cet article nous avons vu que derrière le mot un peu barbare de “Shadow production” se cache en fait un concept assez simple. Inspiré du monde du software, il s’agit d’une méthode pour évaluer une nouvelle solution, ici un modèle, avant de la déployer.
Nous avons proposé une implémentation simple qui utilise des briques existantes dans notre projet. En termes d’outils nous avons utilisé : un DAG Airflow pour orchestrer cette évaluation, une base de données Postgre pour stocker les métriques, un Grafana pour les visualiser.
Rapide à mettre en place, cette technique représente une dernière boucle de feedback avant de mettre votre modèle en production. Elle vous permettra notamment d’identifier les problèmes d’intégration des briques entre elles.
Lorsque vous mettrez en place une brique de continuous training qui entraîne de manière automatique des nouveaux modèles, la shadow production vous permettra de les évaluer de manière efficace avant de mettre un nouvel artefact en production.
Pour aller plus loin, vous pouvez aller creuser les stratégies de déploiement du software telles que canary ou blue green deployment, ainsi que la mise en place du monitoring d’autres métriques.