[MLOps] Les difficultés pour récupérer la prédiction idéale.
Introduction
En phase de construction d’un modèle de machine learning supervisé, les data scientists évaluent la performance de leur modèle par rapport aux labels en utilisant une métrique (par exemple l’AUC). Cela leur permet d’avoir un a priori sur les performances du système qu’ils sont en train de construire.
Cette évaluation n’est qu’un a priori car lors de la phase de construction, des hypothèses ont été formulées et celles-ci peuvent se révéler fausses en phase de production. Il faut donc également s’évaluer lors de cette deuxième phase. Cela permettra de :
- Savoir si le système fonctionne et délivre les performances attendues,
- Suivre les performances du système dans le temps et avoir un a priori sur son impact business,
- Avoir des discussions rationnelles (plutôt qu'au ressenti) sur les performances et l’intérêt du projet.
Pour réaliser une évaluation comparable en production, le data scientist peut chercher à calculer la même métrique qu’en phase de construction. Pour cela, il a besoin d’avoir accès à la prédiction idéale. Cet accès n’est pas toujours facile, et dépend beaucoup du contexte.
Ces cinq contextes illustrent les différentes difficultés que l’on a rencontrées aux cours de nos missions :
- Contexte 1: Un système de prédiction de consommation électrique. L’objectif est de prédire la consommation électrique des Français du lendemain pour adapter les moyens de production. La prédiction idéale est facilement obtenue, car il est possible de mesurer la consommation réelle le lendemain.
- Contexte 2 : Un système de prédiction d'appétence. L’objectif est de prédire avec un mois d’avance l’achat d’une nouvelle voiture pour envoyer des publicités ciblées. Pour obtenir la prédiction idéale, il faut notamment que le mois soit écoulé.
- Contexte 3 : Un système de recommandation de films. L’objectif est de recommander des films aux utilisateurs pour qu’ils puissent aller les acheter en magasin. Comme l’achat ne se fait pas sur le site, il est difficile de savoir si l’utilisateur a vraiment acheté le film.
- Contexte 4 : Un système de détection de défauts par inspection visuelle à partir de photos. Pour entraîner le modèle, les labels ont été obtenus par annotation. En phase de production, il n’y a pas de retour de la part des opérateurs sur la présence réelle d’un défaut.
- Contexte 5 : Un système de maintenance prédictive. L’objectif est de prédire si une panne est susceptible d’arriver prochainement afin d’envoyer un technicien pour entretenir la machine. L’intervention du technicien va éviter la panne. Il devient donc impossible de savoir si la machine allait vraiment tomber en panne.
Dans cet article nous allons voir que ces contextes illustrent les difficultés que vous pourrez rencontrer en phase de production pour récupérer la prédiction idéale. À la fin de cet article vous saurez quelle(s) technique(s) mettre en place pour avoir du feedback et vous évaluer en production.
Vocabulaire
Label : (aussi appelé cible, y, target) il s’agit de la valeur à prédire.
Machine learning supervisé : Domaine du machine learning où les modèles sont entraînés à prédire un label à partir de variables décrivant une situation.
Variables explicatives : ce sont les variables qui décrivent la situation. Elles sont données au modèle pour qu’il puisse faire une prédiction. Elles peuvent être des données tabulaires, des images, du texte, des séries temporelles.
La prédiction idéale : c’est la prédiction que l’on aurait aimé que le modèle fasse pour maximiser l’impact du système. Elle n’est pas accessible au moment de la prédiction. Elle n’est pas toujours égale à la ground truth (un exemple est présenté dans la partie “L'impact de votre système empêche de constater la prédiction idéale”).
Feedback : c’est toute forme de retour donné sur le système par un utilisateur, un expert, etc.
Système de data science : c’est la totalité des artefacts du projet (code, modèles, données). Cela inclut les codes d’extraction et de préparation de données, le modèle de machine learning, l’outil de restitution des prédictions.
Phase de production : Le moment où le système de data science est utilisé. Il a un impact sur les utilisateurs, sur l’entreprise.
Les différentes difficultés que vous pouvez rencontrer
Nous proposons ici quatre grandes catégories de difficultés que vous avez / allez rencontrer pour récupérer la prédiction idéale en phase de production. Pour chaque difficulté, nous allons la décrire, donner un exemple et proposer des solutions.
Difficulté technique pour obtenir la prédiction idéale

Le problème :
Le label a été obtenu de manière ponctuelle au moment de la construction du modèle. Il n’y a pas eu de mise en place de flux de données pour accéder à la prédiction idéale.
Exemple : Un système de prédiction d'appétence aux voitures.
Le modèle a été construit à partir de données de CRM et d’une extraction faite du SI opérationnel des ventes réalisées. La prédiction idéale, ici l’achat de voiture, n’est pas remontée dans le CRM car il n’y en a jamais eu le besoin.
Pour l’obtenir au moment de la phase de construction du système, le data scientist a demandé une extraction qu’il a reçue par mail. Chaque demande de mise à jour prend plusieurs jours.
La récupération de la liste des achats de voitures tous les jours via ce processus manuel n’est pas réaliste.
Solution :
Au moment de la phase de construction du système, il faut anticiper ce besoin de flux de prédictions idéales.
Des flux automatisés de variables explicatives ont été mis en place pour mettre le système en production. Il faut faire de même avec la prédiction idéale pour monitorer ce système.
Le principe qui nous a guidé pour ces problèmes techniques s’applique de manière générale en data science : il faut penser flux de données plutôt que extractions ponctuelles.
L’utilisateur n’est pas incité à donner son feedback
![]()
Le problème :
Certains systèmes sont construits de telle façon que l’utilisateur n’est pas incité à donner la prédiction idéale une fois qu’il a eu sa prédiction.
Un exemple :
Un système de recommandation de films basé sur nos préférences. Avec cette recommandation, l’utilisateur est libre d’aller sur un autre site ou en magasin pour acheter son film. Il nous est alors impossible de savoir si la recommandation était bonne et si l’utilisateur l’a suivie.
On a pensé à mettre un système de bouton “je vais acheter ce film” mais personne ne l’utilise car les utilisateurs n’en voient pas l’utilité.
Solution 1 : Rendre le feedback utile
L’idée est de rendre intéressant et facile la soumission de feedback pour l’utilisateur.
Un moyen pour rendre le feedback intéressant est de l’intégrer dans le parcours utilisateur. Sur notre exemple de recommandation de film, nous pouvons proposer à l’utilisateur de cliquer sur un lien pour obtenir une liste des lieux d’achats du film. S’il clique, cela nous permet de savoir qu’il souhaite l’acheter.
Pour rendre le feedback facile à donner, il faut aussi bien le penser. Par exemple Netflix est passé d’une évaluation sur 5 étoiles à une évaluation pouce en haut / pouce en bas. Cela leur a permis d’augmenter significativement le nombre d’évaluations obtenues. Pour aller plus loin cet article détaille l’intérêt de chaque évaluation.
Solution 2 : Transformer le problème pour faciliter le feedback
L’idée est de changer légèrement le problème pour inciter l’utilisateur à donner son feedback.
Par exemple, sur Gmail, il y a en bas des mails 3 suggestions de réponses. On peut imaginer que le réel objectif de Google est de prédire quelle réponse vous voulez faire à un mail donné. Ils auraient donc pu donner une seule suggestion de réponse. Mais si vous ne cliquez pas dessus, il n’est pas possible de savoir si c’est parce que vous ne voulez pas utiliser ce service ou parce que la suggestion n’est pas bonne. Avec trois suggestions de réponses, lorsque vous cliquez sur une réponse, ils savent que les autres étaient moins adaptées. Certains considérerons que le service est légèrement dégradé pour l’utilisateur mais Gmail obtient ainsi un vrai feedback.
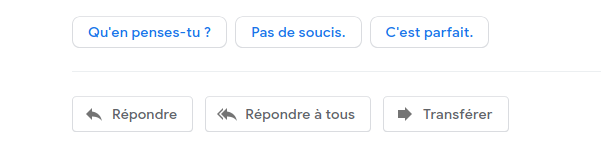
Figure 1 : Suggestion de réponses faites par Gmail.
Ces deux premières solutions peuvent semblent assez similaire, la principale différence est que dans la première il n’y a pas besoin de changer le modèle de machine learning alors que dans la deuxième si.
Solution 3 : Séparer la collecte de la prédiction idéale et l’usage du système
L’idée est d’obtenir la prédiction idéale non pas directement auprès des utilisateurs de notre système, mais d’une manière indirecte.
Sur notre exemple de recommandation de film, on pourrait récupérer les données d’une plateforme de vidéo à la demande, ou demander à des experts cinématographiques de faire des recommandations.
Cette technique revient presque à de l’annotation de donnée et a un coût : rémunérer les annotateurs, mettre en place un outil d’annotation, former les équipes, ...
Le défaut de cette technique est de prendre un proxy de la prédiction idéale : plutôt que d’avoir “ce film intéresse cet utilisateur” on a “l’expert cinématographiques pense que ce film va intéresser cet utilisateur.”
Les principes qui nous ont guidés pour ces problèmes qui ont des utilisateurs non intéressés à donner leur feedback sont :
- Inciter l’utilisateur à donner son feedback, en le rendant facile et utile, pourquoi pas en modifiant le problème,
- Utiliser des experts pour contourner le problème.
Délai pour obtenir la prédiction idéale

Lorsque le système prédit à un horizon de temps, on ne peut obtenir la prédiction idéale qu’au bout de cet horizon de temps. Faire fonctionner pendant 6 mois un système sans avoir de retour sur son bon fonctionnement est assez risqué. On va donc chercher à avoir un retour sur sa performance à plus court terme.
Un exemple : Un système qui prédit l’achat d’une voiture sous un mois.
Il est nécessaire de prédire à un mois, car le processus d’achat est long. Les étapes sont généralement :
- Aller en concession pour découvrir les voitures du moment,
- Faire estimer l’ancienne voiture,
- Prendre rendez-vous pour essayer une voiture,
- Réfléchir,
- Prendre rendez-vous pour signer l’achat de la nouvelle voiture, et la vente de l’ancienne.
L’objectif est d’établir le contact avec le prospect avant qu’il aille dans une concession concurrente.
Solution 1 : Prédire plus près dans le temps
L’un des problèmes lorsque l’on prédit sur un long horizon de temps est que les effets non mesurés, qui peuvent avoir un impact sur la prédiction idéale (par exemple, une offre concurrente qui casse les prix et change la structure du marché telle qu’on l’a apprise lors de l’entraînement) sont plus nombreux, et leur probabilité d'occurrence plus élevée.
Pour limiter ces effets non mesurés, l’idée est de prédire des évènements intermédiaires, plus proches dans le temps.
Cette solution revient à changer en parti le problème : plutôt que de prédire l’achat d’une voiture à un mois, on pourrait prédire la venue sur notre site internet, la venue en concession automobile, etc.
Solution 2 : Prendre du feedback des parties prenantes
En attendant la récupération de la prédiction idéale, l’idée est de demander aux parties prenantes (utilisateur, métier, stakeholder, …) si la prédiction semble pertinente. Avec l’expérience, les parties prenantes acquièrent une expertise qui est un bon indicateur de la pertinence d’une prédiction.
Sur notre exemple de vente de voitures, on peut demander au commercial en charge du dossier de nous dire s’il pense que la prédiction est pertinente. D’ailleurs, si le commercial ne trouve pas la prédiction pertinente il aura du mal à vendre (pour aller plus loin sur le sujet de l’utilisation de prédictions vous pouvez creuser l’interprétabilité et la confiance des systèmes de data science).
Il y a trois limites à cette pratique :
- Il faut que la personne ait une expérience sur le sujet. Par exemple un commercial qui n’a vendu que des voitures diesel aura sans doute du mal à savoir si un client est effectivement appétant aux voitures électriques.
- Il faut que la personne voit un intérêt à donner son feedback sinon elle ne le donnera pas, ou trop ponctuellement. Sur un cas d’usage de prédiction de défauts, nous avons proposé à l’opérateur de nous dire si la prédiction était juste ou non. On a eu très peu de retours car l’opérateur n’avait pas le temps nécessaire à nous accorder. Pour que la personne ait intérêt à donner son feedback, on peut s’inspirer des solutions proposées dans la partie “L’utilisateur n’est pas incité à donner son feedback”.
- Ce n’est qu’un proxy : ce n’est pas parce qu’une partie prenante considère que la prédiction est fausse qu’elle l’est vraiment. Il est notamment biaisé en fonction des intérêts personnels. Par exemple, un commercial réticent à l’utilisation de modèles qui lui disent comment faire son travail aura tendance à juger négativement les prédictions.
Solution 3 : Mesurer des prédictions idéales partielles
Même si la prédiction est faite à 1 mois, il est possible d’avoir une partie de la prédiction idéale plus tôt.
Sur notre exemple d’achat de voiture, il y a certains prospects qui vont acheter dès la première semaine. On pourra donc avoir une mesure partielle du nombre d’acheteurs à un mois. En utilisant la métrique de précision, nous avons représenté les performances en production sur la figure 2.

FIgure 2 : Evaluation de la performance en termes de précision au cours du temps.
En phase de construction, il est possible d’évaluer la performance du modèle entraîné à un mois sur différents horizons : 1 semaine, 2 semaines, … (représentée par des lignes en oranges sur la figure 2). Ces performances à différents horizons nous donnent une référence pour la performance obtenue en production.
On peut donc voir, sur la figure 2, que la performance sur les prédictions du 13/04 sont au-dessus de la référence, et celles du 20/04 en dessous.
Les principes qui nous ont guidés pour ces problèmes à fort horizon temporel sont :
- Essayer de prédire des événements proches dans le temps.
- Prendre des proxys qui donnent un feedback plus rapide pour avoir un a priori sur la performance.
La prédiction idéale provient d’annotations

Le problème :
Les systèmes de data science qui utilisent des images, des séries temporelles ou du texte ont souvent une cible qui est issue d’annotations (c.à.d. on demande à des experts de fournir les labels).
NB : L’annotation est utilisée lorsque les labels ne sont pas stockés ou lorsque l’on met en place un nouveau processus. Cette annotation est un proxy des labels idéaux puisqu’elle revient à demander à un expert de donner son avis a posteriori.
L'annotation est, à tort, limitée à la construction du système pour entraîner un modèle de machine learning. Ne pas avoir d’annotations en production empêche de monitorer le système.
Exemple : Un système de détection de défauts par inspection visuelle.
Le système prend des photos d’une pièce, prédit s’il y a présence de défauts et les indique à un opérateur pour qu’il les corrige.
Pour construire un tel système, nous avons entraîné un modèle de machine learning sur un ensemble d’images annotées. Ces annotations ont été faites par des qualiticiens.
N’ayant pas prévu d’annotations pour la phase de production, nous ne savons pas comment se comporte le système. Les seuls retours que l’on a sont ponctuellement des exemples d’images pour lesquelles le système s’est trompé. Ces retours sont difficiles à exploiter.
Solutions :
Les trois solutions que l’on propose ci-dessous font toujours appel au principe qui vise à penser les annotations en mode flux plutôt que comme une tâche ponctuelle.
Solution 1 : Faire annoter une portion des situations de production chaque jour
Cette solution consiste à faire annoter régulièrement un pourcentage des variables explicatives (image, texte ou série temporelle) afin d’obtenir un feedback sur celles-ci. Il y’a un équilibre à trouver sur le nombre de situations à annoter : suffisamment peu pour que cela ne coûte pas trop cher, suffisamment pour que ce soit représentatif.
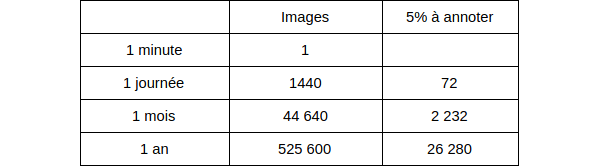
Figure 3 : Exemple d’ordre de grandeur d’images (1 image / minute, 5 % d’annotations)
Sur notre exemple de détection de défauts par inspection visuelle, on peut choisir d’envoyer tous les jours 5% des images à une taskforce d’annotations. Grâce à ces annotations, nous pourrons évaluer la performance réelle du système.
Cette annotation continue doit être pensée tôt pour mesurer la performance dès le début de la phase de production. Il faut alors prévenir les annotateurs, prévoir un budget et construire un outillage pour annoter efficacement. Cela est d’autant plus important que le métier d’annotateur n’existe généralement pas dans les entreprises, il faut alors demander à des personnes / experts de dégager du temps ou faire appel à un sous-traitant.
NB : Comme pour les labels, l’annotation est un proxy de la prédiction idéale. La prédiction idéale est “tous les défauts qui aurait posés problèmes ultérieurement” alors que l’annotation est “tous les défauts que l’annotateur a vu”.
Solution 2 : Prendre du feedback des parties prenantes
L’idée est, comme dans le cas du délai pour obtenir la prédiction idéale, de demander du feedback sur la prédiction.
Sur notre système de détection de défauts par inspection visuelle, on peut fournir une tablette à notre technicien sur laquelle il clique pour indiquer le défaut qu’il est en train de traiter. Un défaut sur lequel il n’a pas cliqué est donc soit un défaut qu’il n’a pas corrigé, soit une fausse prédiction.
Les mêmes limitations que citées plus haut s’appliquent : Il faut que la personne ait une expérience sur le sujet.; Il faut qu’elle voit un intérêt à donner son feedback; Son feedback peut-être biaisé en fonction de ses intérêts et ce n’est qu’un proxy.
Solution 3 : Gamifier l’annotation
Comme nous avons besoin d’annotation tout au long de la vie du système, une technique à laquelle les GAFA sont rodés, c’est la gamification de l’annotation.
Un exemple est l’ajout de tag ou de personnes sur des photos proposé par Instagram. Ils développent des modèles de recommandation de contenu. Le problème est donc de savoir à qui recommander cette photo qui vient d’être postée. En ajoutant un tag ou le nom d’une personne, vous leur indiquez une partie de la prédiction idéale : cette personne, ou les personnes aimant ce tag seront probablement intéressées par votre photo.
Les principes qui nous ont guidés pour récupérer la prédiction idéale sur des systèmes construits avec des annotations sont donc :
- Penser flux plutôt que one-shot.
- Gamifier / faciliter l’annotation pour en réduire le coût.
- Prendre des proxys.
L’impact de votre système empêche d’observer la prédiction idéale
![]()
Le problème :
Lorsque l’on utilise du machine learning supervisé, l'objectif est souvent non seulement d’identifier des situations mais aussi d’agir dessus.
L’action que l’on apporte a pour objectif de modifier la situation, il devient alors difficile de savoir si la situation a été correctement prédite.
Dans ce cas la prédiction idéale et la ground truth sont différentes.
Exemple : Un système de maintenance prédictive.
Le système prédit l'occurrence d’une panne est utilisé pour faire de la maintenance prédictive. Lors d’une prédiction de panne, un technicien intervient pour entretenir de manière préventive la machine. Si le technicien fait bien son travail, alors la machine ne tombera pas en panne.
Solution 1 : Le groupe témoin
“Dans une expérience scientifique, un groupe contrôle, ou groupe témoin, est un groupe d'individus qui ne reçoit pas le traitement testé. À l'issue de l'expérience, comparer les individus du groupe témoin à ceux du groupe traité (ou groupe expérimental) permet d'évaluer l'effet du traitement.” (Source wikipedia)
Les groupes témoins sont très utilisés en médecine ou en marketing sous la dénomination A/B testing. Ils sont particulièrement utiles lorsqu’il y a une dimension temporelle dans le problème à résoudre (c.à.d. du prédictif).
L’objectif est de mesurer l’apport du système par rapport à son absence. Il y a deux façons de faire: soit ne pas traiter des cas identifiés, soit ne pas prédire sur une partie de la population.
Dans notre exemple, il s’agirait soit de ne pas prédire sur une partie des machines et mesurer combien sont tombées en panne par rapport aux machines traitées, soit de ne pas signaler au technicien un pourcentage de pannes prédites et mesurer combien ont donné effectivement des pannes.
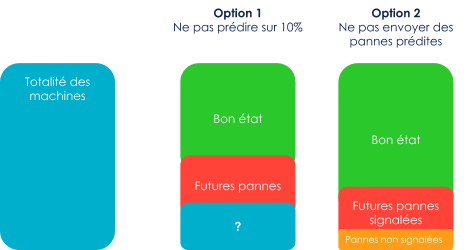
Figure 4 : Représentation de deux façons de faire des groupes témoins.
Les utilisateurs sont parfois réticents à cette pratique car elle est coûteuse. Dans notre cas, des pannes qui auraient pu être anticipées et traitées ont effectivement lieu. Comme pour les annotations il faut trouver un équilibre sur le nombre de situations non traités entre le besoin de mesurer la performance et la perte causée par ce non traitement.
NB : A nouveau, cette technique doit-être mise en place sous l’angle des flux : il faut avoir un groupe témoin dans le temps, et non pas en mode one-shot.
Solution 2 : Obtenir la prédiction idéale avant modification
Cette technique consiste à constater si la situation prédite est présente avant de mener une action.
Cette technique est particulièrement applicable dans le cas où il n’y a pas de dimension temporelle dans le problème à résoudre (c.à.d. ce n’est pas du prédictif).
Sur notre exemple de prédiction de panne, on peut demander au technicien de confirmer qu’il y a effectivement une usure ou un problème qui va causer une panne avant d’entretenir la machine.
Cette technique revient à prendre un proxy de la prédiction idéale : au lieu d’avoir “la machine va effectivement tomber en panne” on a “le technicien a identifié un problème qui aurait causé une panne”.
Les principes qui nous ont guidés pour récupérer la prédiction idéale sur des systèmes dont l’impact empêche d’observer la prédiction idéale sont donc :
- La mise en place de groupes témoins
- Chercher à obtenir la prédiction idéale avant que l’impact ait lieu
Aller plus loin avec la prédiction idéale récupérée
Notre première motivation pour récupérer la prédiction idéale était de pouvoir mesurer la performance en phase de production. Ce sera une brique importante du monitoring de votre système en production. Pour aller plus loin vous pouvez regarder cette conférence qui donne une vue démystifiée et pragmatique du monitoring de data science.
Il est possible de tirer d’autres bénéfices de ce flux de prédictions idéales. Nous allons en voir trois.
Tout d’abord, il est possible d’utiliser cette prédiction idéale pour réentraîner le modèle de machine learning. Cela est intéressant uniquement lorsque les performances du modèle se dégradent significativement ou lorsque l’on a significativement plus de données. Il convient également d’être prudent, ce n’est pas toujours la prédiction idéale qui doit servir de label pour le réentraînement, parfois c’est la ground truth.
Ensuite, on peut utiliser le flux de prédictions idéales mis en place pour essayer des modélisations plus avancées telles que l’apprentissage par renforcement, l’active learning, ou l’online learning
Finalement, il est possible d’utiliser cette prédiction idéale pour construire un cas d’usage plus généraliste. Lorsque vous modifiez le texte de la suggestion de réponse de Gmail, vous permettez à Gmail de collecter du feedback sur la formulation de réponses. Ils pourront ensuite construire un cas d’usage de génération automatique d’email complexes. L’idée est donc de commencer avec des cas d’usages simples pour collecter plus de données qui permettront de faire des cas d’usages plus complexes.
Conclusion :
Il est acquis par les data scientists qu’il faut évaluer un système de data science au moment de l’entraînement. On a parfois tendance à oublier qu’il faut évaluer le système en phase de production.
L’évaluation en phase de production peut être compliquée par la difficulté à récupérer la prédiction idéale. Nous avons vu au cours de cet article les différents freins. Nous avons également vu qu’aucun n’était insurmontable.
Les principes suivants vous permettront de faciliter la récupération de la prédiction idéale :
- Penser flux plutôt que extractions ponctuelles
- Penser aux feedbacks dès la conception
- Adapter le problème pour faciliter la prise de feedback
- L’annotation n’est pas que pour la création du modèle, il y en a encore besoin en production
- S’assurer que l’on a choisi la cible la plus simple possible qui réponde au problème, essayer de prédire des événements proches dans le temps.
- Prendre des proxys. Nous avons vu la mesure des prédictions idéales partielles, la prise de feedbacks utilisateurs, la prise d’avis d’experts, etc.
Le premier usage de la récupération régulière de la prédiction idéale est bien entendu le monitoring du système. Nous avons également vu qu’il existe de nombreux autres usages tels : préparer le réentraînement, collecter des données pour d’autres cas d’usages.