Data-as-a-product: pierre angulaire du Data-Mesh
L'exploitation de la donnée à l'échelle : un enjeu stratégique ?
Dans son ouvrage Empowered, Marty Cagan cite quatre éléments essentiels d’une démarche orientée produit :
La première est d'être prêt à faire des choix difficiles sur ce qui est vraiment important.
La seconde consiste à générer, identifier et exploiter des informations pour orienter ces choix.
Le troisième consiste à convertir les idées en action.
Et le quatrième implique un management actif des personnes/équipes sans recourir au micromanagement.
Faire des choix c'est accepter que toutes les choses ne sont pas aussi importantes.
C'est pour éclairer et guider ces choix que l'exploitation de la donnée est fondamentale.
C'est la vocation de la Business Intelligence (BI) (dans le sens propre du terme intelligence pour renseignement), qui fait partie du monde numérique dit analytique. On fait des tableaux de bord, des projections pour prendre les décisions les plus pertinentes, et faire émerger des idées qui deviendront des actions.
Ce sont des projections visuelles de la connaissance que l'entreprise a accumulées et disséminées dans les données collectées au fil du temps.
En outre, dans le monde numérique qui permet d'opérer le business (un système e-commerce par exemple), l'exploitation de ces données par des programmes fait la promesse que des automates pourront auto-piloter une partie des activités opérationnelles par exemple en assistant le consommateur dans ses décisions propres.
L'entreprise disposera alors d'un ensemble de produits numériques dont le cœur du réacteur sera lié à la donnée.
L'enjeu sera alors d'organiser les données afin de permettre aux équipes de gagner en efficacité.
Cet article propose dans une première partie de définir les deux concepts de data-product et data-as-a-product comme fondation sémantique pour les équipes souhaitant travailler sur l'urbanisation de leurs assets de données. Puis dans un second temps, nous verrons comment ces deux concepts peuvent être déclinés concrètement pour soutenir une stratégie métier.
Langage omniprésent dans cet article
Produit
Un produit, au sens large, est une structure, d'origine artificielle, dont le but est de résoudre un problème particulier.
Un produit numérique est une déclinaison de produits technologiques. Pour atteindre son but, il doit :
Être réalisable techniquement.
Durable dans le temps, en tout cas aussi longtemps que le besoin est présent.
Apporter de la valeur intrinsèque.
Être utilisable par les gens concernés par le problème à résoudre. Dans un produit numérique, l'interface utilisateur est le lien entre l'utilisateur (l'humain) et les fonctionnalités qu'offrent le produit.
Système opérationnel
ensemble des éléments numériques permettant d'opérer le business
Système analytique
ensemble des éléments numériques permettant de prendre des décisions business
Des produits et des données
Dans cette partie, nous allons décliner deux concepts :
- Le data product qui va permettre de résoudre un problème dans un domaine particulier (c'est une solution numérique à un problème; cette solution est propulsée par la donnée)
- Le data-as-a-product qui va apporter des solutions à la gestion de la donnée pour permettre aux data-products de remplir leurs tâches (c'est une solution au problème de mise à disposition de la donnée à l'échelle de l'entreprise; elle a pour but de faciliter le développement des data-products).
Un Data Product
Pour définir un "data-product" nous allons nous appuyer sur la définition de DJ Patil:
To start, for me, a good definition of a data product is a product that facilitates an end goal through the use of data.
Data Jujitsu - The art of turning data into product - DJ Patil *- 2012
Ainsi nous définirons un data-product comme étant un produit permettant d'atteindre son but grâce à l'utilisation de données.
Dans un système analytique, le data product peut prendre la forme d'un rapport permettant de prendre des décisions éclairées.
Dans un système opérationnel, un data product peut prendre la forme d'un système de recommandation produit dans un système de vente e-commerce par exemple.
Un Data-as-a-product
Le data-as-a-product est un concept issu du monde du data-mesh formalisé par Zhamak Dehghani.
Dans le contexte du data-mesh, le terme data représente également un ensemble d'éléments dont la signification des composants est fixée par un ensemble de règles sémantiques (la définition est la même que dans le contexte du data-product car, nous parlons bien de la même donnée).
Passer de data à data-as-a-product consiste à appliquer les règles du product thinking directement à la donnée.
Ainsi le problème que nous cherchons à résoudre avec le data-as-product est le besoin du data-product de disposer de données fiables, qualitatives, accessibles et dignes de confiance.
Par conséquent, nous voyons que le data-as-a-product est bien plus qu'un simple "data-set". La meilleure description d'un produit passant par une description de ce qu'il fait, plutôt de ce qu'il est, nous allons lister l'ensemble de caractéristiques propres ainsi que celles des fonctions qu'il offre (cette notion s'appelle affordance).
(Ces affordances sont expliquées dans le détail dans le chapitre 11 de l'ouvrage Data-Mesh).
Affordance 1: servir des données
C'est une évidence: le data-as-a-product expose des données. Ces données sont exposées via des interfaces clairement définies.
La donnée fournie est en lecture seule afin de garantir l'idempotence des opérations consommant la donnée (tels que des systèmes d'analyse ou de machine learning par exemple).
Affordance 2 : consommer des données
Pour fournir sa valeur, le data-as-a-product consomme des données depuis des sources variées. Les données sources peuvent provenir de différents systèmes tels que :
Des systèmes opérationnels (des bases de données)
d'autre data-as-a-product
des systèmes externes
Affordance 3 : transformer des données
L'essence même du data-as-a-product est de proposer des nouvelles données. Le data-as-a-product doit offrir au développeur la possibilité de transformer les données qu'il a consommées de multiples façons telles que du code, de l'application de modèles de machine learning ou via des requêtes complexes.
Affordance 4: découvrir, et comprendre le sens des données
Le data-as-a-product expose l'ensemble des informations nécessaires pour que les utilisateurs puissent découvrir, comprendre, et utiliser le data-as-a-product en toute confiance.
Affordance 5: offrir des fonctions de maintenance et de gestion du cycle de vie du produit
Bien au-delà de simplement fournir les informations (affordance 1), le data-as-a-product doit offrir des fonctions de maintenance qui doivent permettre de facilement mettre à jour le produit sans interférer avec l'affordance 1. Par exemple en proposant une fonction de mise sous version du code de transformation des données, ou encore du système de documentation.
Affordance 6 : Observabilité du produit
Il est nécessaire de pouvoir observer ce qui se déroule à l'intérieur d'un data-as-a-product. Les objectifs de cette observabilité sont variés comme par exemple :
- De permettre aux opérateurs de comprendre et analyser les résultat des traitements de transformation (affordance 3)
- De permettre aux analystes et aux développeurs de comprendre le cheminement de la donnée (lineage, ou passage de l'affordance 2 à l'affordance 1)
Affordance 7 : Un produit pilotable
Pour rappel, la gouvernance de données structure les règles de gestion de la donnée et de conformité avec la régulation en place. La gouvernance s'assure de plus de la mise en œuvre de ces règles; cependant le rôle de la gouvernance n'est pas de contrôler et de sanctionner le non-respect des règles.
Le produit doit offrir des capacités de gestion transverse pour permettre à un système extérieur au domaine d'agir sur la donnée.
Cette affordance se destine aux équipes de gouvernance, de sécurité mais aussi aux équipes de développement pour faciliter la mise en œuvre des règles de gouvernance. Ainsi, elle pourra offrir une capacité de nihilation d'une donnée personnelle en permettant la suppression d'une clé de chiffrement par exemple, ou encore la possibilité de gérer les politiques d'accès à la donnée en fonction des profils d'individus.
Mise en oeuvre des data-(as-a-)product
La bonne mise en oeuvre de produits (numériques) repose sur ces éléments :
- La mise en oeuvre doit se concentrer sur la résolution de problèmes et non l'ajout de fonctionnalités
- Le produit doit être conçu de manière collaborative (entre métier et tech) et non de manière séquentielle (expression de besoin, puis implémentation par exemple)
Dans le cadre des produits numériques d'aide à la décision (produit analytiques et/ou de machine learning), une représentation systémique pourrait être représentée par l'échafaudage suivant:
Définition d'une stratégie d'entreprise qui s'appuie sur la donnée pour atteindre un objectif (qu'est-ce que mon data-driven business)
Des initiatives métier comme soutien de la stratégie d'entreprise (quels est le plan d'action pour atteindre les objectifs)
Des applications (des data-products) en réponse aux besoins exprimés par ces initiatives (fournir les outils pour avancer dans la réalisation des objectifs)
Des données (data-as-a-product) qui répondent aux besoins des data-products (rendre disponible les données qui permettent de générer, identifier et exploiter des informations pour propulser les outils)
Une plateforme comme socle de développement et d'exécution de ces data-as-a-product (disposer des éléments technologiques pour matérialiser et exploiter ces solutions)
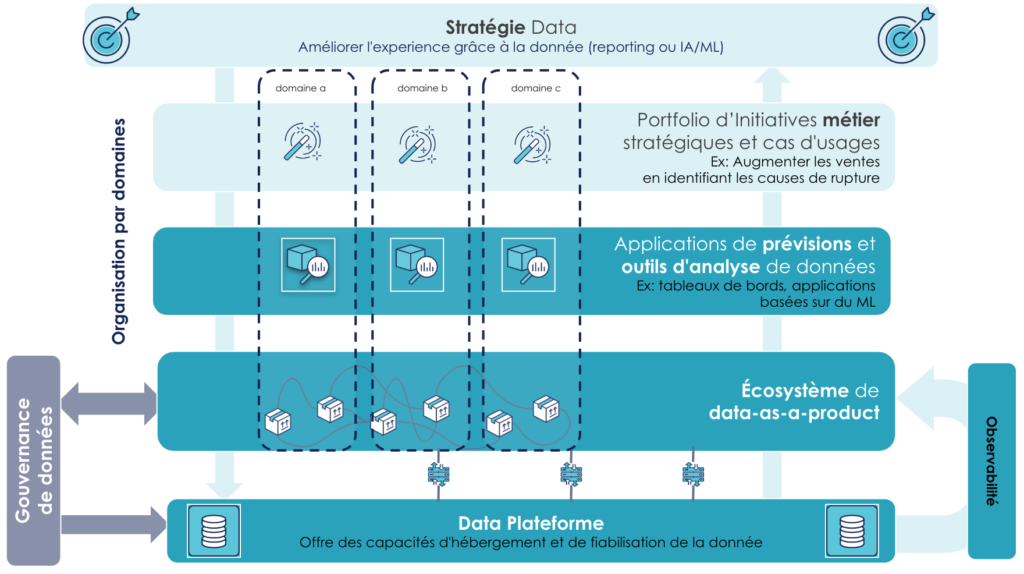
Note: La couche d'écosystème de data-as-a-product qui montre le maillage est hors scope de cet article qui se concentre sur la mise en pratique d'un des éléments et non sur une mise en place du data-mesh au global.
Déterminer les cas d'usage
Les chantiers de réalisation numériques se basent généralement sur des cas d'usage pour s'assurer que la finalité est en phase avec un besoin métier. Posons la définition suivante :
Un cas d'utilisation, ou cas d'usage ( « use-case » en anglais ), définit en génie logiciel et en ingénierie des systèmes une manière d'utiliser un système qui a une valeur ou une utilité pour les acteurs impliqués. Le cas d'utilisation correspond à un ensemble d'actions réalisées par le système en interaction avec les acteurs en vue d'une finalité. L'ensemble des cas d'utilisation permet ainsi de décrire les exigences fonctionnelles d'un système en adoptant le point de vue et le langage de l'utilisateur final.
Les cas d'usage sont en général sous la responsabilité de domaines métier (un domaine définissant ici une activité particulière disposant de ses propres concepts et vocabulaire; par exemple la logistique dans le monde du retail)
Avant toute chose, il convient de s'assurer que les cas d'usage présentent un réel intérêt pour la stratégie d'entreprise et que la solution apportée par l'implémentation apporte une réelle valeur ajoutée. Ainsi, par exemple, dans le cas de la logistique, un cas d'usage dont la finalité est de détecter les ruptures dans les chaînes d'approvisionnement alors que la stratégie business est de liquider les stocks n'apporte pas de valeur (étage 1 et 2 de l'échafaudage).
Nous l'avons vu précédemment, un produit doit apporter une valeur intrinsèque; un bon pattern d'architecture est que le data-as-a-product serve plusieurs cas d'usage et donc plusieurs data-produits pour éviter que sa valeur ne s'exprime qu'au travers du cas d'usage définit.
Placer les cas d'usage sur une carte pour faire apparaitre les data-as-a-product
Note_: une_ carte de Wardley est un outil qui permet de prendre des décisions d'orientation du Business en cartographiant et en étudiant l'évolution des biens propres à une entreprise.
Les biens (composants), qui peuvent être tangibles comme des logiciels ou de la donnée, ou abstraits comme des activités, sont placés verticalement sur une chaîne de valeur. Ce placement permet de représenter l’importance des composants vis-à-vis d’un point de repère particulier (plus nous en somme loins, moins c’est visible, la valeur du bien du point de vue du repère devrait donc être moindre).
Les biens sont ensuite placés sur un axe horizontal qui représente les étapes d’évolutions de ces éléments (dont la définition change en fonction du type de bien).
En guise d'illustration, un atelier basé sur les cartes de Simon Wardley pourrait donner le résultat suivant (c'est un exemple fictif):
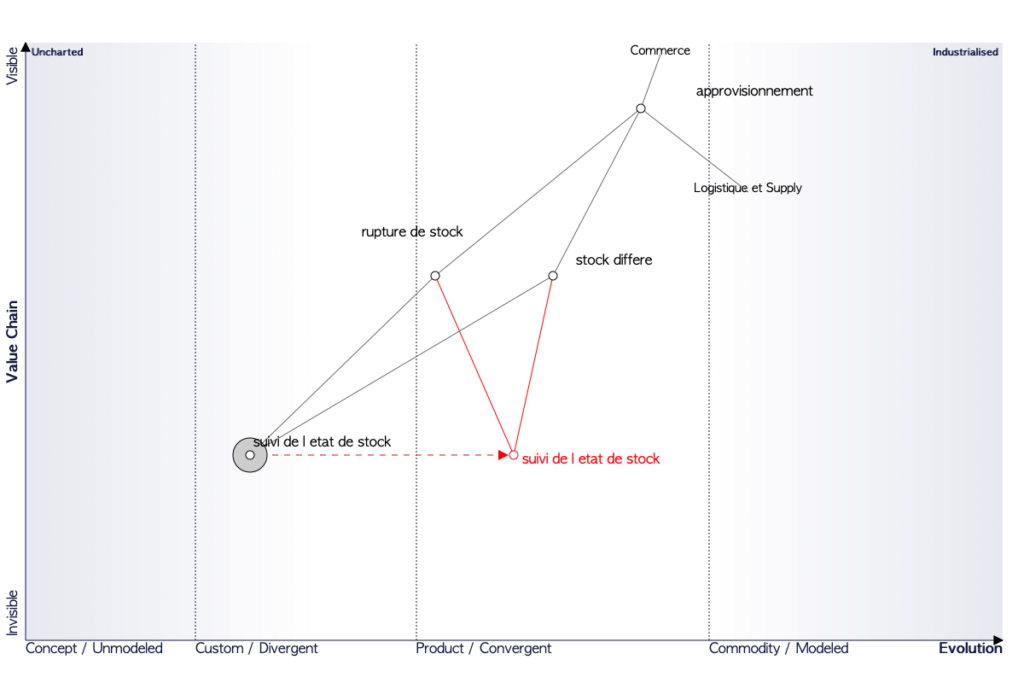
Carte de Wardley
Si une carte de Wardley permet de situer une entreprise dans son marché, nous faisons ici un zoom qui permet de représenter une activité dans le contexte de l'entreprise. Ainsi, sur la carte représentée ici, on voit émerger un besoin de data-as-a-product qui expose le suivi de l'état des stocks.
Explications: Le commerce a besoin de suivre l'approvisionnement, le fait qu'il soit très visible du commerce (entre commerce et approvisionnement sur l'axe vertical) montre que c'est une stratégie de l'entreprise (là où c'est moins visible de la supply chain). Pour suivre l'approvisionnement, il faut des produits qui permettent de gérer les ruptures de stocks (stock-out) ainsi que les stocks différés (backorders).
Ces composants vont utiliser les données issues de l'état des stocks qui se trouveront dans la phase II de l'évolution et qui vont évoluer vers un produit (phase III) au fur et à mesure des itérations. Dans la phase II, les données sont non modélisées et chacun des composants rupture de stock et stock différé utilise sa version des données suivi des stocks. La rationalisation de l'usage va permettre de gérer les données comme un produit qui apportera de la valeur.
| Phases d'évolution | I | II | III | IV |
|---|---|---|---|---|
| Donnée | Unmodeled | Divergent | Convergent | Modeled |
| Activité | Genesis | Custom-Built | Product | Commodity |
Déterminer les frontières sémantiques des données
Une fois le besoin du data-as-a-product avéré, il faut déterminer la sémantique utilisée par ce dernier.
Dans le paradigme data-mesh, un data-as-a-product appartient à un domaine métier; il en est responsable. En s'inspirant des méthodes du DDD, nous pouvons déterminer les frontières sémantiques du data-as-a-product en l'assimilant à un bounded-context.
Ainsi, un atelier de type event-storming devrait nous permettre de déterminer le vocabulaire omniprésent dans le data-as-a-product ainsi que de déterminer:
Quelles sont les données produites
Comment sont-elles mises à disposition
Quel est le cycle de vie des données
Quelles sont les données consommées par ce produit
Quels sont les règles de calcul, transformation et agrégation et de déclenchement interne au produit
Rentrer dans le cycle de développement du produit
Une fois le cadre fonctionnel posé le cycle de développement commence.
Comme nous l'avons vu dans la première partie, le data-as-a-product, caractérisé par ses affordances est bien plus qu'un simple data-set.
Ainsi, pour que le produit soit utile, utilisable et utilisé et apporte ainsi de la valeur au business, il est nécessaire de développer et standardiser certaines de ces affordances.
Publication des métadonnées du produit
La publication des quatre premières affordances (servir des données, consommer des données, transformer des données, et découvrir, et comprendre le sens des données) passe par l'écriture d'un manifeste (décrit dans le chapitre 14 du livre de Zhamak Dehghani).
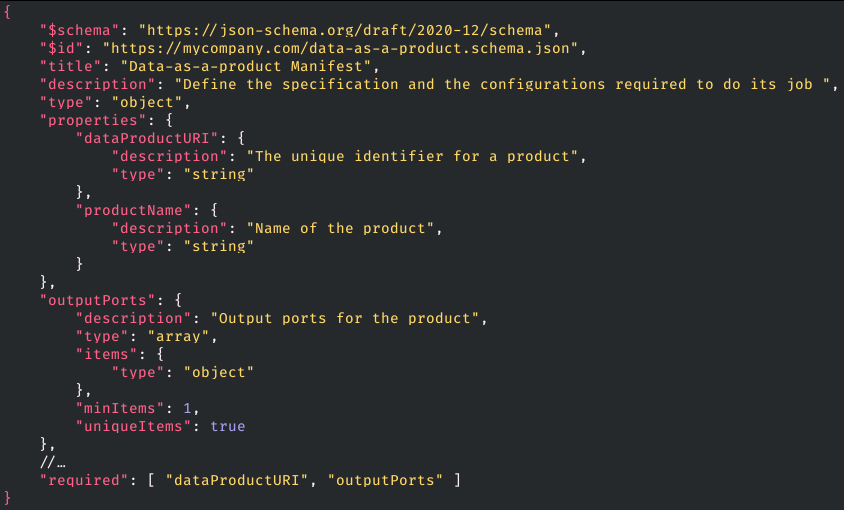
Exemple de manifeste exprimé en JSON-Schema
Parmis les informations indispensables de ce manifeste, on trouve:
L'adresse à laquelle les données produites par le data-as-a-product peuvent être consommées
La description des portes de sortie du produit (output ports) qui ont deux vocations: décrire le mode d'accès aux données et permettre le provisionnement des ressources nécessaires (nous y reviendrons juste après avec la notion de plateforme)
Des fiches de description de Service Level Objective (SLO) pour exposer le niveau de service que l'on cherche à atteindre pour chaque porte de sortie
Les portes d'entrée qui décrivent l'origine et le mode de récupération des données source
La politique interne de gestion des données (rétention, confidentialité, …)
Les éventuels assets supplémentaires nécessaire au fonctionnement du produit (par exemple les données entraînées d'un algo de ML)
La standardisation du format du manifeste facilitera la consommation des data-as-a-product à l'échelle de l'entreprise. De plus, l'utilisation d'un système de sérialisation tel que JSON ou YAML facilitera l'utilisation de la donnée par des systèmes externes.
Le code de génération
Une autre partie fondamentale du data-as-a-product est le code qui permet de générer la donnée.
Il conviendra d'adopter de bonnes pratiques de versionning de code ainsi que de génération, et d'utiliser les techniques de déploiement héritées de l'expérience acquise dans le monde opérationnel.
Ainsi, la mise en place d'usines de déploiement logiciel, de chaîne de CI et d'automatisation de tests permettront de proposer un niveau de qualité optimum du data-as-a-product.
Des outils tels que DBT ou encore Dataform faciliteront l'application de ces pratiques (et demain des langages tels que PRQL permettront de gérer de mieux en mieux le code de génération de la données)
La plateforme
Élément essentiel du paysage numérique, la plateforme de données facilite le développement, déploiement et utilisation des data-as-a-product.
Nous reprenons les principes décrits par Evan Bottcher et définissons la plateforme comme un ensemble d'API self-service, de services, de connaissance ainsi que le support qui permettent leur utilisation; ces composants sont organisés comme un produit interne à destination d'équipes de delivery autonomes.
Dans le cadre du développement des data-as-a-product, la plateforme va fournir les services d'hébergement de la données compatibles avec la définition des output-ports ainsi que les systèmes de calculs qui vont permettre d'exécuter le core du data-as-a-product tel qu'un moteur SQL comme BigQuery sur GCP, Redshift sur AWS ou encore Snowflake.
Attention cependant à ne pas faire l'amalgame entre les services fournis par le cloud provider et la plateforme.
En effet, la plateforme est un produit interne qui répond aux besoins. Les capacités offertes par les cloud providers sont en quelque sorte des facilitateurs qui facilitent la mise en place du produit.
La plateforme est construite au fur et à mesure de l'expression des besoins exprimés par les data-as-a-product.
La Thinnest Viable Plateforme (TVP) capable de supporter les affordances du produit peut tout à fait être un système documentaire bien organisé pour héberger le manifeste décrit précédemment (la notion de TVP est décrite dans l'ouvrage Team Topologies).
Conclusion
La mise en place d'un data-as-a-product doit apporter une valeur intrinsèque;
La méthode décrite dans cet article est un exemple de chemin pour arriver à cette valeur. Cette méthode ne se veut pas exhaustive ou exclusive; elle regroupe un ensemble d'éléments qui ont fait leurs preuves dans la mise en place de produits logiciels opérationnels au cours des dernières années.
Si la valeur métier du data-as-a-product est immédiatement rendue via la mise en place des cas d'usage, c'est le maillage de ces derniers entre eux qui va apporter un avantage concurrentiel à l'échelle de l'entreprise.
Cet avantage se verra:
- au travers de la réduction du temps de mise en place des nouveaux cas d'usage (avec la possibilité de tester des solutions basées sur le machine learning plus facilement par exemple)
- Dans une meilleure organisation de la connaissance à l'échelle de l'entreprise
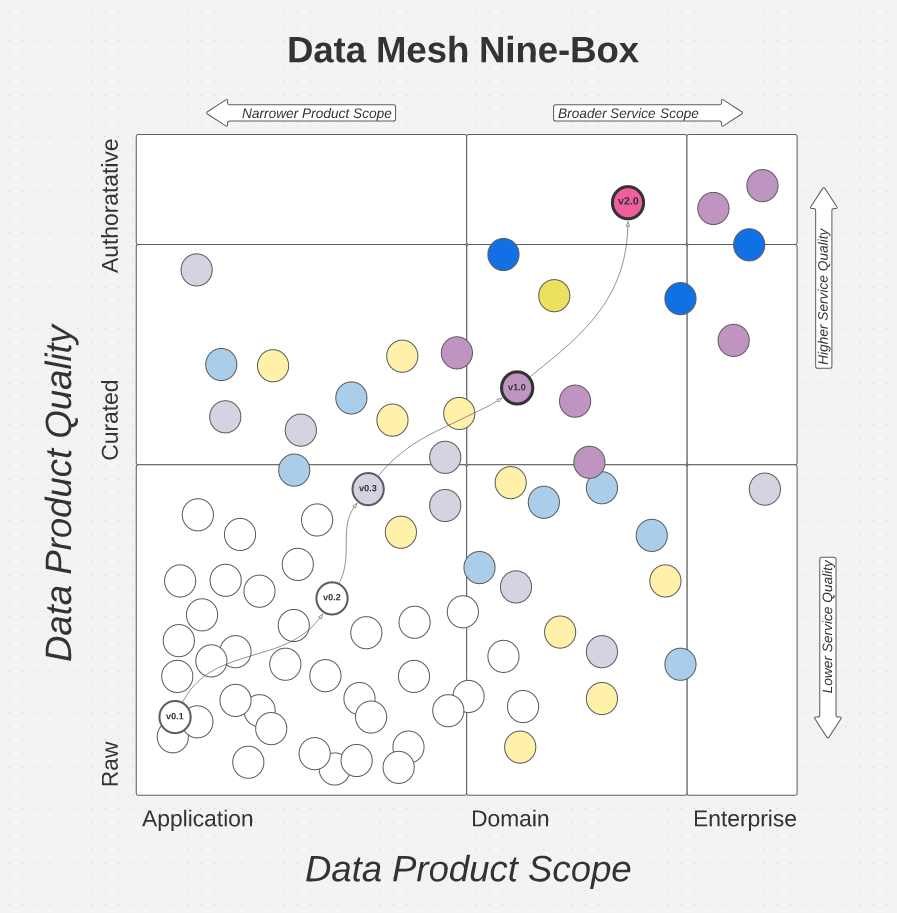
(c) Travis Hoffman, 2021 - https://www.linkedin.com/in/travishoffman/
Par exemple, l'illustration ci-dessus, montre l'apport de valeur grandissant à l'échelle de l'entreprise au fur et à mesure des itérations réalisées sur un data-as-a-product.
Enfin, en ce qui concerne la plateforme, elle peut être construite en parallèle en posant les premières briques qui permettront l'échange des données entre les produits.
L'arrivée de nouveaux langages d'interaction avec la données (SQLX, PRQL) apporte un certain changement qui va permettre de répondre au mieux aux besoins spécifiques en construisant du custom tout en continuant à exploiter la puissance offerte par les cloud providers.