Dans les rouages de Cline (ex Claude-dev): un Agent pour assister à coder
Vous vous intéressez à la GenAI et le terme d’agent est un peu flou ?
Vous avez entendu parler de Claude-dev et vous vous demandez comment ça marche?
Vous développez des produits GenAI et vous aimeriez avoir des insights sur un Agent bien pensé ?
Alors pas de panique, cet article est fait pour vous.
Introduction
En fin 2022, OpenAI a publié le mondialement connu ChatGPT, capable de répondre à toutes les questions, détrônant ainsi madame Irma et son éternelle boule de cristal.
Par l’explosion de la popularité de cette application, de nombreux acteurs se sont mis à vouloir obtenir la meilleure IA pour effectuer des tâches de génération de texte.
Plus elles sont grosses, meilleures elles sont, on comprend donc pourquoi le terme de Large Language Model (LLM) a commencé à apparaître vers avril-mai 2023.
Au cours de l’année ayant suivi l’apparition de ChatGPT, le grand public s’est rendu compte que l’IA pouvait elle-aussi raconter n’importe quoi - de façon similaire à leur marabout favori-, on parle alors d’hallucination.
Les constructeurs de logiciels basés sur de l’IA générative ont alors réalisé qu’il valait mieux utiliser les LLMs pour raisonner, plutôt que pour en extraire des connaissances. Cette vision est parfaitement illustrée par la déclaration du fondateur d’OpenAI Sam Altman :
> “The right way to think of the models that we create is a reasoning engine, not a fact database”
En effet, ces modèles hallucinent beaucoup moins lorsqu’on les interroge en leur ayant mis à disposition une source de données à laquelle ils peuvent se référer : ils raisonnent ainsi sur la base d’informations sourcées plutôt que de leur mémoire, et obtiennent ainsi de meilleures performances.
Rapidement, la notion d’Agent a été introduite dans le milieu de la GenAI : un agent est un programme dédié à la réalisation d’une tâche, et celui-ci intègre un LLM lui permettant d’être autonome dans la réalisation de celle-ci.
Alors à la différence des programmes classiques, la prise de décision de l’agent est décidée par le LLM. Imaginez un agent configuré pour créer une recette de cuisine sur la base des ingrédients que vous lui donnez. En pseudo-code, le prompt de l’agent (= le texte envoyé au LLM) donnerait quelque chose comme ça :
“””Tu es un cuisinier émérite qui ne manque pas d’imagination ni de fantaisie.
A l’aide d’ingrédients qui te sont fournis, tu dois te débrouiller pour
faire une recette en te servant un maximum de ce que tu as à disposition.
Voici les ingrédients disponibles :
{INGREDIENTS}
Voilà la recette :
“””
Si je lui indique la liste de courses suivante dans la variable INGREDIENTS :
- Moutarde de dijon
- Bananes bien mûres
- Confiture de fraises
- Copeaux de chocolat
- Saucisse de Toulouse
Et bien de façon totalement autonome et sans se référer à des règles écrites en dur dans du code, l’agent prendra l’initiative de vous concocter la recette de vos rêves. Si vous avez de la chance, il vous proposera peut-être même du Gloubi-Boulga…
Autre point notable pour les néophytes, les LLMs sont isolés du monde extérieur : ils en ont une connaissance fixe - qui est stockée dans ses milliards de paramètres - et ils ne peuvent pas interagir directement avec l’environnement.
Cette interaction et prise de contexte peuvent se faire de différentes façons, et une d’entre elles consiste à donner la possibilité au LLM d’exécuter des outils (tools) si besoin est.
Le LLM ne les exécute pas vraiment en réalité, il indique seulement dans son texte généré, l’outil qu’il voudrait utiliser. Par la suite, c’est le programme utilisant le LLM qui exécute l’outil.
Parmi les outils, on retrouve en général des wrappers autour d’APIs, autour d’invités de commandes shell ou python.
Les outils sont des moyens généralement déterministes d’exécuter des tâches très spécifiques, et ne sont pas dépendant d’un LLM, au contraire de l’agent.
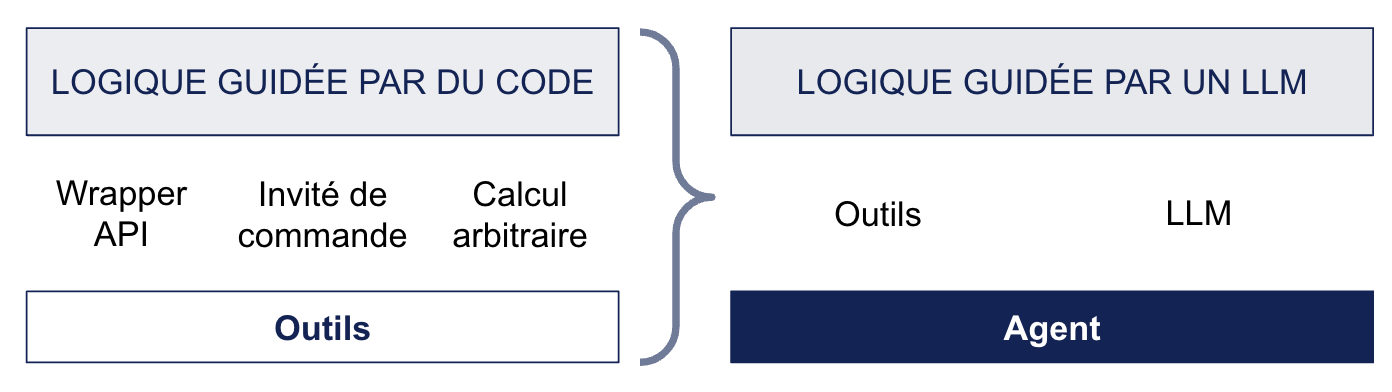
Outil vs agent
En revanche, pour être intégré dans un agent l’outil doit renseigner les informations suivantes (d’après la documentation de langchain) :
- Son nom - pour que le LLM puisse dire “Il faut utiliser l’outil X”
- Sa raison d’exister - pour que le LLM puisse savoir quand l’utiliser
- Le schéma des paramètres d’entrée - pour que le LLM puisse savoir comment l’utiliser
- La fonction à appeler - pour que le LLM puisse savoir quoi exécuter
- Si l’outil doit retourner le résultat directement à l’utilisateur ou au LLM l’ayant invoqué
Pour récapituler, un agent est donc un programme dans lequel on trouvera un prompt, un appel à un LLM, et éventuellement une liste d’outils utiles pour réaliser sa mission.
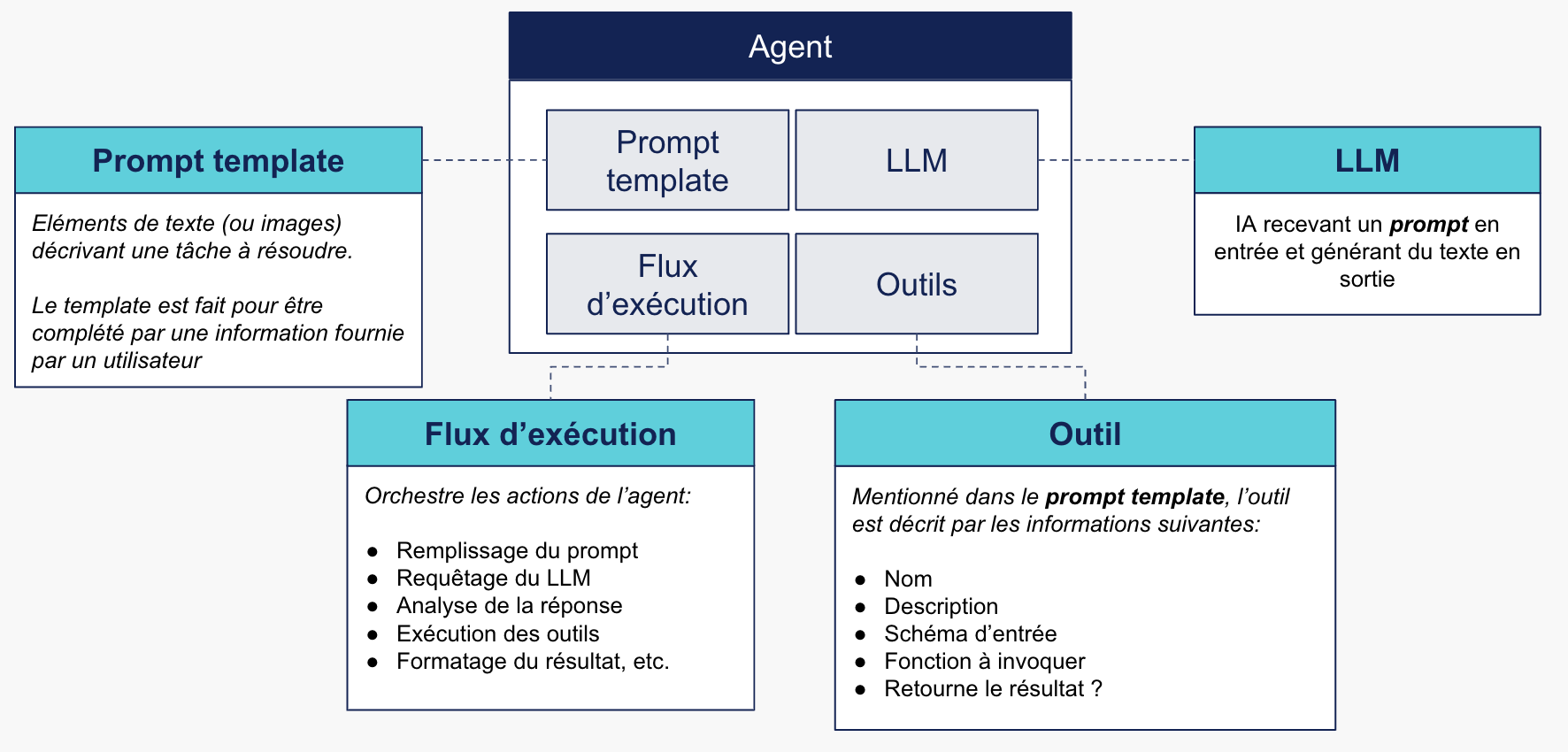
Constitution générale d’un agent
L’agent dont on va s’intéresser dans cet article a pour petit nom Claude-dev. Il est vendu par son concepteur comme étant un coding agent, un assistant autonome, capable d’éditer et créer des fichiers, d’exécuter des commandes (et bien plus encore).
Comme précédemment expliqué pour les agents, Claude-dev utilise un LLM pour résoudre des tâches qui lui sont assignées. Ce LLM a pour but de comprendre les requêtes utilisateurs, et de choisir les bons outils en conséquence.
Nous allons passer en revue son fonctionnement de façon générale, son prompt, l’ensemble des outils à disposition bref, les moindres détails.
Fonctionnement général
Pour utiliser Claude-dev, il faut d’abord l’installer depuis la marketplace de Visual Studio Code , puis le configurer avec une clé API provenant d’un des LLM providers autorisés (OpenAI, Anthropic, Bedrock, Ollama, Gemini, OpenRouter). Petite larme versée pour les utilisateurs d’IntelliJ, Claude-dev n’est pas disponible sur cet éditeur actuellement.
N’étant probablement pas Picsou, je ne peux que trop bien imaginer les frissons d’horreur vous parcourant l’échine à l’idée de débourser quelques euros pour tester le dernier jouet à la mode.
Pour vous rassurer, votre serviteur s’est permis d’effectuer une analyse financière de l’utilisation de Claude-dev, que vous pourrez lire dans la suite de l’article de façon détaillée. Pour le moment, je vous propose de vous contenter du chiffre suivant :
Le coût moyen par requête pour Claude 3.5 Sonnet tombe autour d’un cent de dollar.
Vous noterez que VScode est requis pour faire tourner l’agent; nous verrons plus tard comment Claude-dev exploite ce couplage pour agrémenter son contexte d’exécution.
Une fois l’extension mise en place, vous pouvez désormais vous en servir : Claude-dev vous informe qu’il peut vous aider; pour celà il met à disposition un prompt textuel auquel vous pouvez associer des images afin d’expliciter ce que vous désirez.
Pour cette occasion, j’ai décidé de demander une tâche un peu originale à notre cher agent, celui de transformer un croquis (réalisé en 3 minutes sur excalidraw) en un beau dessin d’architecture. Voyons un peu :
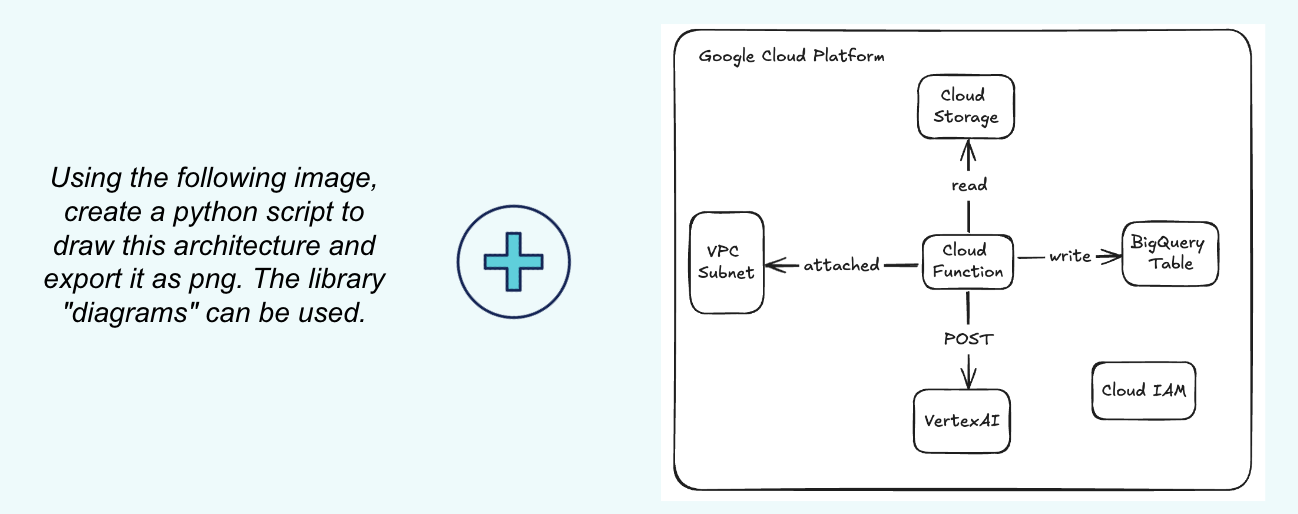
Prompt composé d’un court texte et d’une image
Sans vous spoiler le détail des pérégrinations de Claude-dev, celui-ci nous propose une démarche de résolution itérative pour arriver à la solution voulue.
Il nous offre un plan d’actions, nous demande la permission de les exécuter, et s’y colle suite à notre approbation. Ces actions permettent la création de fichiers, leur édition, l'exécution de commandes bref. Pas mal de choses quoi.
Mais quelle est la portée de ce que l’agent peut réaliser? Et comment fonctionne-t-il véritablement ?
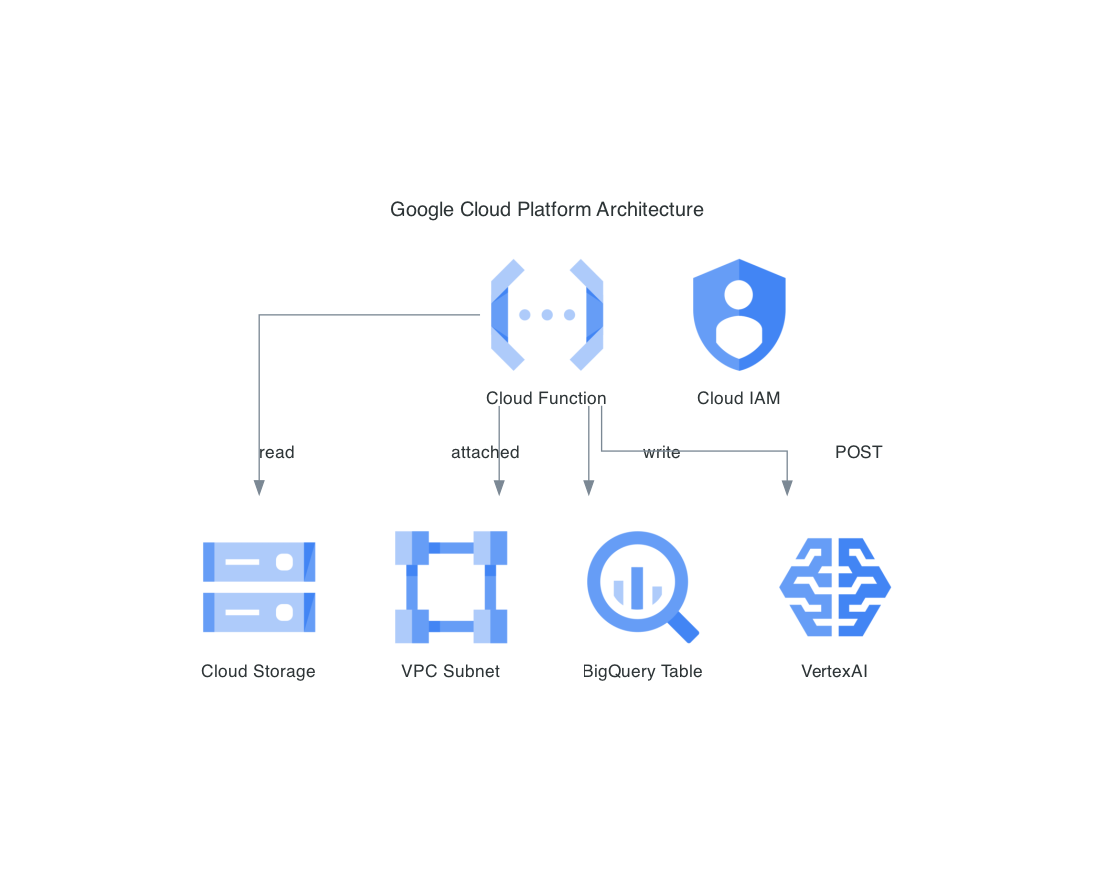
Résultat des 12 requêtes API (<0.12$) permettant de résoudre la tâche précédente
Les étapes clés
Claude-dev fonctionne par étapes. Quand on le sollicite pour un problème, il rentre dans une démarche de résolution prenant la forme d’une boucle itérative, et n’en sort qu’après avoir résolu la tâche.
Le flux d’exécution de l’agent peut se résumer en 6 étapes clés :
Un utilisateur vient solliciter Claude-dev afin de résoudre une tâche. Le développeur décrit le problème à résoudre et fournit éventuellement une image pour appuyer sa demande.
Un appel API est effectué vers un LLM provider
La réponse de cet appel API est ensuite analysée, elle permet de choisir plusieurs outils parmi ceux mentionnés dans le prompt.
Chaque outil est ensuite exécuté, et le résultat de l’exécution de chaque outil est ajouté à l’historique de conversation.
Un des outils renseigné dans le prompt est là pour “terminer” l’exécution de Claude-dev : si le LLM juge que la tâche est résolue par les actions précédentes, il va indiquer que cet outil doit être exécuté.
Si toutefois, le LLM juge qu’il y aura encore des actions à réaliser, alors nous allons recommencer au point (2), en ayant ajouté à l’historique de conversation le résultat de la requête API, et la réponse à l'exécution des outils. Cet historique de conversation fait partie intégrante du prompt envoyé lors de l’appel API.
Schématiquement, ces 6 étapes clés ressemblent à celà :
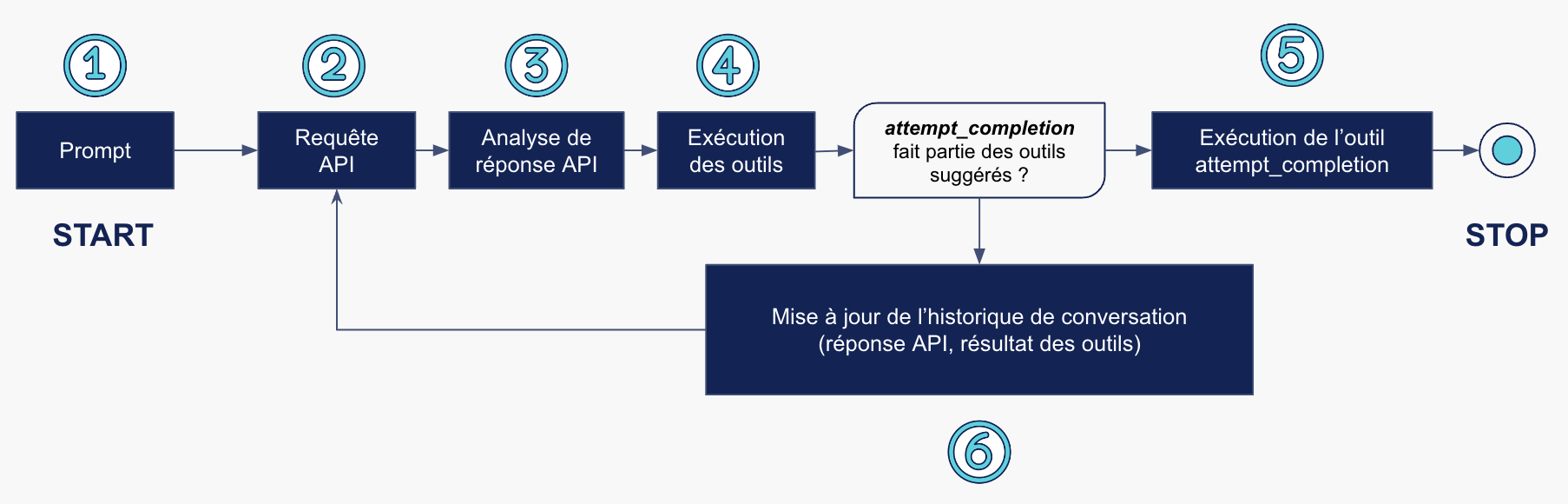
Flux d’exécution simplifié de Claude-dev
Si vous aimez aller dans le détail, je vous invite à poursuivre l’article, puisque nous allons passer en revue ces étapes de façon approfondie. Et à commencer par la première : le prompt!
Le prompt de Claude-dev
Dans Claude-dev, le prompt est très structuré. Pour ainsi dire, il est constitué en 4 parties : le prompt système, le prompt user, l’historique de conversation, et enfin la liste de tous les outils pouvant être utilisés pour mener à bien sa mission.
Prompt système
Ce prompt décrit à lui seul 5 éléments :
- Le rôle rempli par l’agent ainsi que son petit nom, Claude-dev
- Les capacités de l’agent : ce qu’il peut faire
- Ses règles à suivre : ce que Claude-dev doit ou ne peut pas faire
- Les objectifs à atteindre lorsqu’on le sollicite
- Les informations systèmes de la machine faisant tourner l’extension
Le rôle rempli par l’agent est celui-ci : “You are Claude Dev, a highly skilled software developer with extensive knowledge in many programming languages, frameworks, design patterns, and best practices”
Les réponses de l’agent devraient donc être orientées selon les bonnes pratiques de dev, et il s’y connaît en plusieurs langages de programmation. Bonnes nouvelles !
Les capacités de Claude-dev sont parmi les suivantes :
- Il est capable d’analyser et d’écrire du code selon les meilleures pratiques dans plusieurs langages de programmation
- Il peut utiliser des outils s’exécutant sur l’ordinateur de l’utilisateur pour l’aider à résoudre ses problèmes
Le prompt lui décrit un ensemble de cas d’utilisation d’outils disponibles : par exemple l’outil search_files permet d’effectuer des recherches par expressions régulières dans les fichiers d’un répertoire donné.
Quelques-unes des règles auxquelles il est soumis sont les suivantes :
Claude-dev est contraint par défaut à travailler dans le répertoire courant du projet ouvert dans VSCode, une règle explicite est mentionnée pour indiquer que l’on ne peut pas changer de répertoire : on évite ainsi des drames de modifier des fichiers à des endroits inappropriés…
L’agent doit bien penser à prendre en compte les informations d’OS avant de répondre aux questions
On lui donne aussi des guidelines spécifiques aux outils qu’il a à disposition pour bien les utiliser. Si vous êtes curieux, vous pouvez aller les lire ici.
On le guide également pour ne pas s’engager dans des conversations infinies, et de ne pas être trop littéraire dans ses réponses : on le veut “straight to the point”.
Les objectifs fixés par le prompt sont de résoudre chaque tâche à réaliser de façon itérative, en les divisant en étapes claires à exécuter.
Les quelques lignes de cette section sont une sorte de mémo du type “priorise les tâches que tu vas résoudre de façon séquentielle”, “n’oublie pas que tu peux utiliser des outils pour résoudre tes problèmes”, et “quand tu termines la tâche qui t’as été donnée, utilise l’outil attempt_completion”.
Un aspect intéressant de ce prompt est qu’il indique au LLM que toute analyse devrait être effectuée dans des balises
<thinking></thinking>.On lui conseille aussi de faire attention à la structure de fichiers donnée contenue entre les balises
<environment_details></environment_details>. Ce contexte contient la liste des chemins de fichiers du répertoire courant, mais également :- Tous les chemins des fichiers ouverts dans VSCode
- Les dernières commandes exécutées des shells en cours d’exécution
- Les diagnostics d’analyse de code : une sorte de rapport des erreurs de langage (erreur de syntaxe, type hints, etc.), de rapports de linters et d’autres outils. Ce diagnostic est complètement géré par l’intégration à VSCode. Dès lors, j’imagine alors que plus vous avez installé d’extensions pour contrôler la qualité de votre code, plus ce rapport sera verbeux (à confirmer)
- Ces détails d’environnement sont disponibles depuis la version 1.7 de Claude-dev. Auparavant, ceux-ci étaient contenus dans les balises
<potentially_relevant_details> </potentially_relevant_details>.
Chose intéressante également, lorsque l’agent désire exécuter un outil mais qu’il n’a pas tous les paramètres à disposition, on lui indique qu’il devrait utiliser l’outil
ask_followup_questionafin d’obtenir plus d’informations de la part de l’utilisateur et de pouvoir compléter l’entrée de l’outil initial.
Enfin, les informations systèmes composant la dernière partie du prompt système sont au nombre de 4 :
- Le nom du système d’exploitation utilisé
- Le shell par défaut
- Le Home directory
- Le répertoire courant
Ainsi, les commandes que Claude-dev vous recommandera seront adaptées non seulement à votre OS, mais également à votre shell - ce qui augmente les chances de tomber juste.
Prompt User
Le prompt User est un mécanisme permettant de configurer Claude-dev de façon globale : défini une fois dans VSCode, ce prompt sera présent dans tous les projets pour lesquels vous utiliserez l’extension.
Ce prompt permet de définir des guidelines supplémentaires (comme par exemple d’ajouter des tests à chaque morceau de code écrit), et il est intéressant de noter que ce prompt a la précédence sur le prompt système !
De ce fait, vous pouvez patcher le prompt système avec des instructions bien choisies si vous le désirez. Mais faites attention tout de même : lorsque l’on demande une chose et son contraire, des choses surprenantes peuvent arriver.
Conversation history
L’historique de conversation est une partie dynamique de la mémoire de Claude-dev.
Elle est mise-à jour avec :
- Les messages rédigés par l’utilisateur (lors du démarrage de la tâche ou lorsque l’utilisateur demande à Claude-dev de faire différemment une action proposée)
- Les réponses du LLM suite à une requête API
- Le résultat d’exécution des outils utilisés suivant les recommandations provenant du LLM
Liste des outils
L’agent Claude-dev dispose actuellement de 9 outils différents, chacun dédié à un but très spécifique :

Pour éviter l’effet liste de courses en présentant cette boîte à outils, tentons d’éclairer l’exemple donné au tout début de ce chapitre à la lumière de ces utilitaires. On utilise en particulier les outils:
execute_commandpour installer la librairiediagramswrite_to_filepour écrire le programme python vouluexecute_commandpour exécuter python sur le script afin de créer le diagrammelist_filespour identifier le fichier correspondant à l’image généréeinspect_sitepour inspecter l’image et déterminer si elle est conforme: l’outil utilise l’uri de celle-ci (file:///<chemin_vers_l_image.png>) pour que celle-ci s’affiche dans le navigateur; ils en profitent même pour prendre un screenshot… malin !attempt_completionpour valider avec l’utilisateur que la tâche est résolue
On remarque que les outils sont divisés en plusieurs groupes :
- Ceux permettant de la prise d’information (
read_file,inspect_site,list_files,list_code_definition_names,ask_followup_question) - Ceux permettant d’exécuter des actions (
execute_command,write_to_file) - Ceux permettant d’influencer le “control flow” de l’agent (
attempt_completion)
On remarque une marge d’amélioration notable sur la quantité d’outils disponibles. Dans des cas professionnels, on apprécierait ajouter des connecteurs à des bases de données, des utilitaires pour effectuer des recherches internet, des appels APIs bref :
Tout cela nous indique que Claude-dev n’est aujourd’hui qu’à une fraction du potentiel qu’il pourrait atteindre.
Quelques détails notables
Gestion des erreurs
Les outils utilisés par l’agent au cours de la résolution de sa tâche peuvent rencontrer des problèmes lors de leur exécution. Par exemple, si Claude-dev tente d’exécuter une commande python mais que les packages ne sont pas installés, il y aura de facto une erreur.
Ces erreurs ne sont pas dramatique pour le fonctionnement de l’agent, puisqu’elles sont immédiatement ajoutées à l’historique de conversation (à l’étape 6 du flux d’exécution simplifié) :
Lors de l’itération suivante (étape 2), Claude-dev effectuera un appel API mentionnant donc l’erreur, ce qui lui permettra d’envisager une solution pour la résoudre : dans le cas présent, il proposera vraisemblablement d’installer les paquets manquants.
Ce comportement est sympathique puisqu’il vous évite la pénible tâche de devoir débugger par vous-même.
En revanche, cela mène à devoir aborder un point sensible :
- Que se passe-t-il si la tâche est simplement trop complexe pour l’agent ?
- Si l’agent effectue erreur sur erreur sans avancer, Claude-dev va-t-il continuer indéfiniment à faire des appels API jusqu’à ce que l’intégralité de votre compte bancaire soit siphonné ?
La réponse se situe dans le code, puisque pour éviter de condamner votre chère carte bleue, Claude-dev met en place un compteur d’erreurs : au bout de 3 erreurs consécutives, Claude-dev jette l’éponge et arrête ce qu’il fait.
Ce compteur est réinitialisé lorsqu’un outil s’exécute avec succès: on peut ainsi avoir deux erreurs, puis un succès, puis une erreur, l’agent continuera de résoudre la tâche donnée.
Gestion de la mémoire
Il n’est pas sans savoir que les LLMs ont une fenêtre de contexte (context window) limitée. En d’autres termes, ils ne peuvent traiter qu’une quantité limitée de texte à la fois.
Avec une fenêtre de contexte de 100 tokens (= morceau de mot) par exemple, le LLM peut utiliser au maximum 100 tokens (soit un peu plus de 100 caractères) pour effectuer une prédiction. Quant à lui, Claude 3.5 Sonnet (qui a été utilisé dans le cadre de cet article) dispose d’une context window de 200K tokens.
Cela peut sembler beaucoup, mais pour un simple fichier de 100 lignes de code dans lequel on écrirait sur chaque ligne print(“hello, world”), on aurait déjà 2100 caractères (et environ à moitié moins de tokens, en fonction du tokenizer utilisé).
Vous vous en doutez, il va rapidement falloir trouver une solution pour quand Claude-dev aura rempli sa mémoire, autrement il sera incapable de continuer son boulot.
La solution choisie lorsque le prompt devient trop grand par rapport à la fenêtre de contexte est de tronquer la mémoire en éliminant la première moitié de celle-ci : on se dit que les informations les plus importantes sont celles les plus récentes.
Manque de bol, c’est dans les tout premiers messages (et en particulier LE premier) que l’on indique la tâche à réaliser !
Comme les devs ont été malins, ce nettoyage de mémoire épargne le premier message de l’historique de conversation; ainsi l’agent se souvient de la raison pour laquelle on a fait appel à lui (sans quoi, il sera bien malin pour savoir quand il aura terminé son job).
On en déduit une chose : il faut être exhaustif le plus possible dans le premier message et ne pas hésiter à tartiner de détails si on pense avoir besoin de Claude-dev pour un petit moment.
Une solution alternative à ce qui a été choisi pour nettoyer la mémoire aurait été de résumer les échanges les plus anciens plutôt que de les supprimer: ainsi, on compresse l’information passée plutôt que de la perdre.
Analyse financière
Pour déterminer la vitesse à laquelle nos poches se vident en utilisant Claude-dev, nous en avons collecté les logs d’utilisation du LLM et l’usage général de l’API sur Anthropic.
Par l’analyse des logs, nous avons déterminé qu’il y avait environ 12000 tokens échangés par requête, sur une moyenne de 68 appels API.
Dans une utilisation naïve du LLM, le coût engendré par chaque appel API serait de l’ordre de 5 centimes de dollar.

Coût hypothétique d’une requête envoyée à Claude 3.5 Sonnet par Claude-dev
Mais comme la vie est bien faite, Anthropic propose une fonctionnalité réduisant de façon drastique les coûts d’usage de ses LLMs : le prompt caching. Sans en expliquer les détails, dites-vous que cette technique est une façon de réutiliser les prompts que l’on a envoyés précédemment au LLM pour éviter d’avoir à les renvoyer chaque fois : le LLM répond donc plus rapidement, et nous coûte moins cher.
Comme dirait l’autre, les calculs sont pas bons ; nous devons alors prendre en compte les tokens écrits et lus dans le cache afin d’affiner notre compréhension du pricing; en analysant le rapport fourni par Anthropic, on se rend compte de deux éléments :
- Anthropic décompte deux fois moins de tokens par requête que ce que les logs détaillés laissent paraître : on a donc environ 6K tokens par requête.
- La quasi-totalité des données en entrée du LLM sont écrites et lues dans le cache. Les coûts sont effectivement grandement réduits.
Ils s’expliquent par la manière dont le cache fonctionne : quand on y écrit un prompt, on ne l’écrit pas véritablement en un seul bloc, mais par des sections qu’on délimite par des breakpoints.
Ainsi, nous n’avons pas besoin de réécrire dans le cache les sections que nous y avons placées précédemment et nous avons seulement à y stocker les nouvelles : on écrit peut dans le cache, mais on y lit beaucoup !
Par cette fonctionnalité, le coût réel d’utilisation de Claude-dev se situe autour d’un centime de dollar par requête.

Coût réel d’une requête, optimisé par prompt caching
En bref
Après avoir rappelé l’historique de la GenAI en quelques lignes, nous avons abordé le cas de l’agent Claude-dev. Cet assistant de code open-source vous accompagnera dans vos projets développés sous Visual Studio Code pour vous aider à faire votre boulot plus rapidement.
Nous avons pu voir que cet agent se repose sur des outils rudimentaires mais qui, couplés à un solide prompt engineering, un LLM à l’état de l’art, et un code bien pensé, donne des résultats assez impressionnants.
Nous avons également analysé comment le couplage de Claude-dev à l’IDE pouvait lui rendre service: ce faisant, il bénéficie de fonctionnalités pour diagnostiquer les projets sur lesquels il intervient, et d’en récupérer des éléments de contexte pouvant l’aider à résoudre ses missions.
Enfin, nous nous sommes rassurés sur la question financière : si d’apparence, faire appel à un fournisseur de LLM payant nous effrayait, nous avons réalisé que l’utilisation du LLM Claude 3.5 Sonnet demeure abordable - même si les plus fauchés d’entre nous y trouveront à redire.
Pour aller plus loin, vous pouvez aller lire la documentation du projet sur Github et pour les plus téméraires, il est bienvenu d’en lire le code source. Ces derniers y apprendront par exemple que le flux d’exécution présenté plus haut est codé de façon récursive, ce qui pourrait leur donner des idées d’implémentation pour leurs propres agents !