Créer une web-app interactive en 10min avec Streamlit
Dans un projet de Machine Learning, il y a souvent besoin de visualiser les données sous forme de graphes, que ce soit lors d’une phase exploratoire ou pour montrer les résultats d’une modélisation. Force est de constater qu’intégrer ces graphes à une web-app n’est pas forcément aisé, puisque les outils existants nécessitent pour la plupart quelques connaissances front-end, Dash par exemple. Et si nous pouvions faire tout ceci en Python, en 10 minutes ? C’est ce que nous allons voir avec Streamlit, une nouvelle librairie pour créer des wep-apps de Machine Learning.
Streamlit, dont le post de lancement a été diffusé à la mi-octobre 2019, a pour vocation la création de web-apps de Machine Learning. Sur le papier, l’accent est mis sur la simplicité d’utilisation : une API facile à appréhender, des changements pris en compte immédiatement et automatiquement, une visualisation live de ce qui est produit, et une compatibilité avec la plupart des frameworks de dataviz Python.
Alors, Streamlit, esquif ou cuirassé ? C’est ce que nous allons voir par la pratique. La web-app que nous allons créer est interactive, raison pour laquelle je vous invite à jouer avec. Deux façons sont possibles :
En remote
J’ai partagé le code de la web-app que nous allons créer sur Gist, ce qui vous permet de le lancer sur vos machines. Pour cela, il faut d’abord installer Streamlit, sur une version de Python >= 3.6 :
<br><br>pip install streamlit<br>
Puis, lancer Streamlit en pointant vers le code sur Gist :
<br><br>streamlit run https://gist.githubusercontent.com/AurelienMassiot/b3070dab9e31dd119242648b4d27c9b4/raw/53e63271591bbfac6e35df30dacc05de941a63df/dashboard.py <br>
En local
Le code est également sur Github si vous voulez reproduire en local.
Note pour la suite : les agrégats effectués pour les graphes ne seront pas décrits dans cet article car ce n’est pas ce qui nous intéresse ici.
1 - Streamlit, pour une exploration de données facilitée
A titre d’exemple, j’ai choisi le dataset Bike Sharing demand, qui décrit le nombre de vélos loués par heure dans une ville, avec à chaque pas de temps des données météorologiques.
Pour charger les données, on fait du classique Pandas. Streamlit va nous permettre d’afficher le DataFrame proprement formaté en… une ligne de code avec st.write(df) :
<br>from pathlib import Path<br>import pandas as pd<br>import streamlit as st<br><br>@st.cache<br>def load_data():<br> bikes_data_path = Path() / 'data/bike_sharing_demand_train.csv'<br> data = pd.read_csv(bikes_data_path)<br> return data<br><br>df = load_data()<br>st.write(df)<br>
Si on lance Streamlit depuis un terminal :
<br><br>streamlit run src/dashboard.py<br>
On obtient, à l’adresse localhost:8501, une belle page avec notre DataFrame scrollable :
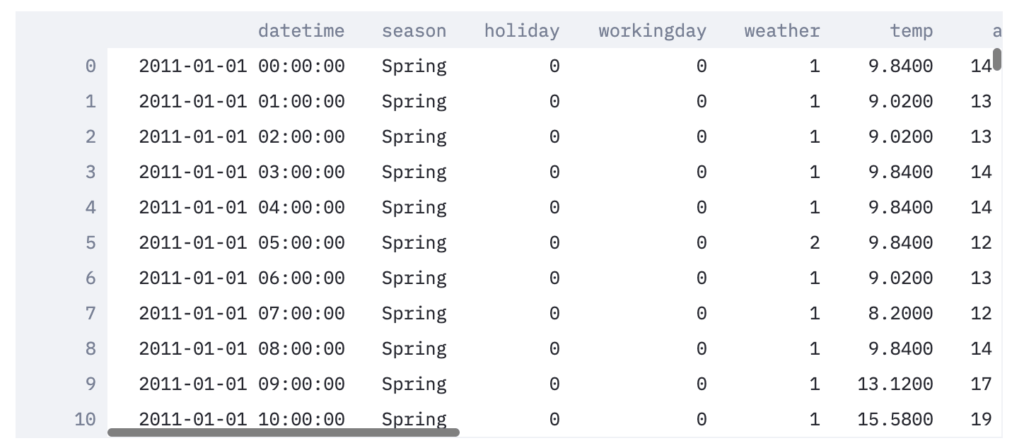
DataFrame avec Streamlit.
Deux concepts sont importants :
- le décorateur @st.cache permet de garder en cache les données chargées, même quand l’application, donc le code, est mise à jour. Il est décrit plus précisément dans la documentation. Il permet une grande rapidité d’affichage !
- la méthode st.write() est le couteau-suisse de Streamlit ; elle va afficher l’objet qui lui est passé de façon automagique, en inférant automatiquement si l’objet est du texte, une figure Matplotlib, une figure Plotly, etc.
Maintenant que nous avons notre DataFrame, nous allons afficher un premier graphe. Pour cela, je fais le choix d’utiliser Plotly Express, qui permet de créer des graphes et dont l’API est construite au dessus de Plotly. J’aurais très bien pu utiliser Matplotlib, Bokeh, Seaborn, etc. car Streamlit est agnostique de la librairie de dataviz utilisée. Mais Plotly Express permet entre autres de pouvoir interagir avec les graphes.
Ici, un pré-traitement des données est fait pour calculer l’heure depuis une date. Ce n’est pas le sujet ici, raison pour laquelle je ne décris pas la fonction, mais tout est disponible sur Github. Ensuite, un graphe Plotly Express est créé.
<br><br>import plotly_express as px<br>df_preprocessed = preprocess_data(df.copy())<br>mean_counts_by_hour = pd.DataFrame(df_preprocessed.groupby(['hour', 'season'], sort=True)['count'].mean()).reset_index()<br>fig1 = px.bar(mean_counts_by_hour, x='hour', y='count', color='season', height=400)<br>barplot_chart = st.write(fig1)<br>
Streamlit s’aperçoit de la modification du code source et va mettre à jour la wep-app, en ajoutant le graphe et sans re-charger les données, grâce au décorateur st.cache décrit précédemment :
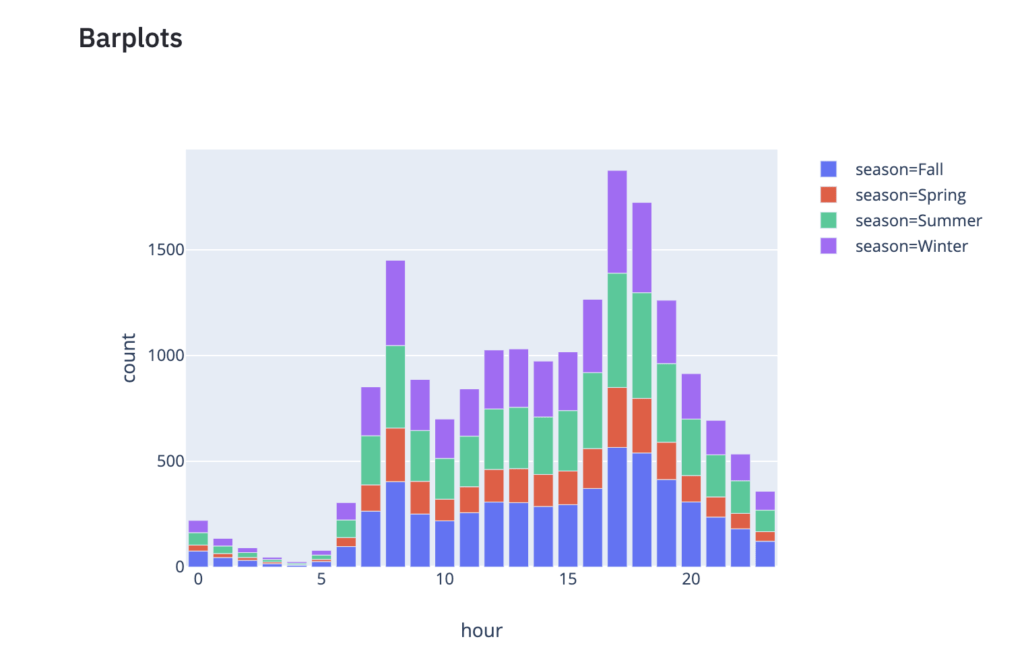
Barplots avec Streamlit et Plotly Express.
On peut se déplacer, zoomer, afficher les valeurs, enregistrer le graphe, car ces fonctionnalités sont inhérentes à Plotly Express et restent intégrées dans une wep-app Streamlit.
Et ajouter d’autres graphes est immédiat ! Voici une série temporelle :
<br><br>df_preprocessed['datetime'] = pd.to_datetime(df_preprocessed['datetime'])<br>fig2 = px.line(df_preprocessed, x='datetime', y='temp')<br>ts_chart = st.plotly_chart(fig2)<br>
On notera d’ailleurs que plutôt qu’utiliser la fonction automagique st.write(), on peut directement spécifier st.plotly_chart() puisque l’on sait ce que l’on manipule.
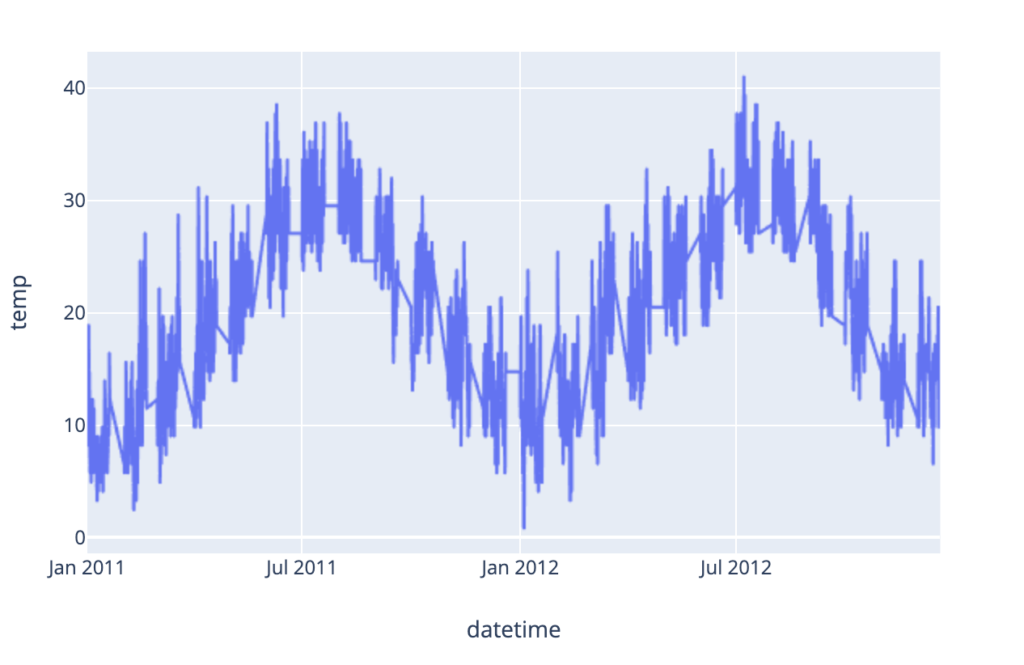
TimeSeries avec Streamlit et Plotly Express.
Et, comme décrit dans la documentation, on peut en une ligne créer un bouton dropdown avec st.selectbox(), ce qui permet notamment de choisir les données à afficher :
<br><br>categories_count = ['casual', 'registered', 'count']<br>chosen_count = st.sidebar.selectbox(<br> 'Which counts for boxplots?',<br> categories_count<br>)<br>fig3 = px.box(df_preprocessed, x='weekday', y=chosen_count, color='season', notched=True)<br>boxplot_chart = st.plotly_chart(fig3)<br>
Le mot clé sidebar permet simplement d’ajouter le bouton dropdown sur le côté plutôt qu’au milieu.
En choisissant une option du bouton, les boxplots vont immédiatement être mis à jour.
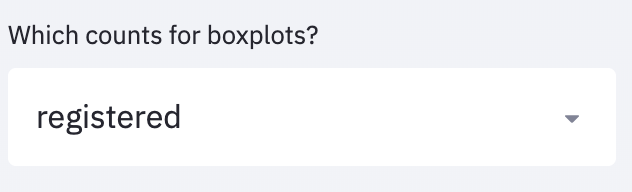
Dropdown avec Streamlit.
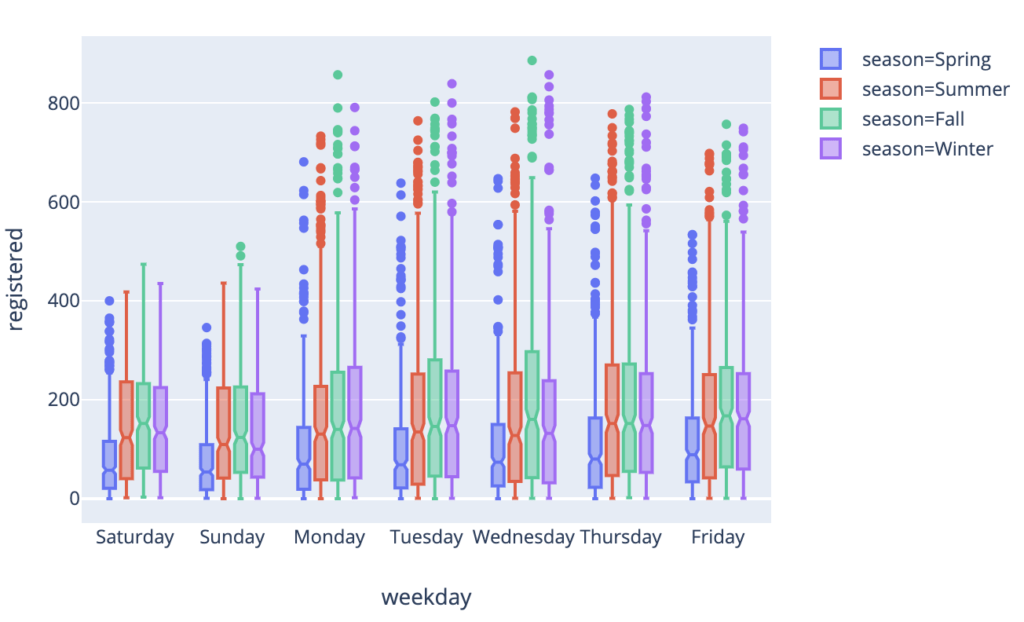
Boxplots avec Streamlit et Plotly Express.
Et il en va de même pour créer d’autres boutons, des sliders par exemple ! A chaque fois, c’est une ligne pour créer l’objet, récupérer sa valeur et l’afficher. Sobre et Efficace.
2 - Streamlit, pour rendre concret le Machine Learning
Admettons maintenant que nous voulions entraîner un modèle de Machine Learning, lui faire prédire de nouvelles valeurs et les afficher. Nous allons ici utiliser comme features, la température et l’humidité, pour prédire le nombre total de vélos loués :
<br><br>from sklearn.ensemble import RandomForestRegressor<br>X = df_preprocessed[['temp', 'humidity']]<br>y = df_preprocessed['count']<br>model_rf = RandomForestRegressor(max_depth=2, n_estimators=10)<br>model_rf.fit(X, y)<br>
On va maintenant simuler du temps réel, en envoyant toutes les 0,1 secondes deux nouvelles valeurs de température et d’humidité. Ces valeurs seront utilisées par notre modèle pour prédire le nombre de vélos loués, et ces valeurs prédites seront affichées sur notre graphe rafraîchi en temps réel.
<br><br>n_rows_to_display = 50<br>df_for_predictions = df_preprocessed.copy()<br>df_for_predictions['predicted'] = False<br>fig = px.line(df_for_predictions.tail(n_rows_to_display), x='datetime', y='count', color='predicted')<br>online_ts_chart = st.plotly_chart(fig)<br>new_row_info = st.empty()<br>predicted_row_warning = st.empty()<br>
Ci-dessus, on initialise un graphe avec en affichant les n_rows_to_display, qui correspondent aux 50 dernières lignes de notre DataFrame. On ajoute également une colonne predicted au DataFrame, car cela nous permettra par la suite de distinguer les valeurs historiques et les valeurs prédites. Enfin, on initialise deux objets new_row_info et predicted_row_warning, qui nous permettront d’afficher les valeurs de température et d’humidité reçues, et la prédiction faite par le modèle.
On va ensuite écrire le code permettant de “streamer” les données :
<br><br>if st.sidebar.checkbox('Stream and predict on new data'):<br> bar = st.progress(0)<br> for i in range(11):<br> # get new row<br> new_row = generate_new_row(df_for_predictions)<br> new_row_info.info(f'Received new values: \n'<br> f'temperature={np.round(new_row["temp"].values[0], 2)} - \n'<br> f'humidity={np.round(new_row["humidity"].values[0], 2)} \n')<br> # predict<br> new_prediction = generate_new_prediction(df_for_predictions, new_row, model_rf)<br> predicted_row_warning.warning(f'Predicted count: {np.round(new_prediction["count"].values[0], 2)}')<br> # concatenate predicted row<br> df_for_predictions = add_row(df_for_predictions, new_prediction)<br> # animate<br> animate(df_for_predictions.tail(n_rows_to_display), 'count', online_ts_chart)<br> bar.progress(i * 10)<br> # wait<br> sleep(0.1)<br>
Ce code peut paraître abrupt au premier abord, mais analysons-le de proche en proche.
- On fait apparaître un bouton checkbox, qui, une fois coché, lancera l’animation. On crée également une barre de progression.
- A chaque itération, on génère une nouvelle ligne qui contient un nouveau Timestamp, une valeur de température aléatoire et une valeur d’humidité aléatoire. Le dataset Bike Sharing Demand ayant des valeurs temporelles par heure, les timestamps sont aussi générés par heure et dans le bon ordre. Les valeurs température et d’humidité sont affichées.
- A partir de ces valeurs de température et d’humidité, on en infère la valeur de nombre total de vélos loués à cette heure grâce au modèle. Cette valeur est affichée.
- On concatène la valeur prédite et son timestamp, au DataFrame.
- On met à jour le graphe avec les 50 dernières lignes.
- On anime la barre de progression et on attend 0.1s.
Voici donc notre graphe pseudo temps réel :
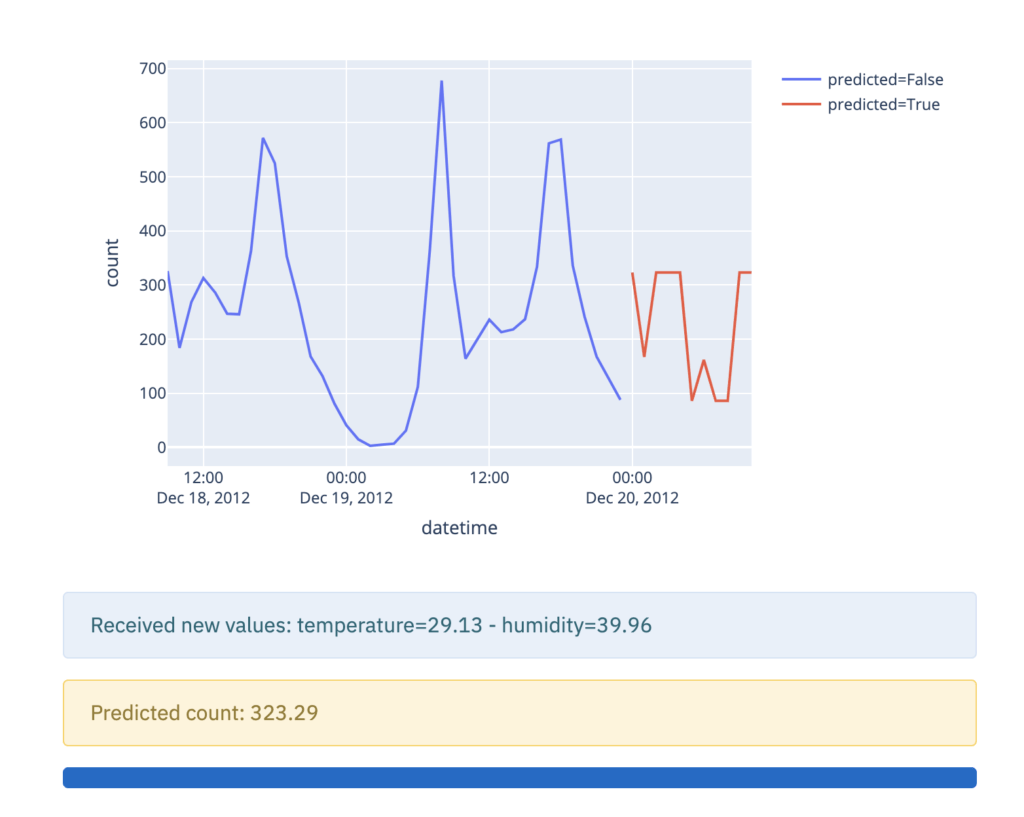
Streaming des données avec Streamlit et Plotly Express.
Notre graphe pseudo temps réel s’actualise bien et sans ramer. Sachant que tout ceci a été créé en peu de lignes de code et ne nécessite que peu d’ajout par rapport à un code classique de Machine Learning.
Conclusion
Finalement, Streamlit tient ses promesses. Pour ce qui est de la simplicité, aucun doute là-dessus, l’API est utilisable sans anicroche : on a simplement besoin de copier-coller ses graphes dans un script et de lancer Streamlit.
La compatibilité avec presque tous les frameworks de dataviz de Python est incontestablement un gros plus. On peut ainsi choisir les frameworks que l’on préfère, compenser les forces et les faiblesses de chacun. J’ai noté un seul défaut : les graphes de SHAP, permettant d’expliquer les outputs d’un modèle, ne sont pas intégrables pour le moment.
Les données en cache et par conséquent le rafraîchissement immédiat de la web-app, impliquent une boucle de feedback très courte lorsque l’on code. Cela permet donc d’arriver vite à ce que l’on voulait faire.
Que ce soit en phase exploratoire sur un jeu de données ou pour montrer les résultats d’une modélisation, par exemple à un métier afin de vérifier la pertinence de celle-ci ou lui donner une vision plus concrète du Machine Learning. Il est important de mettre une interface rapidement entre les mains de l'utilisateur, pour vérifier qu'il peut concrètement se servir de l'insight (visualisation, prédiction, etc.) que nous lui transmettons - et vérifier que le système de Data Science créé ne résout pas un problème inexistant ou avec lequel les utilisateurs ne peuvent rien faire ! A cet égard je conseille Streamlit sans problème. C’est d’autant plus vrai qu’il est aisé de déployer la web-app créée sur le cloud.
Pour de la production, le framework pourrait s’avérer également intéressant, grâce encore une fois au système de caching et de DAG intelligent. Il faudra observer à quel point l’outil est résilient lorsqu’il tourne en continu, mais pour cela on attendra d’avoir un peu plus de recul. A voir comment Streamlit évoluera dans le futur ; va-t-il se concentrer uniquement sur ce qu’il fait déjà bien, le dashboarding, ou aussi ajouter des fonctionnalités avancées, comme le recueil du feedback utilisateur sur les prédictions d’un modèle ? Enfin, n’oublions pas que la conception d’interfaces est un métier en soi.
Références
- https://towardsdatascience.com/plotly-express-the-good-the-bad-and-the-ugly-dc941649687c
- https://medium.com/plotly/introducing-plotly-express-808df010143d
- https://towardsdatascience.com/coding-ml-tools-like-you-code-ml-models-ddba3357eace
- https://towardsdatascience.com/how-to-write-web-apps-using-simple-python-for-data-scientists-a227a1a01582
- https://streamlit.io/
- https://www.kaggle.com/c/bike-sharing-demand