CR Grosse conf 2025 - Talk de YDR - Prototyper l’innovation : framework et plateforme pour accélérer la GenAI
Prototyper l’innovation : framework et plateforme pour accélérer la GenAI
Aujourd’hui, l'introduction de l'intelligence artificielle générative (GenAI) au sein des entreprises est considérée comme un défi majeur. Alors, comment peut-on prototyper cette innovation de manière efficace et accélérer son adoption ?
Yannick Drant, un data architect, AI architect et formateur à Octo Technology, ayant plus de 20 ans d’expérience et avec sa passion pour l’innovation a relevé ce défi lors de sa dernière intervention à la Grosse Conf .

Depuis son émergence en 2022, l'IA générative a inauguré une nouvelle ère, celle où "tout semble possible", comme le dit si bien Yannick Drant. Cette ère est peuplée d'outils IA clés en main, tels que Copilot, qui promettent de révolutionner notre manière de travailler. Cependant, malgré leur potentiel, ces outils n'ont pas toujours tenu leurs promesses, laissant rapidement une place à la déception des utilisateurs.
Yannick, avec sa passion pour l'innovation, a exploré des méthodes innovantes pour aller au-delà des solutions existantes et maximiser l'impact de la GenAI. Il a ainsi développé et prototypé un framework d'accélération des expérimentations, ouvrant la voie à une utilisation plus efficace et transformative de l'IA générative.
“ L'innovation commence par une question : par où débuter ?” Pour Yannick, la réponse réside dans la création d'une communauté centrale d'experts et de professionnels des métiers. Plutôt que de lancer des initiatives isolées. Cette approche permettrait le partage des connaissances et la collaboration. En brisant les silos entre les différentes entités, cette communauté permet de challenger les besoins, en se concentrant sur des cas d'usage à forte valeur ajoutée, elle maximise l'impact de l'IA générative au sein des entreprises.
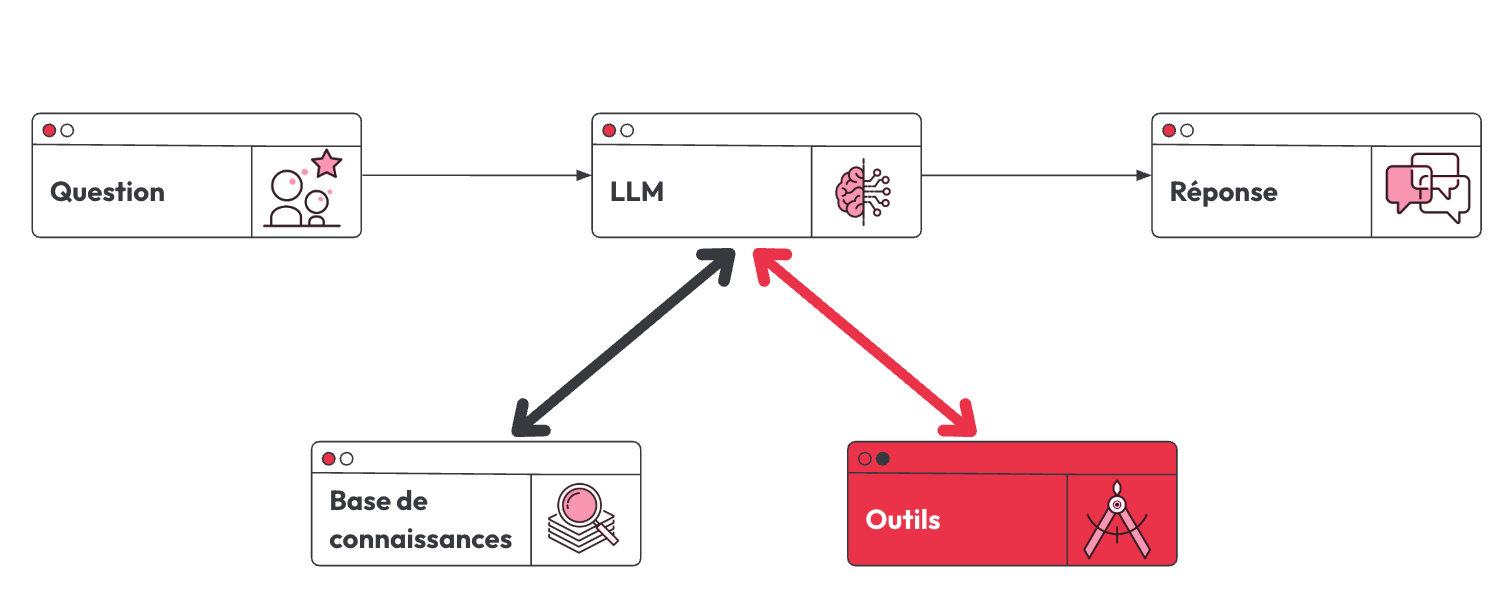
Pour intégrer la connaissance de l'entreprise avec de l'IA générative, Yannick, partage son approche utilisée lors de sa dernière expérience. Cette approche se traduit par ce flux: lorsqu’une question se pose, on s’appuie sur une base documentaire, crée un prompt, et l'envoie au modèle de langage (LLM) pour générer une réponse. Ce pattern est appliqué à tous les cas similaires au sein de l'entreprise, permettant de traiter efficacement les besoins en information.
L’approche qui a été utilisée est une approche appelée laboratoire, un espace où les data scientists et les professionnels peuvent se retrouver pour expérimenter et développer des solutions.“La création de plusieurs laboratoires est cruciale pour prendre des décisions éclairées,” souligne Yannick. Ce cadre isolé favorise l'intégration de nouvelles technologies et la collaboration au sein de l’équipe. Chaque expérimentation dispose donc d'un espace dédié, permettant de tester des idées et des technologies. Une fois validées, ces expérimentations peuvent être transformées en MVP ou intégrées dans la fondation technologique de l'entreprise, rendant les nouvelles solutions disponibles pour d'autres expérimentations. Cette méthode va donc faciliter la prise de décision rapide et l'adaptation aux nouveautés évolutives de l'IA générative.
La plateforme d’expérimentation
Yannick a déroulé le panorama de ce qu’il a pu construire avec ses équipes comme plateforme d’accélération d’expérimentations en un an et demi. L’idée qu’il présente est que plus il y a de technologies et de codes à partager, plus le temps d’expérimentation est réduit.
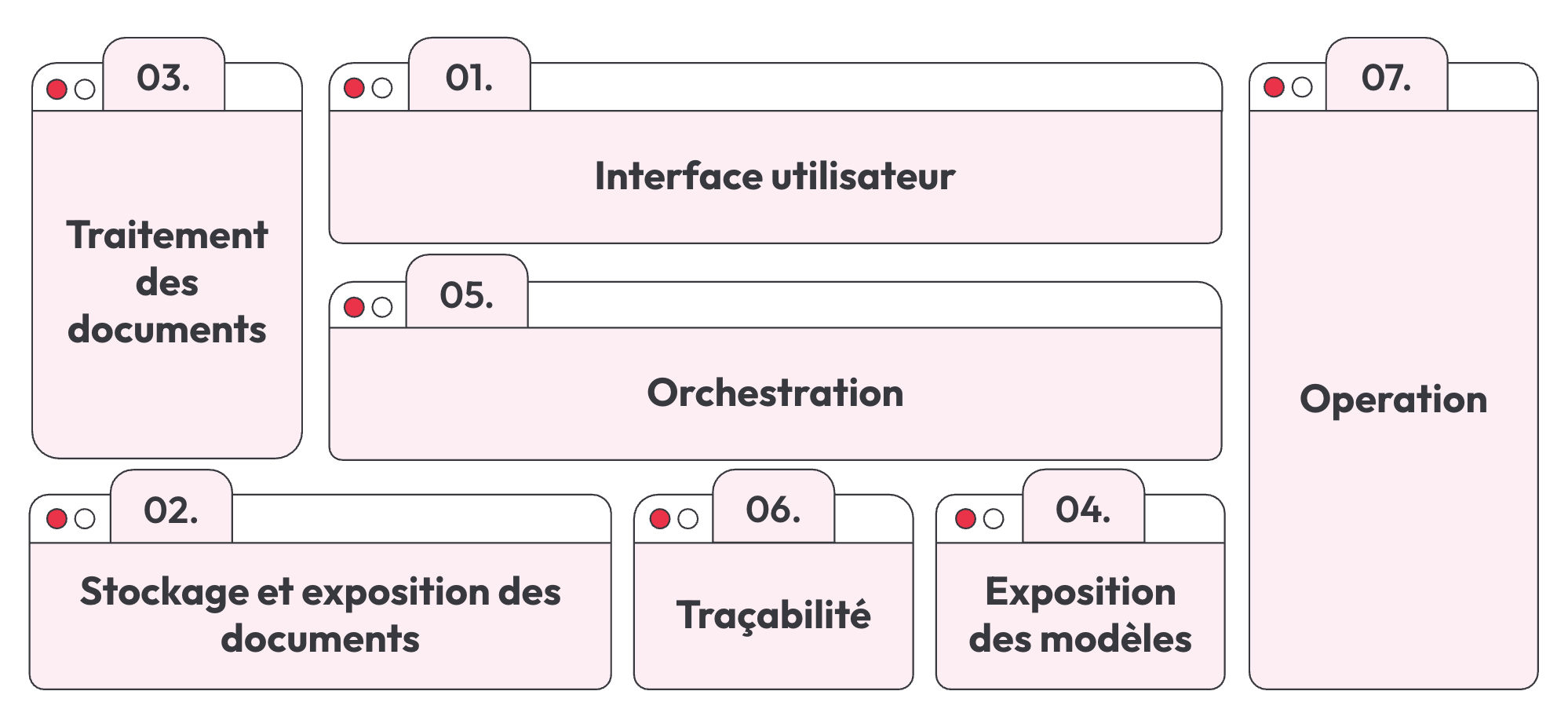
Cette plateforme se divise en 7 parties:
- Interface utilisateur
- Stockage et exposition des documents
- Traitement des documents
- Exposition des modèles
- Orchestration
- Traçabilité
- Opération
1- Interface utilisateur
Une standardisation de l’interface utilisateur a été faite pour toutes les expérimentations. Cette interface a été développée en utilisant Streamlit “un framework open-source en Python qui permet de créer facilement des applications web interactives pour la visualisation de données avec seulement quelques lignes de code”. L'accent doit être mis donc sur la qualité de l’interaction avec les utilisateurs, en s'assurant qu'elles soient intuitives et fluides. Il est également crucial de recueillir activement les retours des utilisateurs afin d'identifier les points d'amélioration des modèles et d'adapter l'interface à leurs besoins.
1- Stockage et exposition des documents
Il s’agit de l’exposition des connaissances de l’entreprise. D’une manière générale, trois topologies se présentent:
- Sémantique: c’est l’utilisation des bases de vecteurs pour rechercher des documents à travers la similarité du sens
- Full Text: c’est une recherche basée sur l'occurrence de mots, efficace plutôt pour des catalogues de produits avec des noms spécifiques.
- Graphe: il s’agit de l’établissement de relations entre différents paragraphes, par exemple un concept et son illustration.
Cette plateforme a été établie plus sur les parties sémantiques et full text, l’indique Yannick. Une autre notion a aussi permis de gagner en pertinence, c’est la notion de Re-ranking.
Le Re-ranking permet de trier et de mettre en avant les documents les plus pertinents parmi une grande liste de résultats de recherche. Après une première requête, une deuxième passe est effectuée pour valider la pertinence des documents, ce qui améliore la qualité des résultats malgré un léger allongement du temps de traitement. Cette approche permet également de requêter plusieurs bases de connaissances simultanément et de faire le re-ranking par la suite. En combinant une base de données sémantique et une base de données full text on peut très bien sélectionner les meilleurs documents. Cette technologie est “un vrai game changer” le cite Yannick.
2- Traitement de la base documentaire
Désormais, la question à poser et à laquelle va répondre Yannick est comment traite-t-on tous nos documents à travers ces bases de données.
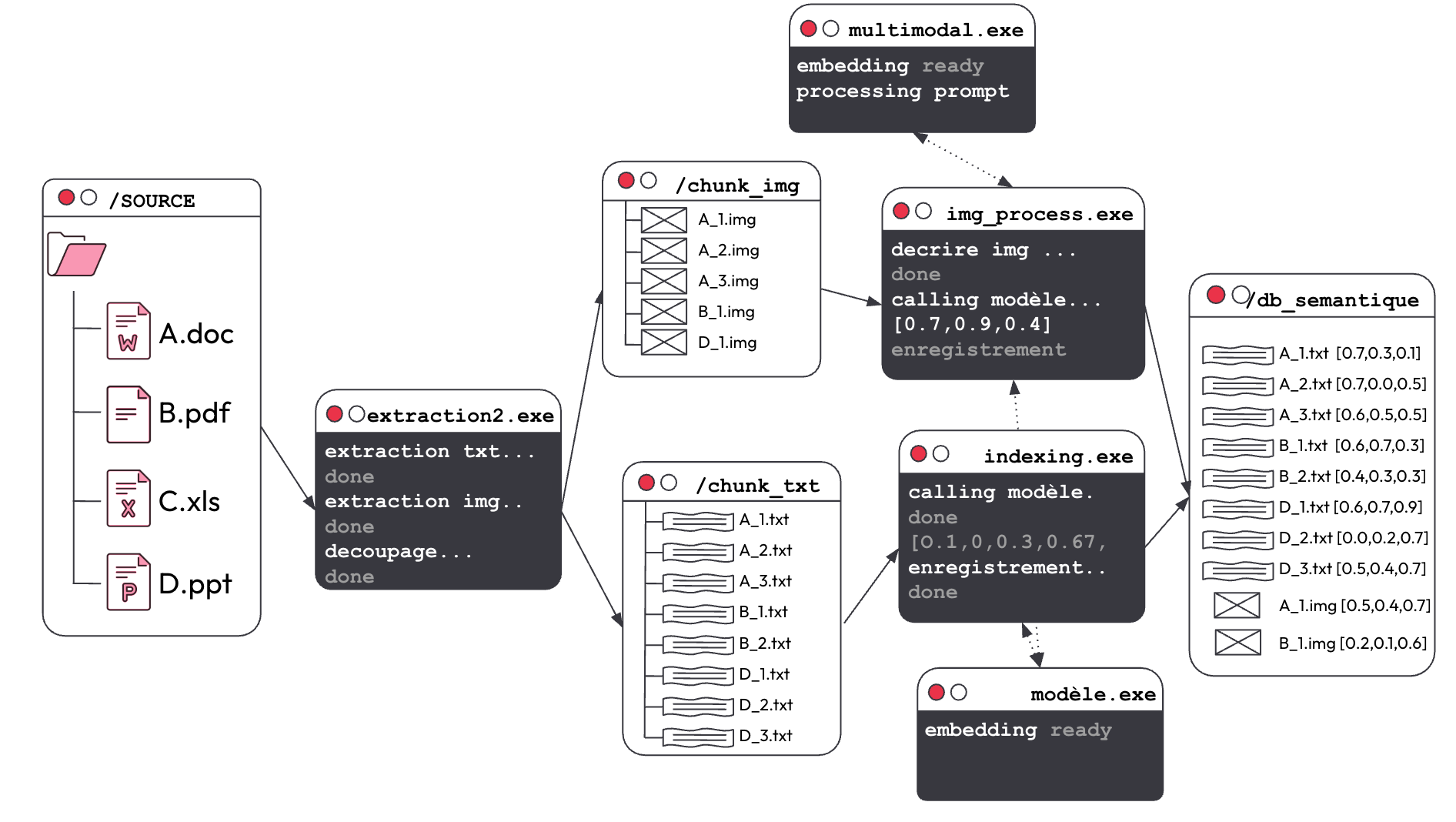
Dans une base de données sémantique, on dispose de plusieurs types différents de documents: pdf, excel ou powerpoint.
La première étape consiste à l’extraction du texte de ces documents, ce qui va créer ce que l’on appelle des chunks ou des morceaux de documents auxquels on attribue des liens. Ensuite, on crée une représentation vectorielle à partir de ces morceaux ou ce que l’on appelle des embeddings qu’on va ensuite les mettre dans une base de données vectorielle.
Mutualiser les bases de code pour différents cas d'usage va donc permettre de gagner du temps et d'enrichir les processus, car une fois qu'une méthode est développée pour un type de document (Word, PDF, images), elle peut être appliquée à tous les cas similaires, optimisant ainsi les expérimentations et l'intégration des nouvelles technologies.
3- Exposition des modèles au sein de la plateforme
Depuis 2024 environ 20 nouveaux modèles et au moment de l’écriture de cet article d’IA génératives ou de LLM ont été annoncés par des géants comme Google, AWS, Meta, etc.. Cela signifie que l’on a à peu près un modèle à tester chaque jour. L’objectif ici est de rester à la pointe de la technologie tout en mettant ces modèles à disposition pour les différentes expérimentations.
Pour ce faire, on peut commencer par une architecture “point au point” : c'est-à-dire que l’on a une connexion directe entre l’application et le modèle IA en question. Bien que ce type d’architecture permette de gagner en temps en rendant l’application rapidement disponible, elle présente un inconvénient majeur quand on commence à gérer une vingtaine ou trentaine d’applications avec des modèles à commissionner, à ce moment la gestion devient beaucoup plus complexe.
D’où l’on introduit le LLM API manager qui joue le rôle d’une application centrale. Le LLM API manager va donc garantir que toutes les applications utilisent la même version et faciliter la traduction entre les différents modèles. Cela permet également de gérer les accès de manière sécurisée comme chaque application dispose de sa propre clé. Un autre avantage aussi est qu’en cas d’indisponibilité d’une certaine version du modèle ou modèle un modèle de repli pourrait prendre le relais assurant ainsi un fonctionnement fluide des applications.
4- Orchestration
Cette partie a comme objectif de faire interagir la base de stockage, l’entrée utilisateur et les modèles. L’approche Graphe, une nouveauté dans ces cas d’usages, va assurer la qualité des réponses fournies en permettant à l’application de décider quand s’arrêter. Éventuellement, chaque application peut devenir un agent interconnecté. D’où ça nous prépare au “monde de demain” avec la notion des outils, où les modèles de langage (LLM) peuvent structurer leurs réponses selon un schéma défini, ce qui facilite l’interrogation des APIs et des systèmes tiers, préparant ainsi l’intégration future de l’approche graphe.
5- Traçabilité
La traçabilité est cruciale dans ce genre de cas d’usage, car ça va permettre de suivre le bon fonctionnement de toutes les applications et de s’assurer que celles-ci répondent bien au besoin à travers la mise en place des KPIs. Cela permet aussi de créer une sorte de ligne de base pour valider les modèles et les données utilisées pour les entraîner. De plus, cette traçabilité facilite le passage à des modèles plus petits et écologiques et permet de monitorer l’évolution des prompts utilisés par les data scientists et donc d’en garder une trace des différentes versions.
6- Opération
Yannick nous présente trois particularité de la partie opération:
- FinOps: c’est le fait de suivre les coûts de chaque expérimentation. Celle-ci va servir comme pilier d’aide à la décision quant à l’investissement dans ces applications et aussi comme projection sur les coûts futurs.
- Sécurité: une étape assez importante dans ce processus permettant de mettre en place un pattern système pour vérifier les vulnérabilités
- Scalabilité: A partir du moment où on commence à traiter plus d’une vingtaine d’applications, il devient assez important de les gérer d’une manière parallélisée, de pouvoir les démarrer, les arrêter et les déployer efficacement.
7- Stack technique
Comme l’équipe doit disposer des outils nécessaires pour assurer la maintenance et le déploiement des applications. Yannick nous partage sa stack technique : 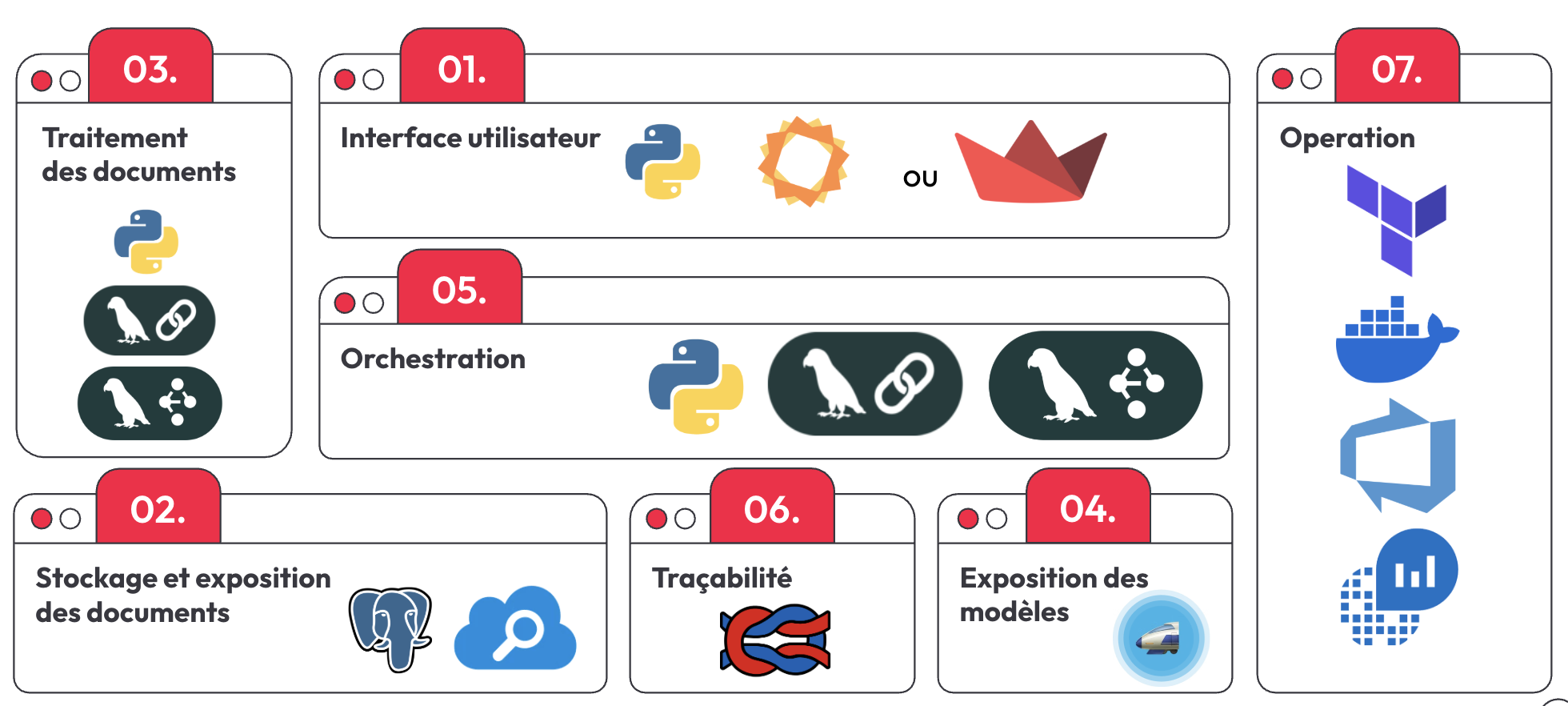
Take Away
En conclusion, Yannick souligne l’importance de la construction d'une telle plateforme centralisée car ça permettra de gagner du temps et d'éviter les initiatives isolées. Yannick nous recommande donc d’utiliser des interfaces utilisateur et de collecter le maximum des retours utilisateurs.
Il attire particulièrement notre attention pour mettre en place une orchestration par graphe et non pas une orchestration étape par étape, de combiner les méthodes full texte et sémantique pour le stockage de documents. Et enfin de bien penser à mettre en place à un point central de communication entre applications et modèles et à la scalabilité des différentes applications mises en place.