CR duckconf 2025 Infra As Code As Code
Lors de la Duck Conf 2025, Sébastien Gahat et Ulysse Fontaine ont renversé le paradigme de l’Infrastructure As Code et réfléchi à une autre manière de penser le déploiement d'applications.
Sebastien Gahat : 80% dev, 20% ops. Arrivé à OCTO en 2019, sur le sujet des applications Cloud native, Serverless, et de l’infra as code moderne, Sébastien a découvert durant cette période les sujets tech qui le passionnent et qu’il essaie de faire grandir à OCTO. Aujourd’hui leader de la tribu des “Artisans de l’Infra as Code”, il cherche continuellement de meilleures façons d’écrire du code d’infrastructure et d’utiliser le Cloud. Il a enchaîné des expériences de Développeur, Devops, SRE, ou Tech Lead, souvent alternant travail sur l’applicatif et sur l’infrastructure. Il est convaincu de l’importance de construire les deux ensemble.
Ulysse Fontaine : 20% dev 80% ops. Arrivé à Octo en 2019 et touche à tout, il utilise une infrastructure maison : Mikrotik, Proxmox, Kubernetes, GitabCI, Bind9, … où il passe le plus clair de son temps libre à POC pleins de projet et techno. Aujourd’hui, il s’intéresse beaucoup à l’architecture logicielle et cloud, coaching devops et développement backend, avec une grande appétence pour le software craftsmanship, la conception de systèmes résilients et sûrs.

L’Infra As Code n’est pas du code
Nous aurait-on menti depuis le début ? Dans l’Infrastructure as Code, ou IaC, ne lit-on pourtant pas “as Code” ?
Afin de déterminer si l’IaC est bien (ou n’est pas) du code, intéressons-nous à la notion de code informatique.
À quoi ressemble en général le code d’infrastructure ?
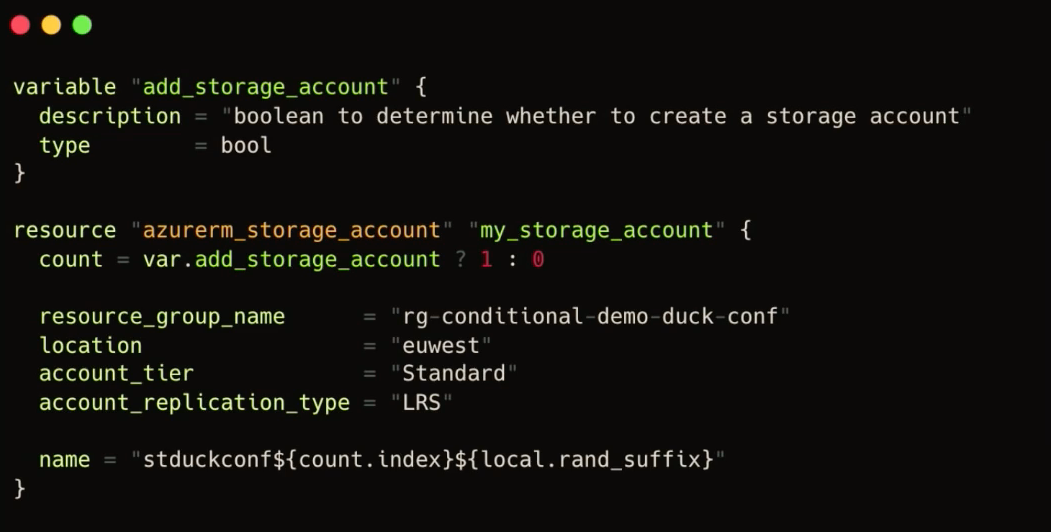
Voici un exemple de code terraform qui permet de déclarer une ressource de type “azure_storage_account” si la variable “add_storage_account” est égale à true.
Pour implémenter cette règle, on utilise ce qui s’appelle une condition ternaire qui en fonction de la variable va demander soit 1 instance soit 0.
Tout cela ne serait pas du code ?
Oui et non. Le code d’infrastructure appartient au monde des DSL.
Domain-Specific Language (DSL), Késako ?
Ce que Martin Fowler nous apprend, c’est qu’un langage dédié (DSL) est un langage de programmation dont les spécifications sont conçues pour répondre aux contraintes d’un domaine d’application précis.
Un DSL est créé pour résoudre des problèmes d’un domaine particulier, et n’est pas conçu pour résoudre tous les problèmes (même si cela serait techniquement possible).
Finalement, un DSL se situe entre un petit langage de programmation et un langage de scripting, et est souvent utilisé comme une librairie de programmation. Une définition finalement assez floue …
Pour mieux catégoriser un langage, on peut s’appuyer sur la complétion Turing, à savoir un langage qui possède un pouvoir expressif au moins équivalent à celui des machines de turing.
Avec ces critères, on peut affirmer que le HCL utilisé par terraform n’est pas Turing-complet.
Mais est-ce suffisant pour dire que cela n’est pas du code ?
Prenons un autre exemple en Java, langage quant à lui Turing-complet.
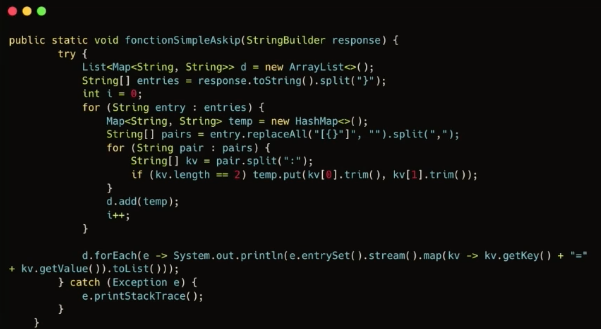
Cette méthode permet de construire une liste. On ne sait pas trop comment elle le fait qu'elles ont les éléments à l'intérieur, pourtant ce langage est bien Turing complet.
L’expression d’une intention, véritable nature du “code”
La clef, c’est de réussir à exprimer l’intention. L'objectif du développeur est qu’à la lecture du code, le lecteur en comprend le résultat et le produit associé : “What You See Is What You Get” (WYSIWYG).
Dans un monde idéal, l’IaC réussirait cela ! Mais on peut se poser des questions sur sa faisabilité :
- Peut-on réellement isoler les couches de complexité ?
- En réutiliser certaines pour d'autres cas d’usage ?
- Avoir un endroit où je mets uniquement mes règles métier (policies) sans parler d’infra ?
- Peut-on tester unitairement ce code ?
Oui répond le développeur, qui a l’habitude d’utiliser deux concepts de la programmation :
- L’abstraction : Faire ressortir les caractéristiques essentielles d’un objet, à son observateur.
- L’encapsulation : “Compartimenter” les objets en séparant le contrat d’interface de son implémentation.
Mais en pratique, comment implémenter ces notions dans le code d’infrastructure ?
L’application des paradigmes de développement au code d’infrastructure
L’intention
Commençons par la base. L’intention doit être aussi claire dans le code que dans les tickets.
Il faut en finir avec la "liste de course” et résonner avec des personas et des user stories.
Par exemple : 
La différence avec le développement d’un produit est que l’utilisateur du produit d’infrastructure est le développeur et non l’utilisateur final de l’application.
L’objectif est d’avoir quelque chose de clair dans le code.
L’interface utilisateur
Elle doit être pensée à la fois pour les Dev et les Ops.
Il faut éviter l’installation et la configuration d'outils complexes et chercher un outil accessible.
Cela peut simplement être une CLI, ou être plus évolué avec une interface web. Lorsque la complexité augmente, on préférera avoir des définitions par des fichiers tels que du Json, du Yaml ou par exemple des CRD pour kubernetes.
Les clefs pour réussir son code d’infra
- Atteindre son but le plus rapidement possible
- Chercher à faire évoluer son code selon les usages plutôt qu’appliquer des design patterns ou des principes
- Avoir des actions répétables pour pouvoir tester
Avoir une vision produit de son infra
Est-ce que je veux vraiment faire tout ça ? A priori, oui. L’objectif n’est pas de tout faire avec un langage de programmation, mais de réussir à modéliser et à exprimer l'intention des développeurs pour qu’ils puissent interagir dessus.
Aujourd’hui, il faut avoir une vision produit de son infra. On a des utilisateurs, des développeurs qui vont utiliser l’infra et des ops qui vont gérer les règles de déploiement.
Chaque partie a des enjeux d'adoption comme un produit.
Comment découper son produit d’infrastructure ?
On peut comprendre que tout le monde n’a pas forcément le besoin de travailler sur l’implémentation la plus basse d'infrastructure, tel que le déploiement de conteneurs.
Dans ce cas, il convient de créer des couches d’abstractions au-dessus du code d’infrastructure (Terraform, Pulumi… ) et ensuite de proposer ses abstractions au client du produit d’infrastructure.
5 - Interface - le portail développeur : une interface simple et efficace
4 - Description - avoir un moyen de décrire son application tel un docker compose
3 - Coordination / usecase - coordination de modules d’infrastructure
2 - Encapsulation / Repositories - L’encapsulation des policies et des pratiques dans les modules d’infra
1 - Provisioning - cloud api - l’automatisation directe de provisionnement de ressources cloud.
L’intention est de donner accès aux développeurs aux couches les plus hautes pour permettre le déploiement rapide d’applications sur mesure.
Les couches les plus basses étant réservées aux ops pour l’écriture des règles de déploiement et de sécurité spécifique à l’entreprise.
Concrètement, à quoi cela peut ressembler ?
Durant la présentation, Sébastien et Ulysse ont présenté un exemple avec Pulumi.
Pulumi est un framework permettant le déploiement et la gestion de l’état de son infrastructure à l’instar de Terraform. La différence est qu’il permet l’utilisation de code tel que du Javascript, Python ou Go pour la déclaration des ressources.
Cette approche permet de faciliter l’intégration des concepts énoncés plus tôt.
Le code du POC est disponible sur github
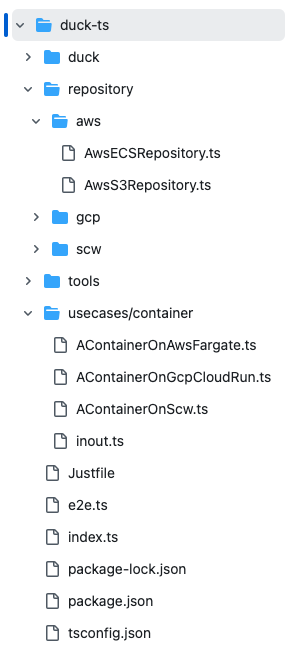
Le proof of concept décompose l’application dans un format dérivé de la clean architecture.
- Repository : Correspond à la construction de nos différents services déployés.
- Ils contiennent la définition des ressources en Pulumi.
- Cet élément constitue la couche 2 de notre modèle OSI de l’infrastructure.
- Dans notre cas, 3 repositories sont disponibles pour des services de aws, gcp et scaleway.
- Use Cases : La couche 3 de notre modèle OSI de l’infrastructure.
- C’est ici que les repositories vont être appelés pour construire des services conformes aux règles de l’entreprise.
- Par exemple, on peut imaginer que pour déployer un conteneur sur AWS nous avons besoin d’un cluster Fargate qui va exécuter notre conteneur, d’un VPC et d’une gateway avec un nom de domaine pour l’accès à distance.
- Duck : Contient la description des actions possibles, notre couche 4
- Déployer un conteneur sur AWS, déployer un conteneur sur scaleway…
- Index.ts : correspond à notre point d'entrée dans l’application (couche 5). Ici, on utilise Commander pour créer une CLI. Par exemple :
- la commande deploy aws va appeler deployContainer du dossier Duck (couche 4)
- Qui va sélectionner les usecase pour AWS qui va utiliser AContainerOnAwsFargate (couche 3)
- Qui va appeler le repository awsECSRepository.ts (couche 2).
- Qui va créer la ressource avec Pulumi (couche 1)
Conclusion du rédacteur
Avec cette présentation, Sébastien Gahat et Ulysse Fontaine nous ont présenté une nouvelle manière de penser l’infrastructure. On ne voit plus l’infra comme une liste de courses, mais bien comme un produit. Un produit spécifique qui n’est pas une application web avec ses propres paradigmes.
Cette approche existe déjà avec les modules terraform ou les CRD de kubernetes. Mais qui, grâce à l’utilisation d’un langage de code conventionnel, permet une collaboration plus simple entre les développeurs et les opérationnels.
Les plateformes de développeurs sont présentées comme une interface plus user friendly, mais est-ce vraiment ce qu’attendent les développeurs ?
Pour en savoir plus sur les plateformes développeurs, Cyril Natkovitch nous présente Comment une Internal Developer Platform peut apporter de la clarté dans un SI mouvant.