Continuous Delivery: How do we deliver in 3 clicks to 7000 machines?
Through this post I would like to share with you the continuous delivery chain that we’ve successfully set up. My point is to describe the whole chain (from the Svn check in to the feedback loop to get the deployment status) and highlight some tricks that we discovered.
In our context, we cannot speak about Continuous Delivery without addressing the DevOps approach that we clearly have in our teams. This approach gives the opportunity to share our needs and exchange points of views between the Developer and Operational teams. Some of the important points are described here.
So let's check out how our DevOps team can build and deploy 7000 clients in 3 clicks.
Context
The solution we have to deploy is a Windows service developed in C# which communicates via FTPS with a server developed in Java.
In this article we will focus exclusively on the .NET client application deployment. The Continuous Integration platform is used by both projects, which is why we do not use TFS but Hudson/Maven for the .NET build. We deploy to an installed base of over 7000 company-provided machines located everywhere in France.
Technology used
From a subversion check in to the deployment of the binaries on the machine we can find several technologies:
- Regarding the Continuous Integration system we use Jenkins, Maven and Nexus. This is a typical java CI but it works great for .NET solutions as well and it’s really easy to deal with.
- The OCS Inventory software has been chosen to administrate the fleet of machines. OCS Inventory is based on a web server centralizing all information sent by the OCS Agent installed on each machine. Through this tool, you can get Registry information, hardware information and deploy packages on machines without any action from the user. Machines can be organized through dynamic or static groups.
- Application connection monitoring with Zabbix
The following schema represents the software’s interactions and actions in our Deployment pipeline.
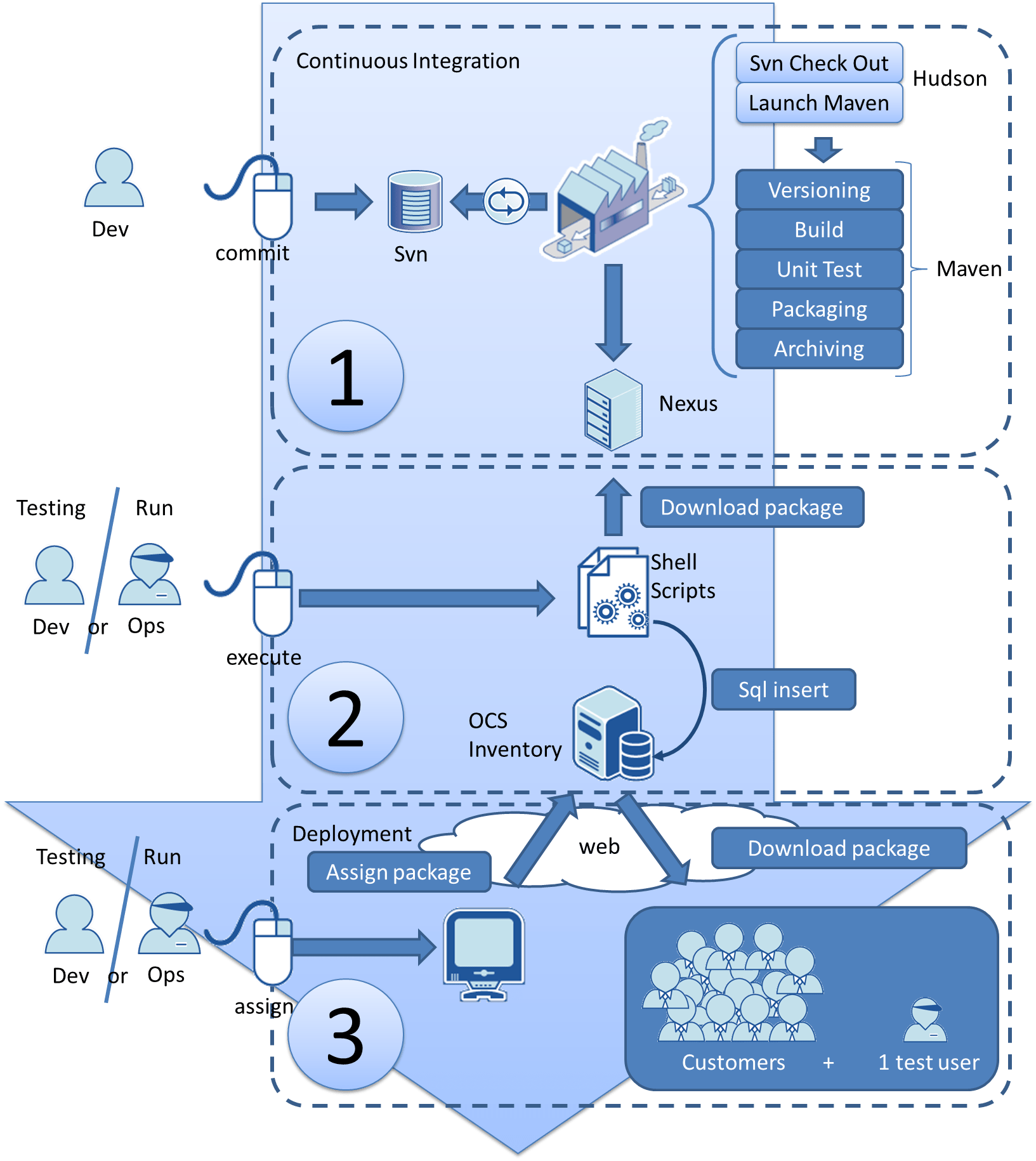
3 clicks to deploy: Deployment Pipeline description
First click: a svn commit launches the Continuous Integration process
Like in all automated build chains, everything starts with a commit; the build is done and tested automatically afterwards.
Our chain is composed of Jenkins as executor, Maven as builder and Nexus as artifacts repository.
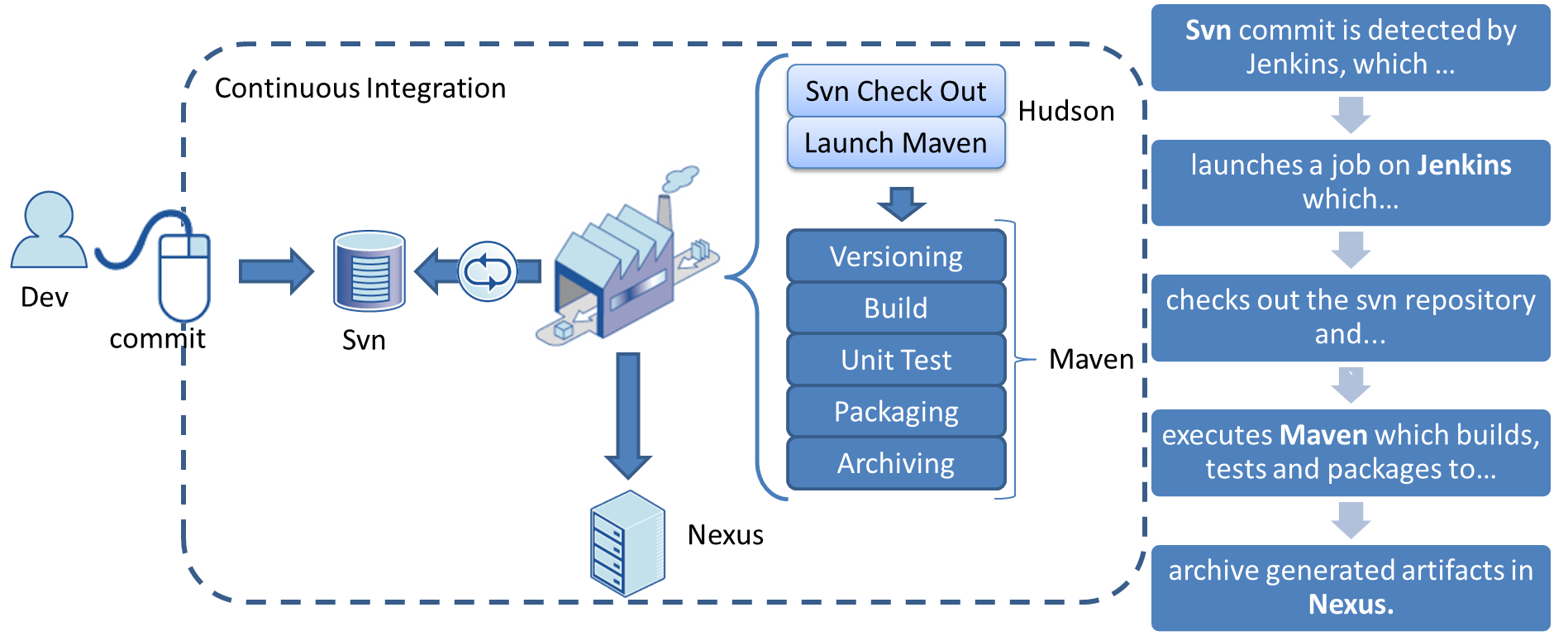
This is a very common CI chain so I won’t describe it more here. But I would like to highlight 2 points:
About Versioning
Once you have to deploy a version of an application to many machines, it is important to properly manage versioning. The reasons range from deployment reactivity to bug cases (fixed with the last version but not the previous one), as well as deployment failures and the controlled deployment of new features. Each DLL of your service has to contain a version number and the setup package has to carry it as well to know which version it contains. In our process, Maven's Pom.xml file carries the version and serves as a foundation for the versioning system (dll version, setup information, artifact names). Technically, before the build, a Powershell script executed by Maven looks for the assembly info files and replaces the version number inside.
About Maven execution steps
Each step is managed by an in-house cmd script executed by the Maven Exec plugin following the principle “Create a Script for Each Stage in Your Deployment Pipeline[[i]](file:///C:/Users/maxence.modelin/Downloads/Continuous%20Delivery%20-%20How%20to%20deliver%20in%203clicks%20only%20on%207000%20machines-v4.doc#_edn1)”.
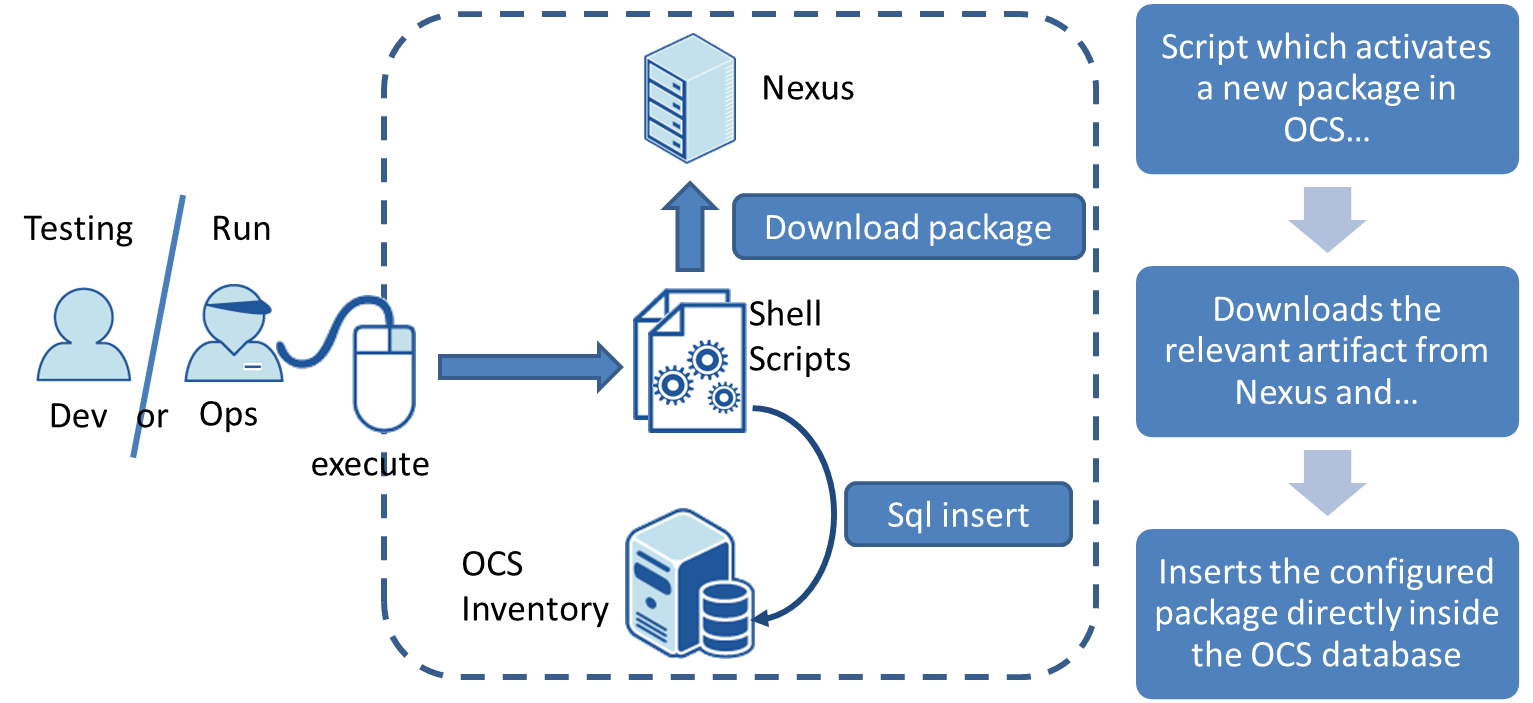
Second click: OCS package creation
A Unix shell script (written by Ops) takes a specific version of a release artifact from Nexus and pushes it as a package ready to deploy in the OCS database.
DevOps point
Ops and Dev had to sit and talk here. Deploying OCS packages is under the Ops' responsibility but application setup is known and developed by Devs. It could take awhile for both teams to understand each others' requirements. Instead of exchanging many informal mails (which could be a really cold media) and being exposed to misunderstandings on wiki documentation, 1 member from each team can sit together and work on scripts and the setup process to deliver a main first version.
Definitely much better than 25 mails and 10 incomprehensible documentation pages (even if it has to be documented as well - and understandable).
Note: this step shouldn’t be manual
In fact this click should not exist because it does not have any functional importance. It should be the last automatic step of the Maven pom file. The deployment should be reduced to only 2 manual steps: - a new build version delivery “controlled” by Dev - package deployment “controlled” by Ops.
The OCS DB insertion as a technical step does not have to be manual and a next iteration on this process will fix it with an Unix shell script.
Third click: assign the package to users
In our context, deployment waves are not effective for all users. Therefore this step is a functional step and has no reason to be automatic: Ops decide to whom they will send the package and assign it through the OCS Inventory tool.
DevOps point
Ops people are busy people. They have a business to run. When setting up the deployment pipeline, we were using the same OCS server to deploy in Production or for testing purposes. As you can guess, we did not succeed in writing the deployment script on our first shot. We iterated on it many times. To give the Dev team more freedom (and so on more responsibility) and get less testing requests, the Ops team granted one of the Dev guys a Power User account on OCS. This means that Devs could deploy packages to customers by themselves. The point, here, is that instead of controlling each of our actions, Ops can decide to entrust a Dev guy with responsibility for the test deployment. This action accelerates development and test cycles, involves theDev team in the deployment's consequences (and how to control them) and gives the Ops team more time to focus on their real work. Definitely a win-win deal.
Is an OCS Inventory test platform needed?
At one moment, we thought about having an OCS Inventory platform just for dev and testing purposes (instead of working with the production platform). Due to other priorities we did not implement that idea. I finally think that was a good thing because it forces dev teams to feel more responsible about the run and check all impacts of their actions.
How do we check that everything works?
Deploying an application to clients is different from deploying to a server, you cannot easily control if it was successfully deployed. Our feedback loop is done by 2 tools (OCS Inventory and Zabbix) and a fake user.
Through a fake user
For each deployment wave, we prepare a machine updated with the current version. This fake client is made part of the group of users to whom we deploy the package. Once the deployment starts we force an OCS Contact on our fake client to download the package and check that everything proceeded smoothly.
Through OCS
The delivery status set by OCS just informs us if the whole package was transferred and the install script launched, but if the installation script ultimately fails, OCS will not report it.
To get a feedback on the deployment status, we write setup information inside registry keys and force an OCS contact at the end of the deployment script. OCS was configured to upload the registry value of these keys and through this system we could make OCS dynamic groups based on these values to detect deployment failures.
DevOps point
Without deployment testing handled by Dev team (instead of Ops team), Dev would never have cared about this point.
Through Zabbix
Our application establishes connections with the server. So we can check user connection server reports as feedback loop as well. To read run reports, Ops gave the developers’ team credentials to use Zabbix and they created some graphics to check what was relevant for us (and not for them).
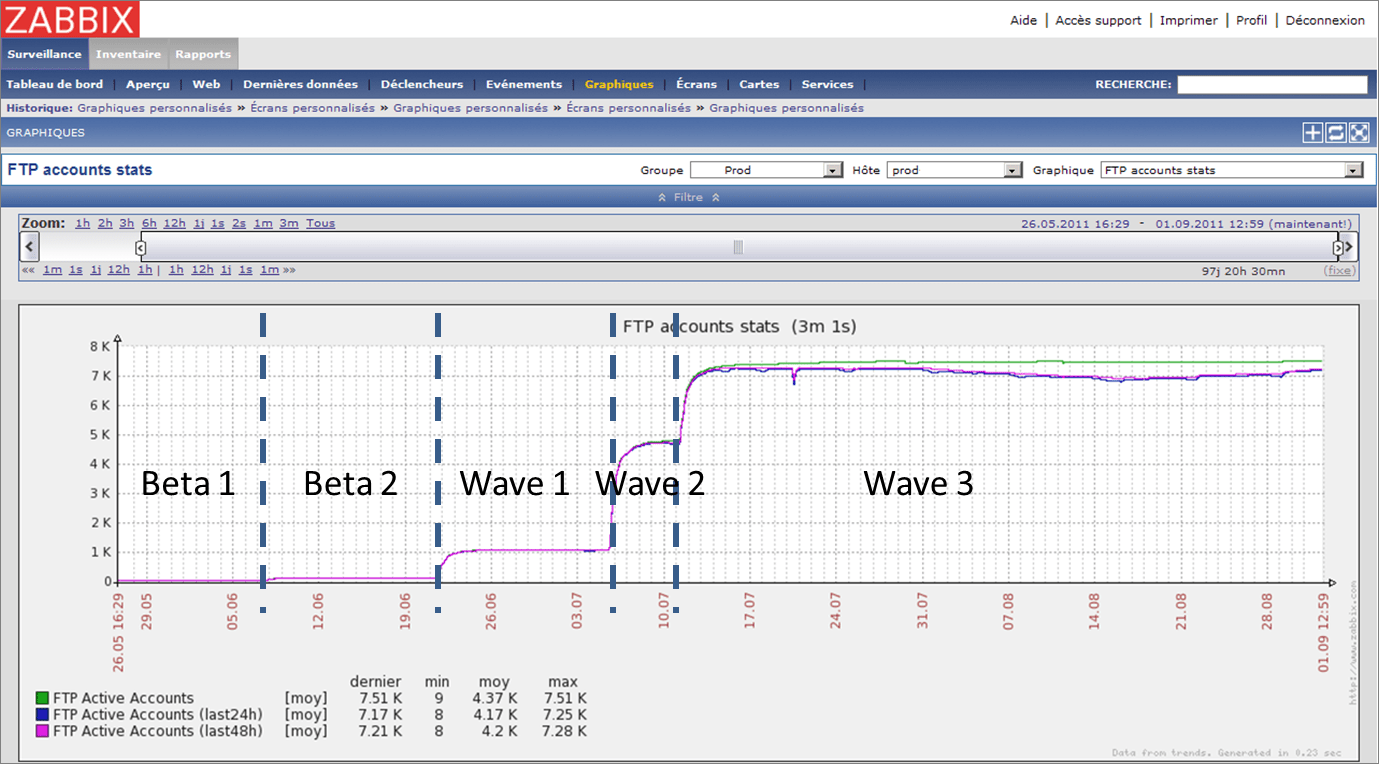
As you can read on the zabbix graphic, the deployment was performed in 5 waves. The first and second waves (10 and 100 users) were beta and then 3 waves covering 1K, 4K and finally 2K users were deployed. Successive deployment waves are spaced by at least 1 week, giving the opportunity to react if an error happens.
The server is never deployed the same day as client applications to mitigate the risk of failure (and in case of error being able to pinpoint easily the issue).
An important point
Deployment and run feedback are important for both Dev and Ops teams. If they aware of errors, Dev guys feel more involved and are more reactive to fix errors. And the Ops team does not have to handle and ask forever to fix them.
Zabbix and OCS Inventory provide interfaces to have an overview on run. It’s an Ops responsibility to set them up and help Dev to use it. But once it’s done, both teams save a lot of time.
Deployment results
So far, we have a 1.5% failure rate during the deployment process. Most failures are caused by user machines rebooting during the deployment, viruses, broken OS or loss of the Internet connection. Very few are caused directly by the OCS Inventory tool.
Following a deployment, 80% of the targeted clients are deployed within 2 days and 99% within the week. This delay is caused by the fact that it is the OCS Agent in each machine that decides when to contact the server.
The maximum deployment wave was for 4000 users in a row.
Finally
From my point of view, one of the bases of Continuous Delivery is to consider that you have to “Deploy the Same Way to Every Environment”. So we used the same chain for testing as for production deployment. Because of this ongoing delivery testing, we (Dev and Ops) were more confident about our delivery process.
One by one, each technical manual deployment step has been automated. A few operations remain manual as they require a functional validation. The Dev team’s definition-of-done then needs to be switched from “producing a binary files zip“ to “delivering a ready-to-be-installed-or-upgraded-and-monitored package“ so that Ops simply have to select who will get the new package (and not create, configure and deliver the whole package)..
So, 2 clicks should definitely be enough to deploy a solution… :)
[[i]](file:///C:/Users/maxence.modelin/Downloads/Continuous%20Delivery%20-%20How%20to%20deliver%20in%203clicks%20only%20on%207000%20machines-v4.doc#_ednref1) From the book “Continuous Delivery: Reliable Software Releases through Build, Test, and Deployment Automation” written by J. Humble and D. Farley