Construire un moteur de recherche avec DataStax
Introduction
Comment construire un moteur de recherche qui rassemble ergonomie, performance et pertinence ? Cette question, nous nous la sommes posée dans le cadre d'un de nos projets. Le Product Owner nous a naïvement exprimé sa volonté d'avoir un moteur de recherche “à la Google” : un outil qui répond aux besoins de l'utilisateur sans aucune connaissance technique ou fonctionnelle préalable, avec une évaluation ludique de son contexte pour lui proposer des résultats pertinents. Une équation complexe qui demande avant toute implémentation une réflexion sur la modélisation de la donnée pour trouver le meilleur équilibre entre de multiples paramètres. Nous verrons comment nous avons su répondre à cette problématique dans une série d’articles. Dans ce premier volet, nous porterons notre attention sur le fonctionnement de DSE, solution de Datastax qui constitue le cœur de notre implémentation. Elle intègre les deux bases Apache Cassandra et Apache Solr chacune d’elles pour un usage différent. Nous établirons dans ce qui suit le principe de fonctionnement de ces deux composants et leurs interactions.
Cassandra
Cassandra est une base NoSQL orientée colonne qui offre un schéma dynamique relativement simple comparé au modèle relationnel. Elle permet le traitement de gros volumes de données en parallélisant le calcul sur plusieurs machines. Chaque table possède une clé de partition qui permet de diviser les données en sous-ensembles qui vont être ensuite distribués sur les différents nœuds d‘un même cluster.
Prenons pour exemple des données clients que nous stockons sur Cassandra :
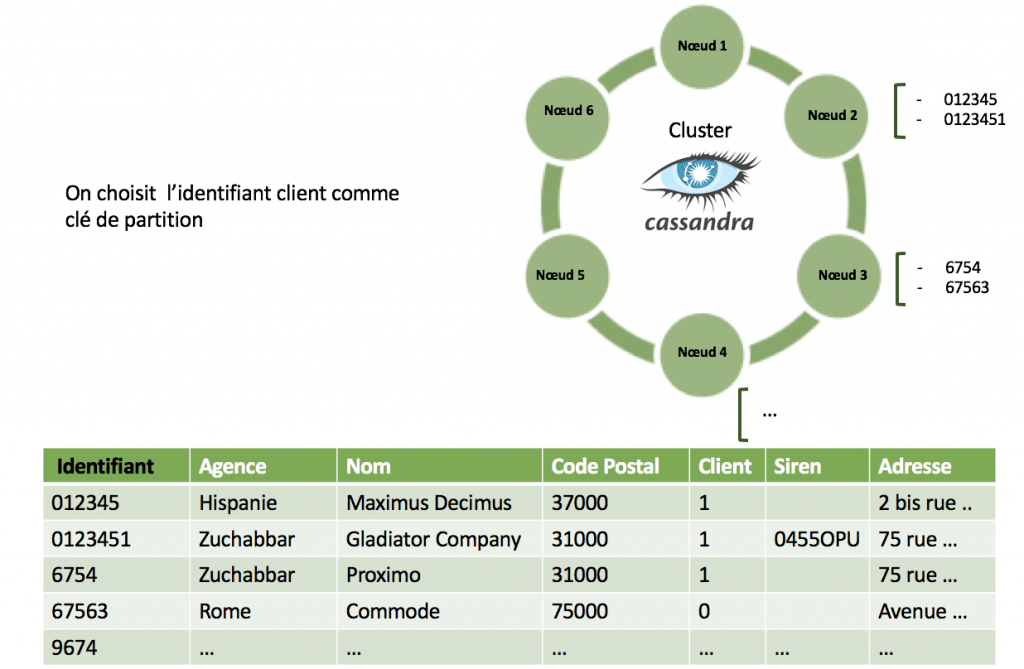
Si on souhaite lire la donnée stockée sur le table on est obligé de renseigner la clé de partition. Sur cet exemple, seules les requêtes qui se basent sur l'identifiant client sont possibles, on est incapable de chercher un client uniquement par son adresse ou son nom. On a toujours la possibilité de créer un Index secondaire sur l’une des colonnes mais cela peut affecter les performances du cluster et ne peut être appliqué sur toutes les données de la table.
Pour enrichir la lecture, Datastax intègre la possibilité d'élever un nœud basique en un nœud de recherche qui intègre sur la même JVM un nœud Solr et Cassandra, ce couplage permet de bénéficier de toute la puissance de la librairie Lucene pour effectuer des recherches plus élaborées sur toutes les données de notre table.
Solr
Apache Solr est une base document distribuée qui encapsule Apache Lucene, une librairie conçue spécialement pour la recherche Full-Text. Lorsqu’on souhaite écrire de la donnée dans ce type de solution on parle d’indexation. Les données au format JSON passent par une première phase d’analyse. On applique un ensemble de transformations aux documents pour en extraire une liste de termes avec leurs index inversés. Ensuite, on génère des segments, objets immutables qui constituent le cœur même de la recherche. Ces derniers sont regroupés sous une représentation logique appelée Index qui porte leurs caractéristiques intrinsèques.
Pour distribuer les données sur l’ensemble du cluster, Solr dispose du Core, une structure qui englobe l’index Lucene et ses propriétés. Dans le même esprit que Cassandra l’index est divisé en plusieurs sous parties appelées shards qui sont ensuite propagées dans le cluster.
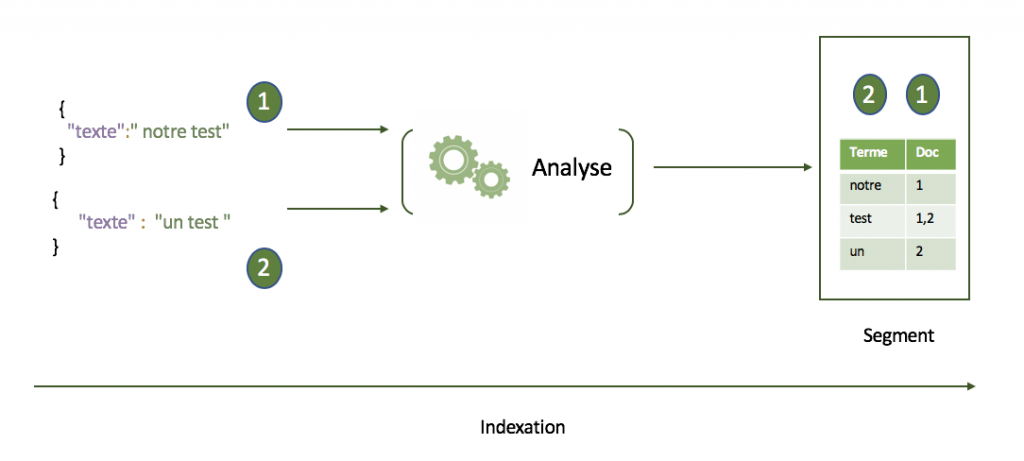
Le core se caractérise par le fichier schema.xml qui synthétise toutes les informations des champs des documents qu’on souhaite indexer ainsi que la liste des traitements et opérations qui leur sont adressés. Par analogie avec le monde relationnel un core représente une table avec son schéma.

Intégration entre Solr et Cassandra
Maintenant que nous avons introduit Cassandra et Solr il est intéressant de voir comment DSE propose de coupler ces deux solutions aux usages différents mais complémentaires, une alchimie qui permet d’associer performance et richesse de recherche. Afin de mieux visualiser l'interaction entre ces deux solutions et comprendre l'intérêt de chacune, nous allons suivre le parcours de l'écriture de la donnée jusqu'à sa mise à disposition pour la recherche dans cet écosystème.
Reprenons notre table de clients créée sur Cassandra. On désire rechercher sur toutes les colonnes et ne plus se limiter à la clé de partition. Pour cela on construit notre schéma Solr qui référence les traitements qu’on souhaite opérer sur les futurs documents de notre Index. Il ne reste plus qu’à utiliser un l’utilitaire dsetool propre à DSE qui permet en une ligne de commande de générer le Core Solr et indexer toute notre table Cassandra.

À présent que la mécanique de base est décrite rentrons un peu plus dans le détail. Dans les coulisses une nouvelle colonne solr_query est ajoutée à notre table Cassandra ainsi qu’un Index secondaire sur cette même colonne. Ce composant sert d’embranchement avec Solr, il gère toutes les mutations soumises par le client d'écriture de DSE. En d’autres termes pour chaque ligne insérée ou supprimée, un document Json est soit indexé soit supprimé de l’Index Lucene.
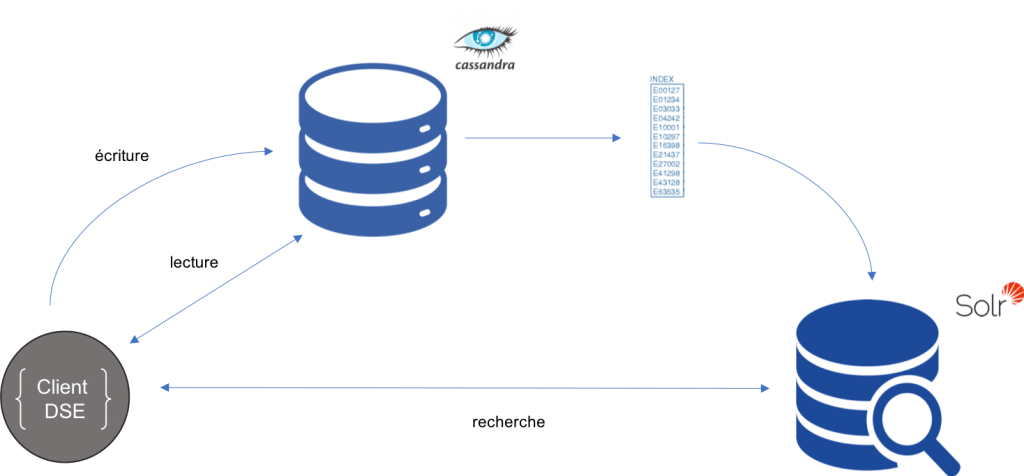
La lecture est portée par le client DSE qui se charge de rediriger une requête sur Cassandra pour les lectures basiques et sur Solr pour les recherches de documents.
Recherche
Maintenant que les données sont indexées nous pouvons lancer notre première recherche

Dans les résultats renvoyés le document qui coïncide au mieux avec notre recherche n’est pas positionné en premier. La pertinence de notre moteur semble ne pas correspondre à nos attentes. Pour en identifier la raison, il faut comprendre comment Apache Lucene score les résultats de sa recherche.
L’algorithme communément utilisé pour le scoring est le TF/IDF, il repose sur le calcul de la fréquence du terme recherché dans un corpus de documents.

- Term Frequency : rapport du terme recherché sur le total des termes du même document
- Inverse Document Frequency : rapport du nombre de documents qui incluent le terme recherché sur l’ensemble des documents du contexte
L’IDF est évalué sur un corpus de documents, il permet d’augmenter la contribution de celui avec des termes plus rares. Sauf que dans un environnement distribué, ce contexte change d’un nœud à l’autre, plus précisément d’une partition à l’autre. Cette variation génère un effet de bord où un document pertinent à l'échelle d’une petite partition se retrouve surévalué par rapport au reste des résultats.

On met en évidence un cas d'école où notre découpage des données n’est pas ajusté à nos recherches. Dans ce cas précis, il faudrait inclure la colonne Nom à notre clé de partition pour une répartition uniforme adaptée à cette recherche.
Ce cas simple met en lumière un point fondamental dans la modélisation de ce type de solution, il est important de partir de la recherche pour sortir notre modélisation. On parle de Design By Query.
Design by query
L’exemple présenté ci-dessus nous aide à mieux comprendre l’importance de cadrer le périmètre fonctionnel et cerner les recherches que va utiliser notre moteur avant de commencer son implémentation. Le schéma à utiliser dans ce type de solution implique une autre façon de penser le stockage et la répartition de la donnée.
Relationnel

Cassandra

Dans le modèle relationnel les données permettent la construction de notre modélisation et des requêtes de notre application à l’opposé de Cassandra et de Solr où les requêtes déterminent la modélisation de notre table ainsi que notre Index et surtout le choix des bonnes clés pour distribuer la donnée.
Conclusion
Ce qu'il faut retenir, c'est que tous les critères d'équilibre de notre moteur vont découler en grande partie du résultat de l’étape de modélisation et d’une phase de test pour vérifier si les choix techniques sont adaptés à notre besoin. Malheureusement, il n’existe pas de formule magique pour réussir notre implémentation, tout le secret réside en notre capacité à faire comprendre au métier l'impact de son expression de besoin et l'accompagner pour construire avec l'équipe de réalisation une modélisation pertinente. Il ne reste plus qu'à tester son comportement en échelle réelle avant de commencer l'implémentation de la solution. Dans le prochain épisode nous détaillerons notre approche auprès de l’équipe projet pour les sensibiliser aux enjeux techniques de notre solution.