Construire un chatbot à l’heure des LLMs
Construire un chatbot à l’heure des LLMs
Si vous travaillez dans le domaine du service à la clientèle, on vous a sûrement déjà prophétisé le bouleversement de votre métier par l’IA, et plus spécifiquement par les large language models (LLMs). Ils sont capables de raisonner sans être entraînés particulièrement pour cela (“Large Language Models are Zero-Shot Reasoners”) et ont besoin de très peu d’exemples pour apprendre à faire de nouvelles tâches (“Language Models are Few-Shot Learners”). Ils peuvent même se baser sur une base de connaissances externes pour répondre aux questions contextuelles à votre organisation (“Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks”). Il devient dorénavant crédible d’automatiser (presque) complètement ce genre de service, avec des bots qui seraient capables de presque passer pour des humains et, dans certains cas, répondre à des questions plus rapidement, 24/7, et à des prix très compétitifs.
Mais vous avez sans doute aussi entendu parler :
- Du chatbot de Air Canada qui propose des réductions qui n’existent pas… et qu’Air Canada a dû appliquer ;
- Du détournement du bot de Chevrolet, notamment pour promettre des réductions ou répondre à des questions de code ;
- De ChatGPT qui accuse un professeur de droit d’agression sexuelle en se basant sur des sources inventées ;
- Du chatbot de DPD qui dit du mal de sa marque.
Alors, est-il crédible aujourd’hui d’utiliser cette nouvelle technologie dans le service à la clientèle de façon sécurisée ? Que proposent les acteurs du secteur des bots dans ce domaine ?
Comment marchent les chatbots basés sur des agents
Commençons par décortiquer le fonctionnement des agents intelligents basés sur des LLMs. En bref, ils utilisent des LLMs pour comprendre des requêtes et y répondre en langage naturel. Ils intègrent par ailleurs d’autres outils, permettant d’augmenter leurs compétences afin de répondre efficacement à des demandes utilisateurs.
Utiliser des LLMs pour communiquer via du langage naturel
Plus précisément, les agents se basent sur des modèles dits “encodeur-décodeur”, tels que présentés notamment dans le papier “Attention is all you need”. Il s’agit de modèles capables de prendre en entrée du texte et d’en générer la suite. Entraînés sur des milliers de milliards de tokens, ils apprennent la structure du langage, à quoi ressemble un raisonnement, des bases de bon sens, l’exécution de certaines tâches…
Ces modèles tels quels ne peuvent cependant pas être utilisés pour avoir des conversations utiles avec des utilisateurs. En effet, ils sont entraînés pour générer la suite d’une phrase. C’est donc en les alignant pour répondre à des instructions, comme avec InstructGPT, et en faisant du prompt engineering que nous arrivons à les faire converser.
Un problème persiste cependant. Ces modèles :
- sont entraînés pour donner une réponse plausible et non une réponse exacte ;
- leurs connaissances se limitent à ce que leur corpus d’entraînement connaît, c’est-à-dire souvent des données publiques qui ne sont plus à jour.
On peut donc les outiller. C’est là où l’approche agent devient intéressante.
Les agents conversationnels pour répondre efficacement à des demandes utilisateurs
Un agent intelligent est un système autonome, capable d'exécuter des actions de lui-même afin d’accomplir une tâche dans un contexte donné. Comme souligné dans le papier “The Rise and Potential of Large Language Model Based Agents: A Survey”, les LLMs sont une brique centrale dans la construction d’agents intelligents aujourd’hui. En effet, leur autonomie (capacité à raisonner sans intervention humaine), réactivité (temps de réponse compatible avec une conversation), proactivité (capacité à s’adapter à un nouveau contexte) et capacité sociale (pouvoir communiquer fluidement en langage naturel), font d’eux d’excellents orchestrateurs pour résoudre des tâches demandées par des utilisateurs en autonomie.
Cette approche permet de répondre à des questions complexes en langage naturel en s'appuyant sur des bases de connaissances, des fonctions externes et d'autres services - voire même autres Agents LLMs. Ils utilisent des modèles de langage pour comprendre les requêtes des utilisateurs et orchestrer l'utilisation de différentes ressources pour générer des réponses. Parmi ces ressources on peut compter:
- Des bases de connaissances. Les agents peuvent accéder à des bases de données externes pour obtenir des informations spécifiques nécessaires à la réponse ;
- Des fonctions externes : Les agents peuvent utiliser des API ou des fonctions spécifiques pour exécuter des tâches complexes ou obtenir des données en temps réel.
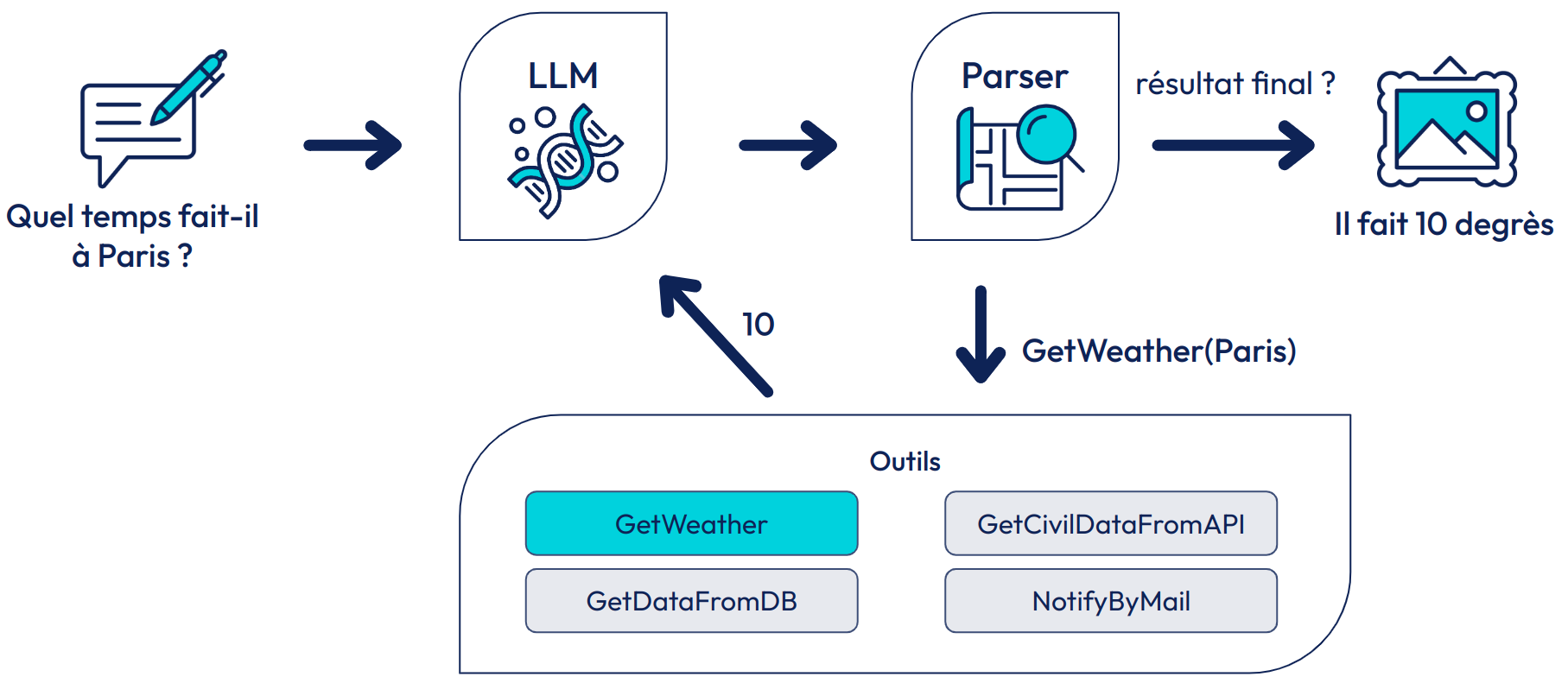
Exemple d’agent conversationnel permettant de répondre à une demande utilisateur
Parmi les outils qu’un agent peut utiliser, on retrouve la récupération augmentée par génération (RAG). Cette technique, de plus en plus répandue de nos jours, permet d'accéder à des informations externes, comme des bases de données ou des documents, de les intégrer de manière fluide et facile dans la base de connaissance du modèle sans avoir à le ré-entraîner. On note deux étapes pour l’architecture du RAG :
- Étape de récupération : Lorsque l'agent reçoit une requête, il utilise un module de récupération pour chercher des informations pertinentes dans une base de connaissances. Pour cela, il compare la requête à un index vectoriel de chaque entrée de cette base. Cela permet d'obtenir des données à jour et spécifiques à la question posée ;
- Étape de génération : Ensuite, le modèle de langage utilise les informations récupérées pour générer une réponse cohérente et contextuellement appropriée. Le LLM intègre les nouvelles données dans son processus de génération pour produire une réponse plus précise et pertinente.
Comment les éditeurs de bots classiques utilisent les LLMs
Les éditeurs de solutions de chatbot historiques sont prudents dans l’intégration des LLMs dans leurs solutions. Ils servent plusieurs clients déjà en production, et cherchent à sécuriser l’utilisation de ces nouvelles technologies avant de les recommander à leurs clients. Cependant, les LLMs bouleversant leur domaine, il est crucial pour eux de les intégrer à leurs solutions. Ils le font en s’inspirant du fonctionnement historique des chatbots, tout en l’augmentant grâce à la puissance des LLMs.
Comment marchent les chatbots classiques
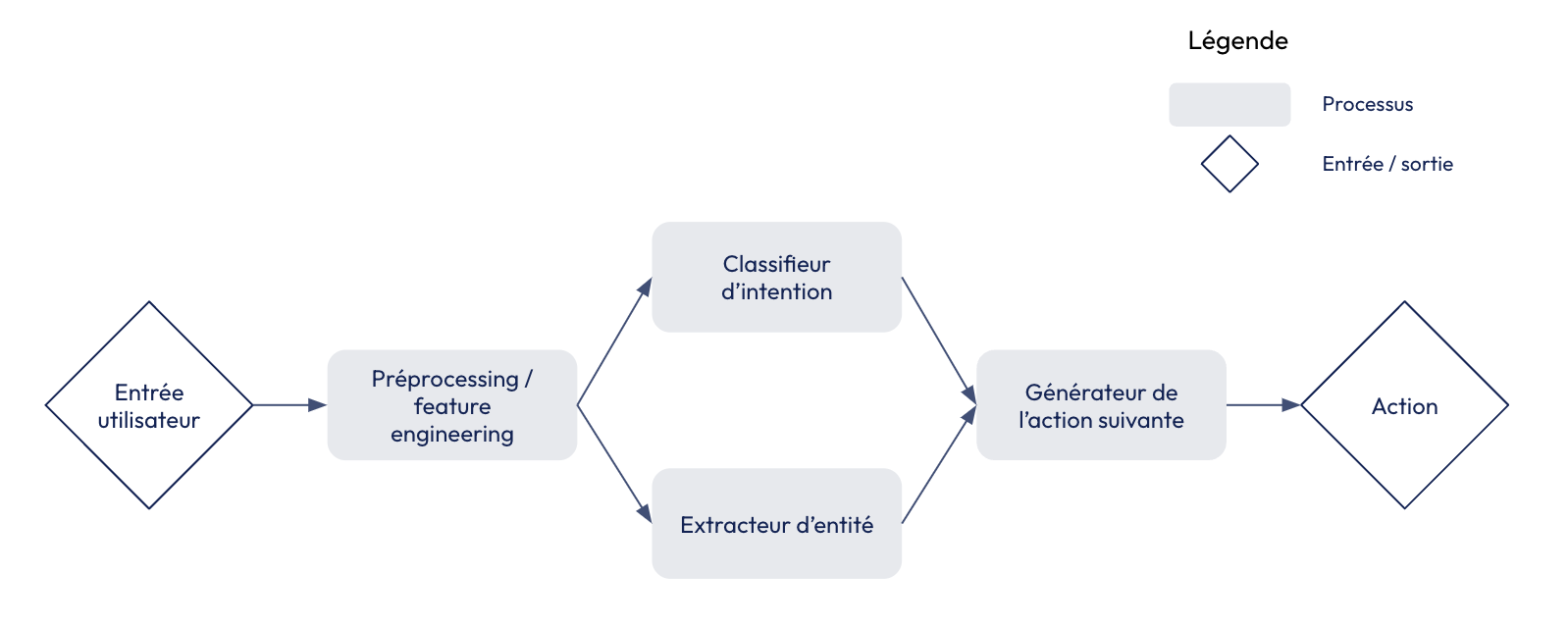
Exemple simplifié de processus de génération de l’action suivante par un chatbot classique
Schématiquement, un chatbot classique :
- Traite le texte donné en entrée par un utilisateur pour en tirer des variables. Il s’agit typiquement d’embeddings : des représentations vectorielles des mots, plaçant les termes proches en sens à côté dans un espace vectoriel. Les embeddings les plus performants, basés sur des transformers, permettent de tenir en compte le contexte dans la génération de ces représentations vectorielles ;
- Extrait des entités, ou termes d’intérêt pour le modèle. Il peut s’agir d’adresses, de noms, de montants, de plaques d’immatriculation… et dépendent du domaine métier dans lequel le chatbot est déployé ;
- Détecte l’intention de l’utilisateur : souhaite-t-il effectuer un virement ? Annuler un voyage ? Parler à un humain ?
- Prédit la ou les actions que le bot doit effectuer suite à la demande de l’utilisateur. Il peut s’agir :
- D’un appel à un outil externe ;
- Du remplissage d’un formulaire ;
- D’envoyer une réponse parmi une liste prédéfinie à l’utilisateur
Ces étapes sont faites soit avec des outils déterministes :
- Regex pour extraire des numéros de téléphone, des adresses e-mail… ;
- Détection de mots-clefs pour déterminer des intentions ;
- Arbre de décision explicitant la prochaine action à prendre sachant les actions précédentes.
Soit en utilisant des modèles de machine learning :
- BERT-NER pour extraire des entités ;
- DIET pour détecter des intentions et/ou extraire des entités ;
- Dialogue transformers pour prédire la prochaine action que le bot devrait prendre.
Les avantages et désavantages des bots classiques
❌ Dans les deux cas, un bot qui traite un cas métier complexe, nécessite soit d’importants efforts de développement afin d’avoir un arbre de décision encapsulant toutes ces règles, soit de pas mal de données d’entraînement afin d’apprendre ces règles métier. Il est d’ailleurs facile de traiter les happy path, lorsque l’utilisateur répond au script idéal, mais beaucoup plus compliqué de réagir à des digressions, corrections, changements de sujet…
✅ Même lorsqu’il se base sur du machine learning, un bot classique n’est pas aussi imprévisible qu’un agent basé sur des LLMs génératifs. Il peut certes mal comprendre une information donnée par l’utilisateur, son intention, ou exécuter une action non pertinente par rapport à la demande, mais il ne peut pas dire quelque chose qui n’a pas été écrit explicitement par un humain. Cela le rend plus stable, mais aussi moins naturel : un bot classique aura du mal à rebondir de façon naturelle aux interactions de l’utilisateur et aura donc un ressenti plus robotique qu’un agent LLM.
L’intégration des LLMs dans les outils de chatbot classiques
Les acteurs que nous avons étudiés viennent du monde des chatbots classiques. Leurs clients en production utilisent surtout leurs solutions historiques. Cependant, ils ont pris le tournant des LLMs, permettant aux deux approches de cohabiter et proposant une implémentation mixte et/ou progressive.
Chez Rasa
Rasa est le leader open source dans le domaine des chatbots. Il propose dans son offre payante, Rasa Pro, une approche des bots qui permet d’intégrer des LLMs pour certaines tâches du bot, sans pour autant le laisser complètement libre au moment de générer sa réponse. Son approche est détaillée dans le papier CALM - Conversational AI with Language Models et dans sa documentation. Nous vous résumons ici son fonctionnement.
Il n’est plus ici question de détecter des intentions et des entités pour ensuite déduire les actions que le bot devrait prendre : CALM compte sur une brique de compréhension du dialogue (Dialogue Understanding - DU), qui peut être basée sur un LLM. Elle prend en entrée les interactions entre le bot et l’utilisateur ainsi que les règles métier définies par le développeur, pour renvoyer une liste de commandes à exécuter.
Les interactions entre le bot et l’utilisateur sont tout simplement le transcript de la conversation.
Les règles métier définies par le développeur sont renseignées sous forme de flows ou de patterns. Un flow ressemble à ceci :
transfer_money:
description: send money to another account
steps:
- collect: recipient
- collect: amount
- action: initiate_transfer
Un pattern est un genre de flow prédéfini permettant de répondre à des situations classiques dans le domaine des bots : digressions, corrections, demande de précisions… ils peuvent être personnalisés par le développeur.
Tous ces éléments sont intégrés dans un prompt, qui donne des indications au LLM sur la façon de générer sa réponse.
Les commandes sont une liste d’actions définies par Rasa. La brique de compréhension de dialogues peut par exemple donner comme commande d’exécuter un flow, de l’annuler, d’enregistrer certaines informations données par l’utilisateur, de faire une recherche documentaire, de demander des clarifications, de transmettre la communication à un humain…
L’intérêt pour Rasa de générer des commandes plutôt que des réponses, c’est que la liste des commandes est une liste prédéfinie par Rasa. Si le LLM hallucine et invente une commande qui n’existe pas, Rasa associe alors une commande par défaut (Cannot Handle). De plus, chaque commande est associée à une réponse qui peut être explicitement écrite par un humain. Les commandes générées sont ajoutées à une pile de commandes, qui seront exécutées par le dialogue manager.
Cependant, il est toujours possible d’utiliser la sortie des LLMs en frontal utilisateur, que ce soit via la recherche documentaire ou la reformulation des réponses via un LLM afin de rendre la conversation plus fluide. Cependant, cela implique un risque de détournement du bot que l’organisation doit être prête à accepter.
Chez Cognigy
Cognigy est un des leaders sur le marché des plateformes d’IA conversationnelles selon Forrester et Gartner (lien accessible pour les abonnés à Gartner). Il s’agit d’une solution propriétaire, qui permet de créer des bots via une interface low code.
Nous avons testé cette solution, qui intègre de l’IA générative principalement sur deux axes :
- Assister la construction d’assistants virtuels ;
- Interagir avec l’utilisateur.
Assister la construction d’assistants virtuels
Cognigy propose d’assister le concepteur de bot sur les points suivants :
- Générer un lexique utilisé lors de la détection d’entités
- Générer les arbres de décision décrivant un parcours de conversation ;
- Générer des données d’entraînement pour la détection d’intentions.
L’objectif est de gagner du temps lors de la construction du bot afin d’améliorer la productivité des personnes le concevant.
Interagir avec l’utilisateur
Cognigy propose une interface no-code pour interagir avec des LLMs. Il intègre des briques permettant de faire appel à un LLM à partir du bot :
- LLM Prompt permet d’envoyer un prompt au LLM de son choix, et stocker sa réponse ;
- GPT Conversation (expérimental) donne la possibilité de discuter directement avec un LLM. Elle peut aussi utiliser une base de connaissances pour minimiser les hallucinations ;
- Search Extract Output permet d’effectuer une recherche documentaire grâce aux LLMs.
Cognigy enrichit également des briques existantes grâce aux LLMs en permettant de reformuler la réponse du bot. Certains nœuds utilisés pour envoyer une réponse à l’utilisateur peuvent être configurés pour que leur réponse par défaut soit reformulée avant d’être envoyée. Cette reformulation peut être utilisée aussi pour réagir à une réponse non reconnue de l’utilisateur : on pose la question autrement pour voir si la réponse est mieux exploitable.
Cognigy est assez prudent avec ces fonctionnalités, et offre des possibilités par exemple de les utiliser uniquement dans la construction d’un assistant de ses agents humains, qui servent de garde-fous contre les hallucinations.
Construire un agent en low code
Grâce aux différentes briques qu’il propose, Cognigy permet de construire un agent conversationnel en clic-bouton, en codant quelques bouts du processus. Voici un exemple simplifié de ce type de flow :
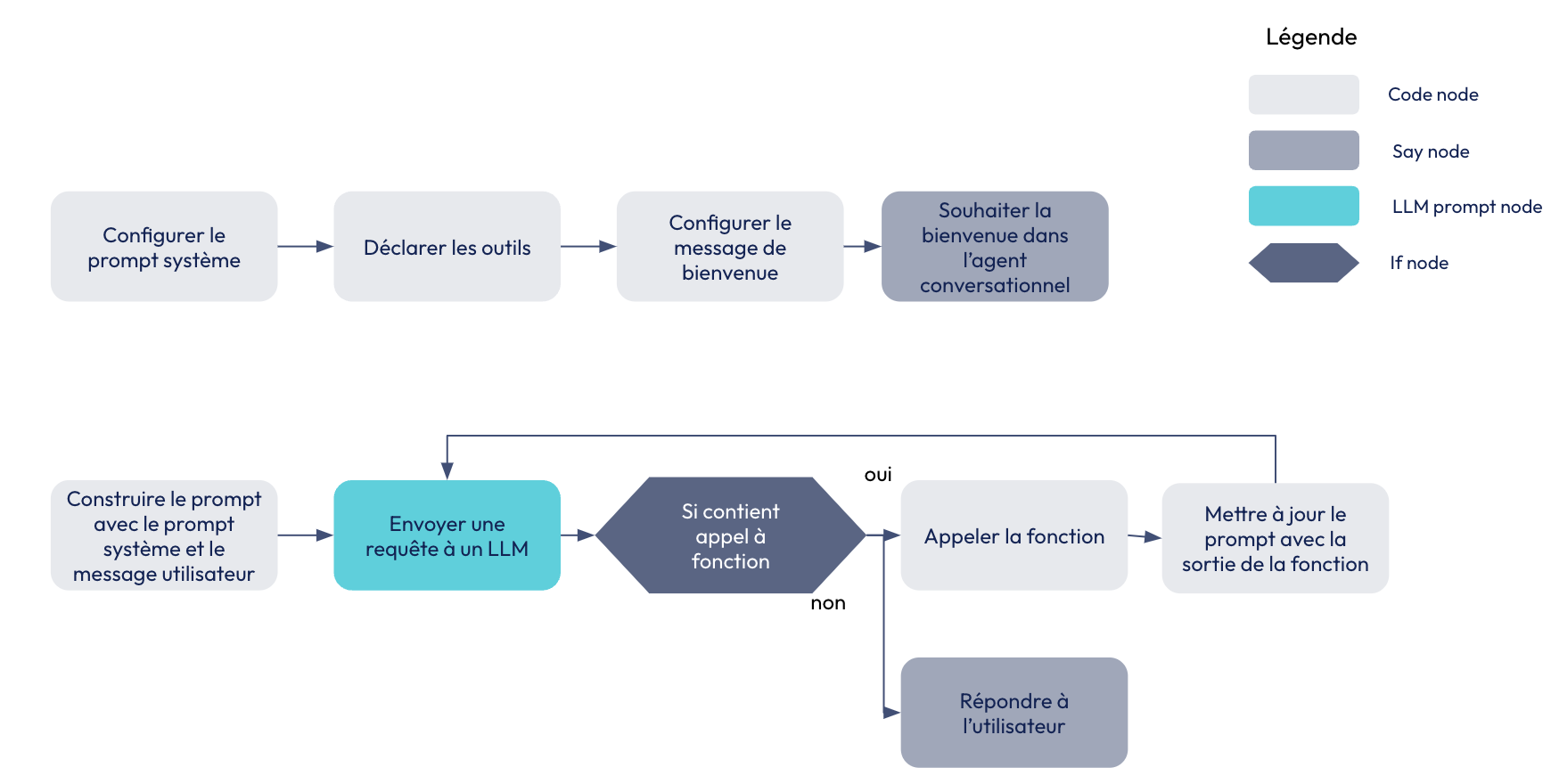
Exemple d’agent créé en clic-bouton avec Cognigy
Chez d’autres acteurs
Même si nous avons concentré nos efforts à découvrir ces deux outils, il en existe plusieurs autres intéressants à creuser, notamment Kore.ai, qui a une approche semblable à Cognigy, ou Openstream, qui prend une approche multimodale.
Conclusion
Il est probablement encore un peu tôt pour basculer tous vos systèmes de gestion de la clientèle vers des agents intelligents basés sur des LLMs. Cependant, nous vous encourageons fortement à expérimenter : une solution propriétaire peut vous aider à mettre rapidement en production un agent plutôt stable, qui aura moins tendance à halluciner. La problématique ici sera probablement la contractualisation : ils demandent souvent des engagements sur des volumes pendant au moins 12 mois.