Construire ses parsers ANTLR avec Maven - Partie 3/3 - Testez vos grammaires
Rappel des épisodes précédents : la dernière version d'ANTLR, la 3.1.1, dispose d'un plugin Maven permettant de gérer à la volée ses lexers et parsers, au moment du build. Nous allons maintenant nous intéresser aux tests unitaires.
Comme pour la partie 2, ce troisième et dernier volet de l'article vient avec un projet de démonstration, sur lequel le texte s'appuie directement.
Poussez Mémé dans les orties !^[<a id="rev-pnote-208-1" href="#pnote-208-1">1</a>]^
Pourquoi ? D'abord, parce que blinder un projet de tests unitaires n'est jamais superflu.
Dans ce contexte, en plus, si vous commencez à écrire des grammaires un tant soit peu complexes, avec des règles de syntaxe qui font référence à des sous-règles qui elles-mêmes... bref, il se trouve qu'une petite modification d'une règle en amont peut changer complètement l'automate qui va reconnaître le langage implémenté, et introduire des régressions de grande ampleur.
Ensuite, vous constaterez vite qu'ANTLR émet parfois des avertissements inquiétants du style "L'automate de décision peut reconnaître la séquence d'entrée en utilisant plusieurs branches alternatives ; la branche n°3 a été désactivée en conséquence" (traduction approximative par votre serviteur). Le projet proposé au téléchargement dans la deuxième partie, si petit qu'il soit, en est un bon exemple. Eliminer ces avertissement n'est pas toujours possible : sans principe d'associativité sous-entendu, une syntaxe comme 1 - 2 - 3 est intrinsèquement ambiguë (= -4 ou +2 ?). Plutôt que de se faire des nœuds au cerveau, une batterie de tests qui s'assurent simplement que la grammaire fait ce que l'on veut, et dont on est sûre qu'elle ne présente pas de régressions, est rassurante.
Enfin, il est impossible de savoir d'un coup d'œil le langage que reconnaît une grammaire en lisant son fichier source .g. Les tests unitaires que nous allons aborder, comme tous bons tests unitaires, ont un rôle documentaire non négligeable en en présentant les spécifications sous forme d'exemples simples et clairs.
Quel outillage ?
ANTLR, tout simplement... ou plutôt gUnit. A l'origine développé comme un projet satellite d'ANTLR, depuis la v3.1 il est distribué directement avec. Ainsi, le JAR antlr-3.1.1.jar que nous avons récupéré par l'intermédiaire de Maven, contient déjà cet outil.
Simplicité et concision
Le fonctionnement de gUnit est des plus simples : il prend en entrée un fichier descriptif de tests (par exemple Demo.testsuite), et est capable de les exécuter dans le contexte de la grammaire à vérifier. Un fichier .testsuite est constitué d'une série de :
nomDeLaRegleATester1:
"Données d'entrée 1" -> "Résultat attendu 1"
"Données d'entrée 2" OK ou FAIL
nomDeLaRegleATester2:
"Données d'entrée 3" returns [Valeur de retour]
...
Dans ce fonctionnement de base, il n'y a aucun code d'initialisation à écrire ou d'environnement à mettre en place (sauf disposer d'une grammaire à tester bien sûr). La forme de la partie droite dépend du type de règle et du test : sortie sur la console (cas n°1), simple indicateur de succès/échec du parsing (cas n°2), ou valeur de retour explicite de la règle si celle-ci en possède une (cas n°3).
gUnit sait aussi valider la construction, par le parser, d'arbres syntaxiques abstraits (AST, brièvement évoqués dans la première partie), mais à ce niveau nous n'en utiliserons pas.
Mise en œuvre
Mais nous allons faire plus que faire exécuter directement les tests par gUnit. Il est aussi capable, à partir du même fichier .testsuite, de générer des classes de test JUnit 4. Du coup, on est capable d'intégrer les tests des grammaires à un harnais de tests unitaires déjà présent pour le projet, tests qui apparaîtront dans les rapports globaux du projet.
Malheureusement, le développement d'un plugin Maven pour gUnit vient tout juste de commencer. En attendant il va falloir l'enrober dans une tâche Ant, branchée sur la phase generate-test-sources du cycle de build (pour rappel, antlr3-maven-plugin se branche sur generate-sources).
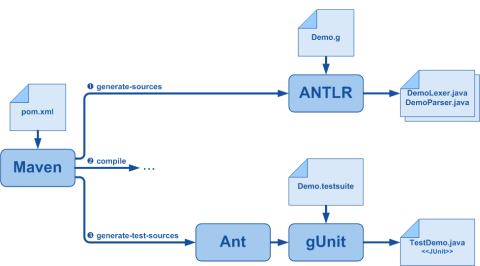
Mise à jour du POM du projet
Reprenons le POM de la deuxième partie de l'article et ajoutons une dépendance vers JUnit 4 ainsi qu'une référence au plugin antrun :
<dependencies>
<!-- Dépendance vers ANTLR v3.1.1 -->
<dependency>
<groupid>org.antlr</groupid>
<artifactid>antlr</artifactid>
<version>3.1.1</version>
</dependency>
<dependency>
<groupid>junit</groupid>
<artifactid>junit</artifactid>
<version>4.4</version>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<!-- Appel du plugin ANTLR (cf. partie précédente de l’article) -->
<plugin>...</plugin>
<!-- Appel d’antrun pour gUnit -->
<plugin>
<artifactid>maven-antrun-plugin</artifactid>
<executions>
<execution>
<phase>generate-test-sources</phase>
<id>com.octo.mvn-antlr.gunit</id>
<configuration>
<tasks>
<property name="compile_classpath" refid="maven.compile.classpath"/>
<ant antfile="antlr-tasks.xml" target="gunit"/>
</tasks>
</configuration>
<goals>
<goal>run</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
Définition des tâches Ant
Voici le contenu du fichier antlr-tasks.xml, appelé depuis le POM ci-dessus :
< ?xml version="1.0"?>
<project name="antlr-tasks" basedir=".">
<macrodef name="gunit">
<attribute name="grammar"/>
<attribute name="srcdir"/>
<attribute name="destdir"/>
<sequential>
<java classname="org.antlr.gunit.Interp" failonerror="true">
<classpath>
<!-- Contient la reference a antlr-3.1.1.jar grace a la dependance specifiee dans le POM -->
<pathelement path="${compile_classpath}"/>
</classpath>
<arg value="-o"/>
<arg value="@{srcdir}/@{grammar}.testsuite"/>
</java>
<move file="Test@{grammar}.java" todir="@{destdir}"/>
</sequential>
</macrodef>
<target name="gunit">
<gunit grammar="Demo"
srcdir="${basedir}/src/test/antlr"
destdir="${basedir}/src/test/java/com/octo/mvnantlr"/>
</target>
</project>
Il définit une tâche Ant , qui va appeler la bonne classe org.antlr.gunit.Interp. Elle est dans le même JAR qu'ANTLR, ajouté au classpath de la tâche par l'intermédiaire de la propriété compile_classpath passée au script Ant.
L'option -o, passée directement à gUnit, sert à lui demander de générer un fichier source JUnit, au lieu d'exécuter lui-même les tests. Cette option ne prend pas en paramètre le nom du fichier à créer : il est construit automatiquement et placé dans le répertoire courant. On ajoute donc une tâche de déplacement du fichier vers le répertoire destdir, qui est un paramètre de la tâche.
Une fonctionnalité intéressante serait de scanner le répertoire src/test/, d'y chercher tous les fichiers *.testsuite et de ne déclencher gUnit que pour ceux qui sont plus récents que les tests cases JUnit éventuellement générés lors d'un build précédent (en reconstituant au passage la bonne arborescence de package). Laissons ce raffinement au futur plugin Maven ; dans notre cas nous n'avons qu'une grammaire et un fichier Demo.testsuite et il est inutile de se compliquer la tâche dès maintenant !
Et ensuite ?
Il reste à écrire Demo.testsuite ! Dans le cas de notre projet de démonstration, les règles de haut niveau (print, ...) écrivent directement le résultat de l'interprétation sur la console. gUnit sait parfaitement comparer la sortie standard du parser pour des données d'entrée et une règle données. Les règles arithmétiques, elles, utilisent des valeurs de retour que nous examinerons avec la syntaxe returns [_valeur_].
Le fichier Demo.testsuite aura donc la forme suivante :
gunit Demo;
@header {
// En-têtes pour les sources JUnit générées
}
exprPri1:
"12" returns [12]
"(1+2)" returns [3]
// ... Autres règles de calcul pur, de type "returns"
statement:
"print 12" FAIL
"print 12;" -> "12n" // Attention au "n"
"a=5;" OK
program:
"// blablabla" OK
"print 12" FAIL
"print 12;" -> "12n"
"a=5;" OK
"a=5; print a;" -> "5n" // Teste une séquence de commandes
Astuce : lorsque l'entrée ou la sortie attendue sont réparties sur plusieurs lignes (gUnit supporte la syntaxe "here-doc" <<< ... >>>), celles-ci sont concaténées dans le source JUnit généré, ce qui pose problème si le fichier .testsuite a des terminateurs de lignes DOS (CR+LF). Dans ces cas-là veillez à garder des terminateurs de type Unix (LF). Laissez aussi au moins un saut de ligne à la fin du fichier, sinon gUnit le refusera.
Exécution des tests
Un mvn install suffit... et ça marche !
------------------------------------------------------- T E S T S -------------------------------------------------------
Running com.octo.mvnantlr.TestDemo Tests run: 19, Failures: 0, Errors: 0, Skipped: 0, Time elapsed: 0.203 sec
Comme expliqué plus haut, gUnit génère pour nous des tests JUnit, il n'y a donc rien de spécial à faire maintenant pour lancer les tests. Dans notre cas, par souci de simplicité on a placé le fichier JUnit sous src/ (cf. antlr-tasks.xml) ; le test sera donc versionné avec les autres sources dans SVN et persistera après un mvn clean, contrairement d'ailleurs au lexer et au parser générés par antlr3-maven-plugin.
Les méthodes de test, elles, sont nommés ainsi : test<_nom_de_la_règle_testée_><_n°_d'ordre_dans_le_fichier_testsuite_>. Quand une règle fait l'objet de nombreux tests, cela peut parfois être difficile de savoir d'un coup laquelle a échoué. Mais en même temps, c'est peut-être aussi que la règle est trop complexe et qu'il est temps de la découper ;-)
Conclusion
ANTLR est une solution reconnue et même la solution de référence pour la construction de parsers, au moins dans le monde Java. En et en plus, il commence à être sérieusement outillé pour s'intégrer avec les produits du moment : Maven, JUnit, et même Eclipse (en plus de l'IDE dédié ANTLRWorks), ce qui le rend directement utilisable dans les projets open-source par exemple.
Et qui n'a jamais rêvé de créer son propre langage ? Les DSLs (Domain Specific Languages) sont à la mode en ce moment, c'est une excellente occasion pour adopter ces outils ! La liste de diffusion dédiée, antlr-interest, est très active et les contributeurs d'ANTLR répondent volontiers aux questions de tous niveaux qui y sont posées.
Merci à Arnaud Héritier pour la relecture et les retours sur la rédaction de cet article
Notes
[1] Désolé pour le jeu de mots minable, c’était trop tentant ! Aucune grand-mère n’a été blessée lors de la préparation de cet article ; par contre la grammaire de démonstration a pu être un peu malmenée à quelques occasions lors de sa mise au point