Comptoir Green AI
Cet article est le compte rendu du comptoir Green AI d’Octo du 16 novembre 2023 présenté par Eric Biernat et Reynald Rivière, faisant suite à cet article sur le blog OCTO.
A l’écriture de ce premier article, le Green AI était un sujet émergent , mais les entreprises s’y intéressent de plus en plus. Il s’agit d’une sous partie de l’IA Responsable qui vise à limiter l’empreinte carbone induite par l'entraînement et l’utilisation des modèles d’IA.
Petite histoire de l’IA avec Alan Turing
Le test de Turing
Alan Turing, le (grand-)père de l’IA, par la définition de son test, a basé la première performance des IA sur leur capacité à imiter les humains. Le test a été largement réussi par Chat GPT, puisqu’on aurait du mal à distinguer d’un humain dans la majorité des discussions. Cependant, on ne peut pas vraiment dire que ChatGPT soit une Intelligence Artificielle Forte, ou Générale, car il est assez mauvais sur certaines tâches basiques notamment. C’est dû au fait que le test de Turing se concentre sur le résultat et non la manière d’y parvenir. Un modèle de type “brute force” peut donc remplir le test sans vraiment faire preuve d’”intelligence”.
Points de rencontre et fossé entre le vivant et l’IA
Par construction, il y a deux points de rencontre entre le vivant et l’IA :
- Les algorithmes sont souvent inspirés du vivant : les neurones artificiels ont été inspirés du cerveau, les CNN (convolutional neural networks) ont été inspirés du cortex visuel du chat, l’apprentissage par renforcement de la dopamine …
- Les résultats ou prédictions des modèles sont liés au vivant : la vision pour les modèles de Computer Vision, la langage pour les modèles de NLP …
Entre les deux points de rencontre, il y a un fossé: les modèles sont très éloignés de l’efficience énergétique du vivant dans leur fonctionnement, mais visent en général la performance pure des modèles, quitte à ce qu’ils soient très énergivores. C’est notamment dû à la définition du machine learning de 1998 par Tom Mitchell qui ne parle que de performance pure.
Le coût en CO2 des modèles
Les modèles d’IA ont deux sources d’émissions de CO2 :
- le CO2 nécessaire à la production d’électricité fournie pour leur entraînement et leur utilisation à l’inférence, qui dépend du mix énergétique de la région où le modèle est utilisé (cloud ou on premise).
- le CO2 émit par les différentes étapes du cycle de vie des composants physiques nécessaires à leur utilisation (extraction des métaux rares, traitements chimiques, construction, recyclage). Cette partie peut devenir majoritaire lorsque le mix énergétique à l’usage est décarboné.
Nous avons vu les sources physiques d’émissions de CO2 des modèles d’IA, nous allons voir les leviers qui jouent sur le coût environnemental d’un modèle.
Dans ce papier , les auteurs font la simplification suivante : 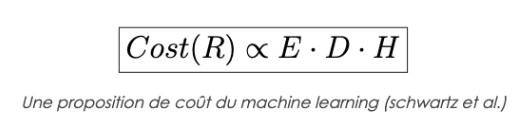
L’IA dans le futur : vers le remplacement de la backpropagation et un retour à l’analogique ?
En entrant plus dans le détail du coefficient “E” du coût des IA, on se rend compte qu’il y a deux grosses sources d’inefficience :
- Algorithmique : la backpropagation utilise beaucoup de ressources
- Physique : le hardware utilisé aujourd’hui est très inefficient
Nous allons ci-dessous développer ces deux problèmes.
Inefficience algorithmique
La méthode d’apprentissage des réseaux de neurones se base aujourd’hui sur la “backpropagation”, où les variables du modèle sont ajustées en fonction des exemples qui lui sont montrés. En résumé : il faut d’abord que l’exemple passe à travers le modèle, “feedforward”, avant de pouvoir calculer les gradients des fonctions d’activation et seulement après reparcourir le réseau dans le sens inverse, “backpropagation” et ajuster les poids et biais. Cet algorithme implique donc un double passage à travers le réseau et de lourds calculs, compris dans le coût d'observation lors de l'entraînement de ces modèles. Ceci contribue au fort impact en CO2 qu’on les réseaux de neurones. Les limites de la backpropagation sont étudiées dans le monde académique
De plus, ces calculs et l'entraînement de ces réseaux est souvent réalisé sur du matériel non-spécialisé, ce qui crée des inefficiences supplémentaires à ajouter à ce coût “E” d'observation.
Inefficiences physique/matérielle
Les machines et le matériel utilisé sont aujourd’hui décorrélées des algorithmes qui vont y “tourner”, bien que certains matériels soient un peu plus spécifiques avec des architectures spécialisées dans certains domaines comme les GPUs.
Petit rappel sur l’Analogique vs le Numérique :
- Analogique: utiliser les courants électriques
- Numériques : transformer ces courants électriques avec un transistor
L’idée de corréler le matériel à l’algorithme et d’avoir des machines dédiées, ouvre la porte au retour analogique.
L’intérêt du numérique est de rendre les signaux déterministes en effaçant les erreurs, même infimes qui sont liées au monde analogique. Le numérique est très utile pour des opérations nécessitant une très grande précision (pour nos opérations bancaires, on ne veut pas d’erreurs sur le montant échangé), au détriment de l’efficience énergétique (l’analogique est des milliers de fois plus efficient que le numérique).
Bien entendu, ces inefficiences nécessitent un travail sur le long terme, et ne sont pas vraiment activables par les entreprises développant des use cases d’IA. En effet, une amélioration des algorithmes et des types de matériel utilisés doivent d’abord être développés par des laboratoires de recherche avant d’être industrialisés. Sur la partie matérielle, des prototypes de puces neuromorphiques commencent à voir le jour.
Nous allons maintenant nous concentrer sur les leviers d’action activables sur le court terme par les entreprises développant des systèmes basés sur l’IA.
A plus court terme, comment réaliser une conception des systèmes de ML plus efficiente ?
On part de plusieurs constats :
- Le gain de performance n’est pas linéaire avec la consommation énergétique d’un modèle (on peut tripler la consommation énergétique d’un modèle pour ne gagner que 0.3 points de performance)
- Il existe beaucoup de métriques sur les modèles mais aucune pour mesurer sa consommation énergétique, son empreinte carbone
- L’empreinte carbone d’un modèle peut être très élevée : GPT-3 d’Open AI a généré une émission de 85 Tonnes de CO2 pour son entraînement
- Environ 90% de l’utilisation énergétique d’un modèle en production se fait à l’inférence
Les différents leviers d’éco-conception des modèles
Partant de ces constats, à Octo nous avons travaillé sur les différents leviers d’éco-conception des modèles d’IA sur leur cycle de vie.
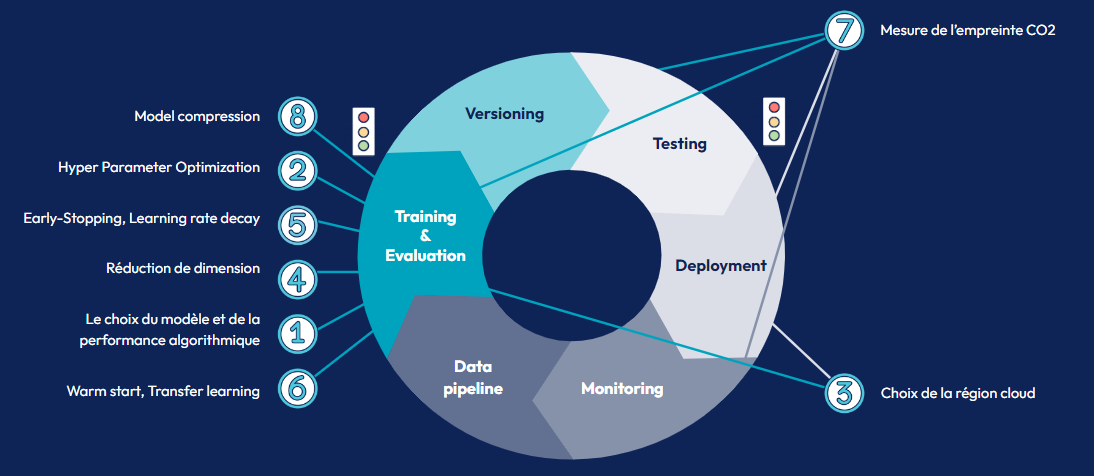
Le choix du Modèle : Nous l’avons vu plus haut, et c’est très intuitif, le coût environnemental d’un modèle est lié à sa taille, plus un modèle est gros et plus il sera polluant. C’est donc un des leviers les plus importants à utiliser pour limiter son coût. Un modèle plus simple sera donc plus frugal en énergie, en plus de coûter moins cher et d’être généralement mieux interprétable. C’est un autre point important du domaine de l’IA Responsable, et permet de faciliter les échanges entre les Data Scientists ayant un profil technique et les profils plus orientés métier. Bien entendu, un modèle plus gros et plus complexe pourra probablement atteindre une performance plus élevée. Selon nos métriques actuelles, il reste difficile de choisir un modèle qu’on sait être sûrement moins performant même si cela permet de baisser son empreinte carbone. Il faut donc trouver un juste compromis entre d’un côté la complexité d’un modèle, et donc souvent sa performance, et de l’autre son coût financier, environnemental et son interprétabilité.
Notre conviction est que ce compromis est fortement lié au contexte métier dans lequel le modèle est utilisé. Il faut donc lier la criticité du cas d’usage avec les moyens mis en œuvre pour adapter la performance du modèle. Nous n’allons pas utiliser le même modèle pour une application médicale qui a un impact sur la santé de patients et une autre où l’on veut prédire une intention d’achat de clients. Il est même pertinent de mettre en place une démarche itérative, en commençant les tests avec des modèles très simples (arbres de décision, voire règle métier) et d’estimer les coûts et bénéfices à utiliser un modèle plus complexe, jusqu’à aboutir au modèle ayant le meilleur compromis pour le cas d’usage considéré.
Certains autres leviers permettent, à moindre coût, de réduire drastiquement la taille des modèles développés (jusqu’à 80%) avec un impact minimal sur leurs performances (de l’ordre du point de performance), ou bien de mettre en place des outils de monitoring d’empreinte carbone à l’échelle du code ou de la plateforme cloud, pour mettre en place l’équivalent d’une pratique de FinOps appliqué au coût environnemental.
Pourquoi s’intéresser au Green AI ?
Une entreprise a beaucoup de raisons de s’intéresser au Green AI, de mettre en place et d’appliquer des bonnes pratiques pour développer des systèmes plus efficients et plus frugaux afin de réduire leur empreinte carbone.
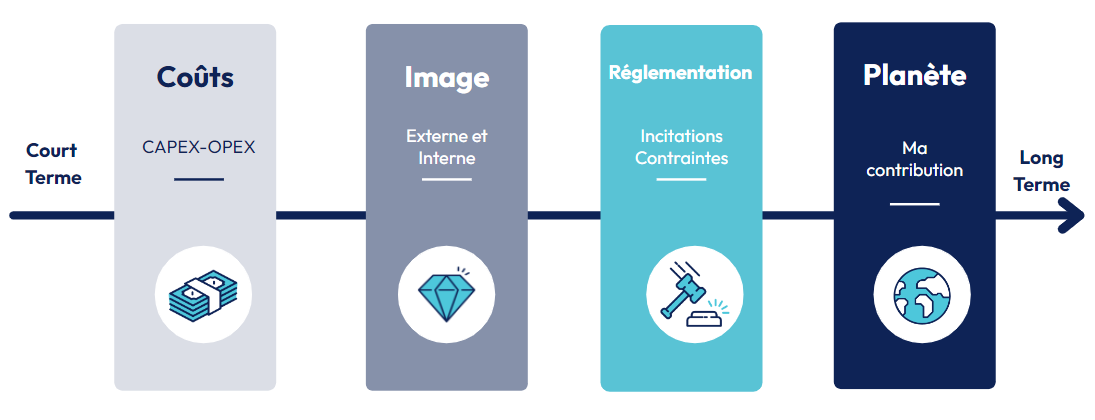
Les coûts financiers (court terme)
De manière très court-termiste et pragmatique, un système plus léger et moins complexe a un coût financier plus faible, il y a dans une certaine mesure une corrélation entre les coûts financier et environnementaux des modèles.
Image d’entreprise (moyen terme)
L’image de marque et l’image employeur sont de gros arguments en faveur du Green AI, les nouvelles générations sont de plus en plus sensibilisées et engagées dans la cause climatique. Une entreprise soucieuse de son image en externe aussi bien qu’en interne se doit d’avoir une stratégie de réduction de ses différents postes d’émissions, dont l’IA fait partie.
Réglementation (moyen terme)
Des réglementations commencent à se créer sur l’IA responsable (comme l’AI Act) et même si elles n’abordent pas aujourd’hui le thème de la consommation énergétique de l'IA, il est probable que de futures réglementations l’incluent.
La planète (long terme)
Au-delà des différentes raisons pragmatiques de s’intéresser au coût environnemental des différents systèmes, il est très important de réduire au maximum l’empreinte carbone de tous les systèmes, et notamment les modèles d’IA que l’on développe en tant que Data Scientists. En effet, le numérique est la dépense carbone qui croît le plus vite, et l’IA en est une sous-partie très énergivore, avec de nouveaux modèles développés dont la taille croît exponentiellement.
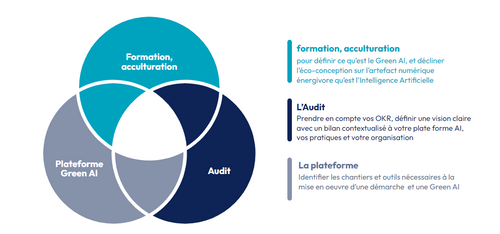
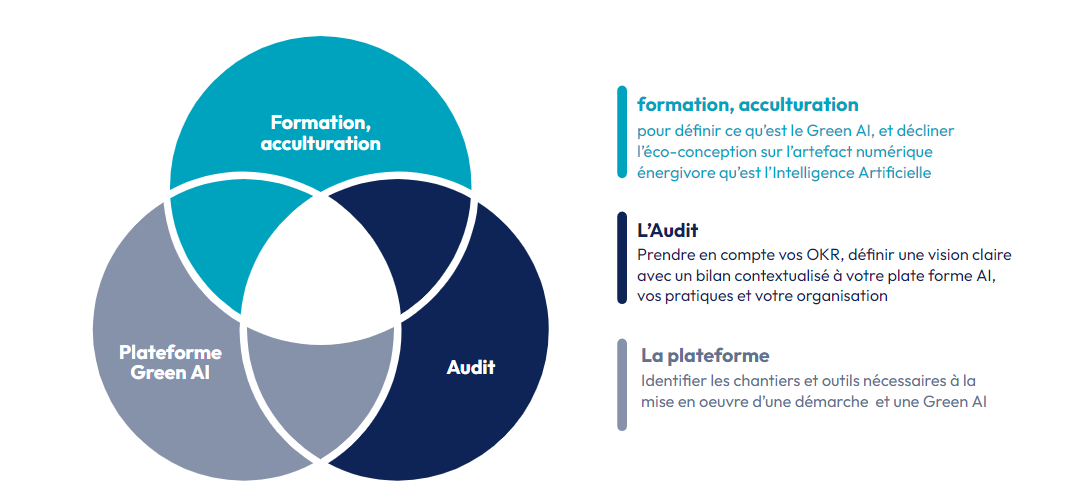
L’offre d’Octo sur le Green AI en trois axes
Octo a ainsi développé une offre pour accompagner des entreprises à mettre en place des systèmes d’IA plus efficients, par trois pans :
- Une formation Green AI qui vise un public technique assez large, décrite ici
- Une offre plateforme, visant à développer des outils permettant la mise en oeuvre d’une démarche globale Green AI
- Un audit permettant d’identifier des leviers d’actions sur les pratiques et l’organisation