Compte-rendu Petit-déjeuner : Un éléphant qui se balançait … Comment mettre en musique les big data et valoriser les données avec de nouveaux services.
Ce petit-déjeuner était l'occasion pour OCTO de démystifier les big data et valoriser les données avec de nouveaux services.
Retrouvez la présentation complète du petit-déjeuner ainsi que la vidéo de l'événement.
- Témoignage Client BNP Paribas
- Retour d'expérience OCTO-BNP
- Présentation de Digital Studies Vol. 02

1. Témoignage Client: Julien Barbier, Program Director, BNP Paribas
- Quand et comment les initiatives et les projets que nous allons évoquer ce matin ont-ils commencé ? Peux-tu nous rappeler la genèse du programme dont tu t’occupes aujourd’hui et quel était le constat initial ?
Au départ les données étaient dans les systèmes Core Banking et notre première initiative a été de mettre ces données dans un DataLake.
- Aujourd’hui, pour reprendre l’intitulé du petit-déjeuner, la BNP cherche à faire danser l’éléphant des BigData : quels sont les nouveaux services métiers qui sont mis en oeuvre ?
Il y a 3 expérimentations pour 3 uses cases qui sont aujourd’hui en production pour répondre à des douleurs exprimées par le métier.
Le premier consiste à aider les conseillers en agence pour qu’ils puissent préparer leurs entretiens car ils avaient plusieurs dizaines d’onglets dans leur dossier client, ce qui ne favorisait pas une vue synthétique.
Il a été décidé de mettre en place une expérimentation nommée MonRendezVous qui consiste à agréger toutes les données pertinentes dans une vue 360° pour faciliter la préparation des rendez-vous des conseillers en agence.
Le second use case correspondait à la situation où un client arrive en agence sans avoir pris rendez-vous. Dans ce cas il faut des éléments beaucoup plus synthétiques pour être en mesure de comprendre qui est le client et répondre le plus rapidement à ces besoins.
Le troisième use case est plutôt pour les fonctions groupe / corporate qu’on appelle le Personal Finance Management qui permet au client (via différents devices) de mieux gérer son budget. Dans ce cas, il s’agit de récupérer les données dans les différents systèmes, de les concentrer dans un DataLake, puis de les distribuer dans des solutions de stockage de type NoSQL pour y ajouter également des traitements de Machine Learning via un moteur de catégorisation qui permet de rendre plus lisible les libellés des opérations bancaire d’un clients (transport, alimentaire, santé, etc.). Sur cette base on peut faire des approches prédictives pour assister le clients dans la gestion de son compte.
- Peux-tu nous dire quels sont les briques et les framework que vous avez retenus dans l’architecture ? Comment s’est fait ce choix ?
Nous sommes partis des solutions qui faisaient partie de notre catalogue. Au départ, nous sommes partis sur la solution BigInsights for Apache Hadoop d’IBM qui était déjà maîtrisée par les équipes de production. Nous n’étions pas prêts pour faire du temps réel sur toutes la chaînes de traitement des données, nous avons donc travaillé pour récupérer en batch les différentes données des applications du coeur bancaire. C’est au-dessus d’Hadoop que nous avons mis une base NosQL Cassandra pour uploader les données avec une faible latence. Dans la distribution Cassandra de DataStax que nous avons choisi, il y a aussi le moteur d’index SolR ainsi que du Spark (même si ce dernier composant n’a pas été utilisé car pas de besoin de flux temps réel à ce stade).
- La banque est un secteur très sensible aux procédures, est-ce que cela a été une difficulté pour lancer le programme ? Y a-t-il eu une logique d’exception ou un droit à l’expérimentation pour libérer ces initiatives ?
C’est d’abord le fruit d’une bonne collaboration et d’une co-construction entre le métier et l’IT. Puis il y a eu des points plus faciles que d’autres : quand une solution est au catalogue BNP Paribas, c’est plus facile pour avancer (c’était le cas de IBM BigInsights), sur Cassandra il a fallu montrer que cela apportait de la valeur dans le cadre d’une logique d’expérimentation, mais aussi que ce type de produit pouvait répondre aux 4 use case que nous souhaitions développer.
Quoiqu’il en soit, le métier doit accepter que c’est une approche expérimentale, avec des erreurs et des itérations pour arriver à mettre en place quelque chose de nouveau au niveau de l’architecture, mais surtout avec de nouvelles solutions pour répondre aux douleurs du métier.
Tous les processus de suivi et de revue de projets, notamment des gros comité d’architecture métier, on été remplacés par des points plus petits mais aussi plus récurrents (une revue tous les 3 mois plutôt qu’une grosse revue pour initier un projet de plusieurs années)
La logique de co-construction avec le métier a permis d’amener des modes de travail différents : on avait un métier qui était très habitué à des méthodes de type cycle en V mais qui a accepté de mettre des méthodes agiles dans sa façon de travailler. Cela implique que dans le triptyque coût, délai, périmètre, on se met en posture de garantir le coût et les délais mais pas le périmètre. Cela a permis de libérer la parole, de faire en sorte que le métier fasse un vrai travail de priorisation des fonctionnalités.
Cette façon de travailler nous a permis de mettre en place le programme en novembre 2016 pour des premières livraisons en production au mois d’avril 2017. Depuis avril, nous avons des mises en productions tous les mois.
Cela signifie que les équipes de production ont joué le jeu de cette logique de mise en production fréquente à laquelle on est habitué pour des frontaux web, mais beaucoup moins pour des projets orientés data et encore moins Big Data.
- Je crois qu’il y a des équipes mixtes prestataires et BNP : comment cela se passe-t-il ? Y a-t-il un enjeu de montée en compétences des équipes internes ?
Il y a clairement un enjeu de montée en compétences des équipes internes, et pas qu’à la DSI. Cela dit le véritable enjeu n’était pas sur les compétences techniques, mais plus sur le mindset ; il fallait accepter de travailler différemment, et cela pour toutes les parties prenantes. Des expertises de 10 ans sur le Big Data il n’y en a pas vraiment, mais des gens compétents il y en a et il faut miser sur l’appétence de ces profils à travailler différemment et à apprendre en faisant.
Sur l’aspect technologique, on a fait du bottom-up en installant les distributions et voyant comme ça marche pendant un ou deux mois : on a appris sur le tas. Après on a pu composer le bottom-up avec une vision plus top-down pour donner de la visibilité. Donc pas une approche top-down versus bottom-up mais plutôt une composition entre top-down et bottom-up.
Il y a également un gros travail qui est fait dans le groupe BNP Paribas, notamment chez ITG, sur ces nouvelles architectures où on capitalise sur les différentes expérimentations qui ont été menées. L’état d’esprit qui a été le nôtre depuis le début sur ce programme n’était pas juste d'expérimenter mais d’aller vraiment jusqu’à la mise en production avec des solutions qui répondent aux besoins des métiers.
NDLR
[Pour répondre à une question du public sur la contribution de la BNP à la communauté OpenSource dont elle utilise les solutions, Julien Barbier rappelle qu’en choisissant la distribution DataStax, la BNP finance une entreprise qui contribue à hauteur de 75 % à la production du code de Cassandra__.]
- Il y a plusieurs prestataires avec lesquels tu as travaillé : comment positionnes-tu OCTO, quel rôle nous as-tu confié et sur quel périmètre ?
D’abord, nous n’étions pas prêts à développer ces solutions et mettre en place ces architectures en nous appuyant sur des équipes externalisées dans des logiques de nearshore car il y avait plusieurs produits développés en parallèle.
Il fallait nous appuyer sur des compétences fortes sur du delivery et du build de projets qui puissent travailler avec les équipes de la production de la DSI de la BNP qui connaissent les contraintes des architectures existantes. Comme on souhaitait avoir une architecture intégrée avec l’existant, il fallait que les produits développés ne soient pas « hors-sol » et donc que des équipes mixtes Métiers, IT et prestataires puissent travailler ensemble de manière co-localisée.
Le rôle d’OCTO a été de challenger et valider des points critiques d’architecture dès le début, mais aussi d’avoir un mindset pour faire du custom dans une démarche agile qui embarque le métier.
2. Retour d'expérience OCTO-BNP
OCTO présentait le retour d'expérience sur la mise en œuvre de ces nouvelles architectures de données, incluant les technologies Hadoop, Spark, Cassandra, Solr ainsi que des expérimentations sur le Machine Learning, tout en soulignant les méthodes de travail utilisées avec des équipes mixtes BNP Paribas / OCTO.
Retrouvez le détail du REX sur le slideshare.
3. Présentation du Volume 2 des Digital Studies
Le sous-titre de ce volume est la “ question du temps dans les architectures digitales”. Pourquoi la question du temps précisément ? Parce que nous verrons que les bénéfices des architectures distribuées se payent toujours, en retour, d’une certaine complexité dans la gestion du temps.

Quand nous sommes allés voir Camille, au département COM & CREA d’OCTO, et que nous lui avons dit que nous allions publier un deuxième volume des Digital Studies sur les sujets d’architecture technique, de gestion du temps et d’évolution vers les architectures de flux… voilà un peu la tête qu’elle a fait quand on lui a demandé de nous proposer un univers graphique pour l’édition.
Mais nous avons finalement trouvé quelque chose qui nous convenait et qui collait parfaitement avec la problématique. Dès qu’on parle de la pression qu’exerce le temps, c’est le lapin d’Alice au pays des merveilles qui s’impose.
TELECHARGER DIGITAL STUDIES VOL.02
Depuis le film Matrix, le lapin blanc et l’expression “follow the white rabbit” sont devenus le synonyme d’un passage de l’autre côté du miroir (qui est d’ailleurs le titre du roman de Lewis Caroll qui fit suite à Alice au pays des merveilles). Finalement ce parti pris représente bien la ligne éditoriale des Digital Studies.

Il est donc question d’architecture dans ce nouveau volume, mais plus précisément de l’évolution des architectures, depuis les mainframe d’IBM jusqu’aux toutes nouvelles formes d’architecture que sont les architectures de flux.
Nous nous attachons donc aux architectures informatiques dans leur genèse et leur évolution.
Un des marqueurs importants de l’évolution des architectures est l’aspect de plus en plus distribué des composants logiciels : stockage et traitement des données sont disséminés spatialement. Et cette distribution commence à présent au niveau même des processeurs, dans la mesure puisque nous avons à présent des processeurs multicoeurs qui permettent de paralléliser les calculs.

La distribution de plus en plus importante des systèmes nous amène à des situations inédites qui sont caractéristiques des systèmes complexes. C’est à dire des systèmes qui ont des comportement non prédictifs et où il est difficile de connaître l’état global du système à un moment donné.
Voici quelques uns de ces aspects auxquels il va falloir s’habituer avec la complexification croissante des systèmes : 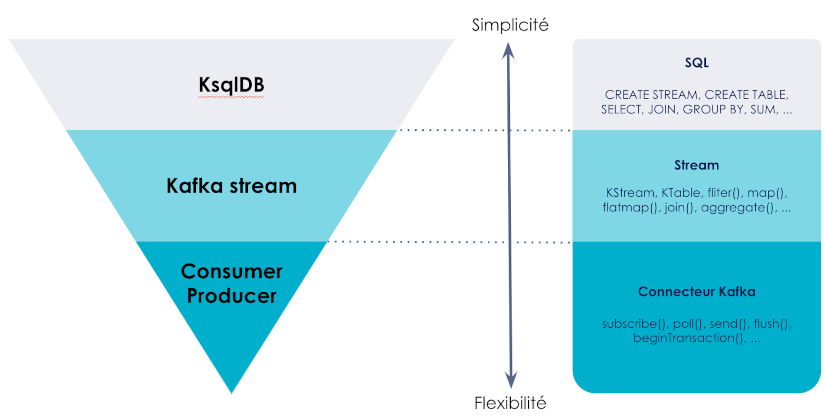
On imagine volontiers qu’Egard Morin se marre, lui qui depuis les années 70 prône une pensée complexe pour comprendre un monde qui va se complexifiant, que ce soit au niveaux des organisations ou des systèmes techniques.
Mais nous n’avons pas attendu pour autant pour trouver des techniques afin de maîtriser la complexité croissante des systèmes distribués.
Dans ce livre blanc nous détaillons ces techniques. Citons d’abord l’approche par les styles d’architecture où nous rappelons qu’un style d'architecture est un ensemble de contraintes que doit respecter une architecture. La maîtrise des styles d’architecture est importante pour toutes les parties prenantes d’un produit digital, aussi bien les développeurs que les architectes et même les acteurs métier. Nous n’hésitons pas à dire que quelqu’un du métier qui ne connaît pas les styles d’architectures des produits informatiques dont il s’occupe ne peut pas faire son métier.
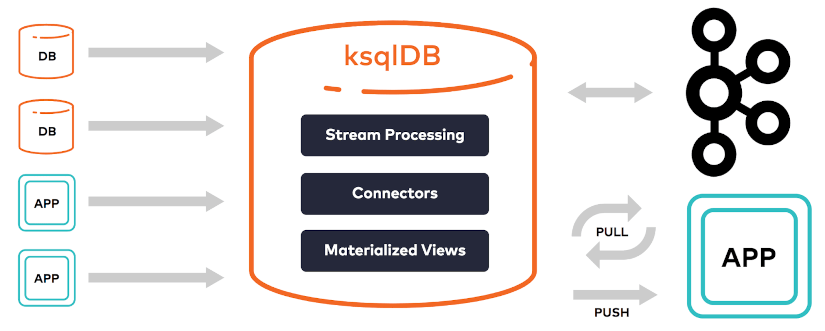
Nous revenons également sur l’importance des logs dans les architectures, qui sont comme le livre de bord des systèmes d’informations. Ce sont des outils puissants et indispensables pour maîtriser la complexité des systèmes distribués, que l’on regarde la place que prend un outil comme kafka dans les architectures de flux.
Il y aussi des travaux de recherche qui ont apporté des solutions pour gérer la complexité des systèmes distribués. Par exemple les travaux de Leslie Lamport, prix Turing 2013, qui a travaillé sur la gestion du temps dans les architectures distribuées, il est le père de ce que l’on appelle l’horloge logique de lamport, a travaillé sur le framework Mesos dont les technologies blockchain sont une implémentation.

Il y a évidemment le théorème CAP démontré en 2002 qui dit que dans un système de stockage distribué des données on ne peut avoir en même temps les trois contraintes suivantes : la résistance au fractionnement du système (P), la disponibilité du système (A) et la cohérence des données (C) :
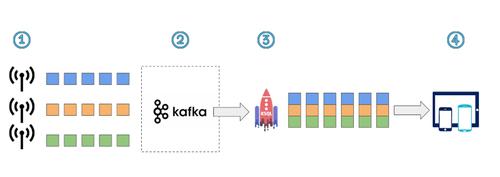
Aujourd’hui, ces systèmes complexes sont notamment utilisés pour traiter des avalanches de data (que l’on pense à loT), où chaque data est un événement en soi, ce qui justifie la dénomination d'architecture event-driven.
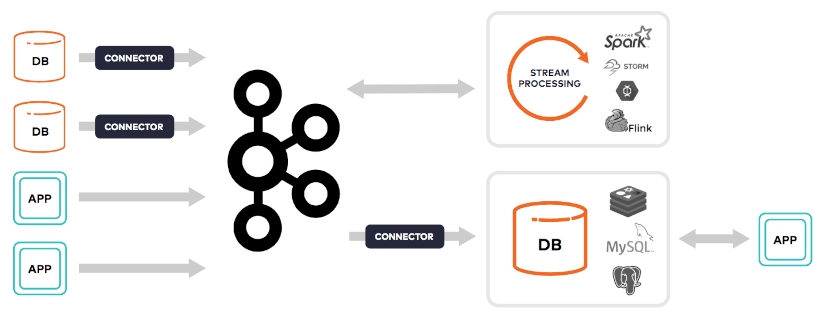
Le traitement de flux d’événements a récemment mis en lumière les moteurs de flux et les architectures de flux qui sont caractérisés, selon Tyler Akidau (Google), par :
- Des Data Sets infinis
- Des faibles temps de latence
- Des résultats approximatifs ou probabilistes

Mais tout le monde a-t-il besoin des ces architectes complexes “dernier cri” ? On connaît l'acronyme YAGNI : “you ain’t gonna need it”. Il est vrai que dans la grande majorité des projets que fait OCTO, tous ne nécessitent pas une telle complexité d’architecture et bien souvent on peut faire beaucoup plus simple.
Il y a donc ce risque de faire de l'Over Engineering et de concevoir une Ferrari là où un vélo aurait suivi.
Enfin, il faut aussi se méfier de la tentation mimétique qui consiste à faire comme les Géants du Web qui sont d’ailleurs souvent ceux qui mettent leur propre frameworks en OpenSource.

Mais quoiqu’il en soit, “ software is eating the world” comme le disait Marc Andreessen. Cela veut dire pour nous que les systèmes technologiques transforment le monde et notre environnement et qu’ils doivent eux-aussi évoluer pour s’ajuster au nouvel environnement. Il y a là un cercle formé de boucles de feedback qui fait que dès qu’un système produit des résultats plus rapidement que les autres, il a tendance à être adopté et à s’imposer.

Dans le domaine bancaire, l’apparition d’un système comptable à faible latence sur le marché imposera son rythme à tous les autres systèmes et la mise en place d’une architecture de flux ne sera pas juste expérimentale mais deviendra réellement critique.
Les streaming engines deviendront mainstream.