Compte-rendu – Le Comptoir OCTO - Comment l’IA générative peut-elle moderniser efficacement vos SI Brownfield ?
Le 27 mai dernier a eu lieu un Comptoir OCTO consacré à la modernisation d’applications à l’aide de l’IA. Nicolas Laurent et Jérémie Klein, tous deux architectes et pionniers de l’utilisation de l’IA générative chez OCTO, y ont partagé leurs expériences et leurs premières conclusions sur cette technologie prometteuse.
En complément de ce compte-rendu, le replay est disponible sur Youtube.
Alors, dans quelle mesure l’IA va-t-elle contribuer à la modernisation de votre SI ?
Introduction
Commençons par un constat : beaucoup d’organisations se débattent avec un existant difficile à maintenir. Le parc applicatif vieillit, sa maîtrise est peu à peu perdue, la documentation manque, les coûts de run explosent… Au point qu’il est souvent plus facile de refaire de zéro que de faire évoluer l’existant.
Dans le même temps, les budgets se restreignent, et les DSI sont poussées à faire plus avec moins : comment alors valoriser cet existant, dans une approche brownfield, sans tout jeter à la poubelle ? Comment faciliter et accélérer des refontes souvent très coûteuses ?
L’IA générative, qui a bouleversé le développement logiciel (et tout le reste !), est une piste de réponse incontournable en 2025. Entre les progrès spectaculaires des modèles depuis un an, leur facilité d’utilisation et leur intégration accrue aux outils de développement, le contexte est favorable à de telles expérimentations… même si les défis restent nombreux : comment interroger efficacement son LLM ? comment s’assurer de la pertinence de ses réponses ? quels outils choisir dans un écosystème si mouvant ? et surtout, quels cas d’usage pour l’utilisation de l’IA ?
Tâchons de nous en faire une première idée à travers quelques retours d’expériences.
Retours d’expériences sur 3 cas d’usage
Nous avons identifié 3 cas d’usages pour l’utilisation de l’IA dans un contexte de modernisation du SI :
- Rétro-engineering : quand on cherche à savoir ce que fait un système sur lequel on a perdu le contrôle.
- Migration de code en tant que dev “augmenté·e” : quand un·e dev utilise des outils d’assistance au développement pour effectuer des tâches de migration de code legacy.
- Migration de code automatique : quand l’IA génère elle-même le code cible.
REX Thoughtworks : comprendre 15 millions de lignes COBOL
Le premier exemple est issu de l’article de Thoughtworks Legacy Modernization meets GenAI, publié sur le blog de Martin Fowler par Alessio Ferri, Tom Coggrave et Shodhan Sheth.
Il s’agit du retro-engineering d’une base de code COBOL, contenant 1500 modules de 10k lignes de code chacun. Sans aide de l’IA, chaque module prend 6 semaines à analyser.
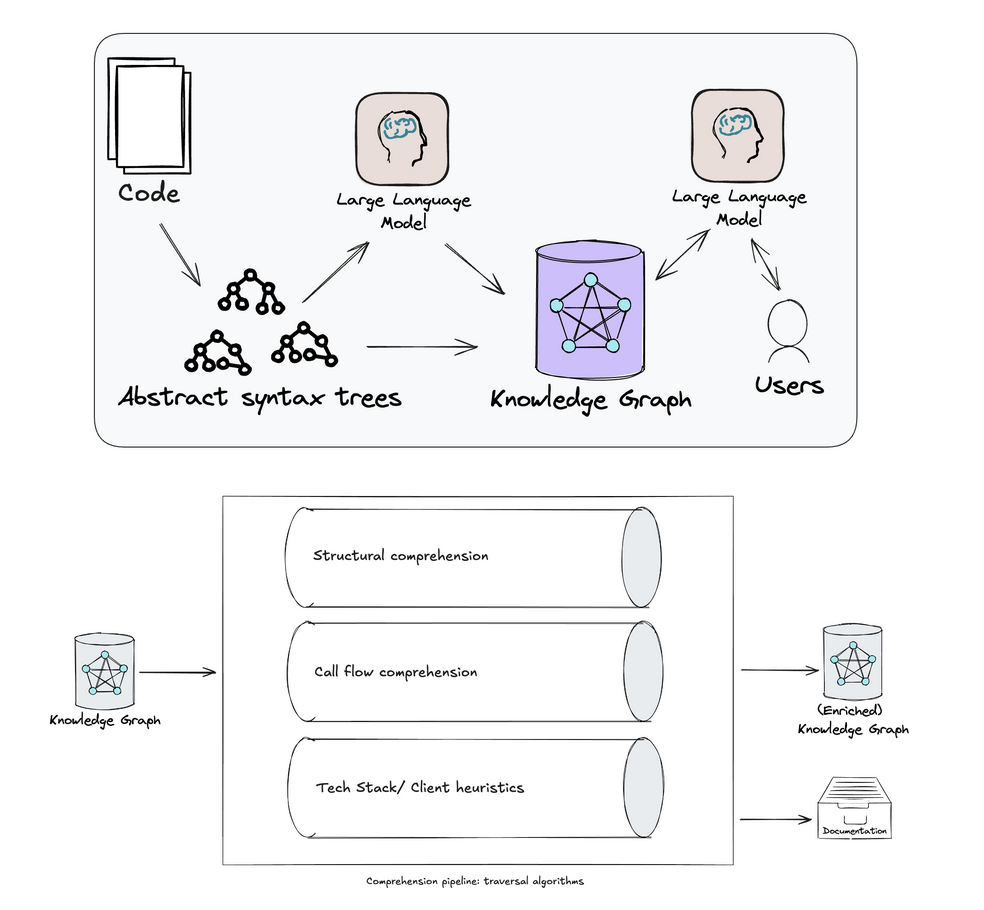
Les équipes de Thoughtworks ont combiné un LLM avec une technologie d’analyse statique existante, les AST (abstract syntax tree), permettant de modéliser un programme informatique sous forme d’arbre d’instructions. Cette analyse par le LLM produit un “knowledge graph”, une base de données qui sert de RAG à un deuxième LLM mis à disposition des experts métier. Ils peuvent ainsi l’interroger en langage naturel pour mieux comprendre la base de code.
Il s’agit donc d’une assistance au retro-engineering par des humains, qui peut être utilisée en complément de méthodes traditionnelles (event storming, analyse statique…).
Thoughtworks considère que l’aide du LLM fait passer de 6 à 2 semaines le temps nécessaire pour analyser un module, ce qui rend le gain très intéressant sur un fort volume de code et justifie la mise en place d’une solution spécifique.
REX OCTO : comprendre une base de code Java complexe
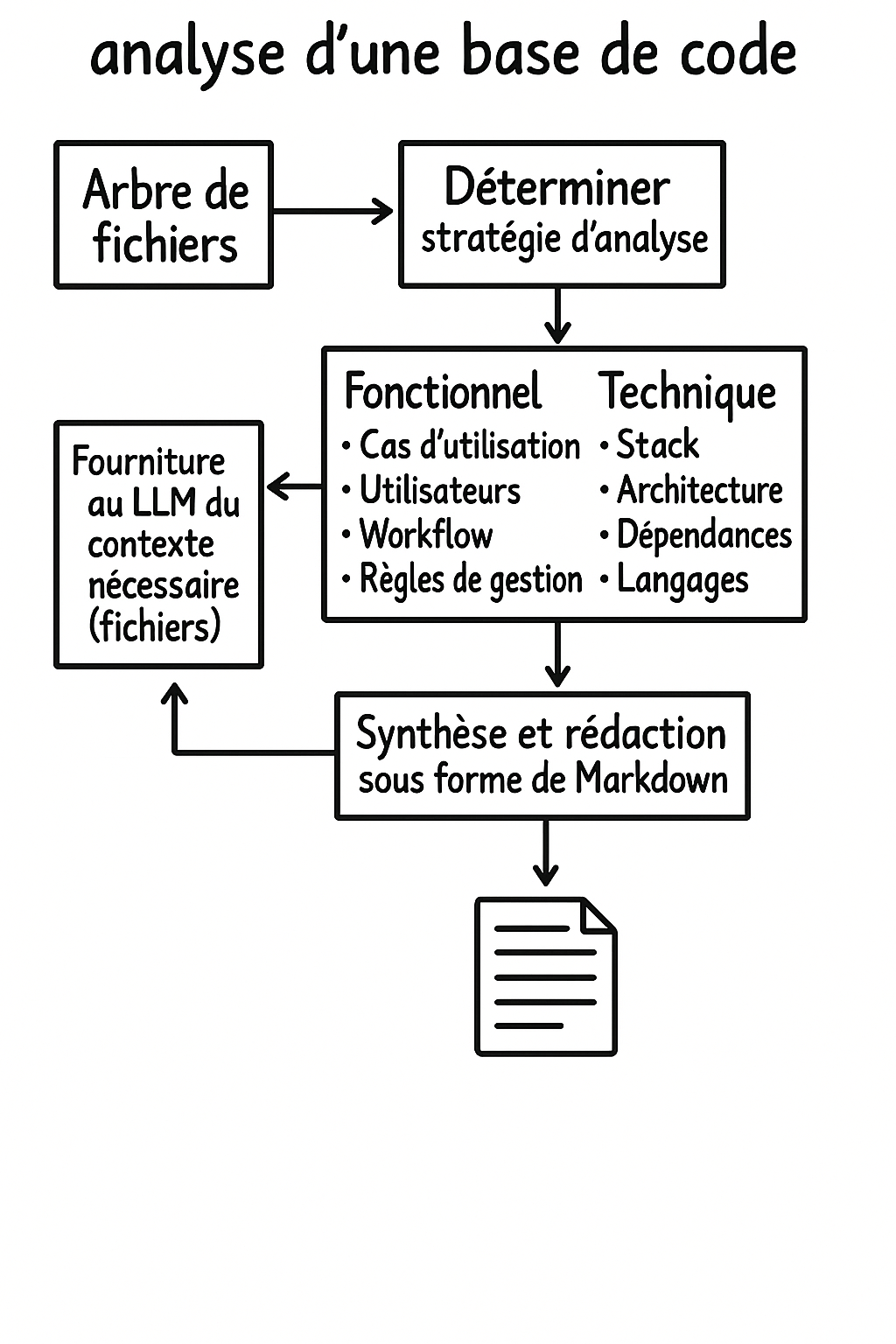
Chez OCTO, nous avons été confrontés à une vieille base de code Java assez complexe : 200k lignes de code, 70 tables et 140 procédures stockées en BDD, plus de 100 écrans… Tout ce qu’on aime !
Il fallait comprendre ce code d’un point de vue technique et fonctionnel, sans accès au métier ou à la documentation.
A l’aide d’un LLM, nous avons procédé par étapes :
- Une analyse automatisée pour avoir une “big picture” du fonctionnement de l’application.
- Une analyse manuelle par des devs, assistés d’outils intégrés aux IDE.
- Une vérification approfondie par carottage de certaines parties du code, pour s’assurer que les conclusions du LLM correspondent à la réalité, et ajuster la stratégie si besoin.
- En sortie, le LLM rédige une synthèse en markdown.
Cet outil nous a permis de retro-engineerer rapidement l’application, et d’estimer l’effort nécessaire pour la moderniser.
REX Airbnb : migrer automatiquement 3500 fichiers de test
Ce retour d’expérience est issu de l’article de Charles Covey-Brandt sur The Airbnb Tech Blog : Accelerating Large-Scale Test Migration with LLMs.
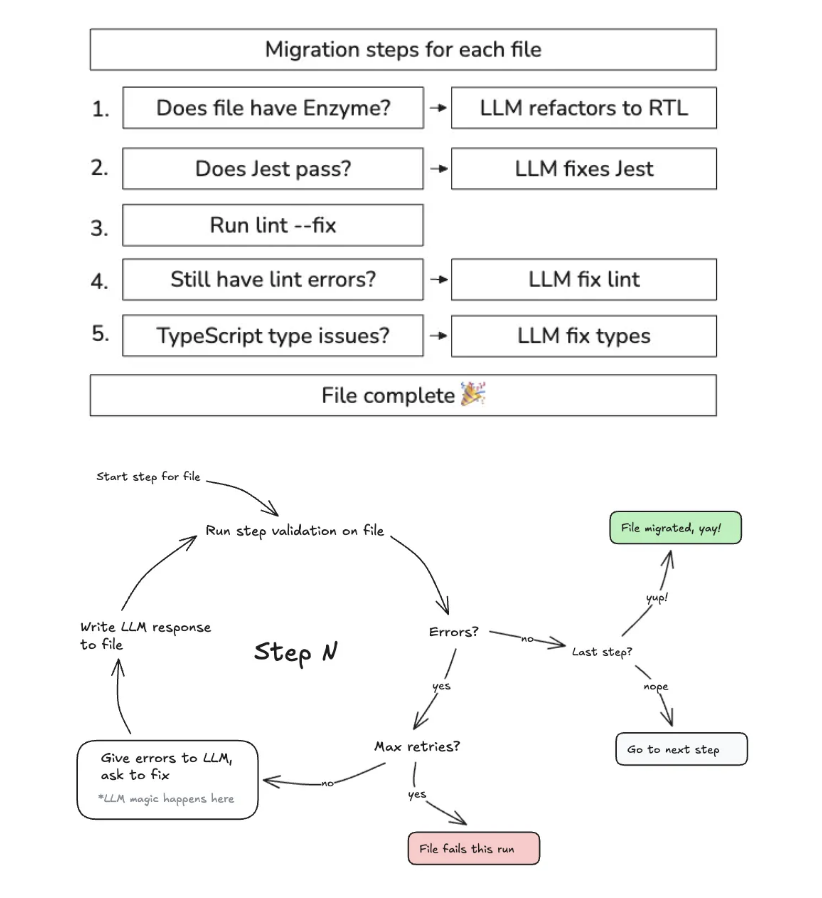
Airbnb a choisi de changer son framework de tests automatisés pour son frontend React, passant de Enzyme à React Testing Library. Que faire alors des 3500 fichiers de test Enzyme ? La migration manuelle était estimée à 18 mois de travail.
Grâce à la mise en place d’une pipeline de traduction automatique s’appuyant sur un LLM, la traduction a été effectuée en 6 semaines : 75% des fichiers ont été migrés dès la première itération, 97% suite à 4 jours d’ingénierie supplémentaire, et les 3% restants ont été migrés à la main.
Ce résultat impressionnant a été obtenu en fournissant beaucoup de contexte au LLM (jusqu’à 50 fichiers connexes en plus de celui à traduire, soit des prompts de 50k à 100k tokens), et en mettant en place une boucle de retry pour raffiner le code obtenu jusqu’à obtenir un résultat satisfaisant. A chaque itération, la pipeline valide que les tests, le linter et la compilation TypeScript passent, et demande au LLM de corriger si nécessaire.
Malgré l’utilisation intensive du LLM avec une consommation importante de tokens, le coût de la migration reste bien inférieur à celui du scénario manuel.
REX OCTO : migrer un client lourd Java en s’aidant de l’IA
Ce cas est représentatif de ce qu’on peut rencontrer chez nos clients : une petite base de code, des technologies anciennes, des librairies plus maintenues…
Nous avons effectué la migration de plusieurs applications de ce type, dont celle d’un client lourd Java de 50k lignes de code. Ici, pas de migration automatique comme chez Airbnb, mais une assistance de l’IA à travers les outils intégrés aux IDE. Même si nous avons demandé au LLM de générer des tests automatisés (en général absents dans la base de code d’origine), des tests manuels sont nécessaires pour s’assurer que l’application se comporte toujours de la même manière.
Dans ce cas, l’humain reste le pilote : il doit avoir suffisamment de recul pour remettre en cause la stratégie de migration proposée par le LLM, se demander s’il ferait pareil à la main, rectifier le tir en cas de besoin… C’est pourquoi ce travail requiert de la séniorité, même (et surtout !) quand on s’appuie sur l’IA.
En accélérant la réalisation de certaines tâches au cours du processus, nous estimons le gain de temps à 60%.
REX OCTO : traduire automatiquement des scripts SAS en Python
Ce dernier exemple provient d’un client possédant une grande quantité de scripts SAS pour manipuler et analyser des données, et souhaitant remplacer cette solution par des scripts Python hébergés sur Dataiku. Il s’agit donc d’une traduction iso-fonctionnelle du langage SAS vers le langage Python, sur un grand volume de fichiers.
OCTO a mis en place une pipeline de transformation s’appuyant sur un LLM, jusqu’au test et au déploiement des scripts dans Dataiku. En plus du code Python, la pipeline produit un rapport sous forme de “fil de pensée”, qui permet de comprendre les étapes de transformation afin de faciliter le debug et d’ajuster l’interrogation du LLM si nécessaire.
En plus d’un gain estimé de 40% à 50% par rapport à une traduction manuelle, l’utilisation du LLM a l’avantage de produire des scripts homogènes en termes de standards et de qualité, en partant d’une base de scripts SAS très hétérogènes.
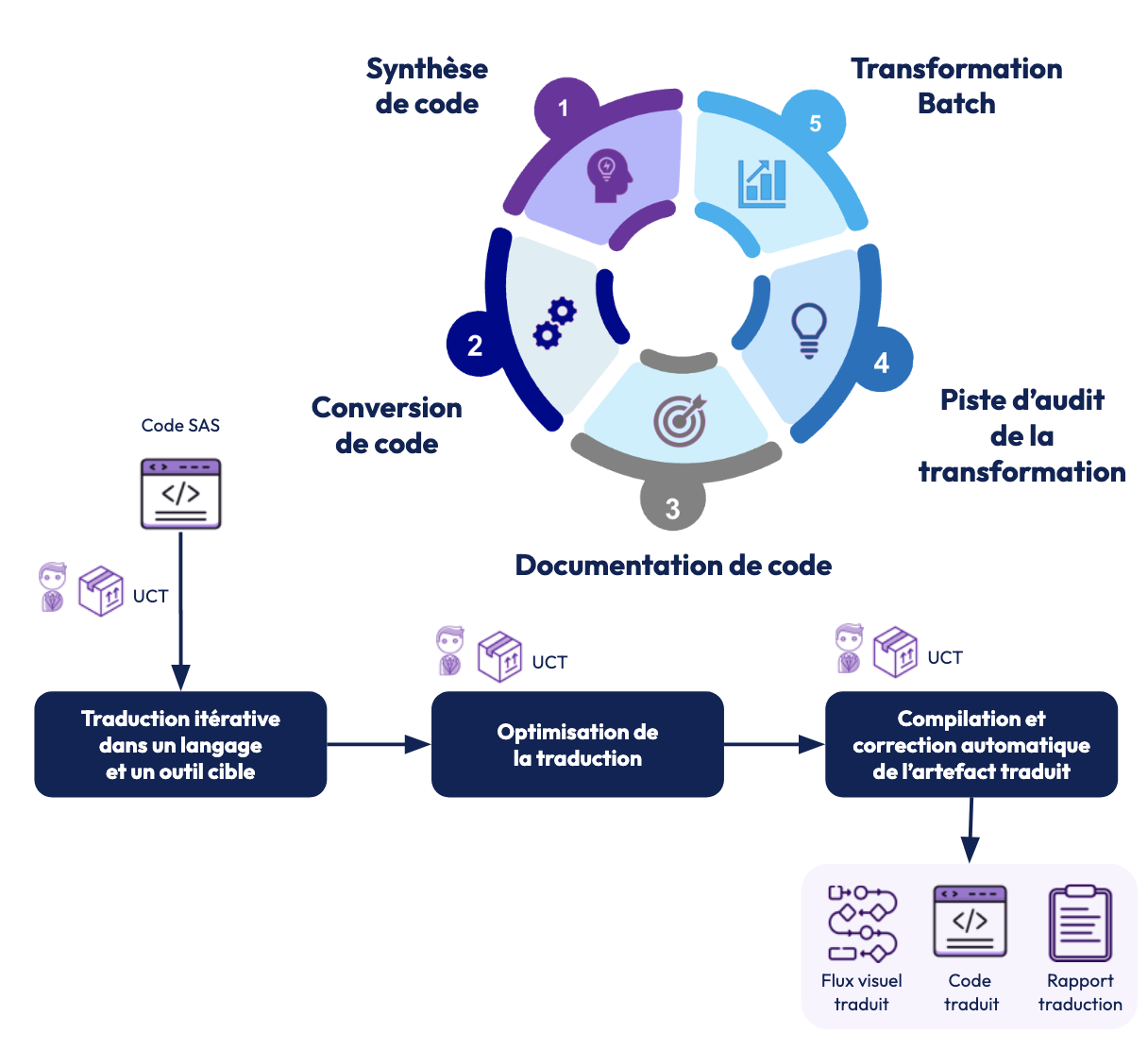
Sur le schéma, UCT est le nom de la pipeline de transformation.
Nos apprentissages
Suite à ces différentes expérimentations, nous avons dégagé quelques grands enseignements concernant l’usage de l’IA dans les travaux de modernisation du SI.
Le ROI est certain, mais difficile à chiffrer
Même si un gain est constaté dans l’ensemble, il dépend beaucoup du cas d’usage, des outils choisis, de l’expérience de l’équipe…
Il faut bien sûr prendre en compte le coût d’ingénierie pour la mise en place de la solution, et le coût du LLM lui-même !
Le bon outillage est un facteur-clé de succès
Choisir le bon LLM, le bon IDE, le bon prompt fait toute la différence.
De notre expérience, les acteurs les plus mainstreams sont les plus performants (Claude Sonnet, Gemini…). Nous avons constaté une qualité de résultat moins bonne pour des modèles open-source plus confidentiels. Ce choix peut aussi être contraint par des enjeux de souveraineté ou de confidentialité, auquel cas on peut envisager d’héberger son propre LLM open-source chez un cloud provider sur des tenants européens (AWS, Azure…).
En ce qui concerne l’assistance au développement, nous recommandons des outils complètement intégrés aux IDE comme Cursor (en version payante) ou Cline, un plugin pour VS Code permettant de choisir le LLM à interroger (y compris des LLM privés). Ces solutions se démarquent notamment du plus mainstream GitHub Copilot. Attention cependant aux coûts de licence et d’utilisation !
Notons que l’automatisation de certaines tâches à l’aide de l’IA passe par du code dédié : il ne faut pas hésiter à développer ses propres outils, dédiés à la tâche qu’on veut réaliser.
Enfin, rappelons que la qualité du prompt est fondamentale, et qu’il faut consacrer du temps à l’améliorer jusqu’à obtenir un résultat satisfaisant.
Exploiter toutes les sources de données
Quand on parle de LLM dans le cadre du développement logiciel, il est évident de donner du contexte au LLM à partir de la base de code.
L’expérience montre qu’il ne faut pas négliger les autres sources de données de l’entreprise, qui sont aussi à même de nourrir le modèle avec de l’information pertinente : documents Word ou PowerPoint, PDF ou autres vidéos.
Des solutions existent déjà pour transmettre ces différents formats à un LLM : markitdown pour les documents Office, MuPDF pour les PDF, Whisper pour transcrire des contenus audio et vidéo…
Piloter l’IA, et non l’inverse !
Les premiers résultats obtenus grâce à l’IA sont parfois spectaculaires, mais attention à ne pas prendre la confiance !
Il faut toujours s’assurer que le résultat est conforme à l’attendu, et itérer dessus jusqu’à être pleinement satisfait. A vous de rester maître de l’IA, de l’emmener là où vous voulez aller et non l’inverse.
Piloter l’IA est donc un vrai travail d’ingénierie, qui requiert de la séniorité.
L’IA produit du code de qualité… si on le lui demande
Contrairement aux outils historiques de transformation de code automatique, les LLM ont la capacité de produire du code de qualité, testé et maintenable dans la durée. Mais encore faut-il l’orienter dans ce sens !
Un prompt très simple (“génère une fonction qui calcule la TVA”) donnera un résultat non seulement basique, mais aussi très aléatoire, car le LLM peut répondre à la question de multiples façons.
A l’inverse, il est possible d’obtenir un résultat beaucoup plus déterministe, et respectant la qualité de code attendue, avec un prompt plus complet : préciser l’intention de la fonction, les cas de test, lui fournir de la documentation sur les standards de code, des exemples de code, etc.
Encore une fois, cet exercice requiert de la séniorité dans le domaine du développement, car il faut avoir une bonne vision du résultat désiré et rester critique de ce que l’IA propose.
Il ne faut pas hésiter à s’inspirer des nombreux exemples de prompts partagés ici ou là, par exemple x1xhlol / system-prompts-and-models-of-ai-tools.
Conclusion
Pour nous, la conclusion est nette : sur ces cas d’usages, l’IA fonctionne et on ne veut pas revenir en arrière.
Alors, voici quelques conseils pour vous lancer à votre tour :
- Identifiez un cas d’usage sur un périmètre restreint, comme du retro-engineering ou de la migration de technologie. Expérimentez d’abord sur un périmètre simple afin de vous approprier les outils.
- Choisissez vos outils, en restant dans les solutions mainstream (Claude Sonnet, Gemini, Cursor…), tout en prenant en compte vos contraintes de souveraineté.
- Trouvez le bon casting : identifiez les early adopters, des personnes motivées par l’IA mais avec un profil de dev senior pour pouvoir prendre du recul et challenger l’IA.
- Expérimentez et itérez : investissez quelques jours, faites le bilan, améliorez les prompts, changez de sujet si cela ne marche pas…