Compte-Rendu de Matinale : Levez la malédiction du passage de l’IA en production
Jeudi 29 novembre, l’équipe Big Data Analytics, en charge des sujets d'Intelligence Artificielle à OCTO Technology, a présenté au cours d'une Matinale sa vision de l'industrialisation de l'IA (voir la vidéo de la Matinale, obtenir les slides).
L’IA, actuellement portée par la hype, est un buzzword qui veut souvent dire tout et n’importe quoi. Data scientists, métiers, marketing, utilisateurs, etc. chacun y va de sa définition. Nos clients se retrouvent avec des POCs d’applications d’IA sans fin qui peinent à être industrialisés et à être intégrés dans le SI.
A travers cette matinale, l’équipe Big Data Analytics d'OCTO nous propose son expérience sur l’industrialisation des applications d’IA et nous présente, de façon pragmatique, les patterns organisationnels, méthodologiques et techniques à adopter pour construire une IA utile et qui marche en production.
LES BONNES PRATIQUES À ADOPTER
DÈS LA PHASE D’EXPLORATION
Il y a plusieurs paramètres dans la production d'IA : business, scientifique et technique. La mise en commun de tous ces paramètres fait qu’on se retrouve dans un système complexe et d’incertitudes. Adopter les bonnes pratiques dès la phase d’exploration permettra de réduire cette complexité et ainsi le time to market.
Les choix d’algorithmes et de métriques sont poussés par les besoin métiers, les KPIs métiers, la disponibilité des données, la capacité d’annotation et la fréquence des données entre autres. Les métiers et les data scientists doivent travailler main dans la main afin de produire une IA utile.
Un autre volet qui peut introduire de la complexité est le choix de l’algorithme. Par exemple, un algorithme de deep learning coûte cher. Parfois une simple régression linéaire peut mieux performer. Pensez-y donc avant de vous lancer dans les choix d’algorithmes complexes souvent inutiles.
Une fois qu’on a construit notre POC simple, il faut tester rapidement en production afin d’éviter d’avoir une multitude de POCs qui ne tiennent pas compte de la réalité. Construire un POC simple, c’est faciliter le passage en production régulier et c’est réduire la boucle de feedback avec les utilisateurs. Le mauvais pattern méthodologique est de construire un POC tous les jours sans passage en production.
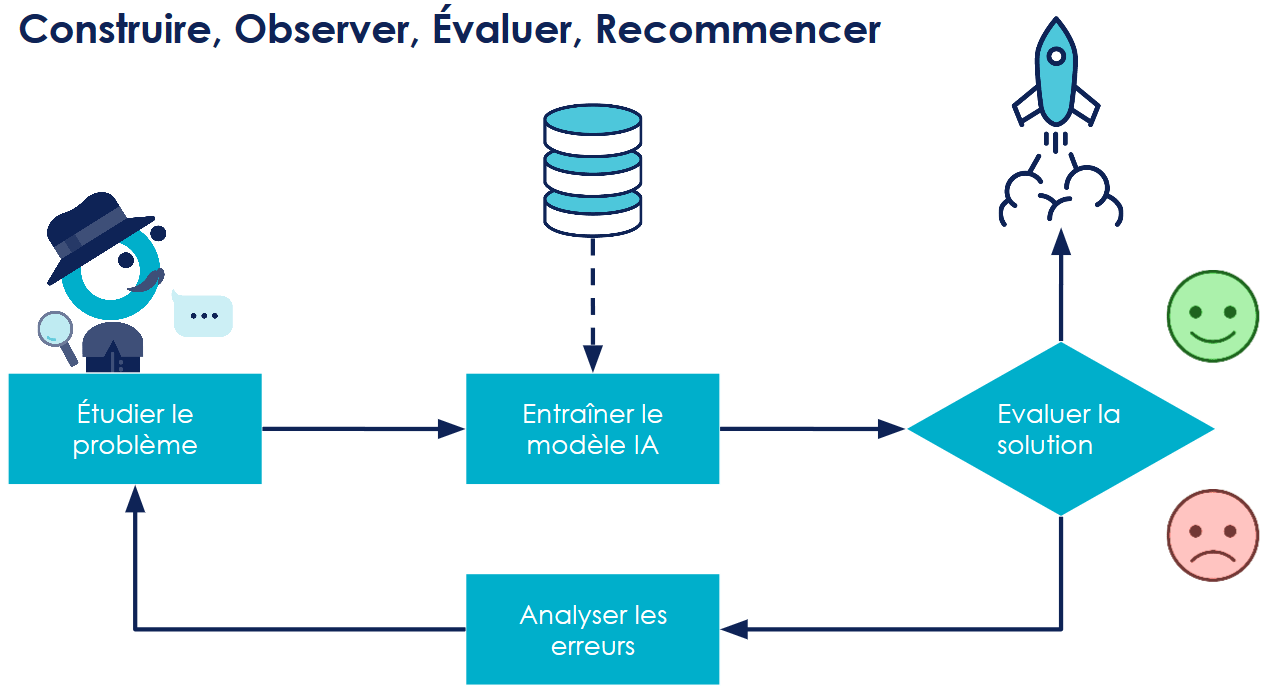
DE L’EXPLORATION À LA PRODUCTION, PAR LE BIAIS DE L’INDUSTRIALISATION
Lorsqu'on commence à faire de la data science, on commence par faire un workflow simple puis on se rend compte qu’il a une valeur métier, et perdre cette valeur peut parfois avoir des effets dramatiques. Comment faire donc pour pérenniser cette valeur métier ? Adopter les bonnes pratiques d’industrialisation c’est assurer la pérennisation de la valeur de notre application.
Une entreprise idéale verrait ses applications d'IA accomplir en continu des tâches à forte valeur ajoutée métier. La donnée étant la fondation de l'IA, cela la suppose fiable, un minimum mature et permettant une parfaite description de l'entreprise.
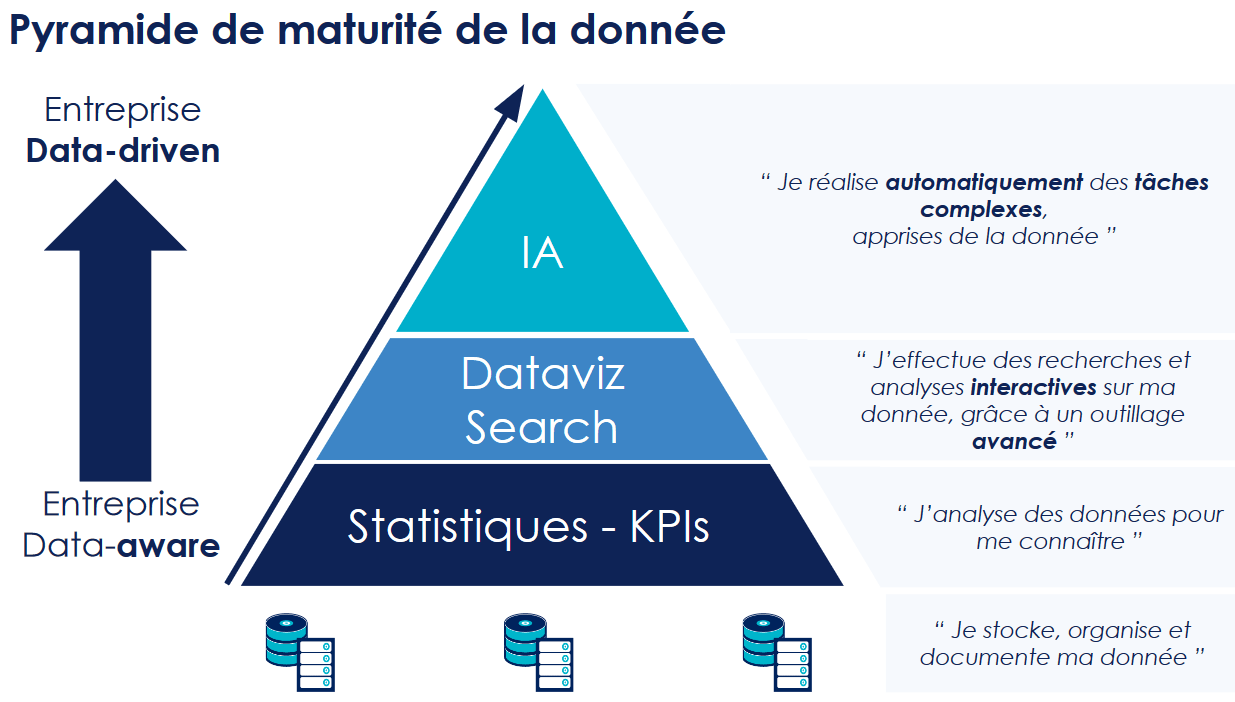
La construction de l'IA passe donc par une compréhension et une maîtrise de notre système de données. Autrement, cela confine à l'anti-pattern de l'IA instable et inutile à terme. Toutefois, il faut éviter de tomber dans le piège du sur-design et juste se concentrer sur la maturation des sous-périmètres strictement nécessaires au départ.
Pour ce faire, il est nécessaire d’adopter une méthodologie projet itérative qui tient compte dès le départ des efforts de production et d’industrialisation. La seule garantie de la qualité s’obtient par l’industrialisation : adoptez les bonnes pratiques projet et armez-vous d’outils nécessaires. Un anti-pattern serait de négliger les efforts d’industrialisation au début du projet car cela aurait à coup sur des retombés néfastes à long terme. Il faudrait les traiter dès le départ.
Un modèle de ML, c’est d’abord du code. Les bonnes pratiques crafts de code et de devops s’appliquent donc aussi aux modèles de ML moyennant quelques ajustements.
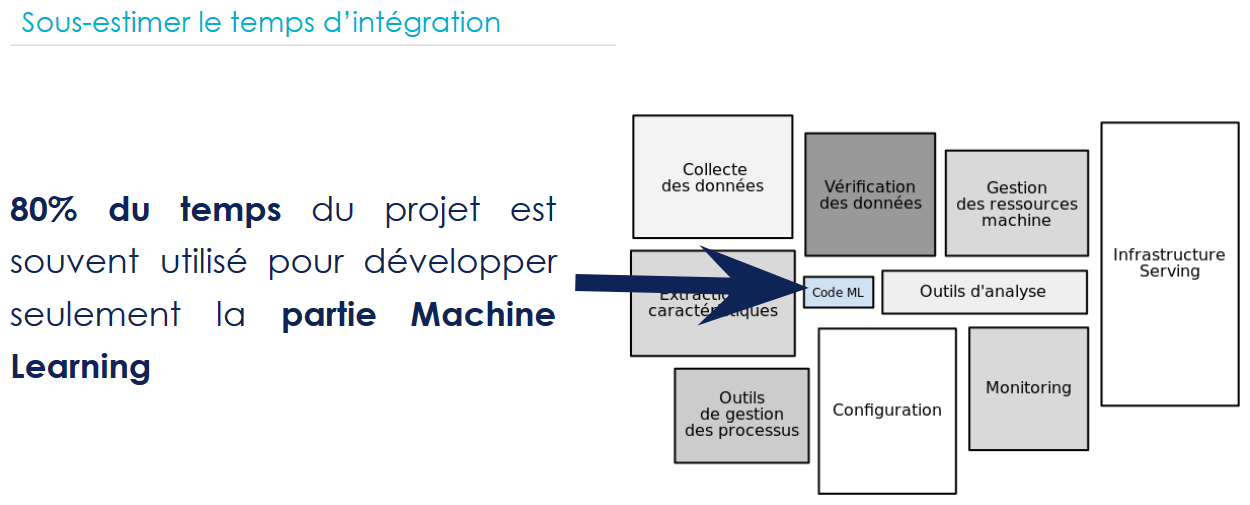
Le choix et l’utilisation d’outils adaptés est un élément crucial car l’écosystème d’outillage d’une industrialisation efficace peut très vite devenir complexe, comme l’illustre la figure ci-dessous :
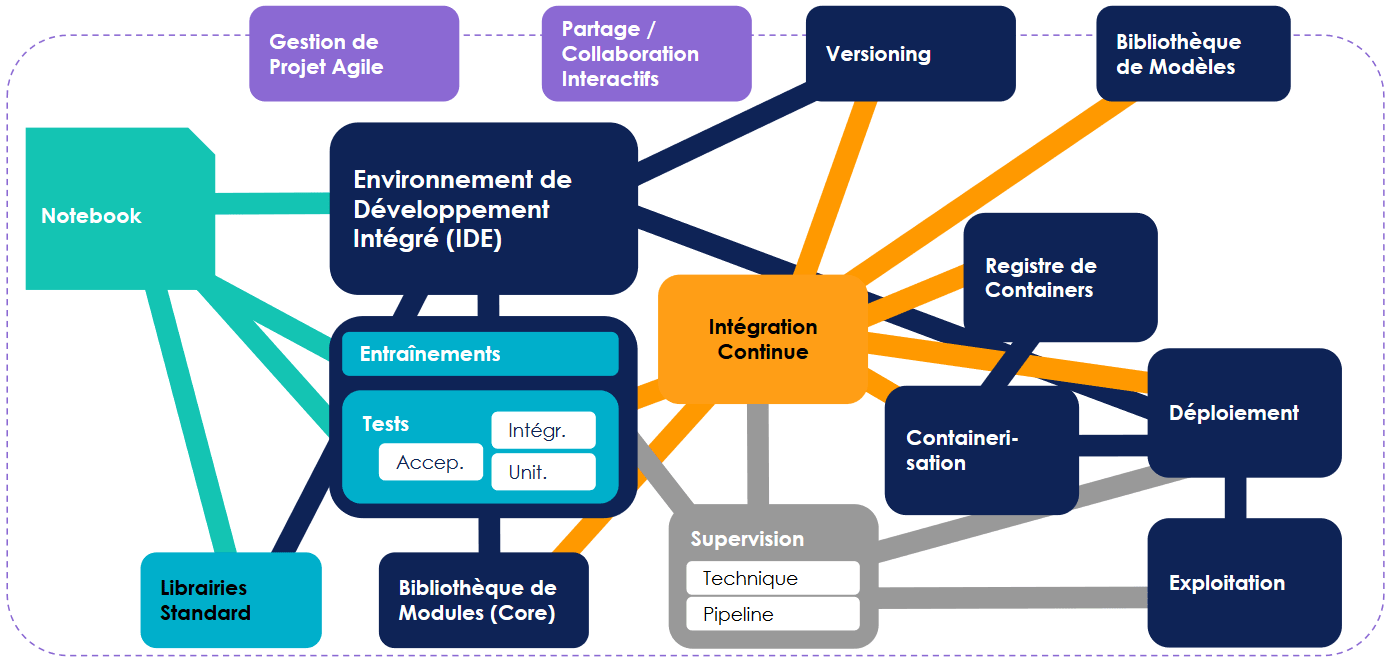
Idéalement, il faudrait un outil permettant l’intégration au mieux de cet écosystème.
Enfin, les applications IA évoluent rapidement et nécessitent l’adoption des meilleures pratiques de développement logiciel couplées avec le devops et l’agilité.
L'INTÉGRATION DU MACHINE LEARNING DANS LE SI
Le machine learning, ce n’est pas de la magie : c’est avant tout du code ! Et en tant que tel, il est destiné à faire partie du SI d’entreprise. Cependant, il apporte son lot de complexité et des problématiques différentes de ce que l’IT ou la DSI a souvent l’habitude de voir. Ce qui rend son intégration plus délicate. Il faut donc s’intéresser aux problèmes prioritaires et les traiter un à un.
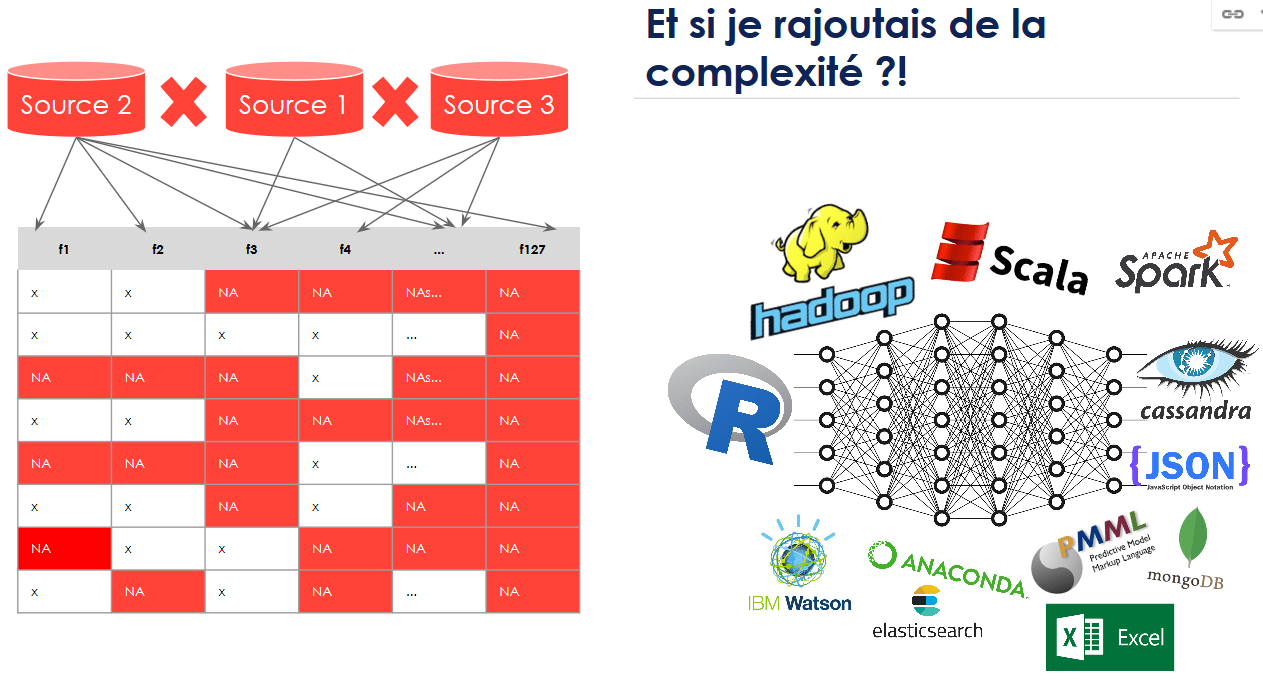
La donnée est à l’entrée d’un workflow de machine learning : c’est le nerf de la guerre. Sans une source de données fiable, on peut induire une grande marge d’erreur dans notre ML. Il est donc important de traiter les problématiques associées en top priorité. Par exemple, une des problématiques récurrentes qu’on observe dans le cas des données multi-sources, est la différence des échelles des différentes sources.
Si j’ai une source de données dont la fréquence est à la journée et une autre qui est trimestrielle, comment les agréger ? Quid des NA ? Très souvent, ce qu’on observe chez nos clients, c’est qu’au lieu de traiter les problèmes un à un, on se rajoute de la complexité (“Tiens, et si je partais sur un CNN multi-layers dans un écosystème Hadoop, le tout en bash ?”)
La top priorité est de brancher le modèle le plus rapidement possible aux différents flux de production quitte à favoriser la compréhension du modèle au détriment de sa performance, car il est impossible d’anticiper les problèmes, en l’occurrence ceux liés à la donnée. Plus vite on s’intègre au SI, mieux on anticipera les coûts d’intégration. Souvent ce qu’on observe est que 80 % du temps est utilisé pour développer la partie machine learning au détriment de l’intégration. On se retrouve à faire 80 % supplémentaires consacrés à l’intégration !
Intégrer, ça prend du temps ; il faut prendre ce temps là dès le début. Atteindre un niveau de SLA élevé passe par une phase d'industrialisation coûteuse. Il faut donc piloter ses métriques, ajuster le ROI et rembourser sa dette régulièrement, car la maturité vient avec l’usage.
Cependant, selon la loi de Conway, « les logiciels sont le reflet des organisations qui les ont construits ». Afin d’intégrer le plus tôt possible, il faut installer l’organisation qui va avec, adopter les bonnes pratiques et les bons outils dès les phases d’exploration.
L'ORGANISATION
Le premier piège à éviter est le silotage. Chaque partie du projet (data scientists, métier et IT) a des intérêts spécifiques.
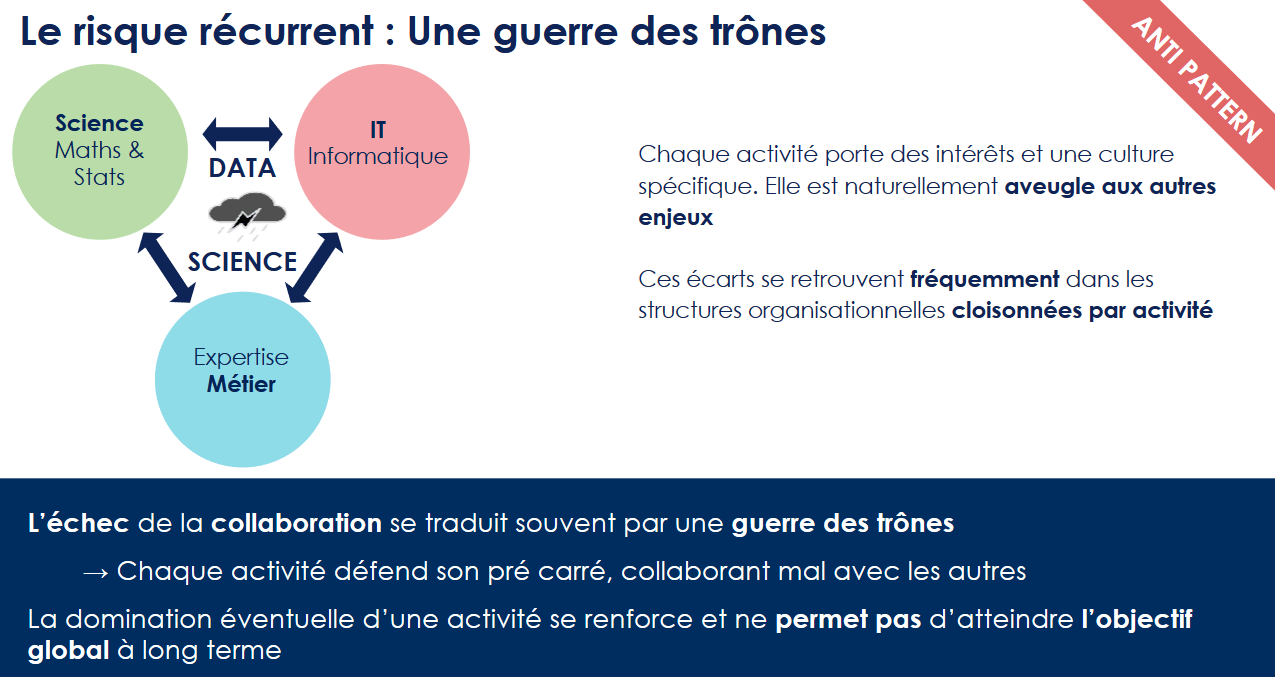
La solution est de construire des features teams, qui partagent des objectifs communs et qui mélangent ces trois profils au quotidien.
DATA DRIVER
Depuis 2015, nous développons un produit à OCTO Technology : Data Driver. Cet outil est le fruit de la capitalisation de toutes nos missions de Data Science. Il est destiné à aider nos équipes à minimiser le temps d’industrialisation des use cases tout en assurant des fonctionnalités poussées telles que le déploiement continu, la reproductibilité et le monitoring fonctionnel des applications IA, pour ne citer que celles-ci. Le socle technique de Data Driver se base sur des projets opensource, dont Airflow pour le scheduling et le monitoring des workflows, ainsi que Docker pour la conteneurisation. Le retour d’expérience sur l’utilisation de Data Driver chez Total en illustre les capacités.
LES RETOURS D'EXPÉRIENCE
Deux retours d’expérience de projets data science ont été présentés dans cette matinale. Les recommandations présentées dans cette matinale par l'équipe Big Data Analytics ont été appliquées dans le cadre de ces use cases et ont permis d'optimiser l'efficacité de l'industrialisation de ces derniers.
REX OPTIMISATION DE CAMPAGNE DE MARKETING
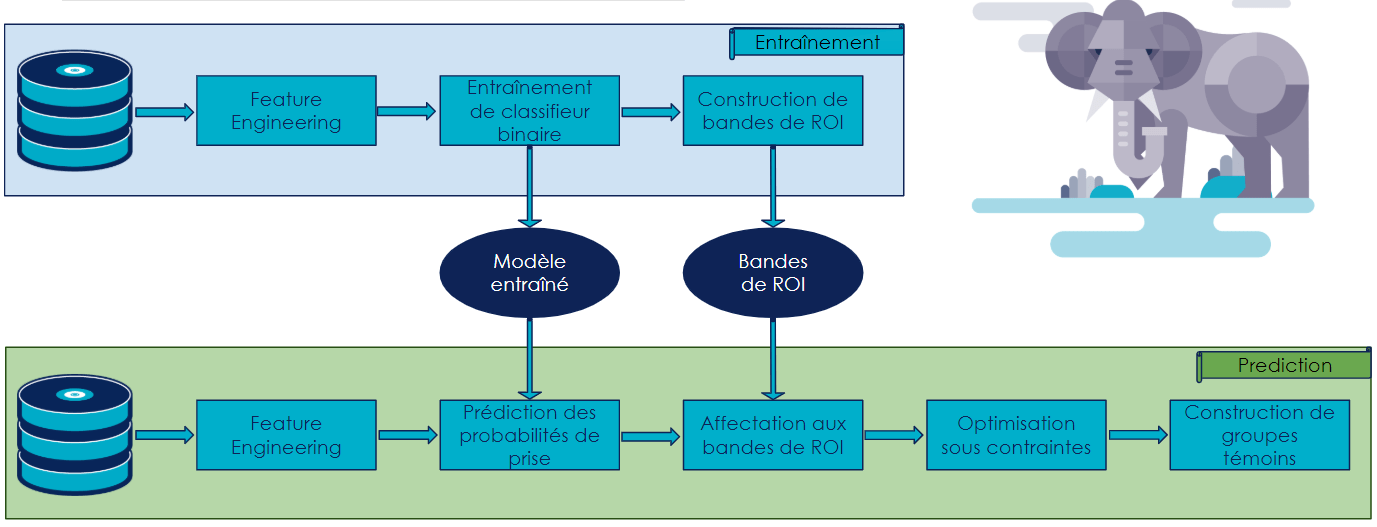
Le premier retour d'expérience concerne l'optimisation d'une campagne marketing dont l'objectif était de déterminer quel client démarcher et sur quel canal pour optimiser le ROI de sollicitation. Pour ce faire, on a utilisé une modélisation uplift (qui se trouve avoir été utilisée lors de la campagne d'Obama en 2008) en exploitant une métrique propre à ce type de use case : l'AUUC (Area Under Uplift Curve). De même qu'un éléphant se mange par petites bouchées, la solution finale (cf. schéma) s'est construite de façon itérative sur quatre POCs, en rencontrant le métier à chaque POC le plutôt possible pour valider conjointement les KPIs et optimiser le modèle. Chaque POC a été mis en production et testé en conditions réelles (en Espagne). Une fois que les performances du système manuel (déjà en place) ont été surpassées, le déploiement à travers le monde a pu débuter : Bulgarie, Brésil, etc., tout en tenant comptes des spécificités locales.
REX TOTAL
Chez Total, plusieurs applications IA sont déployées en production. Leur mise en production est sujette à un ensemble de critères : la validation d’un use case business, l'intégration de l'agilité et du métier dans la projet, la démystification de l'IA auprès des utilisateurs et enfin la facilitation des décisions opérationnelles pour ces derniers.
Voilà maintenant près de 3 ans qu'OCTO accompagne Total sur ce use case industriel : la maintenance prédictive des pompes submersibles (ESP) destinées à la remontée de fluide sur des puits de production. Ces équipements sont critiques car en cas de panne le puits ne fonctionne plus et cela entraîne des pertes conséquentes en termes de ROI. Prédire ces pannes à l'avance permet d'augmenter le temps de vie des ESP et d'optimiser les opérations logistiques. L'objectif de l'IA est de ce fait de remonter les risques de panne pour permettre aux équipes d'adopter la stratégie de maintenance la plus efficace.
Le POC du projet a été effectué pour un premier pays (10 ESP, une centaine de modèles par puits) en utilisant des données de capteurs. Après plusieurs itérations, des résultats intéressants ont été produits et s'en est suivi la question du passage à l'échelle pour déployer sur plusieurs pays. En effet, passer à 3 pays implique une centaine d'ESP, ce qui implique le déploiement de milliers de modèles. Comment gérer cette complexité en production, le tout en agilité ? Comment garantir la reproductibilité entre l’exploration et la production ? Ce "scaling" a été rendu possible par l'adoption de Data Driver dès le POC, notamment grâce à la richesse de son socle technique, ses capacités de scheduling et de monitoring de workflow ainsi que l'intégration naturelle de Docker dans un environnement du Cloud Azure comme en témoigne l'architecture cible ci-dessous :
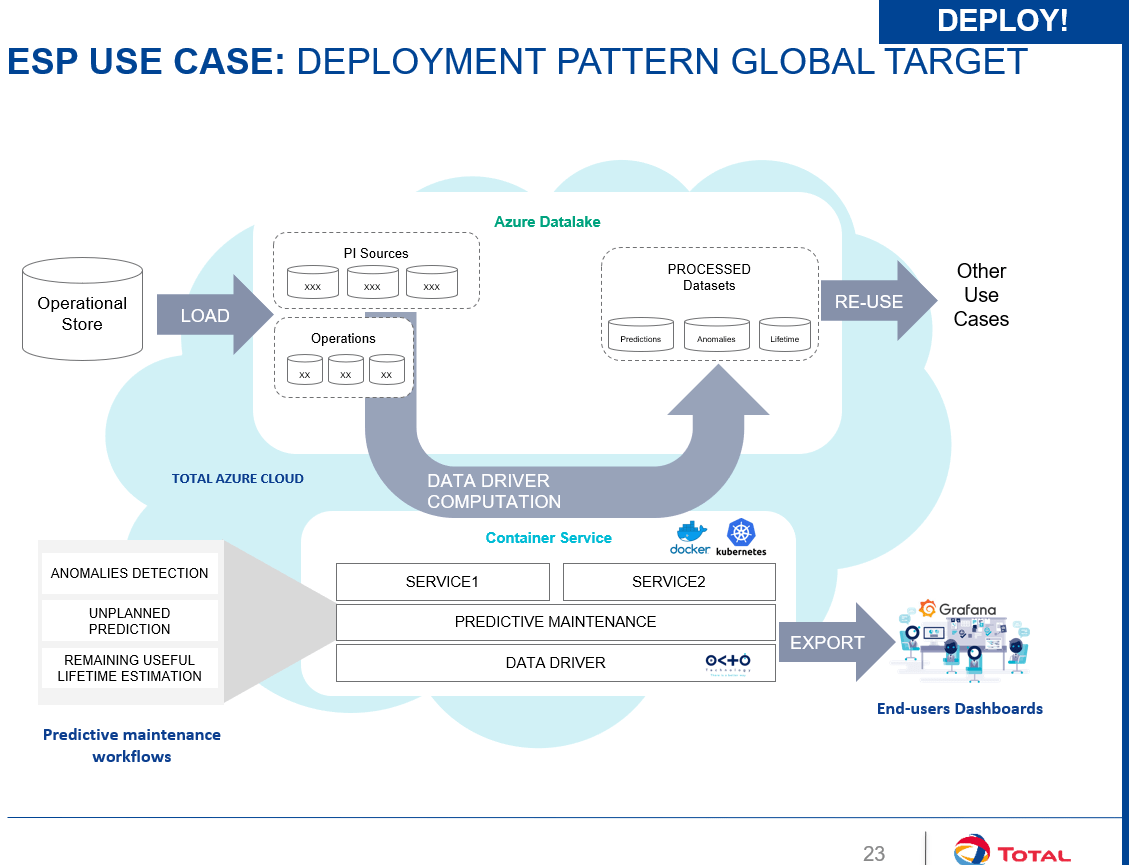
Les points d'apprentissage cruciaux de Total sur ce projet sont surtout : l'organisation en feature teams, l'adoption des pratiques craftsmanship et devops par les data scientists qui a facilité la prise en main de tout cet environnement complexe, l'importance des challenges d'intégration dans le système d'intégration et les choix technologiques judicieux effectués dans Data Driver.
TAKEAWAY
Très souvent, quand on parle d’IA on ne pense qu’à son cas d’utilisation (qui n’est que le dessus de l’iceberg) et on néglige sa face cachée ainsi que tout le lot de complexité avec lequel elle vient. Et c’est au moment de l’intégration dans le SI qu’on se rend compte de sa complexité, mais il est déjà trop tard.

Il est primordial de commencer simple et de se connecter rapidement aux flux de production pour se rendre compte des vrais problèmes et de les traiter par priorités. L’adoption des bonnes pratiques organisationnelles, méthodologiques et techniques dès le début du projet permet de réduire le time to market.
C’est donc l'appréhension de la face cachée de l’IA qui est le secret d’un passage en production réussi.