Compte-rendu de la Duck Conf 2023 : La vie d’Ops au cœur d’un SI en évolution
Cet article est un compte-rendu d’un talk donné à la Duck Conf en 2023. Nos deux speakers d’OCTO Technology, Roberto Duarte - Ops/SRE et Hông Viêt Lê - Tech Lead Ops, nous font un retour d’expérience sur une mission de refonte d’un SI : quelles ont été les décisions prises, leurs conséquences sur une équipe, sur un produit et une infrastructure.
J'ai trouvé ce talk particulièrement intéressant car il permet de revivre les événements marquants d’un projet ambitieux et complexe et de se projeter dans l’histoire racontée, afin de suivre toutes les péripéties de cet attachant duo.
Nos deux orateurs abordent également leur contexte en mission, la stratégie cloud choisie, les réorganisations mises en place et leur top 3 des pratiques SRE, parmi celles adoptées dans l’équipe. De quoi repartir le soir avec les poches toutes pleines d’astuces, mais aussi avec un regard neuf et des idées nouvelles.
Avant tout, une photo du meilleur profil de nos deux intervenants :

Hông Viêt Lê - Tech Lead Ops - à gauche et Roberto Duarte - Ops/SRE - à droite
Magnifique.
Bon, revenons au talk, il est découpé en trois chapitres :
la jeunesse, soit la découverte du contexte de la mission ;
l'adolescence et les crises qui l'accompagnent ;
la maturité, c’est-à-dire la maîtrise du sujet afin d’aller plus loin.
La jeunesse et l’insouciance
Il y a un peu plus de 3 ans, un client confie une mission aux équipes d’OCTO : la refonte et la modernisation d'un système d'information de plus de 25 ans. Il souhaite également se faire accompagner dans ses premiers pas vers le Cloud, séduit par la promesse d’une vélocité bien plus accrue du provisionnement des environnements.
1er objectif : valider le plan de refonte en commençant par un périmètre fonctionnel réduit, impactant et défini en amont avec le client pour éviter une approche Big Bang.
Une équipe pluridisciplinaire est montée afin d’analyser et travailler sur les enjeux fonctionnels, techniques, d’architecture, de déploiement et d’exploitation. Cette équipe est autonome et responsable du développement jusqu’à la production comprise.
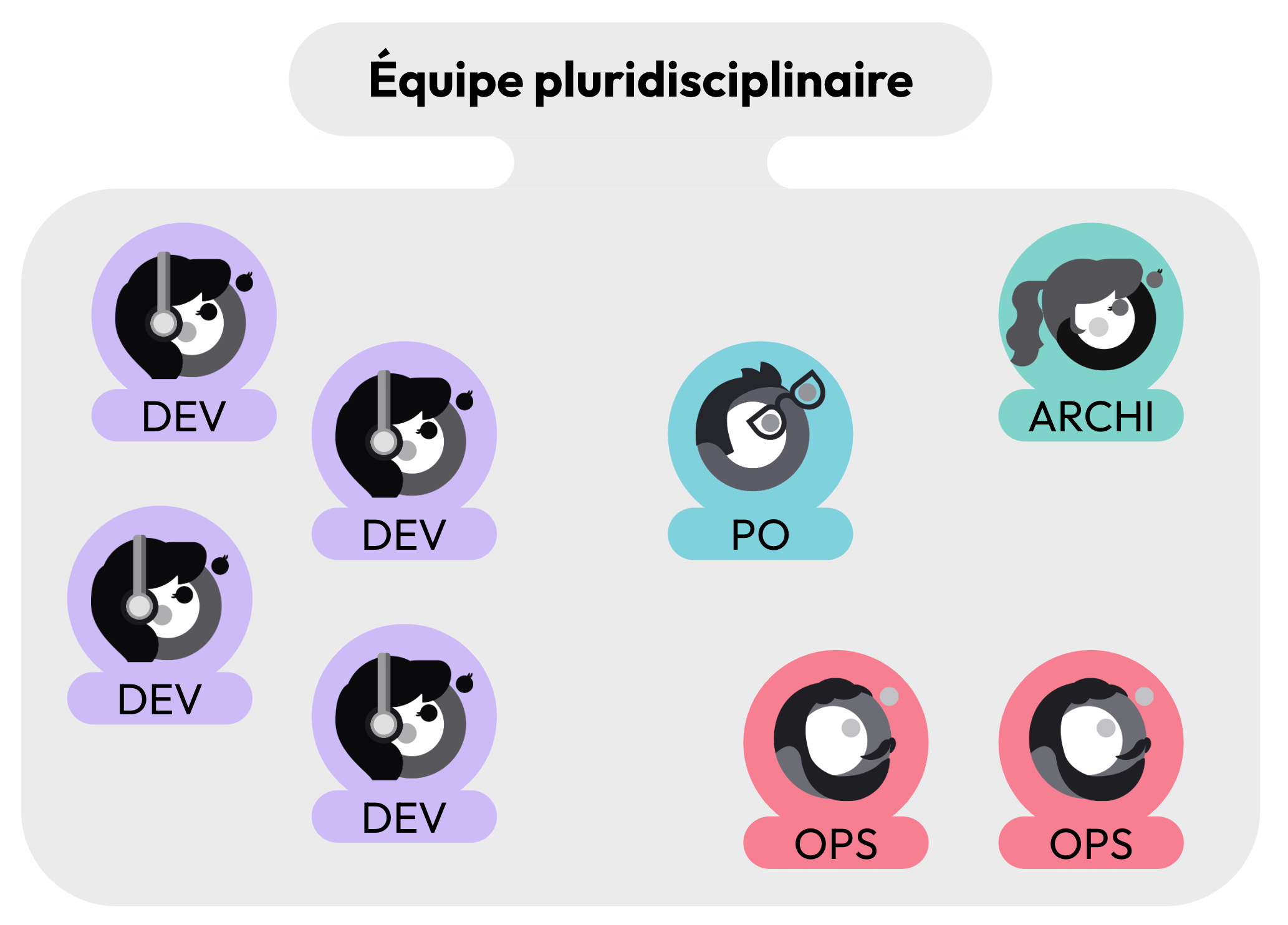
Une équipe pluridisciplinaire, composée d'un PO, d'Ops, d'un Archi et de Devs
Le client est une filiale d'un grand groupe et ce groupe impose à toutes ces filiales d'utiliser son offre d'hébergement Cloud on-premises pour toutes initiatives de Cloud.
Il s’agit d’une solution OpenStack avec un niveau de service IaaS bas niveau. Il est nécessaire de configurer le réseau, les machines et les flux de sécurité, puis d’y installer par-dessus tous les services.
Cette offre on-premises a une particularité : il faut être physiquement sur site pour pouvoir y travailler. En d’autres mots, brancher un câble Ethernet à son ordinateur pour accéder en SSH aux machines de production et pour pouvoir consommer des APIs OpenStack (nb: l'utilisation du VPN n'était pas envisageable).
Puis, catastrophe. La crise sanitaire arrive en mars 2020. Il n’était pas possible de continuer à travailler sans aller sur site client. Pour que les développeurs puissent continuer à travailler depuis chez eux, l’équipe de nos deux consultants propose au client d'utiliser un cloud public : AWS.
Pour que cet environnement de développement sur AWS reste au plus proche de la production, ils vont s’imposer les mêmes contraintes que celles présentes sur OpenStack : pas de services managés (base de données, lambdas, k8s, etc.), uniquement des VMs et du réseau.
La réécriture du code de provisionning des infrastructures Terraform est rapide car l'infrastructure reste finalement la même, et le code Ansible (l’installation des paquets, la configuration des VMs) est facilement portable.
Pour résumer, le client est venu avec une demande de refonte d'un système d'information et malgré le Covid, le projet rebondit et propose une alternative en télétravail avec une stratégie multi-Cloud.
La crise d’adolescence
Les règles sanitaires s’assouplissent et permettent de revenir sur le site du client. Mais le nombre de chaises et de bureaux étant limité, seuls les Ops sont autorisés à y retourner.
Malgré les efforts fournis afin de rendre la production et les environnements de développement les plus semblables possibles, certains éléments d'architecture restent difficilement reproductibles sur AWS :
- Le cloud : OpenStack reste différent d’AWS, rien que par leurs composants physiques (performances, pool de ressources et SLI différents). Les tirs de performances réalisés sur AWS pour anticiper la charge de trafic sont inutilisables. Puis, pour pallier la défaillance d'un système sous-jacent, et construire une architecture plus fiable et plus résiliente que ses bases, il a fallu mettre en place beaucoup d’ingénierie. Et enfin, contrairement à ce que l’on pourrait croire, les services de type commodity de ce Cloud ne fonctionnent pas toujours ;
- Le firewall : il est partagé par tous les projets du groupe. Les clients et les employés passent à travers ce firewall avant d'arriver sur OpenStack. Ces flux sont capables de coupures aléatoires qu’il faut être en mesure de détecter à temps.
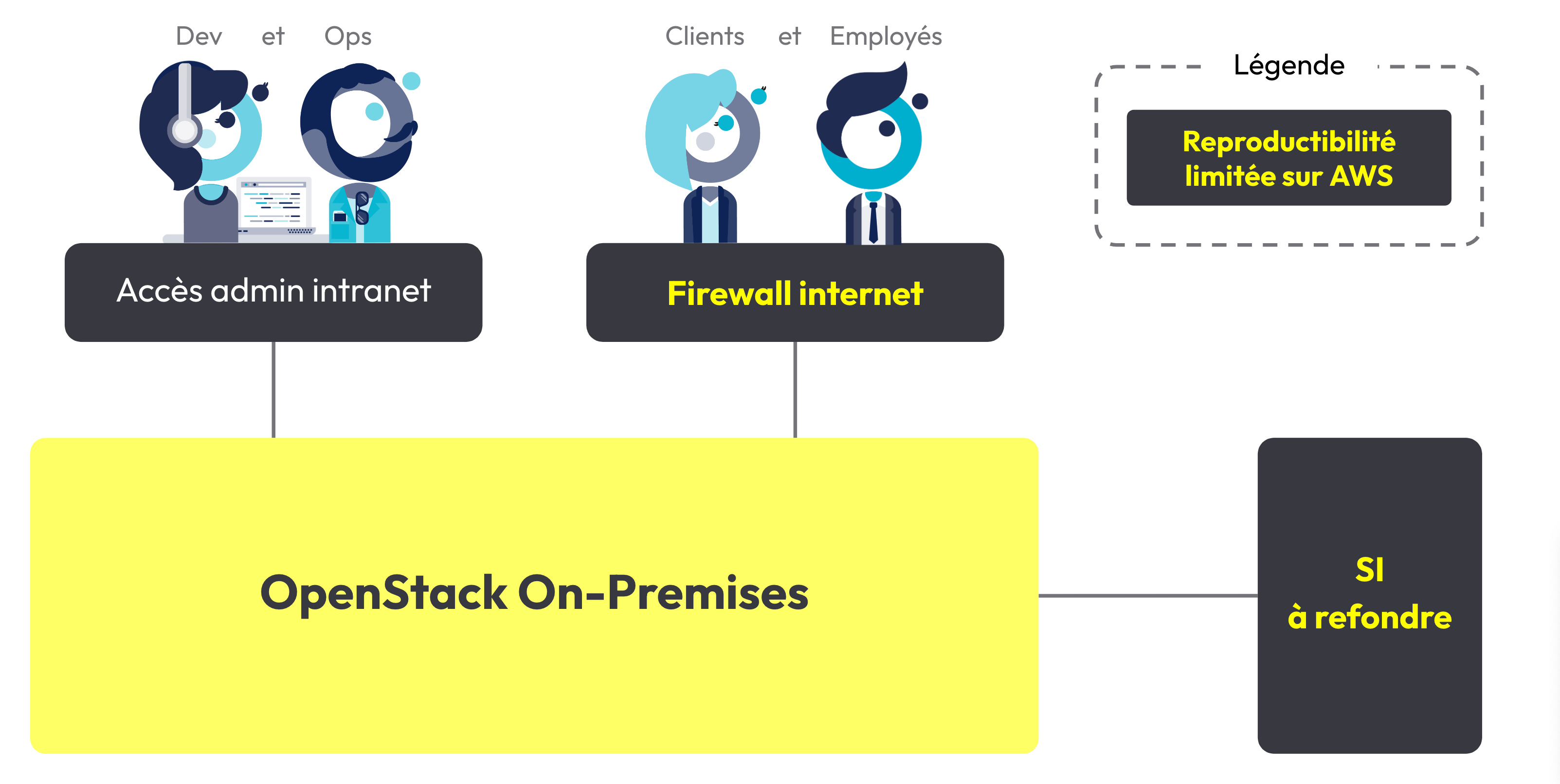
C’est une énorme perte de temps et d'énergie qui impacte la vélocité globale du projet.
Les développeurs continuent de déployer des fonctionnalités en télétravail alors que les Ops, forcés d'être sur site client, continuent de découvrir le véritable monde de leur plateforme cible.
Après quelques mois, le site ouvre en production. Le projet entre en phase de RUN et les bugs, la gestion d'incident, ainsi que le trafic viennent mettre à l’épreuve l’architecture et la résilience de l’infrastructure.
La maturité
Les utilisateurs sont contents, par conséquent le client est mis en confiance sur le plan de refonte. Il va vouloir l'accélérer, et de ce fait, il va débloquer du budget pour renforcer l’équipe déjà présente.
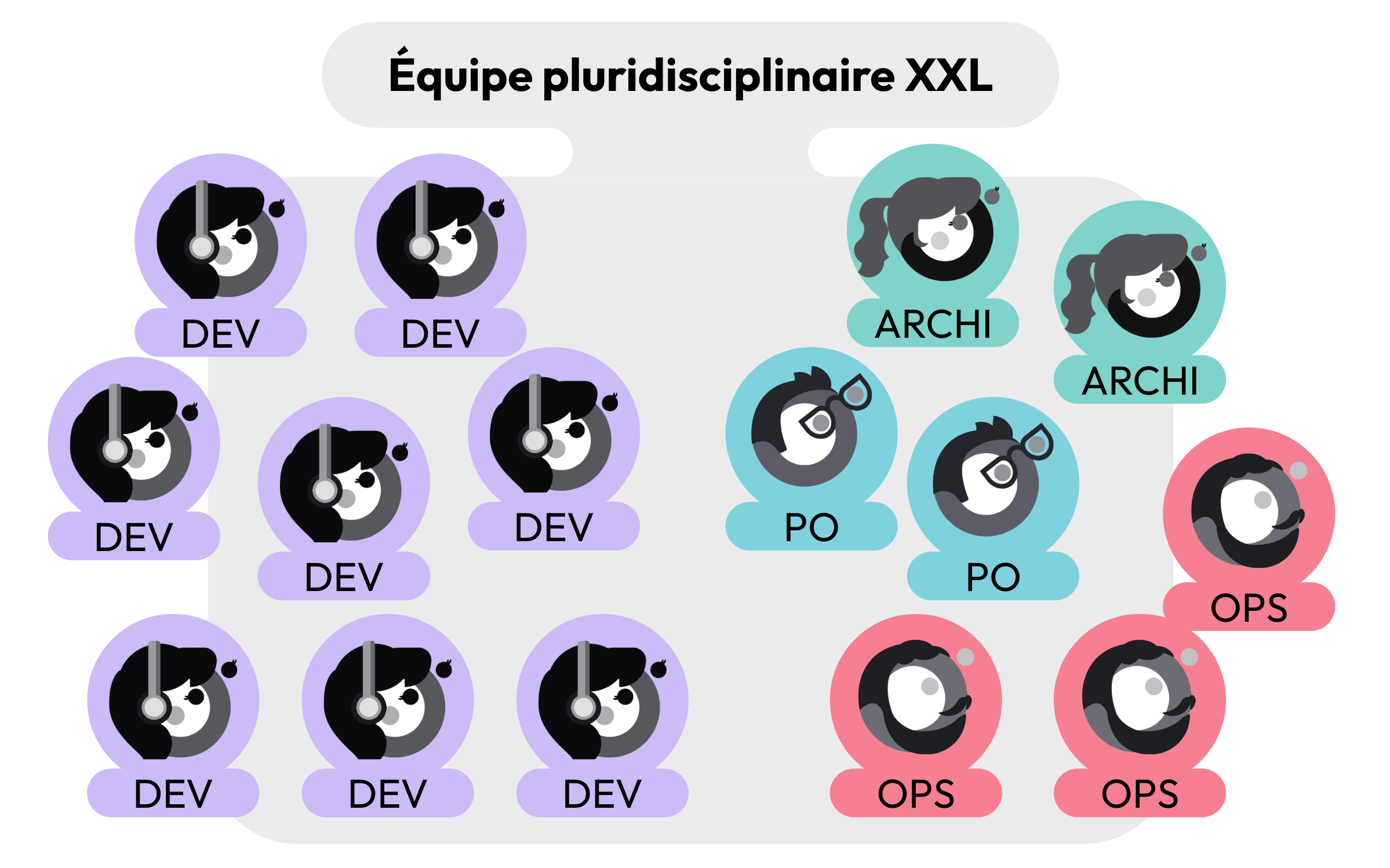
Une grosse équipe pluridisciplinaire, composées de POs, d'Ops, d'Archis et de Devs
Ce renfort va rejoindre la première équipe. Mais rapidement un premier palier de Dunbar est atteint et des problèmes de communication apparaissent dans l’équipe.
La première réorganisation s'opère.
La première réorganisation s'opère.
La direction de mission fait le choix de diviser l’équipe en plusieurs équipes plus petites, chacune responsable sur son périmètre fonctionnel. Bien entendu, ces équipes sont toujours pluridisciplinaires et autonomes de bout en bout du processus de développement.
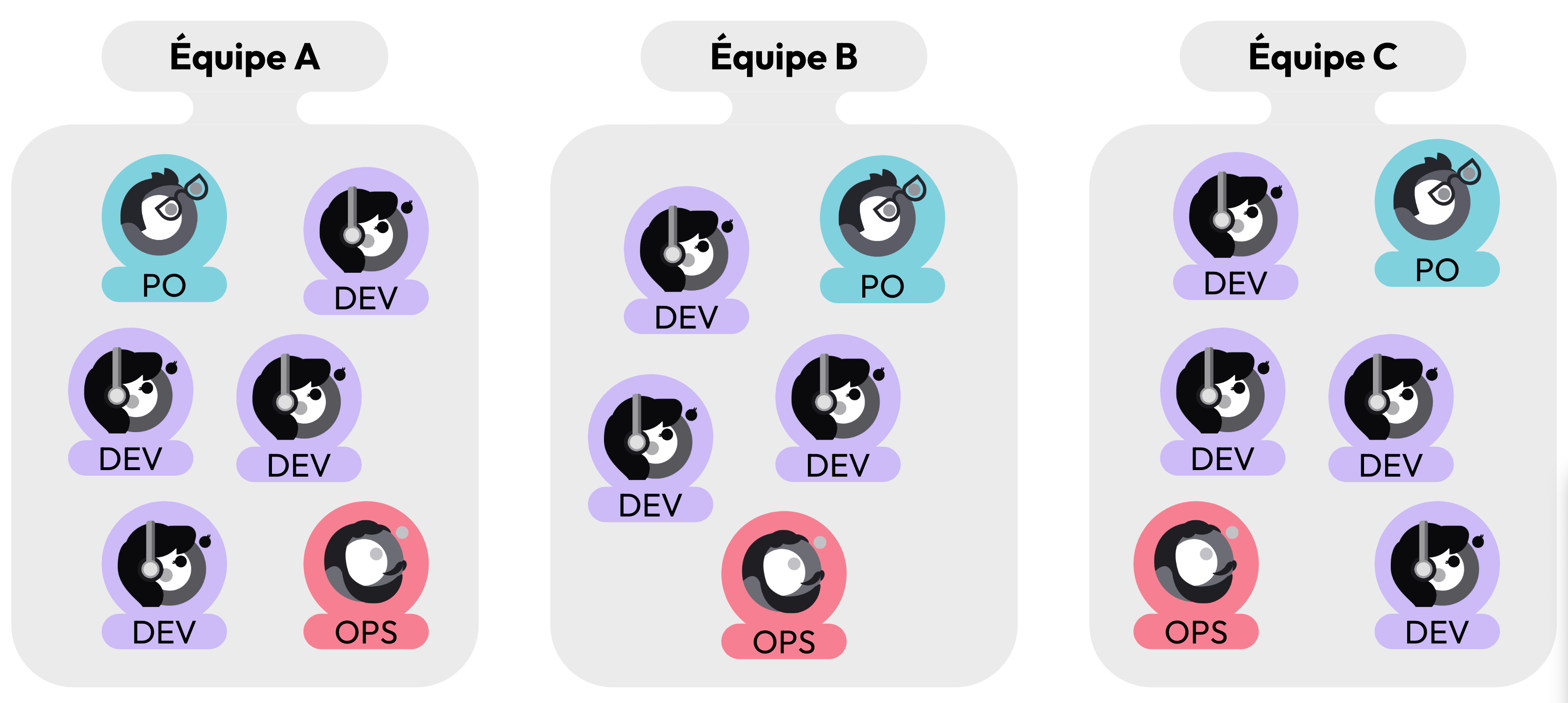
Trois équipes A, B et C, toutes pluridisciplinaires (composées d'un PO, d'un Ops et de Devs)
Même si ces équipes sont autonomes sur leur périmètre fonctionnel, elles travaillent toutes sur une même base de code qui repose sur une infrastructure unique. Et donc, partagée par toutes les équipes.
Ainsi, les Ops de chaque équipe sont amenés à très fortement collaborer avec ceux des autres équipes. Ce qui n’est pas sans conséquence.
Le produit va continuer de se développer, jusqu’à atteindre un certain niveau de maturité. La majorité des features ajoutées ne nécessite pas de modifier systématiquement l'infrastructure. Celles-ci vont de moins en moins impacter la roadmap des Ops :
Les Ops ont le sentiment de ne plus apporter de valeur aux équipes de dév ;
Pour travailler avec les Ops des autres équipes, les Ops vont faire des rituels agiles entre les Ops (daily meeting, démo, rétro, sprint planning) en plus des rituels agiles avec leur propre équipe, ce qui est très coûteux en énergie et en temps ;
Contrairement aux tickets “DEV” labellisés de façon fine (Epic, feature, tâche, dette technique etc.), les tickets des Ops sur le board Jira sont labellisés “Ops”. Des filtres feront même leur apparition pour cacher les tickets Ops sur les boards.
C’est le moment de leur deuxième réorganisation.
Ces douleurs, partagées par tous les Ops, vont les mener à proposer la création d’une nouvelle équipe d’OPS. Un essai est alors réalisé pendant 3 mois et deux objectifs sont visés :
regagner du sens dans le travail, renforcer le sentiment d'appartenance à une équipe
augmenter le temps de concentration des Ops sur des chantiers purement dédiés à l'infrastructure.
Pour rassurer les équipes, légèrement réticentes par peur de perdre en qualité de communication et de créer des silos, un point d'attention est mis sur la qualité et la fréquence des échanges.
La nouvelle équipe est une équipe comme les autres. Ainsi, elle est constituée d’un PO et d’un Tech Lead. Elle a les mêmes rituels agiles que les autres équipes, ainsi que des objectifs validés par la direction technique mais aussi, elle reste au service des autres équipes de développement.
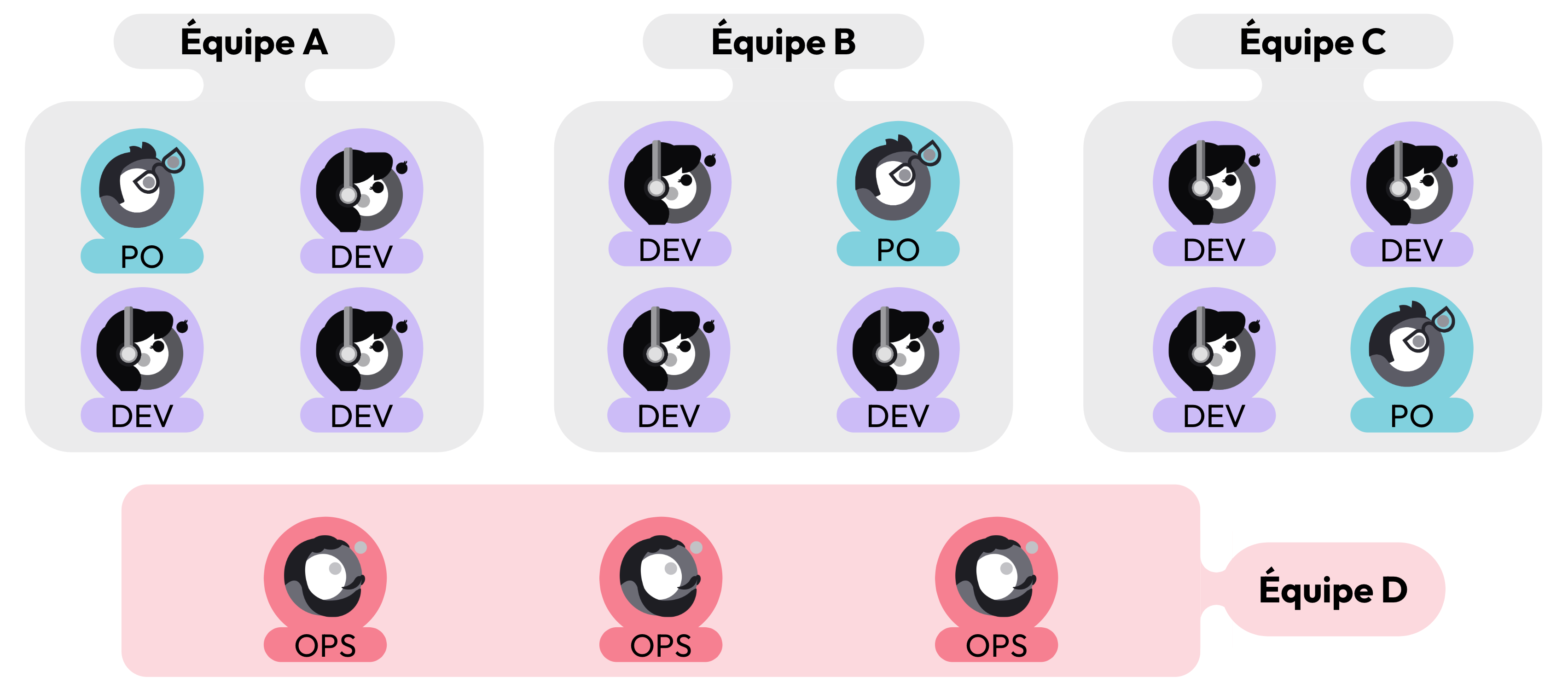
Une équipe D constituée uniquement d'Ops (dont un PO et un Tech Lead)
“Une équipe constituée uniquement d’Ops ? Est-ce une équipe SRE ?”
Petit rappel offert par nos speakers :
DevOps est un ensemble de pratiques qui vise à améliorer le time to market en améliorant la qualité en continu en passant par la collaboration entre le monde du développement et le monde des opérations.
SRE (Site Reliability Engineering) est l'organisation, le rôle et les pratiques des ingénieurs Google pour fiabiliser leur site en production. Ils sont décrits dans un livre publié par Google en 2016.
DevOps se focalise sur la vélocité par la collaboration, alors que SRE se focalise sur la fiabilité en production.

DevOps a beaucoup aidé l’équipe en phase de build. Mais, afin d’améliorer la fiabilité de l’infrastructure en RUN, pour satisfaire à la fois la demande au niveau des équipes de développement mais aussi des usagers finis, l'équipe de Hong-Viet et de Roberto ont rouvert ce livre de Google.
SRE présente un certain nombre de pratiques que l’équipe a mis en place, nos speakers en présentent trois d’entre elles dans leur talk :
Pratique 1 : On-Call
On-Call. Le “On-Call” est un rôle chargé de répondre aux incidents de production.
L’Ops occupant ce rôle est la seule personne appelée à intervenir lorsqu’il y a un problème. Cette pratique permet de protéger les autres personnes de l’équipe pour qu'elles puissent se concentrer à faire des fonctionnalités (en heures ouvrées) ou se reposer (en heures non ouvrées). Ce rôle est tournant pour permettre de faire monter en compétences toutes les personnes de l’équipe et pour réduire le syndrome du super-héros. C’est un rôle sujet au stress. Il faut donc un backup, pour aider à la priorisation des sujets et pour aider sur certains incidents plus ardus.
Cette équipe d’Ops s’est intéressée à l’On-Call pour diminuer la présence de context switching au sein de leur équipe, mais aussi pour donner aux autres équipes un point d’entrée pour communiquer avec eux. De par son succès, ce rôle a été étendu aussi aux équipes de développement.
Pratique 2 : le post mortem Blameless
Le post mortem Blameless. Il s’agit d’une pratique d'amélioration continue et de partage de connaissances. C'est un compte rendu écrit suite à une gestion d'incident. Il détaille le service impacté, la durée de l'incident et les étapes lors de l'investigation qui ont permis de trouver la cause de l'incident. Il contient également les actions de suivie qui vont permettre de fiabiliser le système ou d'éviter que l'anomalie ne se reproduise.
Le but n’est pas d'incriminer des personnes mais plutôt de comprendre l'environnement, le cadre et les process qui ont amené à cette situation (= statut blameless). Il permet de créer de la confiance et ainsi d’éviter toute rétention d'information ce qui permet in fine de gagner énormément de temps.
Pratique 3 : le toil
Le toil, c’est l'ensemble des tâches opérationnelles qu’on est amenés à faire en production (la gestion d'incidents, le support, les montées de versions, la dette technique, etc). Autant de tâches, qui sont, pour la plupart, non prédictibles et qui n’apportent pas de valeur métier. Pour cette raison, nous devons au maximum réduire ce Toil (en nous aidant entre autres de l'automatisation).Pour mesurer ce dernier, l’équipe, dès sa création, décide de changer le label des tickets Jira taggés “Ops” pour différencier les fonctionnalités de la charge opérationnelle. Même si l'idéal reste de savoir le temps passé sur chaque tâche.
Grâce à cette mesure du toil, il devient plus simple d’estimer la capacité disponible pour prendre certains chantiers, mais aussi, lorsque le toil est trop grand, l’équipe des Ops peut influer sur la feuille de route des développeurs.
Takeaway
C’est ainsi que se termine le REX captivant de Roberto et Hông Viêt. Ils nous proposent pour conclure trois takeaway essentiels à retenir de leur talk :
- Appliquer les pratiques SRE selon votre contexte !
Google avait 1200 SRE au moment de la publication de leur ouvrage, l’équipe de nos deux orateurs avait 4 Ops. Le contexte et donc les besoins sont différents et il convient d’adapter les pratiques de façon pragmatique et non dogmatique.
- Se réorganiser c'est normal et c’est nécessaire !
Il faut laisser le temps aux réorganisations de mûrir et il ne faut pas hésiter à la faire évoluer en fonction des besoins et des irritants.
- Méfiez-vous des promesses des Cloud, toutes ne se valent pas !
Regarder le catalogue de services et se faire rapidement une idée de la qualité du service car il va influencer la stratégie adoptée sur votre projet.
Pour tout savoir sur les enjeux Cloud, DevOps et Plateformes, cliquez ici.