Compte rendu CITCON Paris 2009
Ce samedi avait lieu la CITCON Europe 2009 à Paris. CITCON pour Continuous Integration and Test CONference, donc pour les anglophobes Conférence sur l'Intégration Continue et les Tests. J'ai eu la joie d'y participer et donc voici un résumé de ce que j'ai pu y voir et entendre. Vendredi Soir 18h30 : Début des festivités, présentation individuelle des 100 et quelques personnes dans la plus grande salle de l'ISEP qui accueillait la conférence. Pour faire rapide, chacun dit son nom, comment il a connu la CITCON et ce qu'il est venu y chercher. Mine de rien, au rythme de 30 secondes par personnes, on a bien passé plus d'une heure à se présenter. L'occasion de revoir des visages connu : Vincent Massol, Arnaud Héritier, Nicolas Martignole et de mettre des noms sur des visages : Hervé Boutemy avec qui j'ai relu le livre Maven Fr d'Arnaud Héritier et Nicolas De Loof à paraître prochainement.
Suite à cela, proposition de sujets. Tous ceux qui le souhaitaient, passaient au tableau présenter rapidement un sujet. C'était très varié : quelques topics orientés outils (Plugins Hudson, futur de l'IC...), pas mal autour des tests (accélérer les tests, les mocks, les UAT, les tests sur la bdd), l'agile (scrum) et j'en passe.
~~~~~~~~~~~~~~~
Samedi matin, 10h00, première session sur les plugins Hudson, où comment développer un plugin hudson, quels plugins manquent, etc...
Douglas Squirrel nous présente un plugin qu'il a développé pour voir le status d'agents depuis Nagios (par exemple lorsque le serveur maître est down). Son retour d'expérience est que la documentation pour créer des plugins est relativement bien faite et que l'utilisation de Maven facilite la chose (mvn hpi:create). Par contre, l'utilisation de jelly pour la création de vue est assez déroutante ainsi que savoir où placer son code. Heureusement la communauté est là et Kohsuke Kawaguchi aussi ! Une fois votre plugin codé, la commande mvn hpi:run lance un hudson en local et vous pouvez tester votre création. Donc n'ayez pas peur de vous lancer, ca fait pas mal...
On est ensuite parti sur les plugins et améliorations à avoir : meilleure gestion des dépendances entre build avec par exemple la possibilité d'avoir un graph des dépendances entre build, la distribution des tests unitaires : j'ai bien envie de tenter de distribuer les tests avec gridgain sur les agents configurés dans hudson (un article devrait arriver d'ici peu sur le sujet).
~~~~~~~~~~~~~~~
11h15, deuxième session. J'ai commencé par aller voir le sujet du déploiement en continu, mais étant arrivé après le départ, j'ai eu du mal a entrer dans la discussion. Ils parlaient de pipeline de build avec toutes les étapes de l'intégration continue. Ca m'a paru bien loin du sujet initial et j'ai donc changé de salle (c'est le principe des open spaces, si ca ne vous plait pas, partez) pour aller discuter release de (gros) projets. Vincent Massol se pose la question de comment automatiser la release : quand un produit (au hasard XWiki ;-)) est composé de nombreux modules (qui n'ont pas forcément tous bougé et n'ont donc pas forcément à être releasé), le mvn release n'est pas forcément adapté puisqu'il descend dans les sous modules et les release tous. Après nous avoir présenté sa manière de faire pour les releases XWiki (une belle et longue procédure), on part sur la réalisation d'un algo pour trouver les dépendances d'un projet qui ont évolué depuis la dernière release :
// En récursif sur le projet parent et tous les modules :
List currentDependencies = getDependencies();
// Faire de même avec la version précédente du projet (avec le scm, récupérer la version tagé antérieure)
List previousDependencies = getPreviousDependencies();
// Faire le diff des deux listes sur les versions => on obtient les modules ayant évolués
// On peut ainsi releaser ce qui a été modifié
// On peut avoir les évolutions de version pour la release note
On s'est ensuite plongé dans le code du plugin dependency pour essayer d'y inclure le mojo diff permettant d'avoir le différentiel entre deux versions sans toutefois aller bien loin puisque le déjeuner nous appelait. On a également mentionné un plugin Maven que je ne connaissais pas : versions-maven-plugin et qui permet, comme son nom l'indique, de jouer sur les versions des artefacts et entre autre de setter une version pour un projet et tous les modules qui le constituent (fini les grep !) ou encore d'avoir le rapport des dépendences et plugins qui sont disponibles dans une version plus récente.
~~~~~~~~~~~~~~~
Le déjeuner est l'occasion de discuter avec Hervé Boutémy d'OSS : Apache, Maven, Archiva, Continuum, Jason Van Zyl... discussion intéressante sur le passage de l'open source au gain de sa vie (distinction avec "se faire de l'argent").
~~~~~~~~~~~~~~~
14h00, session sur la rapidité des tests. La session commence par une question : "combien de temps prennent des tests rapide ?", sans toutefois préciser de quel type de test on parle. On en arrive à généraliser à comment avoir un feedback rapide (pas seulement les tests mais le build complet) et il émerge que 5 minutes est le maximum raisonnable. Douglas Squirrel nous présente son expérience avec selenium : 12 agents hudson, 15 agents pour selenium pour tester sur différents browsers. Avec cette technique, il en a pour 25 minutes à faire ses tests d'IHM. Par la suite, différentes propositions sont faites :
- Exploiter au mieux les différents cœurs des processeurs (chose qui n'est actuellement pas le cas avec surefire par exemple et qui pourrait s'avérer vraiment bénéfique)
- Distribuer les tests avec Gridgain (pour JUnit) ou TestNG
- Utiliser une base mémoire (HSQL, H2) pour les tests unitaires. On s'est attardé sur le fait de commiter ou pas les requetes mais étant en mémoire, je ne vois pas le problème de commiter.
- Le personnal build (fonctionnalité de Teamcity) pour permettre de continuer à coder pendant que l'intégration continue déroule le build (sans toutefois commiter le code pour ne pas perturber les autres développeurs).
- Et une fois que toutes les solutions annexes ont été mentionnées, quelqu'un a tout de même dit : "et si c'était les tests qui étaient pourris". Donc plutôt que de chercher à améliorer le build, améliorer les tests eux-mêmes. Il parle de réduire le nombre de tests, qui en soit peut être une bonne chose si la couverture reste équivalente. Mais pour cela, il souhaite utiliser des valeurs aléatoires. Je l'interpelle "comment on peut connaître le résultat attendu en faisant du random ?" Alors effectivement, c'est pas tout à fait du random. On a une map avec les valeurs d'entrée et leurs sorties attendus et on test un cas au hasard. Avec le nombre de builds joués par jour, on s'attend à avoir couvert l'ensemble. On diminue effectivement le nombre de tests mais je ne suis pas convaincu de la reproductibilité, du moyen de corriger une erreur détectée par un test...
15h15, session Cloud, le sujet du moment. Avant toute chose, on a décrit les raisons pour lesquelles on veut aller sur le cloud :
Réduction des coûts d'infrastructure (serveurs), maintenance et mise à jour des outils
Optimisation du coût d'utilisation du CPU.
Gérer au mieux les pics de charges. Comme vous pouvez le voir sur le graphique, le serveur d'intégration continue n'est utilisé qu'à certains moment (en bleu) et donc le reste du temps, on paye pour rien (en rouge).
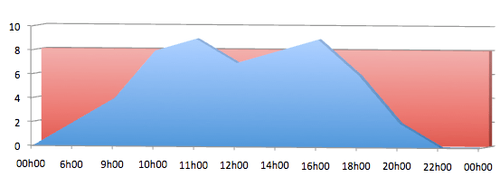
Ensuite, on a parlé des différents problèmes que l'on peut avoir à mettre le serveur sur le cloud (Amazon EC2 par exemple). Plusieurs choses :
- La première à mon sens est la sécurité. Tout le monde n'a pas d'algo de pricing ultra protégé mais pour ceux la, le code n'est pas prêt d'être déporté. J'ai récemment vu dans une grande banque d'investissements française que d'une équipe à une autre, il ne souhaitait pas diffusé le code donc ce n'est pas encore pour tout le monde. Mais il existe des solutions, il est effectivement possible de mettre en place un VPN et ainsi limiter le risque. J'ai beaucoup aimé la remarque de Nicolas Martignole qui "fait plus confiance en Amazon qu'en son équipe IT" et qui imagine bien dans quelques mois ou années coder sur son poste et compiler/tester... sur le cloud.
- Autre problème mentionné, les latences réseaux
- Les limitations en cas d'environnement complexes... on ne peut pas tout déporter.
Une des personnes présentes a mentionné Eucalyptus Cloud et en est plutôt satisfait.
~~~~~~~~~~~~~~~
Conclusion, je n'ai pas pu participé à la dernière session, mais je suis assez satisfait de ma journée. Des discussions intéressantes, des gens intéressants, bien entendu, vu le nombre de sujets en parallèles à chaque session, il m'a fallu choisir mais aucun regret sur mes choix. L'une des sessions consistait à choisir le prochain pays d'Europe à accueillir CITCON et donc, on verra l'année prochaine si je pourrai remettre ça.