Déployer un LLM open source : installation, prompts et usages
En bref
Un LLM open source, c'est un modèle de langage dont les poids sont publics : vous pouvez le télécharger, le déployer et l'utiliser chez vous, sans envoyer vos données à un tiers. Cet article montre comment faire tourner Mistral-7B en local avec llama.cpp ou Ollama, construire vos premiers prompts et poser les bases d'un produit d'IA générative souverain.
Introduction
“Generative AI has the potential to change the world in ways that we can’t even imagine.”
Bill Gates, 2023.
C’est le genre de discours que nous entendons depuis l’arrivée de ChatGPT fin 2022. Chacun a son avis là-dessus, comme pour chaque innovation technologique. Cependant, il est indéniable que ChatGPT a déjà marqué le monde au-delà de la sphère technique. Les chiffres parlent d’eux-mêmes : 2 mois pour obtenir 100 millions d’utilisateurs, 180 millions d’utilisateurs mensuels actifs, la valorisation d’OpenAI qui explose… La concurrence n’a pas tardé à émerger. En effet, à partir du moment où quelqu’un franchit une limite que nous pensions jusque-là inatteignable, un déclic se crée et les concurrents s’engouffrent dans cette brèche. Nous retrouvons le cas de la “four minute barrier”.
Dans cet article, nous ferons attention à bien différencier gpt3.5, le modèle, et ChatGPT, le produit construit à partir de celui-ci.
Les clés de la révolution GenAI sont aujourd’hui majoritairement entre les mains d’entreprises privées, et les modèles sont cachés derrière des APIs propriétaires. Il y a un risque de monopole. Même si ces organisations ont également contribué dans la communauté open-source, avec des modèles comme T5 (Google), Dolly (Databricks), Phi (Microsoft)… Ceux-ci étaient loin de l’état de l’art.
Jusqu’à mi-2023, gpt3.5 régnait quasiment sans partage. Puis les initiatives open source se sont multipliées avec des alternatives de plus en plus crédibles. D’abord avec Falcon en juin 2023, puis Llama2 en juillet, et Mistral en septembre. Aujourd’hui Mistral AI et Meta font la course en tête dans la communauté open-source et proposent des modèles performants pour challenger gpt3.5 (gpt4 est encore aujourd’hui sans équivalent en open-source).
Si nous adoptons l’analogie d’une voiture, ces modèles open-source sont les moteurs. ChatGPT, lui, est bien plus que son moteur gpt3.5, c’est une voiture complète.
En effet, un LLM (pour Large Language Model), est à la base un simple assemblage de fichiers de poids avec une configuration en json. C’est ce que nous voyons sur HuggingFace Hub. Les APIs propriétaires sont bien plus que ça. Elles construisent une infrastructure autour de leurs LLMs, avec une capacité de passage à l’échelle, de la résilience, de la redondance, du logging, etc. Un moteur est un composant, elles ont construit la carrosserie, le châssis, la boîte de vitesses, la ligne de production… bref des produits utilisables par les consommateurs.
Or, aucun de ces produits ne propose une option complètement privée, i.e une installation complète et transparente sur vos serveurs. Les consommateurs ont peu de contrôle sur l’infrastructure, les modèles, mais surtout une faible emprise sur la facturation et la confidentialité. Les données envoyées à ChatGPT, ainsi que les réponses, sont enregistrées chez OpenAI et leur permettent d’améliorer continuellement leurs modèles, d’après leurs conditions d’utilisation. L’open-source peut permettre de créer un produit souverain, sans dépendance à un tiers. Cela peut même s’avérer intéressant sur le plan financier.
Dans cet article, nous allons voir comment déployer un LLM open-source pour le rendre utilisable et poser les bases pour construire un produit d’IA générative.
Le déploiement
Dans cet article, déployer signifie rendre un modèle utilisable. La base d’un logiciel est du code, et le machine learning ne fait pas exception. À partir de ce code, des artefacts sont créés, soit des fichiers qui permettent de réaliser l’action attendue par les utilisateurs. Ces artefacts peuvent être un fichier .exe, comme vous en avez sûrement vu sur Windows, ou un .dmg sur MacOS. En plus de la logique du logiciel, ces artefacts fournissent un code d’installation pour être facilement déployés sur votre machine.
Au début de notre parcours, nous n’avons que la logique, c'est-à-dire les poids d’un LLM. Nous allons commencer par les rendre utilisables, c'est-à-dire pouvoir envoyer des requêtes et recevoir une réponse, comme avec l’API d’OpenAI. Dans un premier temps, il n’y a pas d’interface de dialogue, ni de passage à l’échelle, ni d’industrialisation d’aucune sorte.
Déploiement local sur votre machine
Les LLM sont des modèles très lourds, les fichiers de poids font souvent plusieurs dizaines de giga voire des centaines pour certains. Les APIs propriétaires gèrent cela et permettent de cacher cette lourdeur. Dans notre cas, nous allons devoir la gérer nous-même.
Il est possible de déployer un LLM sur son propre laptop. Cependant, nous allons être limités dans le choix du modèle par la RAM disponible. Dans notre cas, avec un MacBook Pro de 2019 de 32G de RAM et 12 vCPU, nous pouvons utiliser Mistral-7B, le plus petit modèle de Mistral AI. Celui-ci a l’avantage d’être à la fois performant, compact et sous licence Apache2, très permissive.
Bien sûr, vous pouvez utiliser la librairie transformers comme présenté dans la Model Card. Mais vous devrez ensuite écrire vous-même le code pour créer l’API, et le moteur d’inférence par défaut de transformers est peu efficace. Si vous disposez d’un GPU vous pouvez toutefois essayer optimum-nvidia pour optimiser l’inférence. Comme il faut écrire soi-même le code pour le serveur, nous ne l’explorerons pas plus dans cet article, mais cela peut être une option pour votre organisation.
Nous allons présenter 2 frameworks pour utiliser Mistral-7B en local : llama.cpp et Ollama.
Llama.cpp
Llama.cpp est une des premières initiatives pour exécuter des LLM en local. À la base, c’est un projet en C++ pour optimiser l’inférence sur CPU du premier modèle Llama de Meta. Maintenant c’est un framework plus générique qui supporte plusieurs architectures de LLM et qui fournit des SDK dans la plupart des langages populaires. Nous allons nous concentrer en particulier sur llama-cpp-python.
Ce SDK permet de lancer facilement un serveur d’inférence local pour le modèle. Ce serveur reproduit notamment le même contrat d’API qu’OpenAI, ce qui permet de l’utiliser comme remplaçant direct dans les applications qui utilisent déjà les modèles GPT (cependant sans l’infrastructure d’OpenAI derrière et donc sans ses avantages décrits dans l’introduction).
Pour commencer, il faut installer la librairie:
pip install llama-cpp-python==0.2.48 llama-cpp-python[server]
Puis télécharger les poids du modèle. Llama.cpp utilise un format de poids particuliers appelé GGUF. Pour les obtenir vous pouvez soit exécuter un script pour convertir les poids depuis le repository de Mistral AI (vous devrez les télécharger au préalable), soit les récupérer dans un repository existant (The Bloke propose beaucoup de modèles convertis dans différents formats).
Pour faire la conversion vous-même :
# Télécharger les poids
from huggingface_hub import snapshot_download
snapshot_download(
repo_id="mistralai/Mistral-7B-Instruct-v0.1",
local_dir="models",
local_dir_use_symlinks=False,
revision="main"
)
```<br>
Ou \(vous avez besoin de git\-lfs pour exécuter cette commande, [installez le](https://docs.github.com/en/repositories/working-with-files/managing-large-files/installing-git-large-file-storage) si besoin\) :
<br>```shell<br># Récupérer les poids
git clone https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.1
# Cloner le repo llama.cpp et installer les dépendances
git clone https://github.com/ggerganov/llama.cpp.git
pip install -r llama.cpp/requirements.txt<br>```<br>
Puis lancez la conversion : <br><br>```shell<br>python llama.cpp/convert.py ./models --outfile mistral.gguf --outtype q8_0<br>```<br>
L’argument `outtype` spécifie le type des poids en sortie\. `q8\_0` est une quantization des poids en 8 bits\. Cela permet de réduire la taille du modèle avec un minimum de perte de qualité\. On peut aussi quantizer sur moins de bits pour gagner encore plus de place, mais au détriment de la performance\. Sinon on peut également utiliser le type f16 pour garder la qualité originale mais sans compression\. Moins la machine est puissante, plus on doit compresser les poids\. Dans mon cas, une quantization sur 8 bits suffit\.
À partir des poids obtenus (nous utilisons ceux de repo de [TheBloke](https://huggingface.co/TheBloke/Mistral-7B-Instruct-v0.1-GGUF/tree/main)), on peut lancer le serveur llama-ccp-python avec cette commande : <br><br>```shell<br>python -m llama_cpp.server --model ./models/models--TheBloke--Mistral-7B-Instruct-v0.1-GGUF/snapshots/731a9fc8f06f5f5e2db8a0cf9d256197eb6e05d1/mistral-7b-instruct-v0.1.Q8_0.gguf --n_ctx 16192<br>```<br>
Si tout s’est bien passé, le serveur fastapi devrait démarrer et accepter des requêtes sur le port 8000 de votre localhost \(figure 1\)\. Vous pouvez alors communiquer avec le modèle via des commandes curl, ou des objets du SDK OpenAI ou d’un framework comme [langchain ](https://blog.octo.com/le-chatbot-docto-langchain-rag-et-code-associe)\(dans ce cas vous devez changer l’url de base en `http://localhost:8000`\)\.

Figure 1: Démarrage du serveur FastAPI de `llama\-cpp\-python`

Figure 2: Requête au modèle Mistral 7B via `llama\-cpp\-python`
Une requête comme celle de la figure 2 prend environ 15s\. Cela peut être trop lent pour de nombreux cas d’usage\. Vous avez la possibilité de streamer la réponse, c'est\-à\-dire la faire apparaître token par token comme ChatGPT, plutôt qu’en bloc\. Cette option apporte de la fluidité et procure une meilleure expérience utilisateur, notamment pour un usage conversationnel\.
L’option de déployer en local avec llama\.cpp peut être envisageable si vous pouvez vous contenter d’un petit modèle, et que vous n’avez pas besoin d’une qualité de réponse optimale\. Elle est appropriée par exemple pour faire de la complétion de code avec un petit modèle spécialisé\.
#### Ollama
Ollama est une autre librairie populaire pour le déploiement en local avec des ressources limitées\. Tout comme `llama\-cpp\-python`, elle permet de démarrer rapidement un [serveur compatible avec le protocole OpenAI](https://ollama.com/blog/openai-compatibility)\.
Pour commencer vous devez installer Ollama via ce [lien](https://ollama.com/download). L’opération est encore plus simple que `llama-cpp-python`, car il y a une application dmg sur MacOS. Cela va aussi installer la ligne de commande `ollama` sur votre machine. Une fois que c’est fait, vous pouvez démarrer le serveur avec la commande suivante : <br><br>```shell<br>ollama run mistral:instruct<br>```
C’est tout \! Pas besoin de se soucier du type des fichiers de poids, de l’emplacement du modèle… Ollama s’en charge pour vous\.
Vous devriez voir apparaître une invite de commande pour dialoguer avec le modèle, comme en figure 3\. Vous pouvez poser des questions comme vous le feriez avec ChatGPT \(sans l’interface graphique bien sûr\)\. La réponse est streamée par défaut\.
Vous pouvez aussi utiliser la commande pull : <br><br>```shell<br>ollama pull mistral:instruct<br>```
Celle\-ci va démarrer un serveur sur le port 11434 de votre localhost avec un protocole compatible avec OpenAI\. Vous pouvez utiliser la même commande curl que précédemment pour envoyer des requêtes \(figure 4\)\.

Figure 3 : Démarrage du serveur d’inférence Ollama

Figure 4 : Requête à Mistral 7B via Ollama
Pour sa simplicité d’installation, Ollama peut être préféré à `llama\-cpp\-python` pour tester des LLM et pour du prototypage\. Par défaut Ollama utilise les poids quantisés en 4 bits mais vous pouvez changer ce comportement si vous spécifiez des tags dans la ligne de commande \(voici les [tags disponibles](https://ollama.com/library/mistral/tags) pour mistral 7B\)\.
#### Autres frameworks
Nous n’avons vu que quelques frameworks parmi les plus populaires\. Il en existe de nombreux autres, comme [LM Studio](https://lmstudio.ai/) ou [LocalAI](https://github.com/mudler/LocalAI)\. À vous de choisir quel est le plus pertinent dans votre organisation\. Par exemple, avez\-vous besoin [du même contrat d’interface que l’API d’OpenAI](https://platform.openai.com/docs/api-reference/chat) ? Si c’est le cas, tant mieux pour vous car la plupart des frameworks ont l’air de converger vers celui\-ci\. Avez vous besoin d’une UI ou est ce qu’une API REST suffit ? Ce genre de questions peut vous aider à vous orienter dans le choix du framework\.
Il est donc possible de tester des LLM en local et d’implémenter quelques cas d’usages\. Cependant nous sommes fortement limités par la capacité de la machine et l’absence d’accélérateur comme une carte graphique\. Ce mode de déploiement ne permet pas d’utiliser les modèles les plus performants de la communauté open\-source\.
#### Déploiement sur une machine distante
Pour répondre aux limites du déploiement local, il est nécessaire d’utiliser une machine plus puissante et d’envoyer nos requêtes au modèle via une API sur le réseau\.
Les cartes graphiques permettent des gains de performances considérables en machine learning\. Les opérations en deep learning sont en grande partie des calculs tensoriels, et la capacité des GPU à paralléliser ce genre de petites opérations permet d’accélérer l’inférence\.
Malheureusement nous ne disposons pas d’une machine avec un GPU, nous avons donc utilisé une VM dans le cloud, voici sa configuration :
- 1 GPU A10G de 24G
- 16 vCPU
- 64G de RAM
Vous avez toujours la possibilité d’utiliser `transformers` avec l’option `device=cuda` pour profiter du GPU et `optimum\-nvidia` pour accélérer encore l’inférence\. Cependant, nous n’explorerons pas plus cette option ici pour les mêmes raisons que dans la partie précédente\.
Nous allons encore une fois déployer Mistral\-7B sur cette machine\. Pour cela, nous allons comparer trois frameworks : TGI, vLLM et TensorRT\-LLM\.
#### TGI
TGI signifie Text Generation Inference\. C’est le framework développé par HuggingFace qui est derrière les HuggingFace Inference Endpoints\. Celui\-ci introduit plusieurs optimisations, notamment le [continuous batching](https://www.anyscale.com/blog/continuous-batching-llm-inference)\. Il utilise également un serveur en Rust, plutôt qu’en FastAPI et gRPC pour la communication\. De même que GGUF pour `llama\-cpp\-python`, TGI utilise un format spécifique pour les poids des modèles nommé [safetenso](https://github.com/huggingface/safetensors)r\.
Il est possible d’installer le framework sur la machine ou d’utiliser Docker\. L’installation requiert d’installer Rust et de construire des dépendances\. C’est relativement rapide mais un peu plus complexe qu’une installation via `pip`\. Pour ce test, nous avons utilisé l’image Docker\.
Depuis sa création, TGI a utilisé son propre protocole d’API, basé sur une route `/generate` pour répondre à des requêtes\. Cependant depuis début février 2024 et la version 1\.4\.0, [HuggingFace](https://huggingface.co/blog/tgi-messages-api)[ a rendu le framework compatible avec l’API OpenAI](https://huggingface.co/blog/tgi-messages-api)\. On peut donc utiliser les HuggingFace Inference Endpoints ou un endpoint TGI privé comme des remplaçants directs d’OpenAI\.
HuggingFace a aussi développé [Text Embeddings Inference](https://github.com/huggingface/text-embeddings-inference), l’équivalent de TGI pour les modèles d’embeddings, avec un fonctionnement similaire\. Les modèles d’embeddings sont très utilisés avec des [bases vectorielles](https://blog.octo.com/sous-le-capot-des-bases-de-donnees-vectorielles-(vector-databases)) pour construire des systèmes RAG\.
Pour utiliser l’image Docker, il faut d’abord avoir installé les drivers Nvidia sur la machine\. Si vous utilisez un cloud provider, ces drivers sont normalement déjà installés si vous avez sélectionné un type d’instance fait pour le deep learning \(comme les g5 sur AWS, a2 sur GCP, ou nc sur Azure\)\. Sinon vous devez les installer vous\-même grâce à ce [lien](https://developer.nvidia.com/cuda-downloads)\.
Une fois les drivers installés, exécutez la commande : <br><br>```shell
watch -n0.1 nvidia-smi<br>```
Si votre installation a réussi, vous devriez voir un récapitulatif de l’utilisation des GPU, mis à jour toutes les 0,1 secondes \(figure 5\)\.
Vous pouvez démarrer le conteneur docker pour servir Mistral\-7B avec TGI :
```shell<br>docker run --gpus all --shm-size 1g -p 8080:80 -v $PWD:/data ghcr.io/huggingface/text-generation-inference:1.4 --model-id mistralai/Mistral-7B-Instruct-v0.1<br>```
Le conteneur va commencer par télécharger les poids du modèle et les convertir en safetensor s’ils sont dans un autre format\. Cette opération peut prendre un peu de temps selon le modèle\. Une fois que c’est fait, vous verrez apparaître les logs du serveur Rust qui indique le démarrage \(figure 6\)\.

Figure 5 : Suivi de la mémoire GPU

Figure 6 : Démarrage du serveur d’inférence TGI pour Mistral 7B
Vous pouvez tester le modèle avec la commande suivante : <br><br>```shell
curl 127.0.0.1:8080/generate -X POST -d '{"inputs":"Hello, how are you?","parameters":{"max_new_tokens":200}}' -H 'Content-Type: application/json'<br>```
On peut faire la même chose avec le protocole OpenAI : <br>
```shell<br>curl http://17.12.184:8080/v1/chat/completions -H "Content-Type: application/json" -d '{"model": "mistralai/Mistral-7B-Instruct-v0.1", "messages": [{"role": "user", "content": "Hello, how are you?"}]}'<br>```
Vous verrez apparaître la réponse comme avec Ollama ou `llama\-cpp\-python` :

Figure 7 : Requête à Mistral 7B via TGI
On constate que la réponse est bien plus rapide qu’en local\. Grâce à l’accélération GPU et aux optimisations de TGI, l’inférence est environ 15 fois plus rapide que dans la première partie\. Cela fait de TGI un framework crédible pour remplacer l’API d’OpenAI\.
#### vLLM
vLLM est un projet académique de plusieurs universités \(Berkeley, Stanford, San Diego\)\. C’est un projet open\-source qui implémente la [*pagedAttention*](https://arxiv.org/pdf/2309.06180.pdf), créée par les mêmes auteurs\.<br>
La librairie Python est très simple à installer via `pip` :
```shell
pip install vllm
Le serveur se lance avec une simple ligne de commande :
```shell
python -m vllm.entrypoints.openai.api_server --model mistralai/Mistral-7B-Instruct-v0.1
Ou vous pouvez utiliser Docker comme pour TGI. Cependant l’installation est tellement simple que ça n’offre pas de réel avantage pour un test : <br><br>```shell<br>docker run --runtime nvidia --gpus all -v ~/.cache/huggingface:/root/.cache/huggingface
-p 8000:8000 --ipc=host vllm/vllm-openai:latest --model mistralai/Mistral-7B-Instruct-v0.1
Dans tous les cas, les poids sont automatiquement téléchargés depuis HuggingFace. Le framework les charge dans le GPU puis démarre FastAPI pour servir le modèle.
L’intérêt de vLLM est sa grande facilité d’installation et d’utilisation ainsi que sa compatibilité avec un grand nombre d’architectures de LLM. C’est l’un des meilleurs frameworks en termes de vitesse d’inférence (nombre de tokens générés par seconde). Cela vient de la mise en cache de matrices pendant les calculs, de gestion intelligente de batchs, et de la ré-écriture d’opérations CUDA pour limiter les aller-retours entre la mémoire CPU et GPU.
La compatibilité avec le protocole OpenAI est un atout majeur de vLLM depuis sa création. Avant la version 1.4 de TGI, c’était le seul framework optimisé avec accélération GPU qui proposait cela. Les deux sont aujourd’hui équivalents dans le cadre de ce test, même si des différences persistent, comme la quantité de mémoire requise (vLLM est plus gourmand). La vitesse d’inférence de vLLM est similaire à celle de TGI pour la même requête :

Figure 8 : Requête via vLLM
Les logs du serveur sont clairs et permettent d’évaluer rapidement la vitesse en tokens par seconde ou de résoudre les erreurs potentielles (figure 9).

Figure 9 : Logs de vLLM pour une génération
TensorRT-LLM
TensorRT est un moteur d’inférence développé par Nvidia pour le deep learning. Il fonctionne avec Triton, le serveur d’inférence de Nvidia (qui dans ce cas remplace Rust ou FastAPI). TensorRT-LLM est une surcouche de cette librairie, avec une API Python spécialement pour les LLM.
Ce framework est moins connu et populaire que les précédents. On le voit au nombre d’étoiles du projet sur Github (5k vs 7k pour TGI et 15k pour vLLM). Cependant, vu la position de leader de Nvidia sur le marché des cartes graphiques (leur valorisation explose depuis un an), il pique la curiosité. On peut s’attendre à des optimisations très fines de la part du constructeur de ce composant central de l’IA générative.
TensorRT-LLM compile les modèles pour créer des moteurs efficients optimisés spécialement pour les GPU Nvidia. Les poids du modèle sont transformés en un fichier .engine qui est au cœur de l’inférence. Les étapes pour obtenir cet engine et l’utiliser sont beaucoup plus complexes que pour les autres frameworks.
Pour commencer, vous devez installer le nvidia-container-toolkit afin de permettre à Docker d’accéder aux GPU sur votre machine.
À partir de là, il y a plusieurs possibilités pour installer et démarrer le serveur. La documentation peut être assez lacunaire sur le sujet. Mistral donne quelques liens utiles mais il semble que construire le fichier engine puis le déployer en deux étapes indépendantes ne fonctionne pas à la date de rédaction de cet article pour des problèmes de compatibilité entre les dernières versions de tensorrt_llm_backend, le backend utilisé par TensorRT-LLM pour le moteur d’inférence, et Triton inference server (version pré-construite du conteneur NGC). Pour faire fonctionner le test, nous avons essayé plusieurs méthodes et finalement nous avons dû recompiler une grande partie des dépendances.
Commencez par cloner le repo Github de tensorrtllm_backend sur votre machine :
```shell
git clone https://github.com/triton-inference-server/tensorrtllm_backend.git cd tensorrtllm_backend
Si vous n'avez pas installé git-lfs
apt-get update && apt-get install git git-lfs -y git lfs install git submodule update --init --recursive
```
Vous devez ensuite construire l’image Docker de Triton Inference Server avec le backend pour TensorRT-LLM depuis les sources. Cette étape va également installer la librairie TensorRT-LLM dans l’image. Cette opération est longue (environ 2h pour nous, vous pouvez aller vous servir un café voire une dizaine), mais nous a permis d’éviter les incompatibilités de version et les erreurs au démarrage du serveur :shell<br>DOCKER_BUILDKIT=1 docker build -t triton_trt_llm -f dockerfile/Dockerfile.trt_llm_backend .<br>
Une fois que l’image est construite, lancez le conteneur et accédez à sa ligne de commande (nous vous conseillons de monter le volume du dossier racine où vous avez déjà téléchargé les poids du modèle, cela permettra de gagner du temps par la suite) :shell<br>docker run --rm -it --net host --shm-size=1g --ulimit memlock=-1 --ulimit stack=67108864 --gpus all -v /your/root/folder:/workspace -w /workspace triton_trt_llm bash<br>
Dans le conteneur, vous devez maintenant convertir les poids en checkpoints, puis les compiler pour obtenir l’engine :
```shell
# Convertir les poids en checkpoints, model_dir doit contenir les poids tels qu'ils sont sur HuggingFace python3 convert_checkpoint.py --model_dir /your/path/to/mistral/files --output_dir /workspace/tllm_checkpoint_1gpu_mistral_7b --dtype float16
Compiler les poids en engine
trtllm-build --checkpoint_dir /workspace/tllm_checkpoint_1gpu_mistral_7b --output_dir /workspace/mistral/7B/trt_engines/fp16/1_gpu/ --gemm_plugin float16 --max_input_len 32256 --paged_kv_cache enable --remove_input_padding enable --gpt_attention_plugin float16
```
Si tout s’est bien passé vous devez avoir des sorties similaires à celles-ci :

Figure 10 : Conversion des poids HuggingFace pour TensorRT-LLM
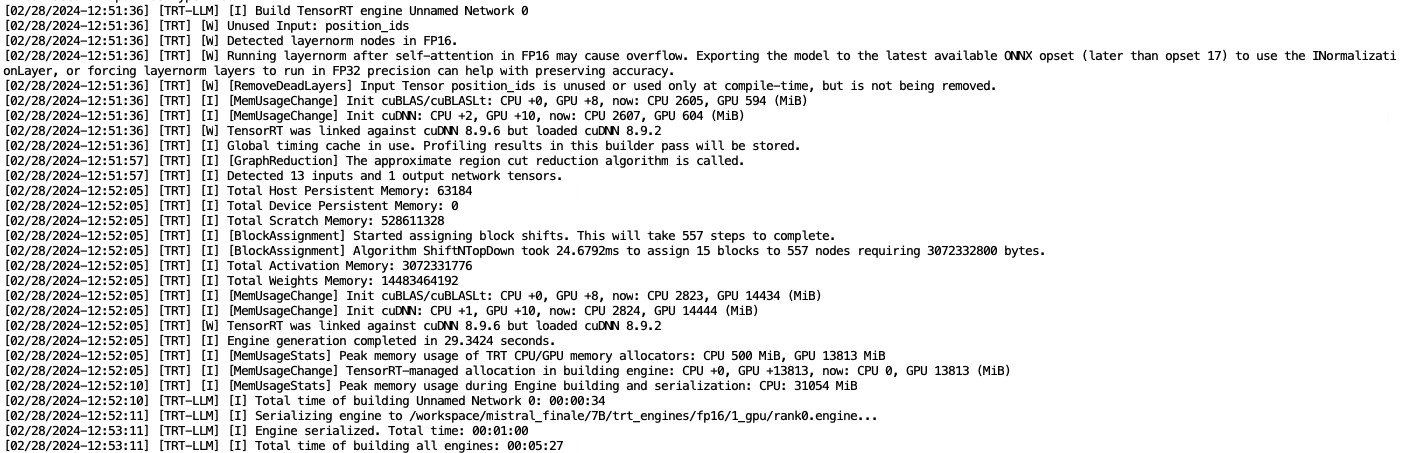
Figure 11: Construction de l’engine TensorRT-LLM pour Mistral
Il faut ensuite intégrer cet engine dans le backend. Pour cela, copiez l’exemple de repo de modèle triton :
```shell
cd /workspace/tensorrtllm_backend mkdir triton_model_repo
cp -r all_models/inflight_batcher_llm/ensemble triton_model_repo/ cp -r all_models/inflight_batcher_llm/preprocessing triton_model_repo/ cp -r all_models/inflight_batcher_llm/postprocessing triton_model_repo/ cp -r all_models/inflight_batcher_llm/tensorrt_llm triton_model_repo/
```
Dans chacun des sous-dossiers (ensemble, preprocessing, postprocessing, tensorrt_llm) vous allez trouver la même structure avec un dossier 1/ et un fichier pbconfig.txt. D’abord, il faut éditer ces configurations. Voici un exemple fonctionnel :
```shell
export MISTRAL_SOURCE_FOLDER=/your/path/to/mistral/files
preprocessing
python3 tools/fill_template.py -i triton_model_repo/preprocessing/config.pbtxt tokenizer_dir:${MISTRAL_SOURCE_FOLDER},tokenizer_type:llama,triton_max_batch_size:64,preprocessing_instance_count:1
tensorrt_llm
python3 tools/fill_template.py -i triton_model_repo/tensorrt_llm/config.pbtxt triton_max_batch_size:64,decoupled_mode:False,max_beam_width:1,engine_dir:/tmp/llama/7B/trt_engines/fp16/4-gpu/,max_tokens_in_paged_kv_cache:2560,max_attention_window_size:2560,kv_cache_free_gpu_mem_fraction:0.5,exclude_input_in_output:True,enable_kv_cache_reuse:False,batching_strategy:inflight_batching,max_queue_delay_microseconds:600
postprocessing
python3 tools/fill_template.py -i triton_model_repo/postprocessing/config.pbtxt tokenizer_dir:${MISTRAL_SOURCE_FOLDER},tokenizer_type:llama,triton_max_batch_size:64,postprocessing_instance_count:1
ensemble
python3 tools/fill_template.py -i triton_model_repo/ensemble/config.pbtxt triton_max_batch_size:64
```
Puis, copiez les artefacts de compilation dans tensorrt_llm/1 :shell<br>rm triton_model_repo/tensorrt_llm/1/* cp /workspace/mistral/7B/trt_engines/fp16/1_gpu/* triton_model_repo/tensorrt_llm/1/<br>
Finalement, démarrez le serveur Triton :shell python3 scripts/launch_triton_server.py --world_size=1 --model_repo=/workspace/tensorrtllm_backend/triton_model_repo<br>
Si tout s’est bien passé vous devriez voir les modèles avec le statut READY et le serveur doit avoir lancé 3 services sur des ports distincts : 8000, 8001, 8002.
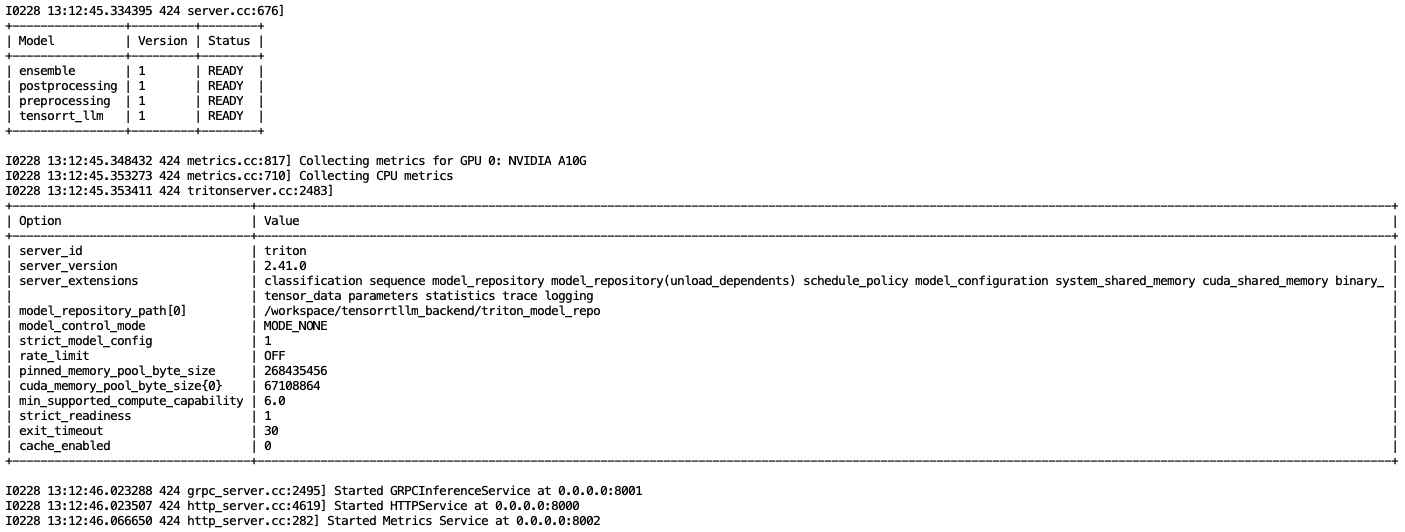
Figure 12 : le serveur Triton est prêt à recevoir des requêtes
À ce stade, il ne reste plus qu’à requêter le serveur :
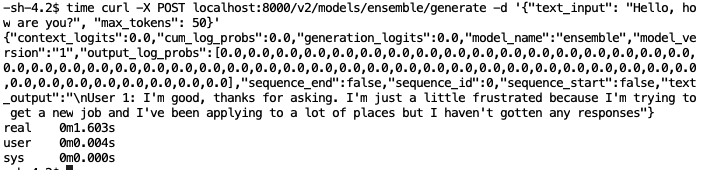
Figure 13 : Requête à Mistral 7B via Triton
Le temps d’inférence est comparable aux frameworks précédents mais la réponse est très différente. Plutôt que de répondre pour lui-même, le modèle s’engage dans une sorte de jeu de rôle et complète la requête avec la réponse d’un utilisateur fictif. Cela peut être dû aux différentes transformations et compilations…
Vu la complexité d’installation du serveur par rapport à vLLM et TGI, nous ne recommandons pas TensorRT-LLM et Triton Inference Server dans le cadre de tests et de PoC. Là où les autres frameworks nous ont permis de démarrer un serveur et de le requêter en quelques minutes (10-15mn si on compte les différentes installations et téléchargements), cela nous a pris plusieurs heures pour le framework Nvidia.
Malheureusement, le protocole d’API de Triton n’est pas compatible avec celui d’OpenAI, ce qui le rend également plus difficile à intégrer. Nvidia s’attend à ce que les utilisateurs mettent en place un API Gateway devant le serveur Triton pour reproduire le protocole, plutôt que d’adapter directement le projet aux standards OpenAI. Sinon, un projet annexe sur Github ajoute la compatibilité (nous ne l’avons pas testé à date).
Triton Inference Server est un serveur optimisé pour les inférences sur CPU et GPU. Il a été conçu pour s’intégrer avec plusieurs backends:
- TensorRT-LLM (celui que nous avons vu)
- PyTorch
- Tensorflow
- OpenVINO
- ONNX…
La liste complète est disponible ici. La solution proposée est une plateforme complète standardisée et unifiée pour industrialiser des modèles construits à partir des librairies les plus populaires. Elle peut donc s’avérer intéressante pour certaines organisations, même si sa mise en place est complexe. Elle est notamment listée dans la documentation de Mistral AI, avec vLLM, pour déployer leurs modèles (ce qui a en partie motivé notre test de ce framework).
Récapitulatif
Nous avons vu plusieurs options pour déployer un LLM i.e permettre des échanges en langage naturel via une API. Nous avons résumé les temps d’inférence pour la requête simple “Hello, how are you?”.
Attention : Ce tableau est donné à titre indicatif pour résumer les résultats de nos tests. Il ne constitue pas une évaluation rigoureuse des performances des différents frameworks (ex: les réponses ne sont pas exactement les mêmes, nous n’avons fait qu’une seule requête…). Ce post medium compare TGI et vLLM avec le calcul de RPS, throughput, latence… Les résultats peuvent aussi varier en fonction de l’architecture du LLM.
| Llama-cpp-python (local, CPU) | Ollama (local, CPU) | vLLM (distant, GPU) | TGI (distant, GU) | TensorRT-LLM + Triton (distant, GPU) | |
|---|---|---|---|---|---|
| Temps d’inférence (secondes) | 13,383 | 11,596 | 1,307 | 1,186 | 1,603 |
Tableau 1 : résumé des temps d’inférence de Mistral 7B pour différents frameworks de déploiement
Sans grande surprise, le déploiement local n’est pas une option viable pour une industrialisation. Celle-ci est plus adaptée pour des tests ou des cas d’usages précis où la souveraineté et la confidentialité sont prioritaires et qu’un petit modèle convient (par exemple, un copilot souverain local avec un “petit” LLM spécialisé en complétion de code).
Le déploiement sur une machine distante avec une carte graphique permet de s’approcher des performances d’OpenAI en termes de latence et de vitesse d’inférence. Cette option permet de construire la base d’un produit utilisable à base de LLM. Cependant, nous sommes encore loin d’égaler les APIs propriétaires sur le passage à l’échelle, la résilience, le logging…
Comment construire des produits GenAI privés ?
Nous avons vu la première étape dans la partie précédente : le déploiement.
Celle-ci nous permet de construire une API qui est la base de produits comme ChatGPT ou DALL-E.
Une API peut tout à fait être en elle-même un produit monétisable, qui s’adresse à une population de développeurs. L’API d’OpenAI a d’ailleurs un support et une facturation, et c’est l’une des sources de revenus de l’entreprise avec les abonnements ChatGPT Plus.
Cependant, notre API avec une seule machine n’ira pas bien loin. Elle est complètement incapable de gérer des centaines de milliers de requêtes, voire des millions comme le fait OpenAI. Dans cette partie, nous allons proposer des pistes pour fiabiliser notre API et en faire un produit utilisable, au moins à l’échelle de votre équipe, voire d’une organisation de taille modeste.
Les problèmes principaux que nous devons adresser sont :
- La capacité à passer à l’échelle : comment gérer plus d’utilisateurs ? Simultanément ?
- La résilience : comment faire en cas de problème ?
- L’authentification : qui a le droit d’accéder à mon API ?
- La journalisation : quelles données ont été échangées via l’API ? comment récupérer les informations sur le fonctionnement ?
Pour répondre à ces enjeux, nous proposons l’architecture suivante, basée sur le modèle C4 :
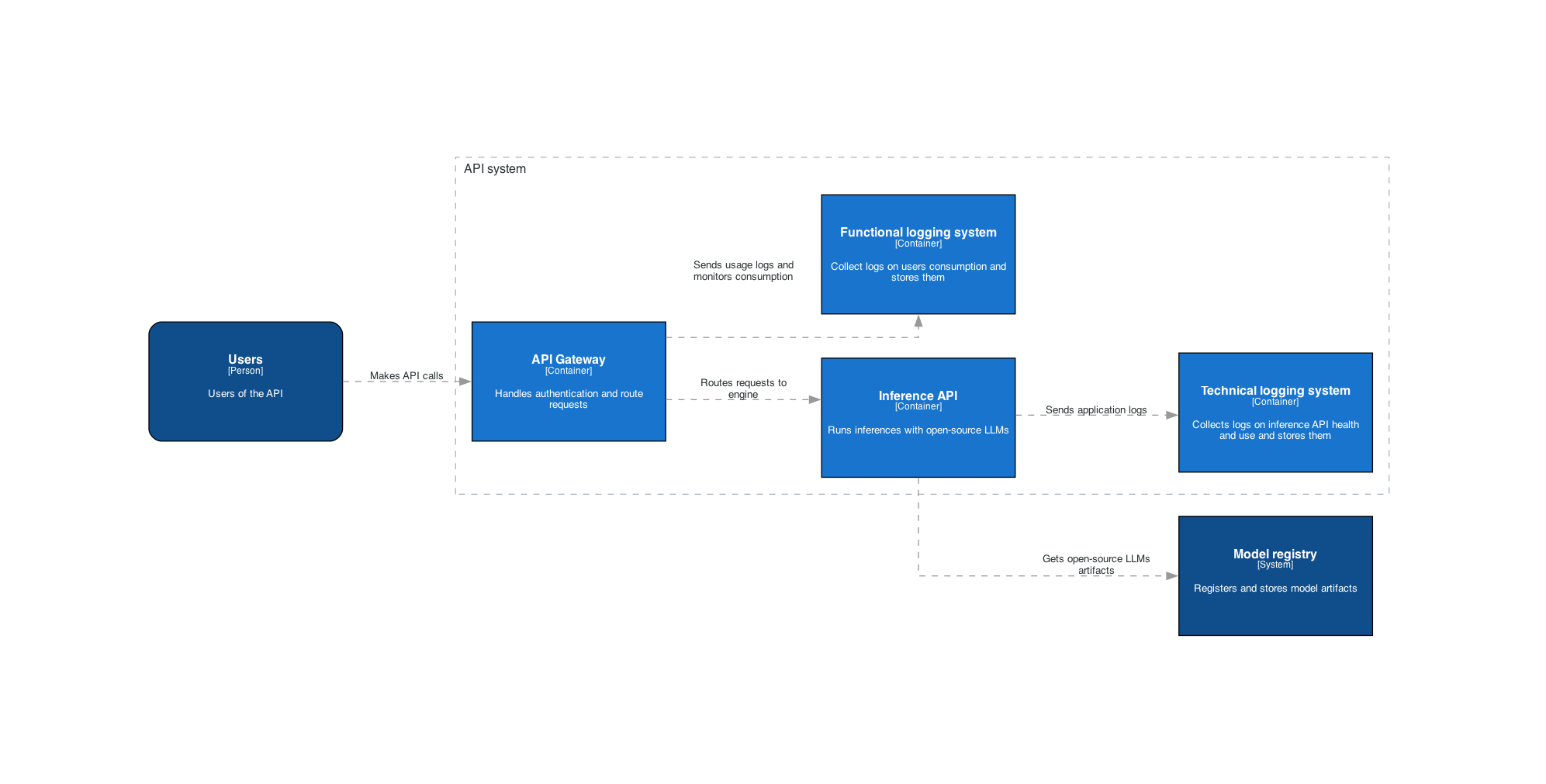
Figure 13 : Architecture haut niveau de l’API
Celle-ci s’arrête au niveau Container du modèle C4 afin de rester suffisamment générique. Pour aller plus loin dans l’implémentation de chaque composant, nous présentons une piste chez les éditeurs cloud principaux, GCP, Azure, et AWS et une piste open source :
- API Gateway
- Cloud : Tous les éditeurs cloud ont un service correspondant
- Open source : Kong est un API Gateway populaire (37k étoiles sur Github) qui vient d’annoncer de nouveaux plugins pour l’IA générative
- Cette partie peut intégrer l’authentification des utilisateurs
- Inference API
- Cloud : vous pouvez utiliser GCP Vertex AI endpoints, AWS Sagemaker endpoints, Azure ML endpoints
- Open source : des conteneurs vLLM ou TGI dans un cluster Kubernetes
- Logging system (Nous faisons une différence fonctionnelle entre les logs de suivi de consommation et les logs techniques de santé de l’API. Dans les faits, ça peut être le même système).
- Cloud : Tous les éditeurs cloud ont un service correspondant
- Open source : logstash ou fluentd pour la collecte et elasticsearch pour le stockage et la recherche
Vous pouvez utiliser HuggingFace Hub comme registre de modèle, ou alors utiliser votre propre gestionnaire de version ou d’artefacts.
Utiliser une stack entièrement open source pour construire ce système est plus coûteux, à la fois en temps et en effort de développement, mais vous permet de garder un maximum de contrôle sur les flux de données. Cela peut être une bonne option si la confidentialité et la souveraineté sont vos priorités.
Une API solide est la fondation de vos futurs produits GenAI. Vous pouvez aussi la monétiser directement. En effet, de nombreuses entreprises comme Together, Perplexity, ou encore Anyscale, vendent leur capacité à servir des modèles facilement pour leurs utilisateurs.
Vous pouvez aussi construire d’autres produits dessus. Le cas d’usage le plus fréquent est une interface de dialogue pour reproduire un chat comme ChatGPT. Celle-ci est souvent couplée à un système RAG (Retrieval Augmented Generation) pour interagir avec vos SI en langage naturel. Si vous ne connaissez pas le RAG, nous avons plusieurs articles qui en parlent sur le blog Octo : Maîtriser le RAG, Construire son RAG grâce à langchain, et le RAG multimodal !
Conclusion
Cet article donne les bases pour déployer et utiliser un LLM open source. Nous présentons également des pistes d’architecture pour en faire une fondation fiable pour vos produits GenAI.
À partir des poids du modèle et fichiers de configuration de Mistral-7B disponibles sur HuggingFace Hub, nous avons pu dialoguer avec le modèle et nous avons donné des possibilités pour construire une API fiable à l’échelle.
La capacité de construire ses propres solutions et les déployer dans un environnement privé est fondamentale pour garder la main sur vos projets et vos données. Au-delà de cet aspect, nous pensons que ces connaissances sont utiles pour les développeurs afin de les aider à mieux appréhender les LLM et plus globalement, les systèmes qu’ils manipulent.
Pour approfondir vos connaissances sur l'utilisation d'outils open source dans le domaine de l'intelligence artificielle, n'hésitez pas à consulter notre article Open-source AI with HuggingFace, qui explore d'autres approches innovantes pour tirer parti des technologies d'IA dans vos projets.
Remerciements à nos relecteurs : Philippe Stepnewski, Emmanuel-lin Toulemonde, Philippe Prados, Florian Bastin, Nicolas Cavallo, Armen Ozcelik, Yannick Drant, Fabien Roussel
FAQ
LLM open source vs ChatGPT : quelle différence ?
ChatGPT est un produit complet bâti sur un modèle propriétaire (GPT-3.5/4) dont les poids ne sont pas publiés. Un LLM open source (Mistral, Llama, Falcon...) expose ses poids publiquement : vous pouvez le télécharger, le modifier et le déployer vous-même. Pas de facturation à l'usage, pas de données envoyées chez un tiers.
Peut-on faire tourner un LLM en local sur son ordinateur ?
Oui. Mistral-7B, par exemple, fonctionne sur un MacBook Pro de 32 Go de RAM. Des frameworks comme llama.cpp et Ollama simplifient le déploiement local sans GPU. Pour des modèles plus grands (13B, 70B...), un GPU dédié ou un serveur cloud devient nécessaire.
Pourquoi choisir un LLM open source plutôt qu'une API propriétaire ?
Trois raisons principales. La souveraineté : vos données restent chez vous. La confidentialité : vous contrôlez ce qui est loggé et stocké. Le coût : pour des volumes importants, héberger son propre modèle revient souvent bien moins cher qu'une API à la requête.
Bibliographie
- Achieve 23x LLM Inference Throughput & Reduce p50 Latency. (s. d.). Anyscale. https://www.anyscale.com/blog/continuous-batching-llm-inference
- Bastin, F. (2022a, septembre 16). Comment utiliser le mutlimodal pour améliorer un chatbot RAG ? - OCTO Talks ! OCTO Talks ! https://blog.octo.com/comment-utiliser-le-mutlimodal-pour-ameliorer-un-chatbot-rag
- Bastin, F. (2022b, septembre 16). Construire son RAG (Retrieval Augmented Generation) grâce à langchain : L’exemple de l’Helpdesk d’OCTO - OCTO Talks ! OCTO Talks ! https://blog.octo.com/le-chatbot-docto-langchain-rag-et-code-associe
- Cavallo, N. (2022, 16 septembre). Maîtriser le RAG - Retrieval Augmented Generation - OCTO Talks ! OCTO Talks ! https://blog.octo.com/maitriser-le-rag-retrieval-augmented-generation
- From OpenAI to Open LLMs with Messages API on Hugging Face. (s. d.). https://huggingface.co/blog/tgi-messages-api
- Gadwal, P. S. (2023, 1 décembre). Deciphering the Giants : A Comprehensive Comparison of Text Generation Interface (TGI) and vLLM. Medium. https://medium.com/@premsaig1605/deciphering-the-giants-a-comprehensive-comparison-of-text-generation-interface-tgi-and-vllm-26da3976d0e9
- Llama 2 vs. GPT-4 : Nearly As Accurate and 30X Cheaper. (s. d.). Anyscale. https://www.anyscale.com/blog/llama-2-is-about-as-factually-accurate-as-gpt-4-for-summaries-and-is-30x-cheaper
- Massiot, A. (2022, 16 septembre). Sous le capot des bases de données vectorielles - OCTO Talks ! OCTO Talks ! https://blog.octo.com/sous-le-capot-des-bases-de-donnees-vectorielles-(vector-databases)
- Taylor, B. (2018, 10 avril). What Breaking the 4-Minute Mile Taught Us About the Limits of Conventional Thinking. Harvard Business Review. https://hbr.org/2018/03/what-breaking-the-4-minute-mile-taught-us-about-the-limits-of-conventional-thinking