Comment utiliser le mutlimodal pour améliorer un chatbot RAG ?
“J’ai un histogramme comparatif dans mon PDF, pourquoi mon chatbot n’est-il pas capable de s’en servir pour me répondre ?”
Générer le résumé d’un graphe, extraire de manière structurée un tableau, identifier les images pertinentes dans les documents, venez découvrir comment booster votre RAG grâce à l’usage raisonné des modèles multimodaux.

Introduction
Les approches RAG (Retrieval Augmented Generation) figurent parmi les plus utilisées pour l’exploitation des moteurs de langages.
Les “Generative AI powered Chatbot” exploitent l’architecture RAG et simplifient la recherche documentaire des employé.e.s des entreprises avec lesquelles nous travaillons.
Les produits qui en découlent sont nombreux : assistants RH & IT augmentés, assistants business analystes pour la synthèse ou la comparaison de rapports, détecteurs de documentation absente ou obsolète… (voir aussi nos bonnes pratiques pour l’évaluation RAG)
Cependant, ces assistants n’étaient pas en mesure de traiter et d’interpréter des images et schémas complexes dans leur base documentaire… jusqu’à l’arrivée du Multimodal avec GPT 4 Vision, LLava ou Gemini dont la version 1.5 est sortie le 15 février.
Alors c****omment détecter, choisir et résumer des graphiques et tableaux dans vos sources documentaires en utilisant le multimodal ?
C’est ce que nous allons résoudre au cours de cet article. Nous supposerons dans un premier temps que les images sont déjà localisées et extraites des documents. Nous verrons ensuite comment les détecter en utilisant les librairies existantes. Nous proposerons enfin de réduire l’usage coûteux (en euros, CO2 et secondes) du multimodal au strict nécessaire.
Cet article s’adresse aux lecteurs ayant déjà une compréhension de l’architecture d’un RAG.
Un repository de code est joint à cet article. Il contient l’intégralité des fonctions et analyses présentées et des expérimentations supplémentaires pour vous aider à intégrer le multimodal et ainsi améliorer la qualité de votre base vecteur.
Qu’est-ce que le multimodal ?
Définition
Les modèles multimodaux sont des modèles neuronaux ayant la capacité d’ingérer différentes modalités de données d’entrées.
L’image, un ensemble de pixels et le texte peuvent être encodés dans un même espace vectoriel.
GPT 4 et Gemini intègrent un text encoder, mais aussi vision encoder leur permettant de traiter les images et le texte.
C’est en ce sens qu’il nous est possible de résumer et restructurer des images contenant des graphiques et d’y incorporer un prompt pour guider le modèle vers la sortie souhaitée.
Disponibilité
L’accès à ces modèles a tout d’abord été limité à certains utilisateurs (private preview) avant de s’étendre à l’ensemble des utilisateurs (public preview). Leur disponibilité générale (GA) varie selon les fournisseurs de modèles de vision, mais leur imminence est évidente. Cette disponibilité permettra à tous leurs utilisateurs de s’en servir pour des projets en production.
Quelques contraintes sont cependant non négligeables à l’heure actuelle. Le temps de réponse des modèles vision est long. Une requête API pour un modèle vision non turbo peut facilement atteindre 20 secondes. S’en servir en brut**e force sur une base documentaire de 10 000 pages est déconseillé, car trop long et coûteux.
De plus, les disponibilités actuelles limitent très fortement la possibilité de parallélisme.
Bien que ces contraintes soient amenées à évoluer avec l’ouverture progressive des modèles multimodaux, n’oublions pas une métrique qui devrait être au cœur de nos projets, l’empreinte carbone de vos modèles.
Cet article s’articulera donc autour de l’usage raisonné des modèles multimodaux.
Exploitation des tableaux de données sans l’usage du multimodal
Comment optimiser l’extraction d’un tableau dans les PDF, PPT(x) ?
Lançons-nous avec une problématique que vous pourriez rencontrer lors du traitement de votre documentation et son ingestion dans une base vecteur : la gestion des tableaux.
Bien que certaines étapes sont nécessaires pour conserver la structure d’un tableau au détriment de son extraction texte, ce premier exemple ne requiert pas forcément l’utilisation d’un modèle multimodal.
Prenons le tableau suivant :
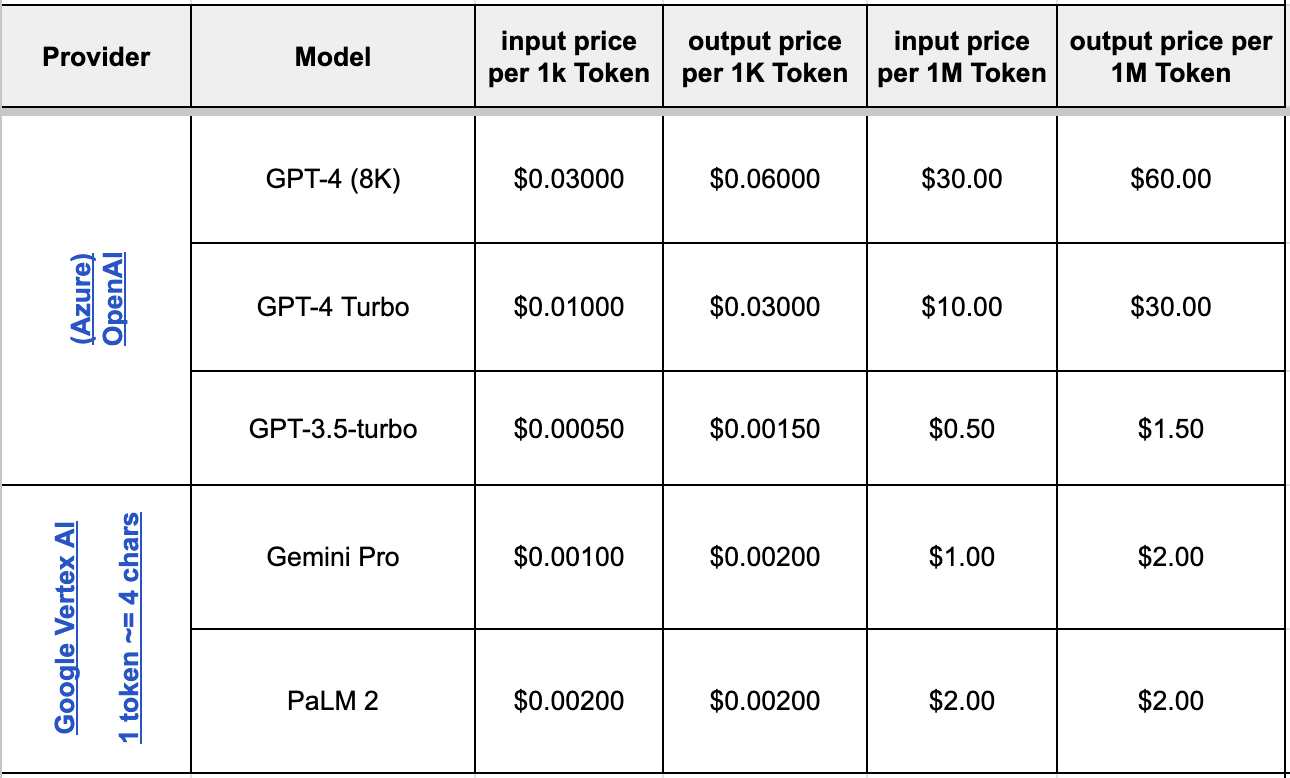
Figure 1 : Notre tableau exemple - C**omparatif des coûts par tokens pour chaque modèle
L'objectif est de l’intégrer dans notre base documentaire afin d’obtenir la réponse à la question suivante :
Peux-tu trier les LLM des cloud Azure et GCP selon leurs coûts par milliers de tokens ?
Insérons le tableau de la Figure 1 dans un fichier PDF (l’approche pour un PPTX est couverte dans le repository GitHub associé à l’article). Ce tableau sera sous deux formats, un format texte et un format image. Nous utilisons Unstructured pour collecter le texte depuis ce powerpoint.
from unstructured.documents.elements import Element
pdf_path = "path_to_my_pdf"
elements: List[Element] = partition_pdf(
filename=pdf_path,
strategy="hi_res",
infer_table_structure=True, # add a text_as_html metadata, useful to keep structure
include_page_breaks=True, # useful to join extracted text by page before chunking
chunking_strategy='auto'
Unstructured possède plusieurs spécificités intéressantes :
- L’extraction du texte dans les documents en intégrant une étape d’OCR selon notre paramétrisation (seulement sur les PDFs pour l’instant, la fonctionnalité n’étant pas disponible pour les PPTs).
- La détection des types de blocs contenus dans nos documents (table, image, titre, texte).
- Le formatage d’une table au format HTML avec l’option infer_table_structure.
Pour rappel, deux formats du même tableau ont été insérés dans notre document initial.
Le premier, sous format texte, a bien été détecté. Le second sous format image n’a pas été détecté. En passant sur PDF, l’OCR aurait récupéré le texte du tableau en perdant sa structure, rendant complexe son interprétation pour un moteur de langage.
Une métadonnée text_as_html est disponible pour l’élément faisant référence au tableau (sous format texte) et contient le code HTML pour le reconstruire.
Voici la synthèse des extractions réalisées selon ces différents cas de figure : 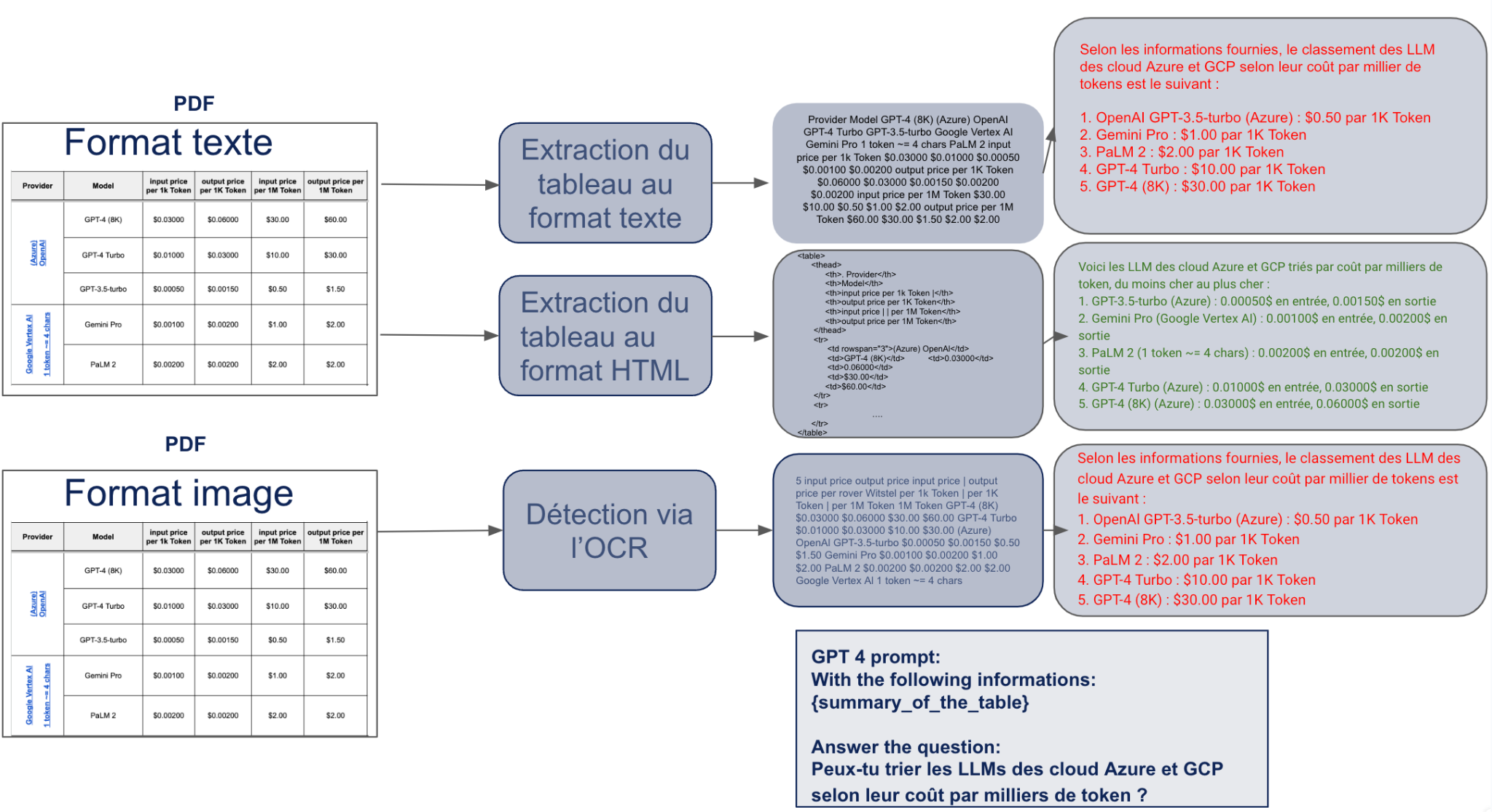
Figure 2 : Les différentes extractions d’un tableau selon son type (tableau, image) pour un PDF avec Unstructured
Analysons les réponses à notre question suite aux différentes extractions du tableau :
- La seule réponse fiable est issue du formatage HTML du tableau, possible uniquement en format texte.
- L’extraction du tableau au format texte avec Unstructured (séparateur tabulaire, saut de ligne) n’est pas toujours suffisante pour un moteur de langage, notamment en cas de valeurs manquantes et en amont d’une étape de chunking.
On a supposé ici que notre retriever a retrouvé le chunk relatif à l’extraction du tableau, et que sa sémantique est proche de la question. En réalité, ce ne sera pas forcément le cas. Nous développons ce point dans la partie suivante.
Astuce : Le chunk contenant notre tableau sous format HTML est de 408 tokens. Dans le cas du PowerPoint, en remplaçant le format HTML par un tableau dont les cellules sont séparées par des ‘|’, on réduit le tableau à 217 tokens sans altérer la qualité de la réponse. Cette méthode Pandas est la plus adaptée pour transformer un tableau HTML en tableau dont les cellules sont séparées par des ‘pipe’. Pandas utilise LXML en premier lieu pour le parsing avant d’utiliser Beautiful Soup en cas d’échec.
En conclusion :
- Dans le cas d’un tableau au format texte, l’extraction HTML du tableau avec Unstructured et sa transformation pour limiter son nombre de tokens est l’approche d’ingestion dans la base documentaire la plus performante.
- Conserver un format HTML approximatif dû à une mauvaise extraction tableau (dans le cas d’OCR notamment) peut s’avérer être la bonne solution. Les moteurs de langages sont capables de détecter ces anomalies et de vous répondre correctement
- Au format image, l’extraction par l’OCR semble être déconseillée. Les valeurs manquantes et la perte de structure rendent son interprétation très compliquée.
Vous trouverez dans ici et ici le code relatif à cette partie, avec un approfondissement sur le type de réponse selon le choix (HTML, texte) et le type de documents d’origine (PPTX, PDF) des tableaux.
Voyons maintenant comment améliorer sa sémantique et optimiser notre retriever.
Comment améliorer la sémantique d’un tableau extrait ?
Considérons que notre tableau est bien extrait et étudions sa sémantique et son embedding.
En prenant le tableau suivant :

Figure 3 : Tableau en format texte extrait par Unstructured au format HTML
Ainsi que son format en délimitation “ | ” :
Provider | Model | input price per 1k Token | output price per 1K Token | input price per 1M Token | output price per 1M Token
------------------------------------------------------------------------------------------------------------------------------
(Azure) OpenAI | GPT-4 (8K) | $0.03000 | $0.06000 | $30.00 | $60.00
nan | GPT-4 Turbo | $0.01000 | $0.03000 | $10.00 | $30.00
nan | GPT-3.5-turbo | $0.00050 | $0.00150 | $0.50 | $1.50
Google Vertex AI 1 token ~= 4 chars | Gemini Pro | $0.00100 | $0.00200 | $1.00 | $2.00
nan | PaLM 2 | $0.00200 | $0.00200 | $2.00 | $2.00
Figure 4 : Tableau en format texte extrait par Unstructured au format HTML et transformé tableau texte avec Pandas et une méthode spécifique
Calculons l’embedding (text-embedding-ada-002) de ces deux représentations textuelles et la similarité avec la question :
Peux-tu trier les LLM des clouds Azure et GCP selon leurs coûts par milliers de tokens ?
html_table_question_cos_similarity = 0.7975
pipe_table_question_cos_similarity = 0.8041
Résumons en anglais les deux formats de tables extraites à l’aide de GPT 4 :
from config.llm import GPT_4
from operator import itemgetter
from langchain.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
def summarize_table(llm, prompt_text, extracted_table: str) -> str:
prompt = ChatPromptTemplate.from_template(prompt_text)
summarize_chain = (
{
"extracted_table": itemgetter("extracted_table")
}
|
prompt
|
llm
|
StrOutputParser()
)
return summarize_chain.invoke(input={"extracted_table": extracted_table})
prompt_summarization = """From the following HMTL or | cells separated table:
----------
{extracted_table}
----------
Summarize the table with key informations.
"""
pipe_table_summary = summarize_table(
llm=GPT_4,
prompt_text=prompt_summarization,
extracted_table=pipe_table,
)
html_table_summary = summarize_table(
llm=GPT_4,
prompt_text=prompt_summarization,
extracted_table=html_table
)
Les résumés sont les suivants :

Figure 5 : Résumé du tableau avec séparateur ‘|’

*Figure 6 : Résumé du tableau extrait avec balises HTML*
Les similarités de ces résumés avec la question sont les suivantes:
summarized_html_table_question_cos_similarity = 0.8166
summarized_pipe_table_question_cos_similarity = 0.8225
Nous constatons une augmentation de 2 points sur la similarité entre la question et les contenus résumés des tableaux.
L’ajout d’un résumé pour un tableau améliore donc la performance du retriever.
Vous trouverez ici le code relatif à cette partie avec une analyse plus approfondie sur la similarité cross-language et un test sur une autre question.
En conclusion :
- Résumer un tableau permet d’améliorer la qualité du retriever.
- Conserver un lien entre le résumé et le tableau d’origine est nécessaire afin de ne pas insérer d’informations dupliquées dans le contexte.
- Les résumés sont par définition des agrégats d’information et peuvent cependant omettre certains éléments importants des tableaux. L’idéal est de faire pointer le résumé vers le tableau extrait d’origine et insérer le tableau dans le contexte lorsque la similarité du résumé ou du tableau extrait satisfait le retriever.
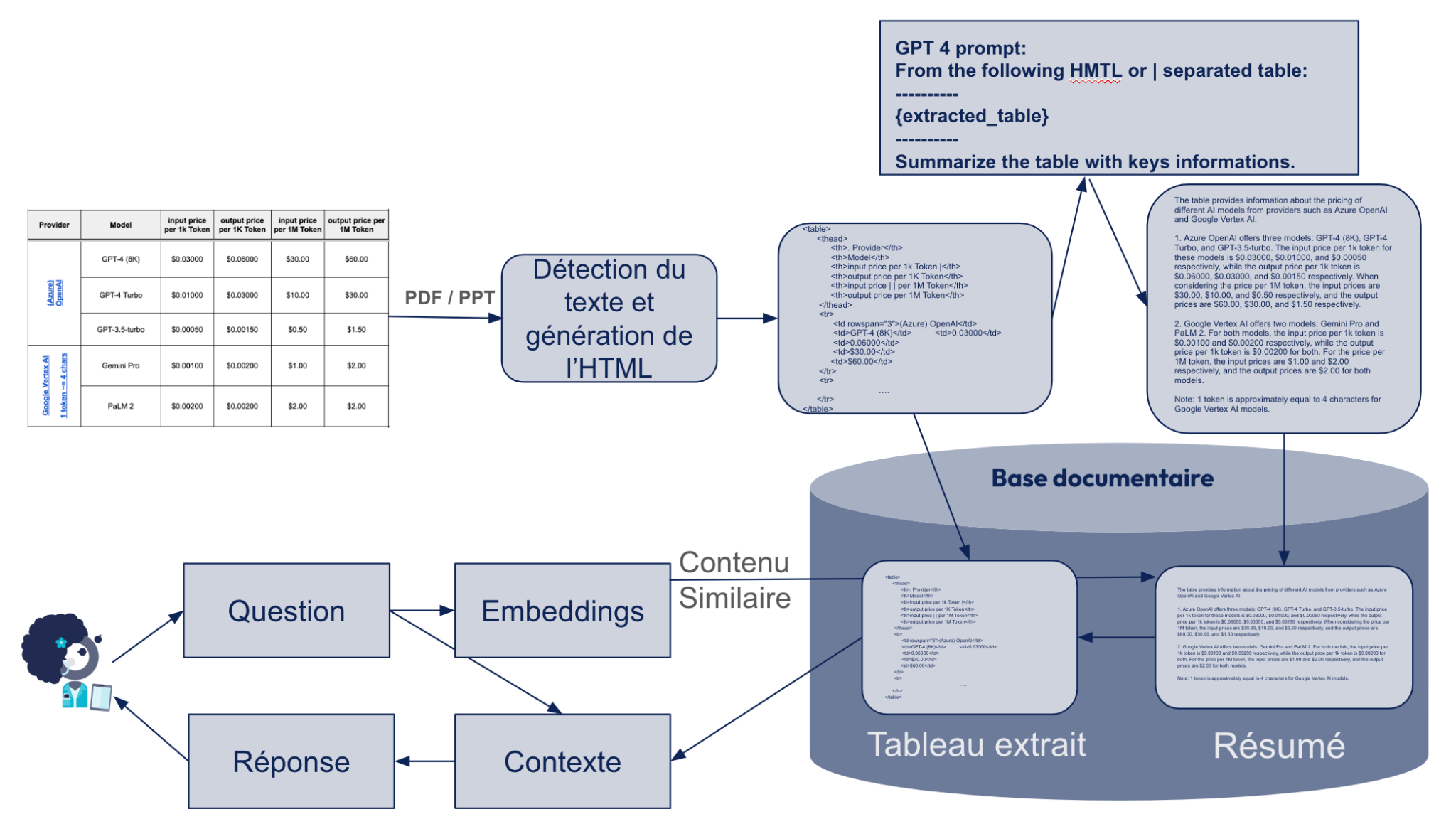
Figure 7 : Architecture RAG possible pour l’extraction de tableaux. Le résumé est ‘retrouvé’ par le retriever, mais le format html est donné en contexte
Extraire les informations d’un tableau au format image
Lorsque le tableau est au format image, nous avons vu que l’extraction OCR faîte par la librairie Unstructured n’était pas convaincante. Dans cette partie, nous réaliserons une étude des différents outils existants sur le marché pour améliorer cette détection.
Les modèles OCR sont généralement composés de deux parties :
- Un module de détection des zones textuelles
- Un module de reconnaissance textuelle
En 1989, Yann LeCun propose un premier modèle d’OCR en utilisant des réseaux convolutifs ainsi que des couches fully connected. Je vous invite à aller voir cette vidéo démonstrative et la description associée.
Une trentaine d'années plus tard, les approches OCR évoluent. Le développement de la recherche pour le traitement de l’image avec notamment les Mask R-CNN améliorent considérablement la détection des zones de texte. Les modèles récurrents tels que le LSTM et plus récemment, les modèles transformers améliorent la partie de reconnaissance du texte.
Les librairies existantes sont nombreuses et permettent de résoudre l’un des deux ou les deux modules constitutifs d’un modèle OCR:
- Yolo V8 propose des modules de détection et d’entraînement de modèles pour des tâches spécifiques relatives à la détection des zones de texte.
- Donut propose une approche OCR axée sur les Transformer avec un module améliorant la qualité de détection sur des langues moins communes
- Tesseract est une librairie très connue proposant une approche bi-directionnel axées sur les LSTM
- Détectron 2 est développé par Meta et intègre de nombreux modèles à l’état de l’art pour la détection des zones de texte
- TrOC est une approche axée sur les Transformer et directement disponible sur Hugging Face
Certains clouds tels que Google Cloud avec Document AI ou AWS avec Textract proposent leur outil intégrable facilement pour votre cas d’usage IA. Document AI propose notamment la détection de tableau et fournit un format de sortie conservant la structure du tableau.
Pour l’extraction de tableaux au format image, Tesseract (libraire open source) et Document AI (en service managé) sont les deux outils qui vous seront le plus utiles.
Vous trouverez dans la Figure 8 l’extraction et la structure détectée par Document AI. Cet outil permet d’exploiter pleinement le contexte du tableau sans en perdre la structure.

Figure 8 : Extraction du tableau au format image de la Figure 1 avec Document AI (GCP). L’image est tronquée, mais les colonnes sont toutes détectées
Ce paragraphe clos les contournements possibles du multimodal. Nous vous avions parlé du multimodal en introduction, mais vous avions aussi prévenu que son utilisation est coûteuse et doit s’effectuer de manière raisonnée. Dans la partie suivante, nous verrons comment utiliser le multimodal pour l’exploitation des graphiques au format image.
Synthèse et résumé des graphiques grâce à l’usage du Multimodal
Dans l’immense majorité des cas, les approches OCR ne sont pas suffisantes pour interpréter un graphique. Extraire les valeurs numériques présentes sur les axes, les points ou les barres verticales d’un nuage de points ou histogramme n’est pas suffisant.
Le multimodal devient alors incontournable.
Les différents cas d’utilisation du multimodal
GPT 4 Vision, LLava et Gemini peuvent s’utiliser de différentes manières comme le montre la F**igure 9.
Tout d’abord, le multimodal s’avère intéressant pour l’ingestion des documents dans une base vecteur.
Lorsque la représentation visuelle d’un type de document améliore sa compréhension, l’usage du multimodal a du sens au détriment de son extraction du texte. Dans le cas d’un tableau, la perte de la structure est impactante. En cas de valeurs manquantes ou d’une structure particulière, il devient impossible pour un moteur de langage de l’interpréter. Dans le cas de graphiques, tels que les histogrammes ou les nuages de points, l’extraction texte est complexe, car l’ordre de l’extraction est fondamental.
Ensuite, un modèle multimodal peut être utilisé pour répondre à l’utilisateur. L’usage d’un modèle multimodal à l’inférence (au sens chatbot) offre la possibilité au développeur d’insérer des graphiques au contexte du modèle servant le chatbot. À l’heure actuelle, le temps d’inférence de ces modèles n’offre pas une expérience utilisateur suffisante, mais il est très probable que cela évolue dans les mois à venir.
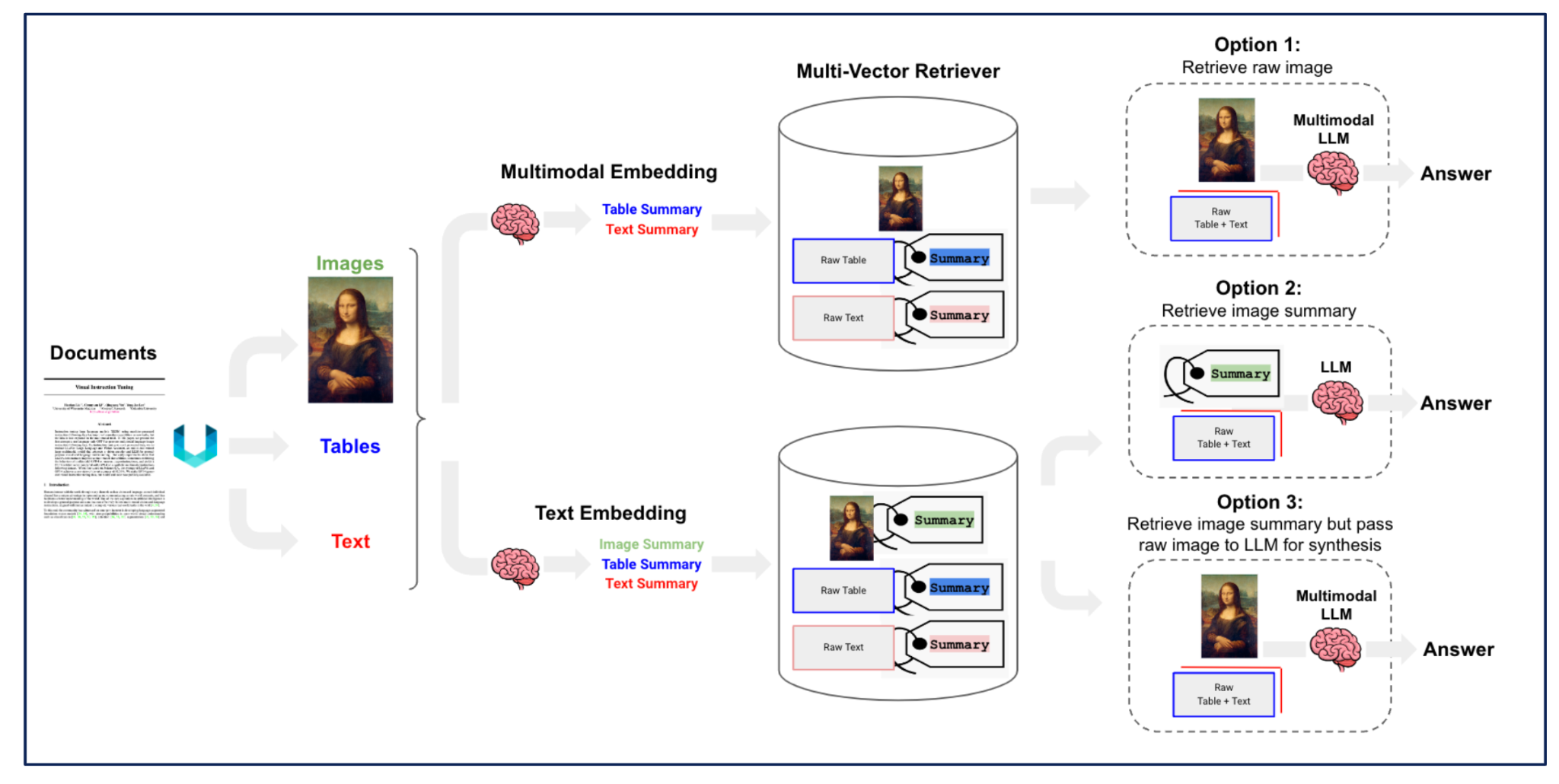
Figure 9 : Les différents cas d’utilisation du multimodal - Source
L’option 1 consiste à générer l’embedding de l’image et à donner l’image en contexte d’un modèle multimodal pour répondre.
L’option 2 consiste à générer un résumé de l’image et collecter l’embedding de son résumé. L’usage du multimodal intervient pour l’insertion dans la base documentaire, mais pas pour la réponse à la question.
L’option 3 est similaire à l’option 2, mais l’image d’origine est donnée en contexte du modèle multimodal pour fournir la réponse.
À l’heure actuelle, l’option 2 est la plus propice, car le temps de réponse API d’un modèle multimodal est long. Ce temps peut être acceptable pour alimenter la base documentaire, mais sera déceptive pour l’utilisateur qui attend une réponse rapide.
Résumer les graphiques dans les documents
Reprenons notre tableau sous format image uniquement et ajoutons le document qui nous a servi d’accroche dans cet article :
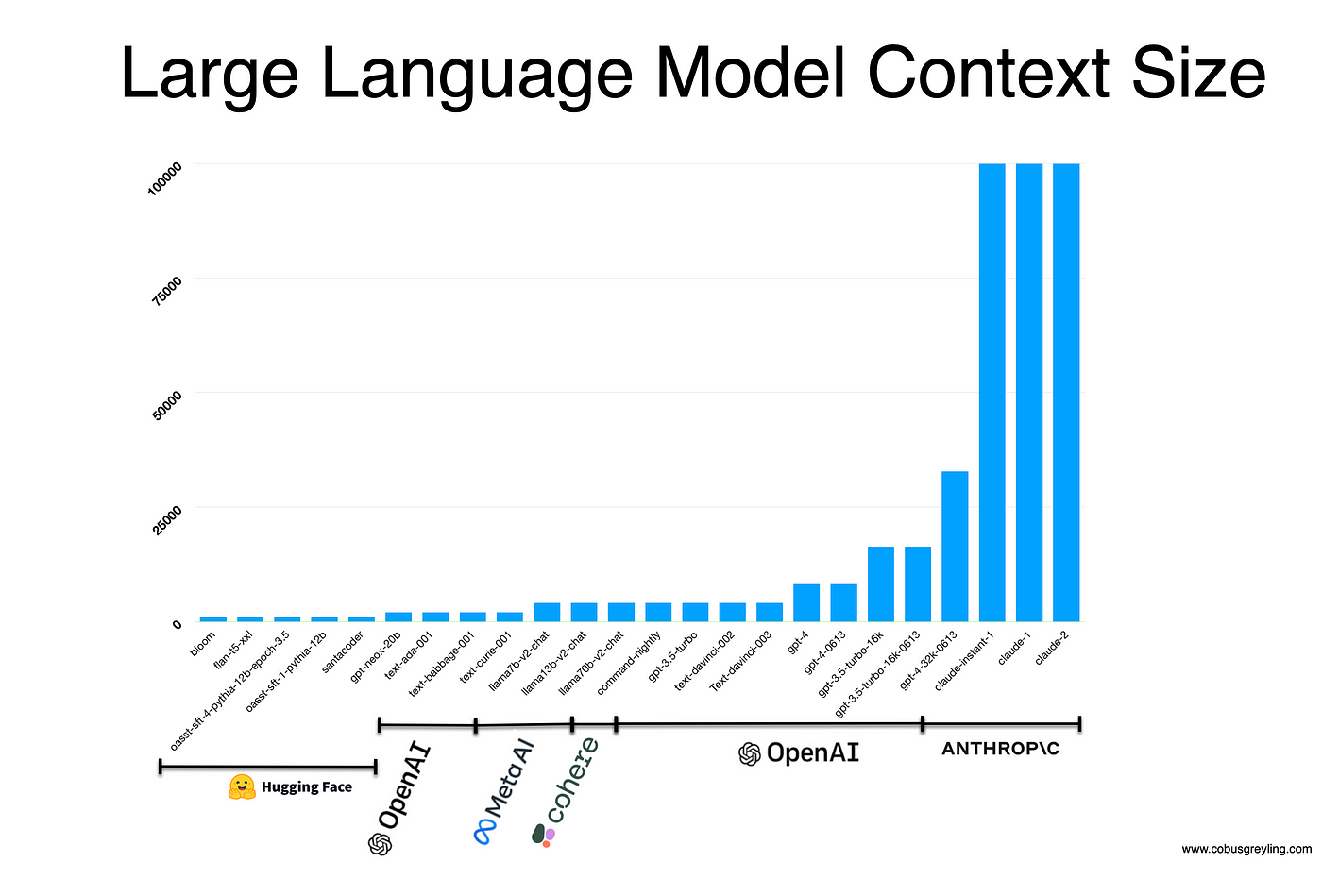
*Figure 10 : Exemple de graphique \- Taille du contexte selon les LLMs*
Ce graphique est assez complexe à exploiter par OCR. Les barres verticales relatives au nombre de tokens maximum par LLM ne sont pas explicitées. Cependant, l'œil humain identifie les modèles Claude comme des modèles à 100K tokens de contexte. Le nombre de tokens du modèle bloom est plus dur à quantifier à l'œil nu.
Essayons d’extraire le texte de ce graphique avec Unstructured :
from unstructured.partition.pdf import partition_pdf
saved_images_directory_path = "../data/pdf/extracted_images"
graph_elements = partition_pdf(
filename=graph_image_pdf_path,
infer_table_structure=True,
strategy="hi_res",
include_page_breaks=True,
chunking_strategy='auto',
extract_images_in_pdf=True, # Save the found images in the document
extract_image_block_output_dir=saved_images_directory_path # Directory path where to save found images in the document
)
“””
-------- Element --------
Element type: <class 'unstructured.documents.elements.Image'>
Element text: FS SP SFTP PP ELSES A 4 é o % % % Sous Gh x jah - s a ¢ ee ee ¢ 2 # s é & © OpenAI ANTHROP\C Py rusgingrace = Fs & = 8 6 fF &
“””
L’OCR n’est pas performant du tout dans ce cas.
Cependant, nous avons ajouté un paramètre afin de récupérer les images détectées dans le document. Elles sont stockées dans notre dossier *data/pdf/*extracted_images:
Figure 11: Figure détectée et sauvegardée par Unstructured. Notez que le titre a été retiré.
Il est donc possible d’automatiser le processus de synthèse des images trouvées dans le document.
Voici la méthode et un exemple de prompt pour tenter de résumer une image en un tableau.
import os
import base64
from config.llm import GPT_4_V
from retrying import retry
from langchain.schema.messages import HumanMessage, SystemMessage
def encode_image(image_path: str) -> str:
"""Encode image to base64"""
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode("utf-8")
@retry(stop_max_attempt_number=3, wait_fixed=60000)
def summarize_image(encoded_image: str, prompt: str) -> str:
"""Apply batch image description from extracted text"""
return GPT_4_V.invoke(
input=[
SystemMessage(
content=[
{"type": "text", "text": prompt},
]
),
HumanMessage(
content=[
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{encoded_image}",
"detail": "high"
},
},
]
)
]
).content
image_filepaths = [os.path.join(saved_image_directory_path, filename) for filename in os.listdir(saved_image_directory_path)]
PROMPT_TABLE_AND_IMAGE_SUMMARIZATION = """
You are an AI assistant that summarizes images containing charts or tables.
For each chart of table in the image:
- If the image contains a chart: summarize the chart as a table
- If the image contains a table: create a table from the table image.
- If it cannot be summarized as a table, provide a detailed explanation of the chart or table.
Also, provide a title of each extracted table or image and a two paragraphs summary.
Add '\n\n' between each table or chart description
"""
for filepath in image_filepaths:
encoded_image = encode_image(filepath)
print(summarize_image(encoded_image, prompt=PROMPT_TABLE_AND_IMAGE_SUMMARIZATION))
Le résumé de GPT 4 Vision pour la Figure 11 est le suivant:
Figure 12 : Résumé de l’image trouvé dans le document PDF correspondant à la Figure 10
Que s’est-il passé ?
Unstructured détecte et sauvegarde les graphiques présents dans les PDFs mais n'inclut pas le contexte environnant tel que les titres, commentaires ou justifications. La description faite de l’image est le nombre de paramètres par moteur de langage et non pas le nombre de token maximum.
La détection de l’image réalisée par Unstructured s’avère donc inadaptée à une exploitation pour synthèse par le biais d’un modèle multimodal, car elle est trop réductrice.
Cependant, Unstructured nous donne une information précieuse, la page du document qui contient l’image. Rien ne nous empêche de collecter la page complète qui contient l’image, à savoir l’image donnée par la Figure 11 incluant le titre du graphique.
Le résumé fourni par GPT 4 Vision pour cette image titrée est le suivant.

Figure 13: Résumé de la Figure 11 en utilisant GPT 4 Vision
Les résultats sont plus performants. GPT 4 Vision s’est aidé du contexte environnant pour décrire le nombre de token par modèle. Ce dernier étant représenté par des barres verticales, il en a fait des approximations.
Il faut toutefois noter que ce type de graphes est assez complexe même pour l'œil humain.
En conclusion, pour l’exploitation des graphiques images, l’usage du multimodal peut être très utile. Sa mise en place consiste en plusieurs étapes :
- La détection des images dans les documents (avec Unstructured pour les PDF ou python-pptx pour les PPTx)
- La prise en compte du contexte environnant à l’image et utile à sa synthèse (avec pdf2image pour les PDF et python-pptx pour les PPTx)
- La gestion de la paramétrisation du modèle multimodal (température, top_p, max_tokens)
- La conservation en métadonnées des images, résumés et tableau issue de l’analyse multimodale d’une image
- Le choix du prompt (synthèse par résumé tableau ou par description non structurée)
Nous détaillons ces différentes étapes dans ce notebook.
Astuce: Généralement, les interfaces chatbots incluent les sources permettant à l’utilisateur de confirmer et d'approfondir sa recherche. Elles s’accompagnent parfois du texte extrait dans la documentation. En quick win, nous vous conseillons d’inclure les images et non pas leur résumé lorsque celles-ci sont utiles au retriever afin d’améliorer l’expérience visuelle de l’utilisateur.
Le lecteur “Data Engineer” pourrait frissonner en lisant cette partie et il n’aurait pas tort. Les PDFs peuvent contenir un volume très importants d’images, dont la plupart ne nécessitent pas un résumé. Le coût computationnel et monétaire du multimodal n’est pas négligeable et il est important de pouvoir le contrôler.
Cette dernière partie vous propose quelques astuces pour identifier les images pertinentes.
Optimisation de l’usage d’un modèle multimodale
CLIP pour la sélection d’image pertinentes
Nous avons déjà expérimenté pour nos clients la synthèse visuelle des images présentes dans les documents PDF et PPT. Cependant, la grande majorité d’entre elles ne nécessitent pas d'être résumées. Les logos, photos et icônes embellissant un document peuvent représenter jusqu’à 90% des images de ce document.
Afin de limiter les appels API aux modèles multimodaux, une première étape de filtrage des images est nécessaire.
Notre objectif est d’analyser chaque image avec un modèle peu coûteux en ressources et d’identifier si elle apporte des informations utiles à notre chatbot.
Nous supposerons dans cette partie qu’une image contenant un graphique ou un tableau est intéressante.
Comment classifier une image en tant que tableau ou graphique ?
La conférence International d’analyse et reconnaissance de document (ICDAR) a déjà abordé ce type de problématiques. Ce papier présente les différents modèles, datasets et leur performance pour la classification de graphiques.
Certains modèles de classification en zero*-shot learning* peuvent aussi être utilisés. Cette tâche de classification étant relativement simple, des petits modèles suffiront. Parmi ces modèles, nous citerons CLIP et sa version Hugging Face très simple d’accès.
Essayons de classifier les images extraites d’un PDF pour ne conserver uniquement les graphiques et les tableaux.
Nous utiliserons le support présentation du Comptoir RAG animé par Nicolas Cavallo en janvier dernier chez Octo. Ce document contient 35 pages et inclut des graphiques, tableaux et autres images n’ayant pas d'intérêt à être résumées.
Commençons par extraires les images et le texte avec Unstructured
from unstructured.partition.pdf import partition_pdf
PDF_PATH = “path_to_pdf”
DETECTED_IMAGE_DIRECTORY = “subdir_of_pdf_path”
elements = partition_pdf(
filename=PDF_PATH,
infer_table_structure=True,
strategy="hi_res",
include_page_breaks=True,
chunking_strategy='auto',
extract_images_in_pdf=True,
extract_image_block_output_dir=DETECTED_IMAGE_DIRECTORY
)
Notre dossier d’images extraites contient 211 images.
Essayons de réduire le nombre d'images à résumer à l’aide de CLIP.
Nous utilisons içi une approche de zero-shot learning. Nous indiquons au modèle CLIP les labels possibles pour chaque image collecté de notre document: graph, table, other:
import os
from typing import List
from PIL import Image
from transformers import CLIPProcessor, CLIPModel
def open_images_from_directory(directory_path: str) -> List[Image.Image]:
images = os.listdir(directory_path)
images = [os.path.join(directory_path, img) for img in images]
images = [Image.open(img) for img in images]
return images
def get_pertinent_images(images: List[Image.Image], labels; List[str]):
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
inputs = processor(text=labels, images=images, return_tensors="pt", padding=True)
outputs = model(**inputs)
logits_per_image = outputs.logits_per_image
probs = logits_per_image.softmax(dim=1)
return probs
LABELS = ["graph", "table", "other"]
images = open_images_from_directory(DETECTED_IMAGE_DIRECTORY)
probs = get_pertinent_images(images, LABELS)
Nous obtenons pour chaque image les probabilités, les valeurs softmax du produit scalaire en l’image et le label.
Regardons par exemple les images associées aux labels graph ayant une probabilité supérieure à 90%.
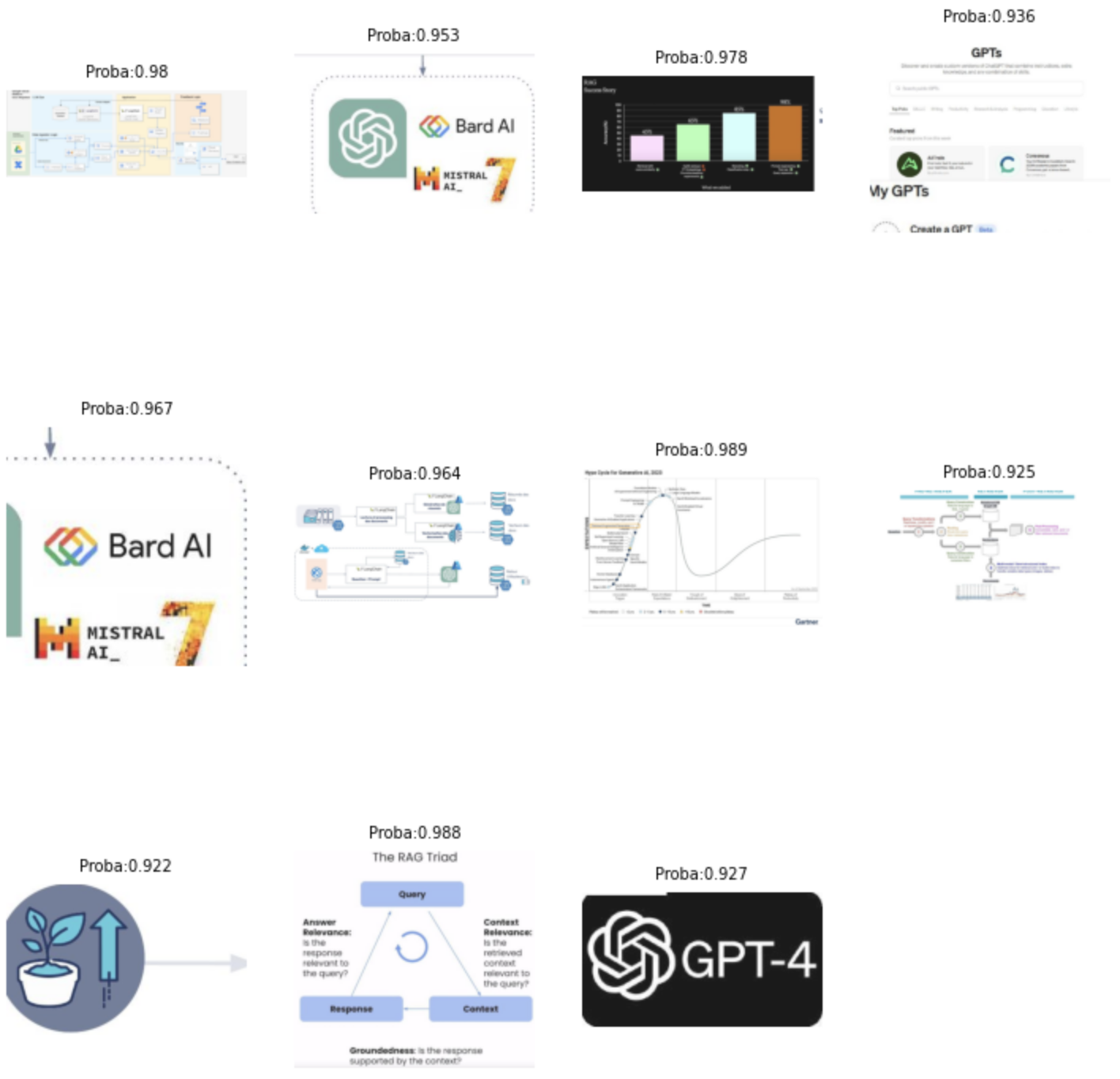
Figure 14: Images détectées comme ‘graphique’ par CLIP avec une probabilité supérieure à 90%
Dans cet exemple, CLIP nous permet de détecter 11 images (dont 7 sont informatives). Ces images peuvent être résumées par un modèle multimodal comme Gemini ou GPT 4 Vision.
Pour information, le temps de classification pour une image par CLIP est de 0.25 secondes contre 20 à 30 secondes pour GPT 4 Vision.
Nous avons filtré 95% des images détectées par Unstructured sur un PDF de 53 pages.
Le tableau suivant résume les temps et coûts d’ingestion approximatifs avec et sans cette étape de filtrage. Le filtre CLIP nous permet de réduire le temps d’ingestion d’un document de 90% dans notre exemple. Dans le cas où nous résumons la page du PDF contenant l’image et non pas l’image en question, afin de conserver le contexte environnant, le gain est de 65%. Retrouvez ici l’intégralité du code de cette section.
| Etapes | Sans étape de préfiltrage | Avec pré-filtrage CLIP |
|---|---|---|
| Détection des images et bloc de texte avec Unstructured | 2 min 29 | 2 min 29 |
| Prédiction de la pertinence avec CLIP (211 images) | - | 12 secondes |
| Résumé des images avec un modèle multimodal (12 images vs 211 images) sans parallélisme (actuellement limité sur Azure et GCP) | ~ 70 min (analyse de l'image) ~ 17 min (analyse de la page entière du PDF pour conserver le contexte) | ~ 4 min |
| Génération des embeddings et ingestion dans la base vecteur | ~ 15 sec | ~ 15 sec |
| Total | ~72 min 44 sec (analyse de l'image) ~19 min 44 sec (analyse de la page entière du PDF pour conserver le contexte) | ~ 6 min 44 sec |
Figure 15: Temps d’ingestion d’un document de 53 pages avec 211 images. L’analyse est faîte sur 2 CPU et sans parallélisme sur les appels APIs au modèle vision
Fine tuner un modèle de classification
Afin de fine tuner un modèle pour améliorer sa détection, il nous faut un dataset d’entraînement.
Notre problématique réside en la recherche d'images pertinentes dans des documents non structurés.
Nous considérons une fois de plus que les images pertinentes sont les tableaux et les graphiques. Nous aurons toujours pour objectif de prédire si une image est un graphique, un tableau, ou une autre image. Ce papier, cité dans la partie précédente, présente différents datasets d’images de graphiques labellisés et notamment le dataset UB PMC. Il existe aussi des dataset de tableaux tels que le Table Bank dataset. Ces datasets sont initialement conçus pour entraîner des modèles de détection de structures et d’interprétations de graphiques. Nous les utiliserons uniquement à des fins de classification.
Le choix du modèle à fine tuner est relatif à notre problématique, à savoir une classification. Vous pourrez utiliser un des modèles les plus performants et le fine tuner aux graphiques de votre propre entreprise ou à ceux issus des datasets cités précédemment.
Voici un exemple de labels pour le dataset Doc Figure contenant des graphiques et des tableaux:
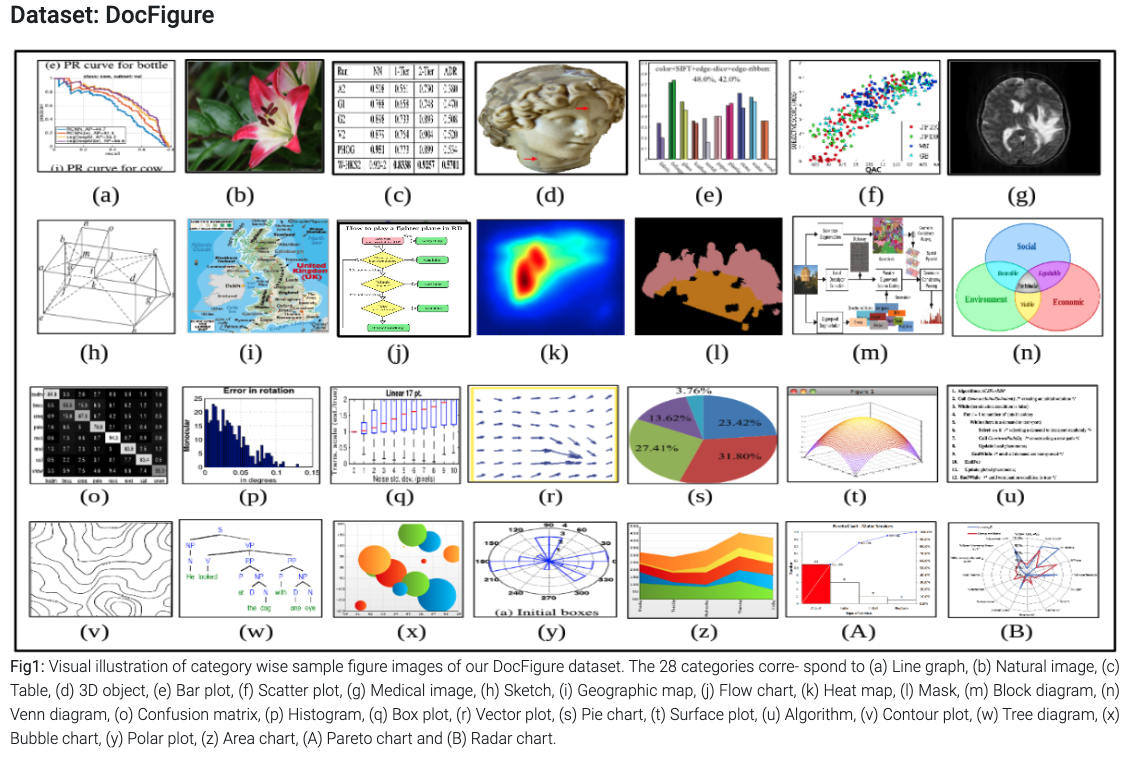
Figure 16: Exemples d’images et catégories du dataset Doc Figure
Conclusion
Nous vous avons présenté dans cet articles différentes approches d’extractions d’informations non textuelles.
La figure 17 synthétise les approches qui s’offrent à vous afin d’améliorer la qualité de votre base documentaire et du chatbot sous-jacent.
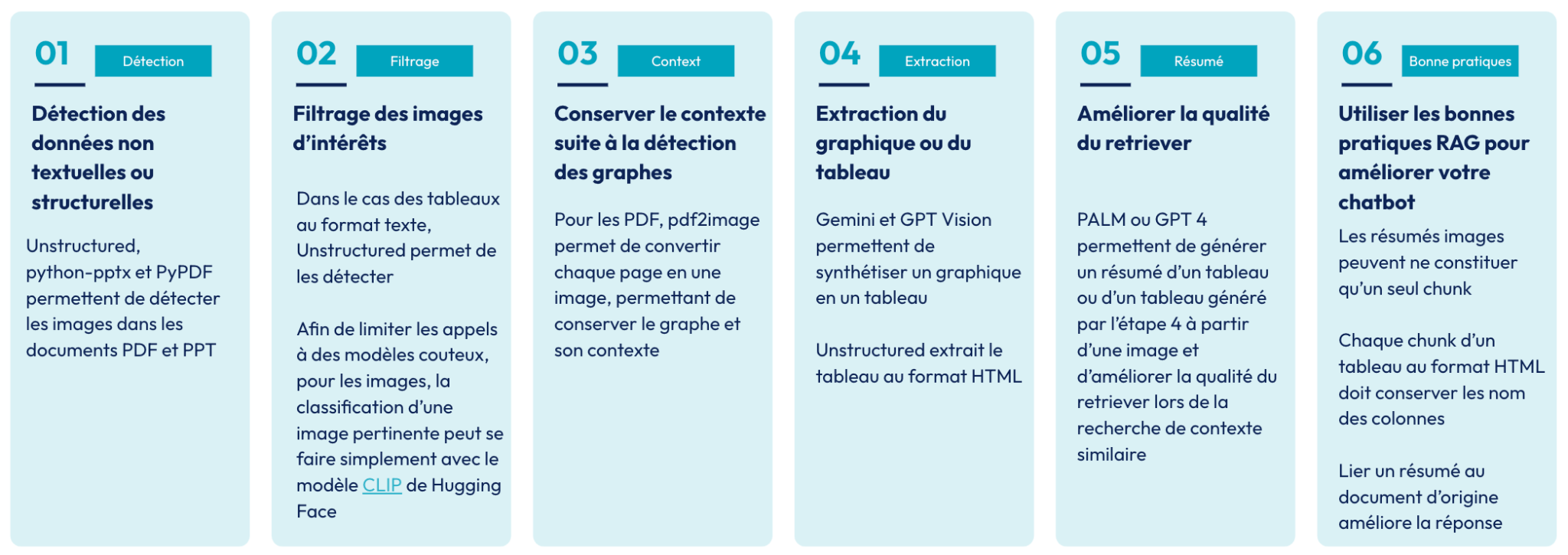
Figure 17: Résumé des techniques présentées dans cet article pour l’exploitation des images et tableaux
Ces techniques peuvent complexifier et allonger la durée d’ingestion des documents dans votre base de données vectorielle. Cependant, selon le volume d’images et tableaux contenus dans vos documents, les mettre en place peut grandement améliorer la performance de votre Chatbot.
Au cours de la rédaction de cet article, Llama Index à sorti Llama Parse, un parser de documents permettant de synthétiser les images et figures, utilisable par clé API uniquement pour l’instant.
Sources:
- Extraction de documents non structurés avec Unstructured
- Construire son RAG avec LangChain
- ICDAR: Revue des datasets et modèles de classification de graphiques et tableaux
- L'usage de CLIP pour la classification zero shot
- Extraction OCR de table avec Document AI
- Comprendre le Multimodal avec LangChain
- Extraction de documents non structurés avec Llama Parse