Comment scaler le nombre de pods dans votre cluster kubernetes
Dans un précédent article, nous avons abordé les nouvelles fonctionnalités du Horizontal Pod Autoscaler (HPA), cet article entre un peu plus en détail dans la manière de le mettre en place dans votre cluster Kubernetes. Progressivement apparus il y a quelques versions (depuis la 1.7 pour être précis), de nouveaux mécanismes portés par des HPA(v2) étendent le fonctionnement historique des HPA(v1) qui permettait presqu’exclusivement l’autoscalling en se basant sur le CPU consommé par les pods. Quelques moyens plus ou moins détournés permettaient de faire de l’autoscalling sur d’autres critères, mais cela relevait avant tout de la magie noire.
Voyons comment l’architecture de collecte de métriques a évolué et les usages qui en découlent.
Exit Heapster; enfin, bientôt
Le changement d’architecture implique en premier lieu que l’utilisation d’Heapster est rendue obsolète pour l’autoscaling. Il n’est donc plus nécessaire de le mettre en œuvre, car il est voué à se voir remplacé par d’autres composants. À noter qu’en version 1.9.3 de Kubernetes, la commande kubectl top se base encore sur Heapster et risque donc de ne plus fonctionner s’il est complètement supprimé. Il en va de même pour l’affichage des graphes dans le Dashboard.
Mise en place d’un aggregation Layer
Kubernetes permet d’étendre l’APIServer en démarrant un aggregation layer. Ce dernier, qui tourne dans le même processus, va être en mesure d’agréger des appels à des APIs exposées par des services tiers, sous réserve qu’ils se soient enregistrés au préalable.
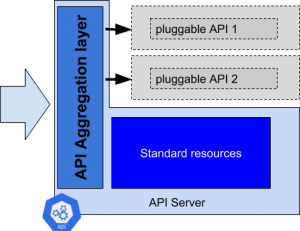
Un certain nombre de paramètres sont à fournir au démarrage de l’APIServer pour activer l'aggregation layer. Une fois démarré, l’APIServer devient porteur d’un nouveau type de ressources : les APIServices qui représentent tous les groupes d’APIs qui sont disponibles dans ce cluster Kubernetes. Les ressources par défaut sont naturellement déjà disponibles :
$ kubectl get apiservices NAME AGE v1. 11d v1.apps 11d v1.authentication.k8s.io 11d v1.authorization.k8s.io 11d v1.autoscaling 11d v1.batch 11d v1.networking.k8s.io 11d v1.rbac.authorization.k8s.io 11d v1.storage.k8s.io 11d v1alpha1.admissionregistration.k8s.io 11d v1alpha1.rbac.authorization.k8s.io 11d v1alpha1.scheduling.k8s.io 11d v1alpha1.settings.k8s.io 11d v1alpha1.storage.k8s.io 11d v1beta1.admissionregistration.k8s.io 11d v1beta1.apiextensions.k8s.io 11d v1beta1.apps 11d v1beta1.authentication.k8s.io 11d v1beta1.authorization.k8s.io 11d v1beta1.batch 11d v1beta1.certificates.k8s.io 11d v1beta1.events.k8s.io 11d v1beta1.extensions 11d v1beta1.policy 11d v1beta1.rbac.authorization.k8s.io 11d v1beta1.storage.k8s.io 11d v1beta2.apps 11d v2alpha1.batch 11d v2beta1.autoscaling 11d
Derrière ces groupes d’API se cachent toutes les ressources que l’on a l’habitude de manipuler (pods, services, deployments, statefulsets, nodes…). L_’autoscaling_ est à présent capable de se baser sur des métriques qui sont exposées dans les groupes d’API qui ne sont pas disponibles par défaut. C’est la raison pour laquelle il est nécessaire de démarrer deux nouveaux composants qui implémentent respectivement v1beta1.metrics.k8s.io et v1beta1.custom.metrics.k8s.io.
Démarrage du fournisseur de métriques standard (Resource Metrics)
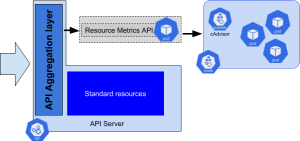
Ce premier nouveau composant qu’il est nécessaire de mettre en œuvre porte le doux nom de Kubernetes metrics server. Il est en charge d’agréger les métriques standards des pods (cpu, mémoire) qui sont exposés sur les ports de métriques des nœuds Kubernetes. Une fois ce server installé, une déclaration permet d’exposer les métriques :
$ kubectl get apiservices v1beta1.metrics.k8s.io
NAME AGE
v1beta1.metrics.k8s.io 13s
Si tout s’est bien passé, il devient possible de directement requêter les métriques remontées par ce composant :
$ kubectl get --raw '/apis/metrics.k8s.io/v1beta1/pods' | jq { "kind": "PodMetricsList", "apiVersion": "metrics.k8s.io/v1beta1", "metadata": { "selfLink": "/apis/metrics.k8s.io/v1beta1/pods" }, "items": [ ... [ snip ] ... { "metadata": { "name": "nginx-8669f45f7d-xgk66", "namespace": "default", "selfLink": "/apis/metrics.k8s.io/v1beta1/namespaces/default/pods/nginx-8669f45f7d-xgk66", "creationTimestamp": "2018-02-19T14:44:31Z" }, "timestamp": "2018-02-19T14:44:00Z", "window": "1m0s", "containers": [ { "name": "nginx", "usage": { "cpu": "0", "memory": "1844Ki" } } ] } ] }
Par défaut, deux métriques sont collectées pour chaque pod : la mémoire et le cpu consommés.
Dés que ce composant est en place, l’autoscaling standard fonctionne, et ce, même si Heapster est absent du cluster. Il est donc possible d’utiliser la traditionnelle commande kubectl autoscale :
$ kubectl autoscale --min=2 --max=5 deploy/nginx --cpu-percent=70
Mais aussi de créer manuellement un HorizontalPodAutoscaler basé sur la mémoire :
apiVersion: autoscaling/v2beta1 kind: HorizontalPodAutoscaler metadata: name: nginx spec: maxReplicas: 5 minReplicas: 2 scaleTargetRef: apiVersion: extensions/v1beta1 kind: Deployment name: nginx metrics:
- type: Resource resource: name: memory targetAverageValue: 1500k
Ce nouveau format de hpa (en version v2beta1) dispose d’une capacité de référencer des compteurs de plusieurs types dont le premier (Resource) est relatif aux métriques standard d’un pod. Les seuils peuvent être exprimés de plusieurs façons : - targetAverageUtilization : pourcentage moyen de la métrique que le hpa va chercher à obtenir - targetAverageValue : valeur absolue moyenne de la métrique que le hpa va chercher à obtenir
Autoscaling en se basant sur la Custom Metrics APIs
Pour dépasser l’autoscaling classique, il est possible d’ajouter un second composant qui vient à nouveau étendre l’API exposée par défaut dans K8s. Cette fois-ci, le groupe d’API s’appelle custom.metrics.k8s.io. Pour illustrer le fonctionnement, nous allons mettre en place plusieurs composants supplémentaires :
- Une application qui expose des métriques, notamment une magnifique sinusoïde du nom de fake_load.
- Un serveur Prometheus (le mécanisme standard de monitoring des architectures Kubernetes) qui va collecter les métriques de cette application.
- Un adaptateur (sous forme d’un pod technique) qui expose une API Custom Metrics et s’appuie sur le serveur Prometheus pour fournir des données.
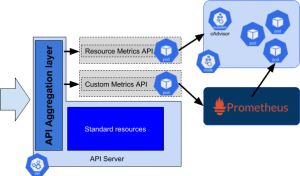
Nous passons ici les détails du déploiement de Prometheus et de l’adaptateur. Résumons simplement la situation en disant que l’on se basera sur un opérateur pour gérer Prometheus, qui facilite grandement la gestion de Prometheus. Voici le lien pour l’installer. En ce qui concerne l’implémentation de la Custom metrics API, voici le lien pour l’installer.
Pour vérifier que l’installation fonctionne il est possible de la même manière de requêter :
$ kubectl get --raw '/apis/custom.metrics.k8s.io/'
{"kind":"APIGroup","apiVersion":"v1","name":"custom.metrics.k8s.io","versions":[{"groupVersion":"custom.metrics.k8s.io/v1beta1","version":"v1beta1"}],"preferredVersion":{"groupVersion":"custom.metrics.k8s.io/v1beta1","version":"v1beta1"},"serverAddressByClientCIDRs":null}
Nous allons ensuite déployer notre application ; pour une question de commodité, nous travaillerons dans le namespace default :
$ kubectl run metrics-app --image=arnaudmz/metrics-app:1.4 --replicas 1
Pour monitorer metrics-app, nous avons besoin de créer une ressource de type ServiceMonitor, cette dernière est une CRD (Custom Resource Definition) apporté par prometheus, qui permet de définir un service que l’on souhaite superviser :
apiVersion: monitoring.coreos.com/v1 kind: ServiceMonitor metadata: labels: k8s-app: metrics-app name: metrics-app namespace: monitoring spec: endpoints:
- interval: 30s path: /metrics port: http-metrics scheme: http jobLabel: k8s-app namespaceSelector: matchNames:
- default selector: matchLabels: run: metrics-app
On remarque que dans le port on précise http-metrics, ce dernier est un port alias, pour que Prometheus puisse le collecter (on emploie le terme « scrape » dans la litérature Prometheusienne).l est donc nécessaire de créer le service correspondant :
apiVersion: v1 kind: Service metadata: labels: app: metrics-app service-monitor: metrics-app run: metrics-app name: metrics-app spec: type: ClusterIP clusterIP: None ports:
- name: http-metrics port: 8080 selector: run: metrics-app
Il est possible de vérifier que le scrape se fait sur metrics-app. Des appels à l’URL /metrics doivent apparaître régulièrement dans les logs du conteneur, que l’on peut consulter via la commande :
$ kubectl logs -f metrics-app-566457f68-h7s9d
Nous pouvons également vérifier que les métriques sont disponible sur la Custom Metrics API :
$ kubectl get --raw '/apis/custom.metrics.k8s.io/v1beta1/namespaces/default/pods/*/fake_load'
{"kind":"MetricValueList","apiVersion":"custom.metrics.k8s.io/v1beta1","metadata":{"selfLink":"/apis/custom.metrics.k8s.io/v1beta1/namespaces/default/pods/%2A/fake_load"},"items":[{"describedObject":{"kind":"Pod","namespace":"default","name":"metrics-app-566457f68-h7s9d","apiVersion":"/__internal"},"metricName":"fake_load","timestamp":"2018-02-21T16:54:51Z","value":"28762m"}]}
Maintenant que l’on est sûr que toute la chaîne de collecte est fonctionnelle, il est grand temps de créer une ressource HPA afin de scaler notre metrics-app en se basant sur les métriques qu’elle produit :
apiVersion: autoscaling/v2beta1 kind: HorizontalPodAutoscaler metadata: name: metrics-app-hpa spec: maxReplicas: 5 minReplicas: 2 scaleTargetRef: apiVersion: extensions/v1beta1 kind: Deployment name: metrics-app metrics:
- type: Pods pods: metricName: fake_load targetAverageValue: 20
Pour vérifier que l’on scale bien suivant suivant fake_load, il suffit d’observer notre ressource:
$ kubectl describe hpa metrics-app-hpa
résultat:
Name: metrics-app-hpa Namespace: default Labels:
Annotations:
CreationTimestamp: Wed, 28 Feb 2018 10:34:47 +0100 Reference: Deployment/sinus Metrics: ( current / target ) "fake_load" on pods: 32954m / 20 Min replicas: 2 Max replicas: 5 Conditions: Type Status Reason Message
AbleToScale True SucceededRescale the HPA controller was able to update the target scale to 4 ScalingActive True ValidMetricFound the HPA was able to succesfully calculate a replica count from pods metric fake_load ScalingLimited False DesiredWithinRange the desired count is within the acceptable range Events: Type Reason Age From Message
Normal SuccessfulRescale 4m horizontal-pod-autoscaler New size: 2; reason: Current number of replicas below Spec.MinReplicas Normal SuccessfulRescale 12s horizontal-pod-autoscaler New size: 4; reason: pods metric fake_load above target
il est à noter que l’upscaling et le downscaling ne suivront la sinusoïde produite par metrics-app, et ce dû au paramétres de cooldown qui est bien plus long que la phase de ladite sinusoïde.
On a vu que l’on pouvait scaler un pod à partir de ses propres métriques, c’est ce qu’on appelle une HPA de type Pod. Il est toutefois possible de scaler en se basant sur les métriques d’une autre ressource que celle que l’on veut scaler, c’est ce qu’on appelle une HPA de type Object. Voici un exemple d’une HPA qui permet de scaler un deployment nginx en fonction de la sinusoïde émise par metrics-app:
apiVersion: autoscaling/v2beta1 kind: HorizontalPodAutoscaler metadata: name: metrics-app-hpa spec: maxReplicas: 5 minReplicas: 2 scaleTargetRef: apiVersion: extensions/v1beta1 kind: Deployment name: nginx metrics:
- type: Object object: metricName: fake_load target: apiVersion: extensions/v1beta1 kind: Deployment name: metrics-app
targetAverageValue: 20
Conclusion
Nous avons donc vu qu’avec l’arrivée des HPAv2 et du nouveau modèle de gestion des métriques, il est possible de faire scaler des groupes de pods en fonctions de métriques :
- Standard (CPU, mémoire) : les métriques de type Resource
- Spécifiques et directement exposées par les pods à faire scaler : les métriques de type Pod
- Spécifique et relatives à un autre objet du même namespace (pod ou autre) : les métriques de type Object
La mise en œuvre reste encore laborieuse et il y a fort à parier que les composants de type adaptateurs vont fleurir pour enrichir l’écosystème. Soit en proposant des connecteurs vers d’autres types de système de monitoring, soit en offrant des fonctions de calcul ou traitement de métriques plus intelligents (fonction d’agrégation de métriques, de consolidation…).
À titre d’exemple, et même si la documentation de Kubernetes met en avant ce genre de cas d’utilisation, il est pour le moment très compliqué de déclencher un scaling sur des métriques relatives aux Ingress en frontal d’un service (nombre de requêtes par seconde et par pod par exemple).