Comment Puppet, Cfengine ou Chef peuvent aider études et production
Pour faire suite à l'article d'introduction sur le mouvement des DevOps, nous pressentons que, dans leur lourde tâche, nos héros vont devoir s'appuyer sur un certain outillage leur permettant de fluidifier la phase de Mise En Production ; qui dit fluidification dit appli déployée plus vite et le business traduit ça par : "la fonctionnalité va arriver bien plus vite au client". Et le business aime ça.
L'utilisation du shell est une solution, mais qui montre ses limites. Il est temps de faire appel à d'autres outils. Voici un rapide tour d'horizon de quelques instruments de déploiement automatisé et de leurs principes.
Principes
Les outils de type Cfengine, Puppet ou Chef reposent sur un certain nombre de concepts communs. Précisons à toutes fins utiles que le cœur de cible de ces outils est le monde des serveurs dits « ouverts » et qu'ils vont manipuler des terminologies proches d'UNIX (systèmes de fichiers, points de montage, paquets, cron, permissions UNIX…). À noter que la version payante de Cfengine permet notamment de gérer les machines Windows.
Ces outils tendent à définir un état de configuration (système, applicative) dans lequel on souhaite voir nos machines. On est donc assez proche de la gestion de parc mais pas très loin du déploiement automatisé. Les agents déployés sur les machines cibles vont prendre une configuration de référence sur un dépôt central et opérer les tâches d'administration pour atteindre cette cible. Cfengine, dans sa version 3, parle par exemple de promesse pour définir les actions qu'il va entreprendre (il s'engage à ce qu'un fichier soit présent, et avec les bons droits, à ce qu'un paquet soit installé...).
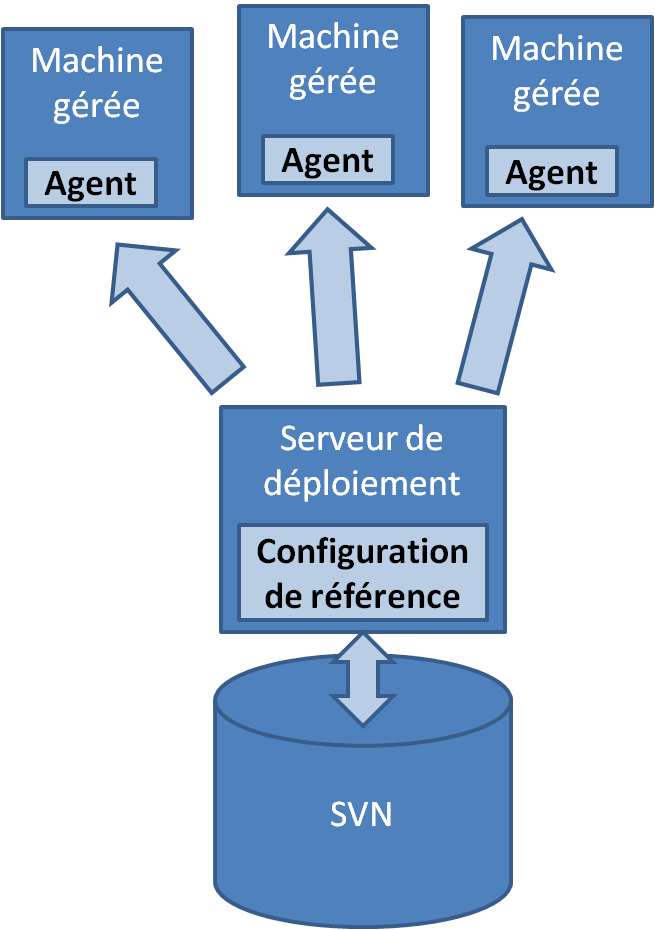
Les agents vont donc avoir l'incessante mission de rendre une machine conforme à une cible. Malheur à l'édition manuelle d'un fichier localement sur une machine, le prochain déclenchement de l'agent ira consciencieusement l'écraser par la version de référence, si elle a été définie. Au contraire, si une machine n'a pas été modifiée depuis le dernier lancement de l'agent, celui-ci ne fera strictement rien.
La notion de référence, de dépôt central des configurations est un principe essentiel. Même si les outils n'imposent pas l'utilisation d'un gestionnaire de version, l'automatisme qu'ont les développeurs depuis plusieurs années doit devenir systématique dans le monde de la prod : qui dit « dépôt de configuration », dit « gestion de version ». Bien entendu, pour améliorer la convergence des équipes de dev et de prod, on va préférer (ré-)utiliser un outil de gestion de version déjà maîtrisé par les équipes de dev, y appliquer les mêmes bonnes pratiques et standards en matière de gestion de branches, d'étiquetage.
Si c'est en prod', c'est dans le gestionnaire de serveurs [Puppet, Cfengine, Chef] (rayez les mentions inutiles). Si c'est dans le gestionnaire de serveur, c'est géré en version dans [CSV, SVN, Git, Mecurial] (rayez les mentions inutiles)__.
Les actions possibles
Un grand nombre d'actions sont ainsi possibles avec les outils de déploiement de configuration :
- Installer un paquet système (RPM, Deb, pkg...)
- Installer un fichier à partir du référentiel, en utilisant éventuellement un système de gabarits pour y placer des données dépendantes de chaque machine (exemple : l'adresse IP d'écoute du service)
- Mettre en place ou modifier une tâche planifiée
- Créer un répertoire
- Supprimer un répertoire/fichier
- Tirer un lien symbolique
- S'assurer que tel ou tel fichier/répertoire dispose de droits prévus
- Changer le montage d'un système de fichiers (local ou réseau)
- Et finalement, le saint Graal : lancer une commande quelconque. On comprend bien qu'il est simplement possible de faire tout et n'importe quoi
- Reboot de la machine
- Redémarrage d'un service
- Déploiement d'un artefact
- Initialisation d'une base
- Import de données
- Remise en marche d'une réplication
- ...
Exemples
Les outils utilisent généralement une syntaxe particulière pour les fichiers de configuration. Là où Cfengine a redéfini un format de fichiers spécifiques, Puppet et chef héritent du langage dans lequel ils ont été écrits (Ruby) pour utiliser une syntaxe déjà existante.
Exemple ici avec le positionnement de droits particuliers à un fichier.
À la Puppet :
file { "/etc/plop":
owner => root,
group => root,
mode => 644,
}
À la CFEngine :
[...]
files:
"/tmp/patapouf"
create => "true",
perms => m_u_g("644", "root", "root");
body perms m_u_g(m,u,g)
{
mode => "$(m)";
owners => { "$(u)" };
groups => { "$(g)" };
}
À la Chef :
file
Utilisation
Cela ne fait pas franchement de différence que l'on travaille au niveau d'une machine physique ou d'une machine virtuelle. Dans les deux cas, on pilote, on administre l'engin. Seul le cycle de vie peut différer, en effet pour créer une nouvelle VM, on aura tendance à cloner une VM de base, alors que pour des machines physiques, il faut souvent effectuer des manipulations plus compliquées, à grand coup d'installation, de ghost, de boot PXE, j'en passe et des meilleures.
Les agents qui appliquent des modifications sur les machines ont beaucoup de droits. C'est normal, ils doivent pouvoir installer des paquets, changer des fichiers de configuration du système, redémarrer un service voire toute la machine. Il est important qu'une confiance se mette en place entre le serveur central et l'agent. On a souvent recours à de la cryptographie asymétrique (X.509, RSA…) pour s'assurer mutuellement de l'identité de l'autre.
Les agents peuvent être invoqués sur tout ou partie du parc, soit manuellement à la demande, soit automatiquement à une fréquence configurable. Certains de ces outils vont apporter du contrôle d'accès de manière par exemple à ce que les déploiements sur un environnement de développement soient possibles pour tous, alors que les changements de configuration de production seront mieux contrôlés ou réservés à une certaine population.
Modélisation de la configuration
Une fois que l'on a vu le panel d'actions possibles sur nos systèmes, voyons comment les appliquer sélectivement sur nos machine.
Pour faire simple disons que l'on va être capable de filtrer des actions à des groupes/profiles/rôles/tags (j'emploierai par la suite le terme groupe uniquement pour des questions de simplicité). Exemple : installer Apache uniquement sur les systèmes identifiés comme des serveurs Web.
# extrait d'un fichier de configuration cfengine v2
déclaration des groupes
groups: sql_servers = (db1 db2 dev1) # 3 machines dans ce groupe web_servers = (www1 www2 dev1) # idem, dev1 est dans les deux groupes san_users = ( ReturnsZero(/bin/grep -qi san /etc/mtab) ) # groupe dynamique
installation automatique de paquets
packages: any:: # tous les systèmes ont systématiquement NTP et SNMP installés openntpd action=install snmpd action=install
web\_servers::
apache2 action=install
san\_users::
san\_diag\_package action=install
En fonction de l'organisation, on va donc travailler à définir des groupes qui ont du sens, qui parlent aux gens, qu'ils soient des études ou de la prod', car au final, tous vont s'y référer. Cette étape est essentielle dans la modélisation d'un outil de déploiement automatisé.
On se rend compte que l'on va généralement superposer au moins trois type de groupes aux machines:
- Des groupes techniques d'infrastructure ou de sécurité (Linux, DMZ, NoSAN, VLAN_203, DataRoom_01) => couche IaaS
- Des groupes techniques de socle applicatifs (JBoss, Tomcat, PHP, MySQL, rails) => couche PaaS
- Des groupes fonctionnels applicatifs (MaBanque, MaBanque_2_0, FrontOffice) => couche SaaS
Et pour les DevOps, hmm ?
Les outils de déploiement automatisé dans une approche DevOps peuvent représenter une très bonne interface entre les dev et les infreux. Les deux équipes sont finalement amenées à contribuer à remplir les fichiers de configuration d'un même outil.
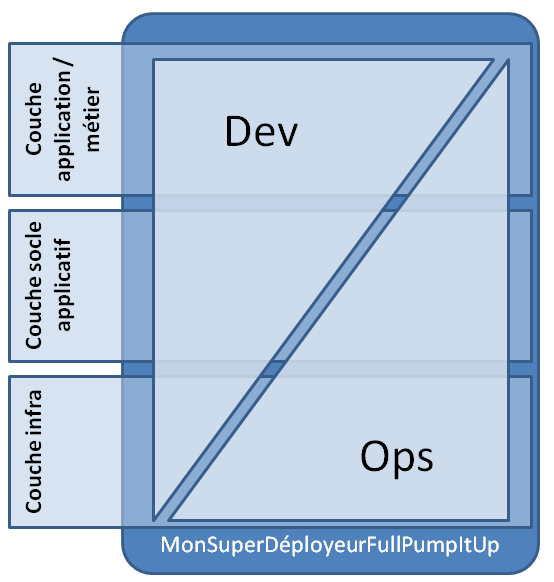
Dans cette vision, les ops sont avant tout vue comme une équipe qui met en place les bases de l'outil et définit les actions techniques associées aux groupes, principalement de bas-niveau. En déclarant ces actions à leur convenance, elle s'assure que tous les systèmes seront installés à l'identique et conformément à ses us et coutumes (supervision, sauvegarde, journalisation…), bref aux petits oignons.
Les dev vont avoir avant tout un rôle de contributeur au sens éditorial : ils déclarent des objets, leur attribuent des profils en piochant dans les groupes techniques fournis par l'infra. Un vrai self-service. Ils contribuent également à améliorer les socles applicatifs
Dans le cas d'une infrastructure 100% virtualisée sur un socle déjà provisionné/dimensionné, une équipe de dev bien épaulé par ses ops est donc potentiellement capable de déployer automatiquement de nouveaux services (au sens fonctionnel), de l'OS à l'application, en production, avec toutes les briques d'infrastructure nécessaires à leur exploitation, à des vitesses impressionnantes.
Conclusion
Les outils de déploiement automatisé apportent une très forte capacité à fluidifier et industrialiser des mises en production. C'est une brique qui se justifie souvent pour des tailles de parcs serveurs conséquentes et pour laquelle un ticket d'entrée est toujours à évaluer (en terme de temps et de compétences à acquérir).
Par rapport à l'utilisation du shell, qui restait à l'initiative de l'exploit' et éventuellement à disposition des dev - et finit par former un véritable serpent de mer au fur et à mesure de l'ajout de fonctionnalités et de spécificités - nous avons ici de véritables outils communs pour le déploiement des applications. Par ailleurs, tout comme le shell, ces outils Open Source ont les défauts et qualités inhérents à leur écosystème : rapides à mettre en œuvre, légers, mais un peu spartiates dans l'utilisation ; et principalement cantonnés aux *nix.
Comme bien souvent, c'est l'organisation à laquelle l'outil participe qui fera le succès d'une mise en prod et non l'outil en lui même. Le mariage entre l'approche organisationnelle DevOps et ces socles techniques semblent très prometteur.