Comment l'IA peut-elle changer le recrutement ? (partie 2)
Dans la première partie de l’article, nous avons vu quelles étaient les solutions logicielles permettant aux entreprises de trier les candidatures. Cette démarche, qui a de l’intérêt principalement lorsque l’entreprise reçoit énormément de candidatures, repose sur une méthode simple mais très limitée. Nous avons vu que l’IA a le potentiel pour apporter des solutions aux limites évoquées mais présente aussi des écueils à éviter, notamment les biais.
Dans cette deuxième partie, nous allons présenter une technique de NLP qui pourrait permettre de pallier les défauts du simple tri par mots-clés.
Pallier les défauts de la détection de mots-clés
Nous avons vu que le plus gros reproche que l’on peut faire à la détection de mots-clés est que c’est extrêmement dépendant de l’orthographe. Les termes sémantiquement proches ne sont pas pris en compte par les algorithmes de détection de mots-clés alors qu’un recruteur le pourrait.
La raison est simple : pour l’ordinateur, les mots ne sont qu’une suite de caractères dénuée de sens. Il peut repérer des mots dont la suite de caractères n’est pas trop différente de celle du mot recherché (e.g. Distance de Hamming, de Levenstein, de Jaro-Winkler), mais ceux-ci ne sont pas nécessairement proches sémantiquement (e.g. lorsque le mot est court, lorsqu’on peut obtenir son contraire avec un préfixe privatif, etc.). C’est là qu'intervient le concept de word embedding.
Le word embedding
Cela consiste à construire une représentation vectorielle des mots telle que les vecteurs représentant les mots conservent certaines des relations que les mots ont entre eux. Les vecteurs sont des objets mathématiques, à l’instar des nombres, qui peuvent être exploités par l’ordinateur. En particulier, on peut les comparer et voir si le vecteur associé au mot 1 est plus ou moins loin du vecteur associé au mot 2. C’est intéressant si les mots au sens proche ont des vecteurs associés proches également.
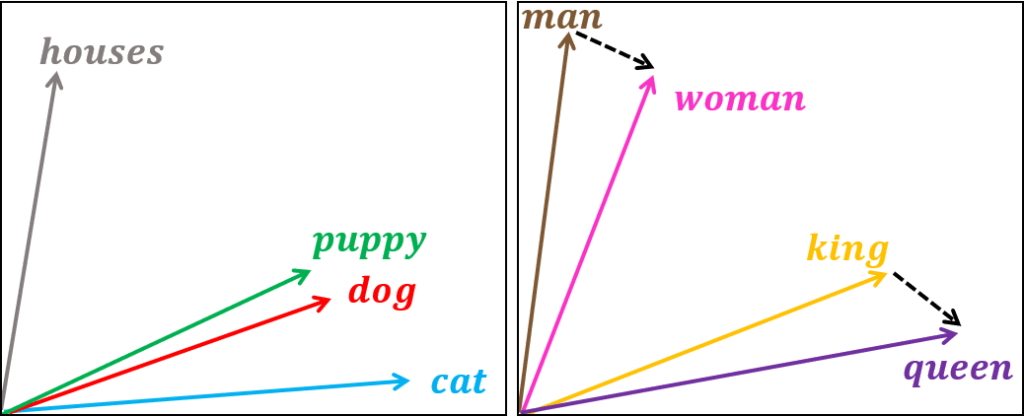
Pour construire cette représentation vectorielle des mots, le principe est d’apprendre à un réseau de neurones à prédire un mot à partir de son contexte (continuous bag-of-words CBOW) ou vice-versa (skip-gram). Ce sont deux variantes de l'algorithme word2vec. Cette technique est basée sur l'hypothèse qui veut que les mots apparaissant dans des contextes similaires ont des significations apparentées.
Le principe adresse brillamment notre problème puisque dans le cas d’une faute d’orthographe, d’une formulation différente ou d’une abréviation, il est vraisemblable que le contexte soit extrêmement similaire à celui du mot-clé. Du coup, les représentations vectorielles associées à ces mots seront proches.
Grâce au word embedding, l’ordinateur peut désormais repérer des mots sémantiquement proches. En outre, comme en reconnaissance d’image, il est possible de tirer parti d’un modèle déjà entraîné sur un jeu de données généraliste, tel que les articles de news ou les pages Wikipedia, grâce au fine-tuning. L'entraînement prend alors moins de temps que de partir de zéro, nécessite peu de données et permet d’avoir plus de mots que le vocabulaire du corpus qui peut être très spécifique.
Cependant, cette approche est loin d’être parfaite. Tout d’abord, il y a des défauts inhérents au word embedding. L’hypothèse de base est raisonnable pour les noms, en revanche des adjectifs opposés peuvent apparaître dans le même contexte. C’est notamment problématique pour l’analyse de sentiment. Les mots "bon" et "mauvais" vont apparaître dans des phrases similaires (e.g. c'est vraiment un bon/mauvais film). Le contexte étant similaire, les vecteurs résultants seront proches alors qu'ils sont opposés en sens. De plus, comme tout ce qui se base sur l’apprentissage automatique, l’approche est dépendante du jeu de données.
Les modèles pré-entraînés
Tirer parti des modèles pré-entrainés nécessite un corpus contenant les mots-clés dans un contexte assez spécifique pour affiner leur représentation vectorielle. Les modèles pré-entraînés disponibles en ligne l’ont été sur des corpus d’articles de presse ou de wikipedia. Ces documents sont trop généralistes pour que les modèles aient des représentations vectorielles des mots-clés utiles. Par exemple, les termes liés de près ou de loin à l’informatique sont jugés similaires.
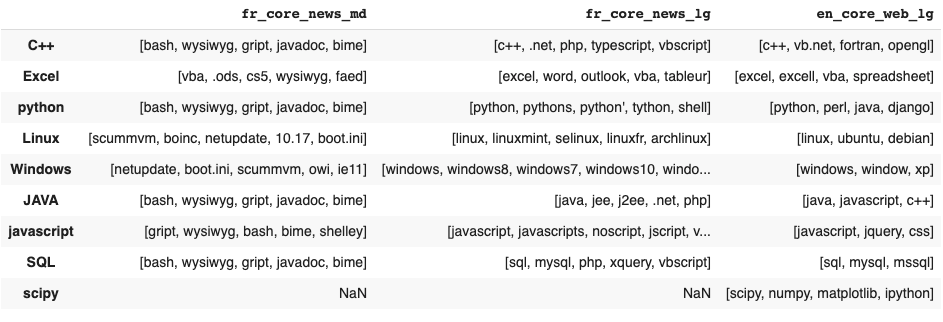
Addendum : Lorsque nous avons fait cette observation initialement, spaCy contenait seulement un modèle de taille médium pour la langue française. On peut d’ailleurs voir que les rapprochements sémantiques qu’il est capable de faire ne sont pas très précis. En écrivant l’article et en voulant reproduire cette observation, nous avons testé le modèle large publié depuis et il est nettement meilleur. Le modèle large anglais est encore meilleur pour les termes testés et peut-être qu’en combinant les deux on pourrait obtenir des résultats exploitables.
Construire une représentation vectorielle
Pour construire ces embeddings, il faut constituer un corpus de textes contenant les informations que l’on veut traiter automatiquement. Nous avons à notre disposition les CVs des candidats. Malheureusement, c’est une source de données commode mais bien différente de celles utilisées généralement pour créer des représentations vectorielles.
Les modèles présentés dans la littérature sont souvent entraînés avec des corpus d’articles de presse ou de wikipedia. Ces textes sont écrits avec une syntaxe typique et souvent correcte. Or comme dit précédemment, la syntaxe des phrases d’un CV est particulière. Voici un bloc de texte pris dans un CV au hasard reflétant la structure textuelle que l’on retrouve en majorité dans les CVs.

Cette syntaxe sera sans doute moins facilement exploitable par l’ordinateur pour créer une représentation vectorielle de mots car le contexte entourant chaque mot-clé est assez peu porteur d’information sur ce mot-clé (e.g. JAVA, Spring). D’autant plus lorsqu’ils sont listés les uns à la suite des autres sans que l’ordre n’importe.
Essayez de faire l’exercice de deviner un mot en fonction de ceux qui l’entourent. Pour la partie “Contribution” c’est faisable. En revanche, dans la partie “Environnement”, c’est quasiment impossible. C’est problématique pour nous car ce sont ces mots qui sont susceptibles d’être des mots-clés. Tout ce qu’on peut déduire de leurs contextes, c’est qu’ils sont similaires.
Or ce que nous voulons, c’est un moyen de rapprocher "Excel" et "Spreadsheet" par exemple. Le word embedding construit à partir des CVs jugera que ces termes sont proches mais ils seront également proches de tout un tas d’autres termes (e.g. python) si bien que leur proximité ne sera pas exploitable si le contexte n’est pas assez spécifique.
Notre motivation principale est de rendre la détection de mots-clés plus souple et plus intelligente. C’est-à-dire la rendre capable d’accepter les termes proches sémantiquement, qu’ils soient des synonymes, des abréviations ou qu’ils contiennent des fautes.
Nous avons vu que la proximité sémantique est adressé par l’algorithme word2vec. Il en existe une implémentation qui procure un avantage supplémentaire dans le cas des fautes. fastText entraîne un modèle avec des parties de mots (Enriching Word Vectors with Subword Information). Cela concentre l’information apportée contextuellement qui serait sinon répartie sur les représentations vectorielles correspondant aux orthographes différentes.
Nous avons obtenu des résultats satisfaisants à première vue en appliquant cet algorithme. Nous avons aussi essayé d’autres types d'embeddings.
Autres manières de produire des embeddings
En nous inspirant des informations implicitement capturées par les moteurs de recommandation (Jeremy Howard en parle dans cette vidéo de 52:41 à 59:34), nous avons construit une représentation vectorielle en tirant partie de la relation entre les pages wikipedia concernant les potentiels mots-clés (repo pour les intéressés).
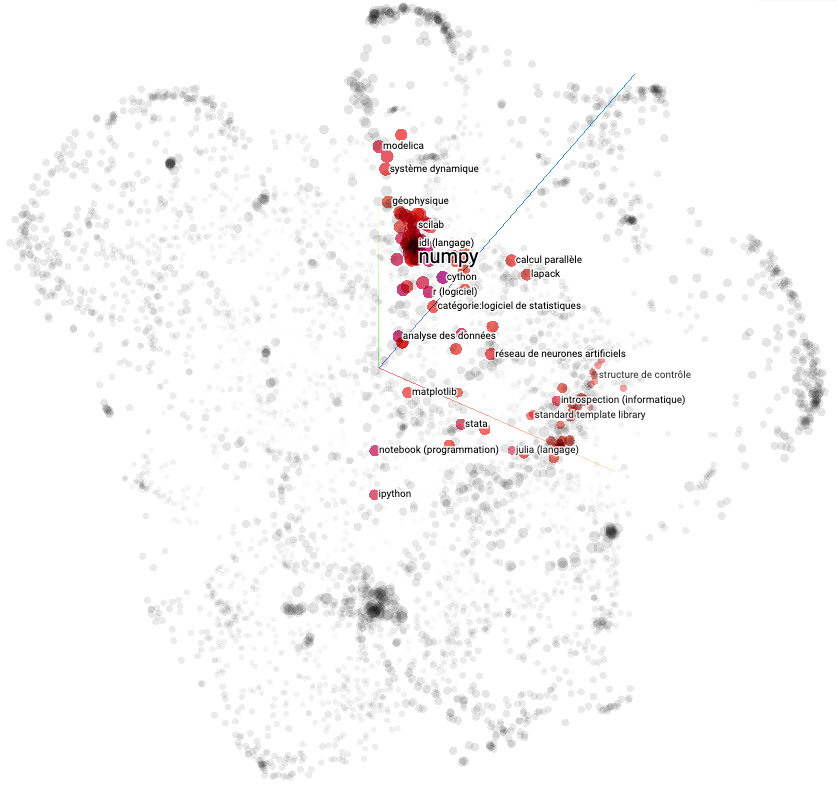
Cette représentation capture des relations de distance entre les termes assez raisonnables. Elle semble meilleure que celle issue d’un doc2vec (un algorithme basé sur word2vec pour obtenir une représentation vectorielle des documents d’un corpus) sur les pages wikipedia. Cependant, nous nous sommes aperçus de la difficulté d'évaluer la qualité d’une telle représentation.
Évaluer une représentation vectorielle
En effet, nous n'avons pas défini clairement ce qu'un embedding réussi doit être. Nous avons une idée de ce qu'il doit permettre de faire : associer une distance plus grande entre "python" et "css" qu'entre "python" et "pandas".
Pour l'évaluer, on peut par exemple lister les rapprochements qu'on voudrait que l'embedding intègre et voir combien de fois il fait les bons rapprochements.
Lister tous les rapprochements serait long et enlèverait l'intérêt de générer un embedding. Cependant, si on n'en liste pas assez ou si on ne liste pas les bons, on prend le risque que la métrique ne soit pas représentative de la qualité de l'embedding.
Ensuite, cette métrique sera-t-elle corrélée avec l'amélioration du système de tri des candidatures ?
Pour ces raisons-là, nous avons fait le choix de nous contenter de notre appréciation et de mesurer l'apport des embeddings sur le tri des candidats plutôt que leur qualité intrinsèque.
Conclusion
La technique présentée dans cette deuxième partie permet d’intégrer une dimension sémantique à la représentation de l’information. Les mots ne sont plus traités par l’ordinateur comme une suite de caractères sans sens apparent. Ils sont à la place représentés par des vecteurs que l’on peut comparer entre eux afin de savoir s’ils sont plus ou moins proches les uns des autres. On peut ainsi espérer construire un algorithme capable de détecter des mots-clés de manière intelligente : en considérant les termes de sens proches du mots-clé cible comme également valables.
Dans la suite de cet article, nous vous présenterons notre implémentation d’une solution de tri par mots-clés grâce à l’IA et les challenges que nous avons rencontrés.