Comment hacker Spark pour effectuer du data lineage
Cet article explore certains aspects clefs du lineage de données au niveau du data set, en indiquant comment il est possible de hacker le moteur Spark pour y parvenir.
Le data lineage dans les architectures distribuées
Le data lineage, ou traçage des données, est généralement défini comme un type de cycle de vie des données qui inclut les origines des données et où elles se déplacent au fil du temps. Ce terme peut également décrire ce qu'il advient des données lorsqu'elles passent par divers processus. Le lineage de données peut aider à analyser la manière dont l'information est utilisée et à suivre les informations clés qui servent un objectif particulier.
La maîtrise du suivi du cycle de vie de la donnée est devenue un enjeu capital pour nombre de Systèmes d'Information ayant recours aux technologies Big Data et autres architectures distribuées. Si dans certains cas cette fonction peut être facilitée par la présence d'outils natifs à la plateforme et dédiés au lineage de données (cas des environnements de type Hadoop), il reste que les possibilités des ces derniers ne répondent pas toujours à l'intégralité des besoins fonctionnels et parviennent difficilement à faire cohabiter finesse de grain de lineage et temps de calcul fonctionnellement acceptables.
Pour prendre l'exemple de deux stacks Open Source pouvant effectuer un lineage de données dans la constellation Hadoop, Apache Falcon et Apache Atlas, nous nous rendons compte des limites quand il s'agit de faire preuve de flexibilité devant la diversité des besoins fonctionnels et d'efficacité sur des périmètres aux tailles drastiquement différentes.
Ainsi, Atlas, qui est en cours de maturation (v0.8.1), effectue du lineage global de données en scrutant les méta-données internes des stacks (HDFS, Hive Metastore, HBase, Kafka, ...). La granularité du lineage est haute, au niveau du chemin des données, mais sans intégration de toutes les informations du cycle de vie de la donnée, telle que la version. Un data set peut garder indéfiniment la même URI mais sa version peut évoluer dans le temps, ce qui n'est pas géré par Atlas. Il sert principalement à effectuer du lineage statique, qui répond à la question : "De quelle table est issue telle autre table ?".
De son côté, Falcon, également en cours de maturation (v0.10), sert surtout de meta-orchestrateur, pouvant générer des informations de lineage de pipeline de données. Le grain est limité nativement au pipeline de données.
Si le besoin est de tracer de manière précise le cycle de vie des données, disons à la granularité du data set et de sa version, en répondant à la question : "De quel data set et dans quelle version de celui-ci est issu tel data set de telle version de telle table ?", la question devient vite une use case architectural pour le moins ardu. On parle ici de data lineage dynamique, où le traçage suit le cycle de vie de la donnée à mesure que les pipelines de traitement évoluent en termes de fonctions et de périmètre.
Cet article se propose de présenter une manière efficace de répondre à cette dernière question. Cette solution est basée sur l'utilisation d'Apache Spark comme moteur de traitements, notamment en exploitant l’arbre du plan d’exécution logique des traitements (Logical Execution Plan). Elle reste cependant ouverte par conception à une utilisation par d'autres processus de traitement.
Un peu de théorie
L'enjeu théorique principal du lineage de données est de répondre à la question "quelle(s) donnée(s) ont été utilisées par quel processus pour produire telle autre donnée ?". Bien que l'objet du traçage soient les données, ce sont les méta-données de celles-ci qui sont appelées à être exploitées pour établir ce lineage. Le concept habituellement adopté pour résoudre ce type de problématiques repose sur la formulation des relations entre entités sous forme de triples sémantiques. Ce type de concept est un des piliers du standard RDF (Resource Description Framework), une famille de spécifications de modèle de données des méta-données servant notamment à décrire les liens entres les ressources du Web Sémantique. On peut le retrouver également dans nombre de modélisations comme les modèles décrivant les graphes.
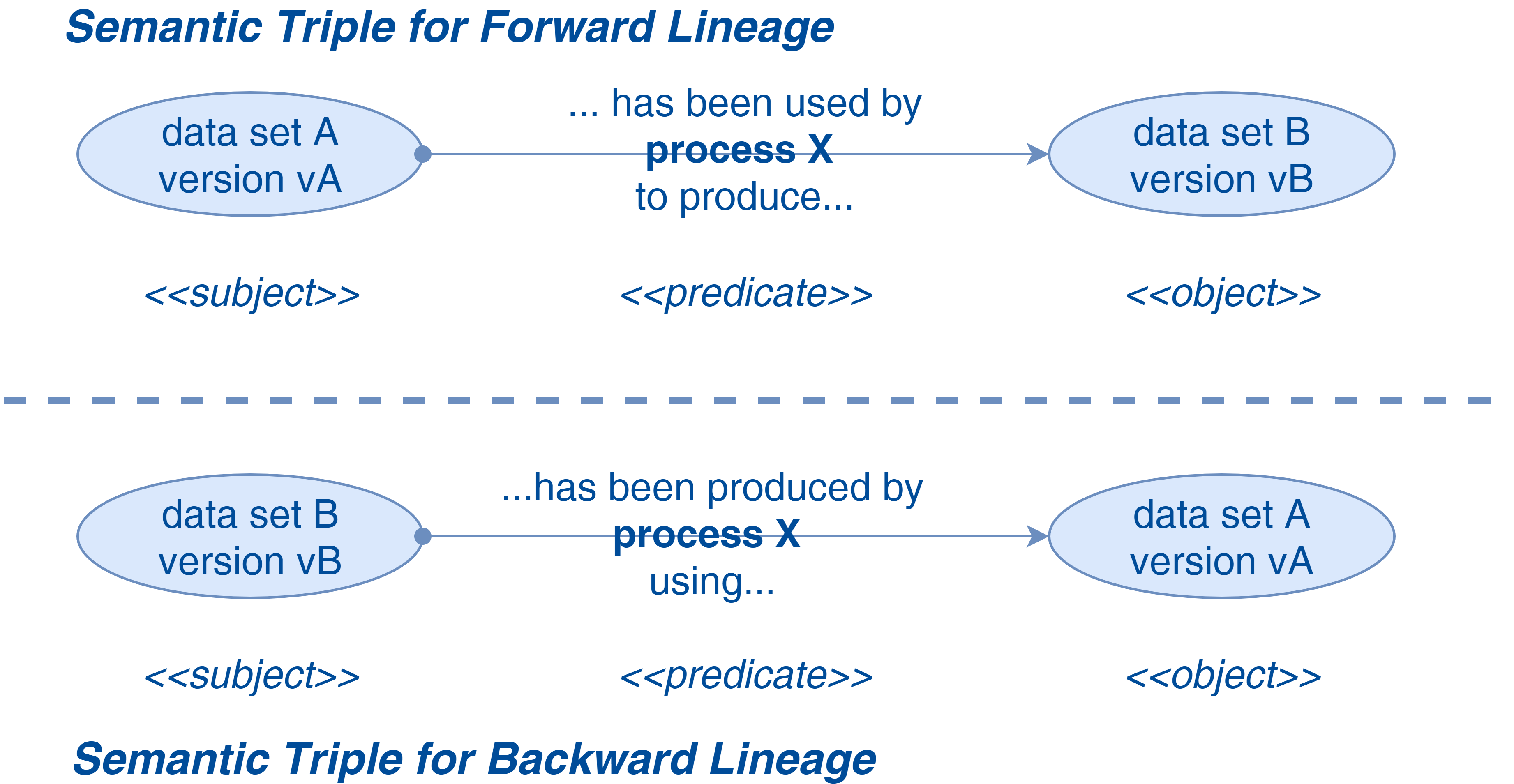
Un triple sémantique est un ensemble de trois entités qui permet de transcrire la relation entre elles. Il prend la forme : sujet --> prédicat --> objet. Appliqué au lineage de données, il peut se présenter sous deux modes :
- Le forward lineage, indiqué pour les analyses de propagation, utilise un prédicat qui lie une donnée à celles produites par un processus en utilisant celle-ci.
- Le backward lineage, plus approprié pour le traçage, utilise quant à lui un prédicat qui lie une donnée à celles qui ont servi à la produire grâce à une processus.
Si on transpose ces principes au traitement de données pour effectuer un lineage à la granularité du data set et de sa version, le triple sémantique peut être formulé comme ceci : "le data set B version vB a été produit par le processus X version vX en utilisant le data set A version vA". Il s'agit d'un backward lineage, le sujet étant le data set produit (B en version vB), le prédicat (ou encore le verbe) étant "a été produit par le processus X version vX en utilisant" et l'objet étant le data set utilisé (A en version vA).
Chaque data set produit est ainsi relié aux data sets sources par le biais d'un processus (et inversement). Cette approche aboutit à construire un graphe acyclique orienté ou DAG (c'est à dire ne contenant pas de circuit fermé), permettant de remonter de chaque data set / version vers tous les data sets ayant servi à sa génération.
Il est intéressant de noter que dans ce cas de figure (notamment à ce niveau de granularité), seules les I/O des processus sont prises en compte, il n'est pas nécessaire d'exploiter les données manipulées en interne. Comme vu plus haut, ce niveau de granularité (data set / version) nécessite également d'effectuer un data lineage dynamique pour que le mécanisme implémenté permette de suivre l'évolution des versions sans changement de modèle ou de code.
Une des difficultés majeures que l'on peut rencontrer est la gestion de la version de data set. Une multitude de cas peuvent exister et aboutir à une stratégie différente, en fonction du use case et de l'architecture adoptée. A titre d’illustration des stratégies possibles, prenons un exemple où la version de chaque data set correspond fonctionnellement aux données collectées/traitées durant un jour donné et est matérialisée par un simple incrément.
Il est alors possible d'adopter deux stratégies différentes d'adressage des données, correspondant à deux choix architecturaux :
- Les data sets sources de versions différentes sont adressés par version : c'est le cas notamment lorsque la version du data set à utiliser par un processus est connue au lancement de manière directe ou indirecte (fournie par un ordonnanceur exploitant des règles précises de déduction de la version)
- Les data sets sources de versions différentes sont adressés de manière indifférenciée : ce cas est plus compliqué à gérer. Sans une stratégie de transmission de l'information de version vers les data sets générés, cela finit en une situation où les data sets générés vont être issus de toutes les versions de data sets sources (voir figure ci-dessous). On peut adopter une solution se basant sur les principes suivants :
- La version des data sets générés par un processus est, au cours de l'exécution de ce dernier, calculée en fonction des versions des data set sources. Elle est alors identique, par version de data set source, pour tous les data sets générés
- Dans le groupe de sources d'un processus, un unique data set, qu'on appellera "data set de référence" pour le processus, doit être choisi pour porter la version "de référence". C’est cette dernière qui est propagée en tant que version unique des data sets générés
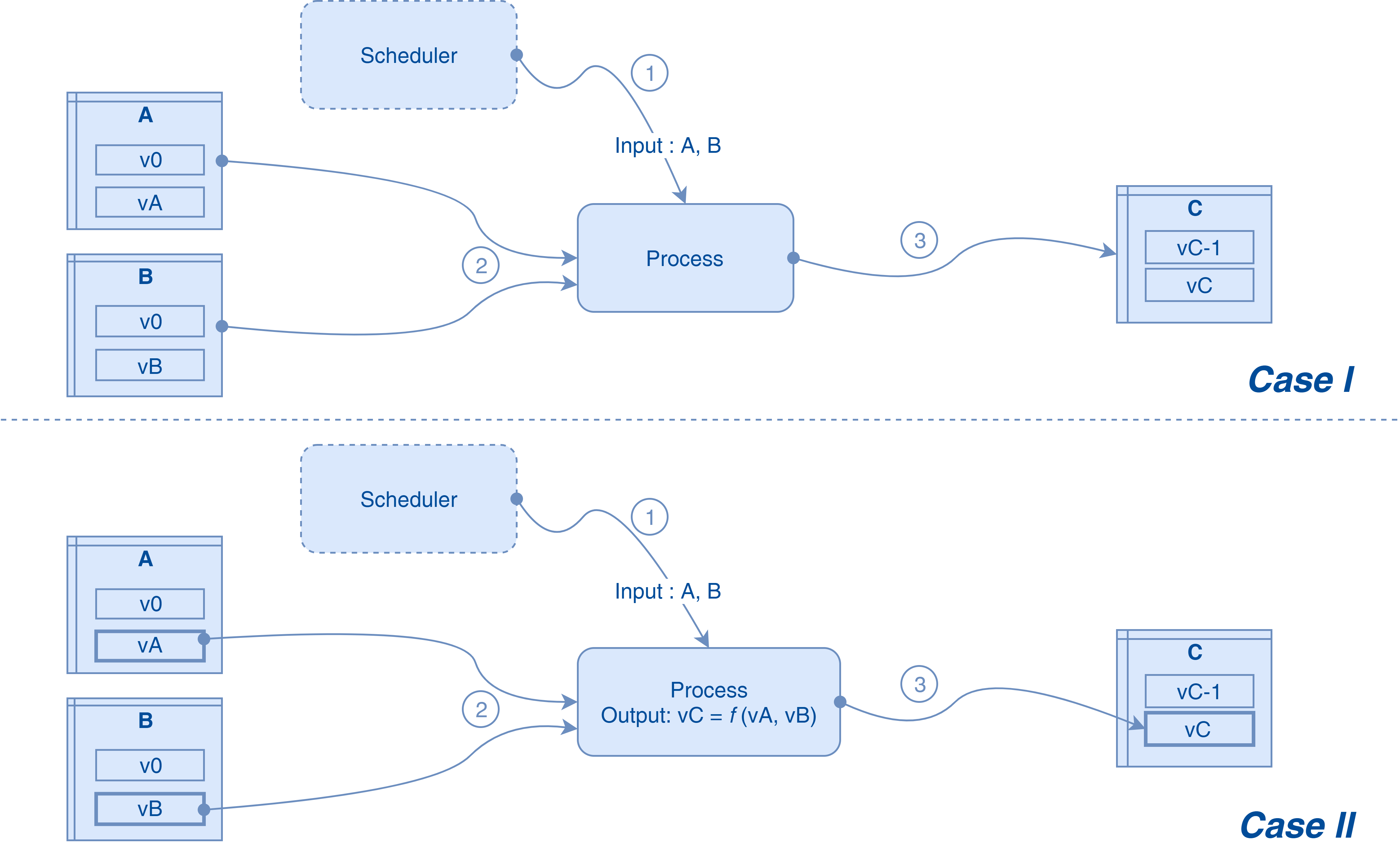
Dans le Cas I, les data sets sources A et B sont adressés sans référence à la version. Le data set généré C dépend alors de toutes les versions des data sets A et B. On retombe dans une situation de lineage statique. Dans le Cas II, les data sets sources A et B sont adressés par version, la version vC du data set généré C est alors calculée en fonction de vA et vB. Dans notre cas, nous désignons un data set de référence, A par exemple, et une fonction simple de calcul : vC = vA.
Traitement d'un cas typique
La proposition qui suit est issue de travaux effectués dans le SI d'un client, dans le cadre d’un PoC, destiné à fournir une solution présentant :
- une empreinte minimale pour les applications existantes et futures (effort de développement, maintenabilité, refactoring, overhead de processing, ...)
- restant compatible avec un noyau existant tournant sous Spark, sans prise de risque par intégration de stacks exogènes
- bénéficiant d'une architecture Hautement Disponible, résiliente, scalable, évolutive, réactive, découplée et conforme au pattern CQRS de l'architecture globale
Fonctionnellement, la motivation principale du client était de répondre à une contrainte légale de permettre un audit fin de l'origine des données au niveau du data set. Opérationnellement, il s'agissant d'obtenir une maîtrise parfaite du périmètre d'impact d'une action sur un data set estampillé comme critique pour en assurer une re-génération en toutes circonstances.
Simplification
Tous ces sujets ne pourront pas être abordés dans cet article. Je propose une vision simplifiée du problème, focalisée sur la problématique du lineage tout en gardant à l'esprit les contraintes citées ci-dessus. L'intégralité du code source de démonstration utilisé est disponible ici.
Ainsi, dans ce use case très simplifié :
- Des data sets sont lus sur HDFS et sont persistés sur le même système de fichiers.
- Les data sets clients-vX et products-vY sont utilisés par un premier driver Spark (BusinessDriver_One) pour produire une composition de ces données matérialisée dans le data set namesAndProducts et persistés dans le conteneur du même nom. Ici, X et Y dénotent la version du data set.
- Un second driver Business_Driver_Two se charge de générer à partir de ce dernier data set une vue agrégée formant le data set productSummary.
- Les drivers quant à eux sont des batchs Spark qui sont lancés potentiellement plusieurs fois par jour.
Choisissons la deuxième stratégie de propagation de version citée plus haut pour notre présent exemple. Le contenu des data sets peut également évoluer dans le temps, de nouvelles versions des enregistrements contenus pouvant être écrites. Il est judicieux alors d'inclure la version du data set dans le modèle de données des enregistrements, comme il suit dans le cas du data set clients-v15 :
{"name": "Bike", "surname": "Mike", "product-id": "B12", "quantity": "1", "version": "15"}
{"name": "Poll", "surname": "Kevin", "product-id": "R23", "quantity": "2", "version": "15"}
Il s'agira donc d'adapter le mécanisme de lineage et de persistance pour prendre en compte les valeurs possibles de cette version. Par exemple, nous avons choisi dans notre cas d'utiliser la version comme l'une des clés de partitionnement en aval des fichiers d'entrée (à savoir dans les fichiers namesAndProducts et productSummary) pour permettre les opérations de purge des données basées sur la version de data set.
Qui dit cycle de vie de datasets dit également identification univoque dans le SI de toute instance de processus. Ceci implique qu'identifier de manière statique un processus (par le nom de la classe du driver pour un exemple très simpliste) ne suffit pas. Chaque instance, c.à.d. chaque lancement effectif de chaque driver, devra être identifiée de manière unique. Dans cet exemple, cette instance sera identifiée par un Run Id composée avec l'identifiant du driver.
Notre exemple est alors décrit par la schéma suivant :
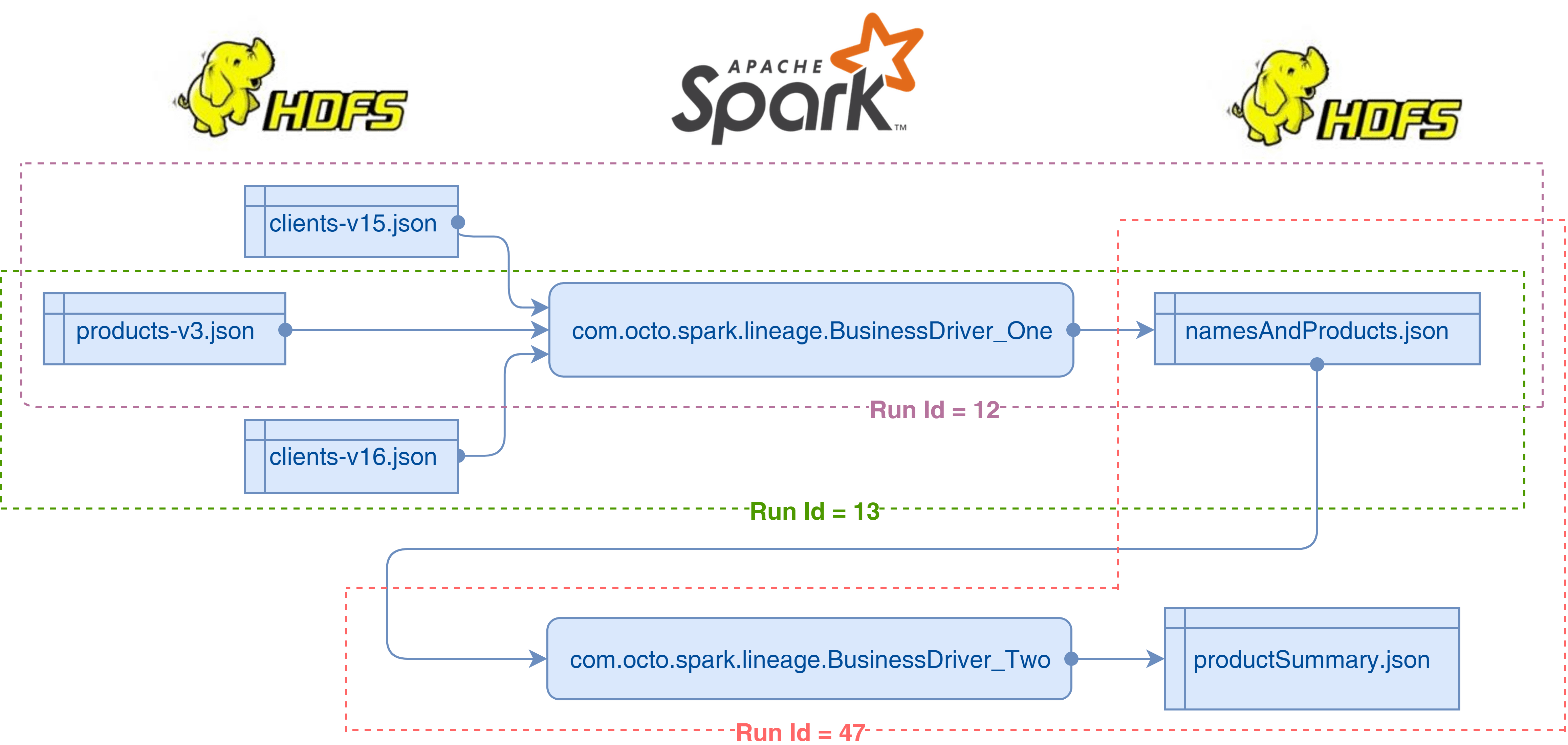
Dans le Run Id 12, les fichiers clients-v15.json et products-v3.json sont traités par BusinessDriver_One pour ensuite persister le résultat dans namesAndProducts.json. Dans le Run Id 13 une nouvelle version de clients est intégrée. Le Run Id 47 de BusinessDriver_Two intervient suite à ces deux runs pour produire une vue agrégée de namesAndProducts dans productSummary.json.
Spark comme provider local de metadata de lineage
Pour parvenir à générer les informations de lineage de manière dynamique, l'idée est d'exploiter certaines particularités du moteur de traitements Spark. En effet, dans une des phases de préparation de l'exécution des traitements de manière distribuée, ce moteur construit notamment un DAG des transformation effectuées qu'il formalise dans un plan d'exécution logique, ce qui en fait un lineage des transformations. Comme ces transformations utilisent des data sets en entrée et génèrent des data sets en sortie, il suffit de trouver le moyen d'utiliser ce DAG pour répondre à notre besoin de tracer les data sets.
Dans les applications de traitement industrialisés basées sur Spark, telles que celles développées pour les Data Hub, les conteneurs de données les plus largement utilisés sont les RDD. Depuis la version 2.0 de Spark, l'utilisation des DataFrame et des DataSet se répand avec la maturité de Spark SQL. Dans l'un ou l'autre cas, exploiter le DAG se fera de manière différente.
Utilisation des RDD
Sur une instance de RDD, il existe une fonction toDebugString() qui fournit un String décrivant le DAG de transformations permettant d'obtenir ce RDD :
(2) ShuffledRDD[29] at reduceByKey at BusinessDriver_One.scala:46 []
+-(2) UnionRDD[28] at union at BusinessDriver_One.scala:46 []
| MapPartitionsRDD[13] at map at BusinessDriver_One.scala:20 []
| MapPartitionsRDD[7] at rdd at AppCore.scala:52 []
| MapPartitionsRDD[6] at rdd at AppCore.scala:52 []
| MapPartitionsRDD[5] at rdd at AppCore.scala:52 []
| FileScanRDD[4] at rdd at AppCore.scala:52 []
| MapPartitionsRDD[27] at map at BusinessDriver_One.scala:22 []
| MapPartitionsRDD[21] at rdd at AppCore.scala:52 []
| MapPartitionsRDD[20] at rdd at AppCore.scala:52 []
| MapPartitionsRDD[19] at rdd at AppCore.scala:52 []
| FileScanRDD[18] at rdd at AppCore.scala:52 []
Cette fonction est destinée au débogage et ne fournit pas une information structurée. J'ai reproduit la logique exacte de Spark 2 pour fournir, moyennant un RDD en paramètre, l'arbre de lineage de ces traitements. Ce qui donne pour le même RDD (voir la fonction RDDLineageExtractor.lineageTree() ):
(2) ShuffledRDD[29] at reduceByKey at BusinessDriver_One.scala:46 []
UnionRDD[28] at union at BusinessDriver_One.scala:46 []
MapPartitionsRDD[13] at map at BusinessDriver_One.scala:20 []
MapPartitionsRDD[7] at rdd at AppCore.scala:52 []
MapPartitionsRDD[6] at rdd at AppCore.scala:52 []
MapPartitionsRDD[5] at rdd at AppCore.scala:52 []
FileScanRDD[4] at rdd at AppCore.scala:52 []
MapPartitionsRDD[27] at map at BusinessDriver_One.scala:22 []
MapPartitionsRDD[21] at rdd at AppCore.scala:52 []
MapPartitionsRDD[20] at rdd at AppCore.scala:52 []
MapPartitionsRDD[19] at rdd at AppCore.scala:52 []
FileScanRDD[18] at rdd at AppCore.scala:52 []
Cette fonction peut alors être utilisée dans un code centralisé, tel que le noyau générique des applications (ici symbolisé par la classe AppCore), pour être invoquée à chaque action (typiquement un I/O) de tout driver exécuté. Les informations de lineage, dont l'arbre de traitements, sont alors générées en invoquant la même fonction (ici lineSparkAction() ) à la lecture d'un JSON, juste après avoir construit le RDD correspondant et, à l'écriture d'un RDD, juste avant sa persistance :
def writeJson(rdd: RDD[_ <: Row], outputFilePath: String): Unit = {
lineSparkAction(rdd, outputFilePath, IoType.WRITE)
val schema = rdd.take(1)(0).schema
spark.createDataFrame(rdd.asInstanceOf[RDD[Row]], schema).write.json(outputFilePath)
}
def readJson(filePath: String): RDD[Row] = {
val readRdd = spark.read.json(filePath).rdd
lineSparkAction(readRdd, filePath, IoType.READ)
readRdd
}
La fonction de lineage a, quand à elle, trois responsabilités : faire générer l'arbre de traitements par la fonction lineageTree(), générer les méta données du data set (qu’il soit d’entrée ou de sortie, tout dépend du sens de l’I/O) en analysant le RDD et le conteneur cible et, enfin, produire les messages de lineage en exploitant toutes ces données. Dans notre cas, et par souci de simplicité, ces messages sont également persistées sur HDFS. On peut cependant imaginer beaucoup d'autres patterns dépassant le cadre de cet article.
private def lineSparkAction(rdd: RDD[_ <: Row], outputFilePath: String, ioType: IoType.Value) = {
val rddLineageTree: TreeNode[String] = RDDLineageExtractor.lineageTree(rdd)
val datasetMetadata: (String, String) = getDatasetMetadata(rdd, outputFilePath)
val processInformation: String = processId
produceLineageMessage(rddLineageTree, datasetMetadata, processInformation, ioType)
}
Utilisation des DataFrame (ou des DataSet)
Lorsque l'on utilise des DataFrame (ou des DataSet) de Spark SQL, la tâche est nettement simplifiée. En effet, depuis la version 2 de Spark, les informations de lineage des traitements sont fournies directement par l'API des DataFrame. Pour un DataFrame donné, la méthode inputFiles() renvoie un tableau des sources de données utilisées pour générer ce DataFrame. De ce fait, on peut se suffire d'intercepter uniquement les outputs pour générer les informations de lineage. L'impact immédiat est que moins de messages de lineage sont générés.
def readJsonDF(filePath: String): DataFrame = {
spark.read.json(filePath)
}
def writeJson(df: DataFrame, path: String, lineData: Boolean = true, saveMode : SaveMode = SaveMode.Overwrite): Unit = {
if (lineData) lineSparkAction(df, path, IoType.WRITE)
df.write.mode(saveMode = saveMode).json(path)
}
Petit bémol à garder à l'esprit : "Depending on the source relations, this may not find all input files". Le concepteur/développeur doit vérifier que les différentes data sources utilisées sont bien tracées.
Contenu des informations de lineage
Les message de lineage ainsi générés doivent contenir les informations permettant de construire in fine les triples sémantiques nécessaires à la construction du graphe de lineage des data sets. Une liste suffisante mais non exhaustive des informations à incorporer est :
- Définition univoque du processus
- Nom complet de la classe de driver
- Run Id
- Identifiant du domaine applicatif (par ex. le group-id maven)
- Identifiant du module applicatif (par ex. l'application-id maven)
- La version de l'application
- Définition univoque des data sets
- Identifiant (par ex. le nom de la table)
- URI (par ex. URL complète sur HDFS)
- version (celle du data set à la granularité ciblée)
- le type d'I/O (lecture ou écriture)
- le statut de cycle de vie initial
- Les sources et puits (sink) de lineage
- Dans le cas d’un I/O en écriture :
- La “destination” du traitement générant le message de lineage (dite puits ou sink), correspondant à la racine de l’arbre de lineage
- Les “origines” du traitement générant le message de lineage (dites sources), correspondant aux feuilles de l’arbre
- Dans le cas d’un I/O en lecture
- Les sources uniquement (feuilles de l’arbre)
- Dans le cas d’un I/O en écriture :
Le statut de cycle de vie étant justement une méta donnée appelée à évoluer avec le cycle de vie fonctionnel du data set (ex. passer d'un état "donnée quelconque" à "donnée critique").
Génération du graphe de lineage
Dans notre cas, l'identification du processus dans les messages de lineage a été simplifié à son strict minimum. Ainsi, seuls sont exploités le nom de la classe ainsi que le Run Id. Le reste des informations à identifier dans la méthode lineSparkAction() ne relevant pas d'un challenge technique.
Les messages de lineage générés dans notre exemple forment le data set suivant :
+----------------+------+--------------------------------------------+---------+-----------------------------------------------------------------+------------------------------------------------------------------------------------------+-------+------------------------------------------------------------------------------------+-------+
|datasetName |ioType|producer |reference|sinks |sources |status |uri |version|
+----------------+------+--------------------------------------------+---------+-----------------------------------------------------------------+------------------------------------------------------------------------------------------+-------+------------------------------------------------------------------------------------+-------+
|namesAndProducts|WRITE |com.octo.spark.lineage.BusinessDriver_One$13|false |(1) MapPartitionsRDD[29] at map at BusinessDriver_One.scala:52 []|FileScanRDD[4] at rdd at AppCore.scala:45 [],FileScanRDD[16] at rdd at AppCore.scala:45 []|Initial|data-lineage-spark-demo/src/main/resources/examples/generated2/namesAndProducts.json|16 |
|namesAndProducts|WRITE |com.octo.spark.lineage.BusinessDriver_One$12|false |(1) MapPartitionsRDD[29] at map at BusinessDriver_One.scala:52 []|FileScanRDD[4] at rdd at AppCore.scala:45 [],FileScanRDD[16] at rdd at AppCore.scala:45 []|Initial|data-lineage-spark-demo/src/main/resources/examples/generated2/namesAndProducts.json|15 |
|productSummary |WRITE |com.octo.spark.lineage.BusinessDriver_Two$47|false |(1) MapPartitionsRDD[13] at map at BusinessDriver_Two.scala:28 []|FileScanRDD[4] at rdd at AppCore.scala:50 [] |Initial|data-lineage-spark-demo/src/main/resources/examples/generated2/productSummary.json |16 |
|namesAndProducts|READ |com.octo.spark.lineage.BusinessDriver_Two$47|true | |FileScanRDD[4] at rdd at AppCore.scala:50 [] |Initial|data-lineage-spark-demo/src/main/resources/examples/generated2/namesAndProducts.json|16 |
|products-v3 |READ |com.octo.spark.lineage.BusinessDriver_One$12|false | |FileScanRDD[16] at rdd at AppCore.scala:45 [] |Initial|data-lineage-spark-demo/src/main/resources/examples/raw/products-v3.json |3 |
|products-v3 |READ |com.octo.spark.lineage.BusinessDriver_One$13|false | |FileScanRDD[16] at rdd at AppCore.scala:45 [] |Initial|data-lineage-spark-demo/src/main/resources/examples/raw/products-v3.json |3 |
|clients-v15 |READ |com.octo.spark.lineage.BusinessDriver_One$12|true | |FileScanRDD[4] at rdd at AppCore.scala:45 [] |Initial|data-lineage-spark-demo/src/main/resources/examples/raw/clients-v15.json |15 |
|clients-v16 |READ |com.octo.spark.lineage.BusinessDriver_One$13|true | |FileScanRDD[4] at rdd at AppCore.scala:45 [] |Initial|data-lineage-spark-demo/src/main/resources/examples/raw/clients-v16.json |16 |
+----------------+------+--------------------------------------------+---------+-----------------------------------------------------------------+------------------------------------------------------------------------------------------+-------+------------------------------------------------------------------------------------+-------+
On se rend vite compte du côté incomplet des messages : nombre de messages (ceux en lecture) ne comportent pas de "sinks". Il est nécessaire dans ce cas, pour construire le graphe de lineage, d'effectuer une étape de consolidation. Elle consiste à mettre en relation les nœuds source avec les nœuds puits en analysant les graphes construits à partir des messages.
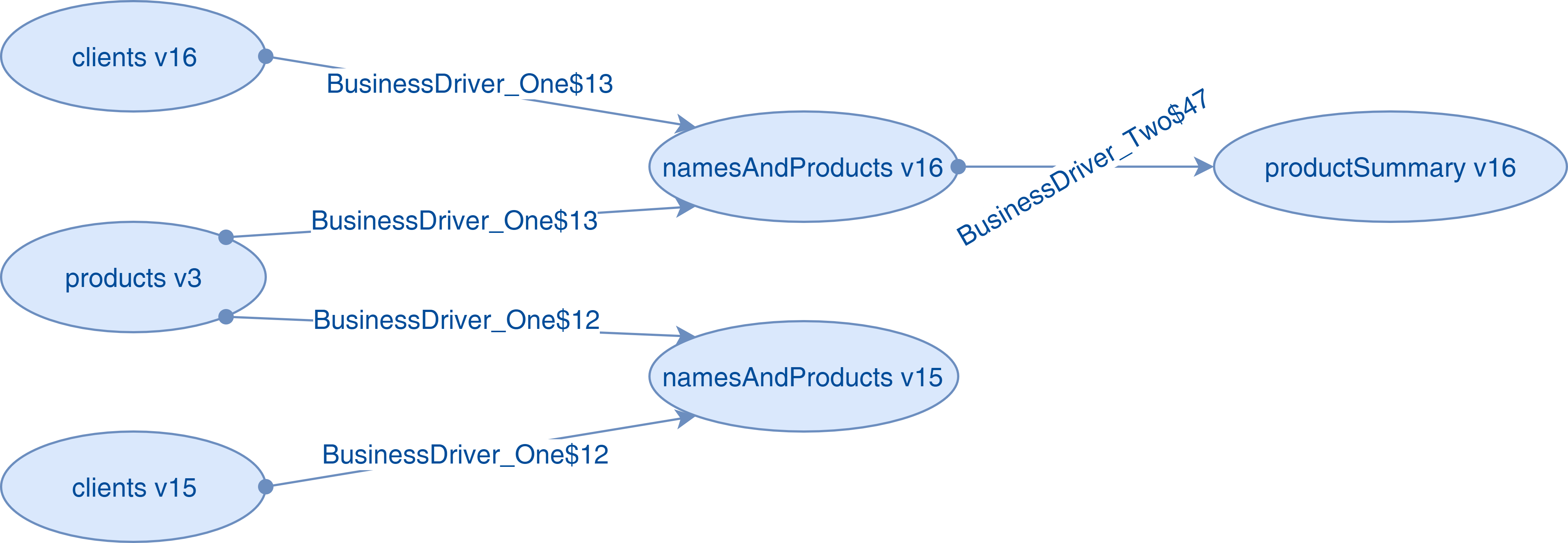
Une fois cette étape de consolidation effectuée, et une fois le graphe construit (classe LineageGraphGenerator), on obtient le lineage suivant pour notre exemple :
Node [0]---> [Dataset: namesAndProducts, Version: 16] has been produced by:
[com.octo.spark.lineage.BusinessDriver_One$13] using: [Dataset: products-v3, Version: 3]
[com.octo.spark.lineage.BusinessDriver_One$13] using: [Dataset: clients-v16, Version: 16]
Node [1]---> [Dataset: namesAndProducts, Version: 15] has been produced by:
[com.octo.spark.lineage.BusinessDriver_One$12] using: [Dataset: products-v3, Version: 3]
[com.octo.spark.lineage.BusinessDriver_One$12] using: [Dataset: clients-v15, Version: 15]
Node [2]---> [Dataset: productSummary, Version: 16] has been produced by:
[com.octo.spark.lineage.BusinessDriver_Two$47] using: [Dataset: namesAndProducts, Version: 16]
Présenté graphiquement (en tronquant les noms de classe pour la lisibilité), cela correspond à ce qui suit :
Exploitation du graphe de lineage
Ce graphe de lineage peut alors être exploité pour gérer le cycle de vie des données au niveau des data sets. Par exemple, supposons que seul le data set productSummary en version 16 doit être retenu au long terme car considéré comme une donnée critique par le métier. En parallèle, nous désirons supprimer dans un processus de purge les plus anciennes versions des data sets clients et products. Dans quelle mesure peut-on effectuer cette suppression sans mettre en péril la possibilité de reprise (comme dans le cadre d'un PRA) de la donnée productSummary ?
La réponse à cette question revient à effectuer une analyse d'impact sur le graphe de lineage. Cette analyse repose sur l'identification de composants connectés (connected components) par l'implémentation de l'algorithme du même nom en utilisant un moteur de base de données orienté graphe. Le moteur utilisé dans notre cas (toujours dans la classe LineageGraphGenerator) étant Neo4j, via une intégration très simpliste pour les besoins de l'article. Cet algorithme fournit alors un sous-graphe qui permet de connaitre tous les data sets / versions sources "connectés" avec productSummary en version 16, en l'occurrence clients v16 et products v3.
C'est ici qu'intervient l'attribut "status" ajouté au modèle de données des messages de lineage. Par défaut, tous les nœuds se voient attribuer la valeur "Test". Si un data set est déclaré "critique" par le métier, un service spécifique devra se charger de mettre à jour le nœud correspondant dans la base de données graphe en conséquence. Le même service se chargera de requêter cette base de données pour obtenir les data sets connectés et les tagger également comme "critiques". Le service de purge, lui, devra systématiquement vérifier le statut d'un data set / version et ne pas le supprimer si son statut est "critique".
En résumé
Le sujet est vaste et implique des impacts profonds, tant au niveau architectural, gestion des développements, que de gouvernance de la donnée. Dans cet article, nous avons néanmoins défriché certains aspects clefs du data lineage de données au niveau du data set, à savoir :
- la possibilité - pour le moment - d'implémenter en in-house la solution si le niveau de granularité du traçage est relativement fin
- les éléments de théorie sur lesquels se baser
- la possibilité d'utiliser des particularités intéressantes de Spark pour intégrer cette logique dans les parties centrales d'applicatifs de traitements
- comment elles peuvent s'intégrer dans le code avec le traitement d'un cas typique
- la stratégie de gestion de version des data sets
- la structure des messages de lineage
- l'exploitation de ces messages pour bâtir le graphe de lineage
- une piste d'exploitation du graphe