Comment conserver les mots de passe de ses utilisateurs en 2019 ?
Lorsque vous concevez une application, vous vous posez forcément la question de l’authentification et du contrôle d’accès. Pour ça, plusieurs méthodes sont disponibles et la première qui vient généralement à l’esprit est l’utilisation d’un couple identifiant / mot de passe.
Dans la mesure du possible, on préfèrera utiliser une solution dédiée à l’authentification et au contrôle d’accès : en bref, utiliser une solution d’IAM pour gérer ces aspects à votre place. C’est généralement plus simple à maintenir et c’est surtout souvent meilleur pour l’expérience utilisateur.
On utilisera généralement pour cela les protocoles Oauth2 et OpenID Connect, plus de détails sur l’approche et les concepts ici.
Mais il demeure des cas où (pour des raisons techniques, métier, voire philosophiques) on voudra stocker des mots de passe pour notre simple application web. Et c’est là qu’une question majeure se pose : quel est l’état de l’art en 2019 pour stocker un mot de passe ?
Hacher et saler : non ce n’est pas de la cuisine !
Le mot de passe est une donnée qu’il convient de protéger car voler le mot de passe de quelqu’un permet d’accéder à ses privilèges sur l’application où on l’a volé ...
… Et sur d’autres applications parce que vos utilisateurs utilisent les mêmes mots de passe partout.
On cherche donc un processus qui permette de stocker autre chose que le mot de passe, une sorte de donnée dérivée qui permettra à coup sûr de vérifier que l’utilisateur entre la bonne information, mais sans stocker le mot de passe en clair. Au cas où votre base de données (ou celle d’un autre !) serait diffusée.
On veut donc :
- Le transformer en un résultat qui sera toujours le même, mais différent du mot de passe initial (pour vérifier à coup sûr la concordance)
- Qu’on ne puisse pas retrouver le mot de passe d’origine à partir du résultat
- Qu’il soit possible de trouver un résultat pour n’importe quel mot de passe en entrée
Il se trouve qu’il existe un outil qui fait exactement ça : des fonctions mathématiques particulières : les fonctions de hachage (ou hashage). Le résultat de cette fonction est appelé hash (ou encore empreinte ou condensat).
Super, on a des fonctions qui nous permettent de stocker une donnée dérivée du mot de passe (le hash) et qui nous évite qu’on retrouve la donnée initiale ! On est prêts ?
Eh bien non, pas encore. En fait, il reste une problématique que l’on n’a pas évoquée. Et pour l’illustrer on va faire une petite mise en situation.
Vous possédez une base de données contenant les mots de passe hashés de vos utilisateurs. Une fonction de hashage donne toujours le même résultat pour une même entrée. Cela vous assure de pouvoir vérifier que le mot de passe que vous propose l’utilisateur est bien le bon.
Sauf qu’il y a un problème. La plupart de vos utilisateurs utilisent les mêmes mots de passe. Ce qui veut dire que votre base de données va ressembler à ça :
| Utilisateur | Hash |
|---|---|
| nadia | 5f4dcc3b5aa765d61d8327deb882cf99 |
| kailash | f71dbe52628a3f83a77ab494817525c6 |
| malala | 5f4dcc3b5aa765d61d8327deb882cf99 |
| denis | 5f4dcc3b5aa765d61d8327deb882cf99 |
| juan-manuel | 5d41402abc4b2a76b9719d911017c592 |
| ... | ... |
L’attaquant a aussi à disposition la liste des mots de passe les plus fréquents et peut lier les mots de passe globalement fréquents à vos mots de passe hashés les plus présents. Ici, Nadia, Malala et Denis ont le même mot de passe. Il y a fort à parier que celui-ci soit très commun. Plus la base de données est grande et plus les corrélations sont représentatives.
Pour éviter cela, on stocke dans la base de données une chaîne de caractères générée aléatoirement, différente pour chaque utilisateur. On l’appelle un "sel". Cette chaîne de caractères est ajoutée au début du mot de passe avant de hasher :
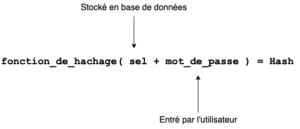
On prendra soin de créer notre sel avec un générateur de nombre aléatoire adapté à la cryptographie. Les fonctions permettant de générer ces chaînes de caractères sont la plupart du temps facile à identifier (à condition qu’on les connaisse). On peut par exemple citer SecureRandom en Java ou encore crypto.randomBytes() en node.js.
Cette méthode permet de donner un hash propre à l’utilisateur, même si le mot de passe est identique.
Par exemple, avec la base de données de tout à l’heure, et sachant que les utilisateurs ont toujours les mêmes mots de passe, chaque utilisateur aura un hash différent :
| Utilisateur | Sel | Hash |
|---|---|---|
| nadia | ahygif | 1d44bde8465fdd37f63070739af0e21e |
| kailash | hfzjli | e19f90f109047a39afb3c4d90aa45bd4 |
| malala | ksutf” | 87ea2f42a9e6d6471f61389ea8b45378 |
| denis | oknsfr | 4d4156f6086f99eed39f19ac92668ef3 |
| juan-manuel | pmlkjh | 86dfda0725c183011ce3f685a9049058 |
| ... | ... | ... |
Cette méthode permet également d’éviter les attaques par Rainbow Table, que nous ne traiterons pas en détails ici, mais qui est un modèle d’attaque courant.
On sait désormais qu’il faut hasher ses mots de passe et utiliser un sel. Maintenant, quel algorithme de hash utiliser ? Se valent-ils tous ?
Quel algorithme ?
Ceux qu’il faut éviter
Si vous avez déjà entendu parler de hash mais que vous ne vous y êtes pas attardé, vous avez peut-être entendu parler d’un certain nombre d’algorithmes : MD5, SHA-1, SHA-2 (SHA-224, SHA-256, SHA-384, SHA-512), SHA-3.
Sachez que ces algorithmes ne doivent pas être utilisés pour hasher des mots de passe, pour les raisons suivantes :
- Ces algorithmes sont souvent très rapides pour le calcul des hashs. C’est un désavantage dans le cas des mots de passe car cela permet à l’attaquant de mettre en place facilement des attaques par force brute (test de toutes les combinaisons possibles) ou par dictionnaire.
- Ils ne facilitent pas la mise en place des sels
Vous pouvez utiliser SHA-2 et SHA-3 pour d’autres utilisations que des mots de passe (par exemple pour servir d’empreinte d’un document, mettre en place une vérification SRI, participer à la signature d’un certificat, ...). Voyons maintenant quels algorithmes sont à favoriser dans notre cas.
Ceux qu’on favorise
Mettons en avant les points essentiels à prendre en compte pour déterminer si vous devez utiliser un algorithme plutôt qu’un autre pour hasher des mots de passe.
Le seul aspect générique et indépendant de l’implémentation est l’ensemble de propriétés cryptographiques pures de l’algorithme. Cela se traduit par la résistance aux attaques par force brute, dictionnaire et rainbow table. Le tout avec les technologies utilisées par les attaquants. En 2019, les attaquants qui souhaitent casser vos hash vont généralement utiliser un GPU. Pour ceux qui ont de l’argent, plusieurs en parallèle.
En plus de cela, il faut prendre en compte le contexte technique. Pour votre technologie cible (celle que vous souhaitez utiliser à un instant T), vous souhaitez évaluer :
- La disponibilité des implémentations
- Le support des implémentations
- La facilité d’utilisation des implémentations (génération des sels, documentation de l’API, compatibilité, ...)
Sur les purs critères techniques, indépendants de l’implémentation et de la disponibilité de l’algorithme dans votre langage préféré, on pourrait classer les algorithmes ainsi :
| Argon2 | Scrypt | Bcrypt | PBKDF2 | |
| Résistance aux attaques communes (online / CPU) | ✓ | ✓ | ✓ | ✓ |
| Résistance aux mêmes attaques, par GPU | ✓ | ✓ | ✓ | / |
| Résistance aux attaques GPU, avec beaucoup de ressources (parallélisées, bonnes cartes GPU) | ✓ | / | ✗ | ✗ |
Comparaison des algorithmes de hachage de mots de passe (sources : 2, 3, 4, 5)
Légende :
✓ : Très robuste, pas de difficultés, que cela soit maintenant ou à moyen terme / : Robuste, pas de difficultés majeures en 2019, la situation pourrait se complexifier d’ici quelques années (amélioration du matériel, évolution des techniques) ✗ : Peu robuste, sensible aux attaques et vulnérable maintenant ou dans un futur proche
Cette rapide comparaison met beaucoup en avant Argon2.
L’algorithme a des propriétés extrêmement intéressantes et il est certainement le plus résistant aujourd’hui. C’est d’ailleurs pour cela qu’il a gagné la dernière Password Hashing Competition. Il a le seul défaut de n’être pas encore intégré de manière extrêmement aisée dans les langages et frameworks.
Scrypt est assez similaire à Argon2 dans sa réaction aux attaques. Il est un peu moins robuste mais aussi plus ancien et donc un peu mieux supporté (on le trouve notamment dans les API de node.js et Python). C’est aussi un très bon choix pour stocker vos mots de passe.
On a ensuite deux méthodes qui sont moins bonnes mais qui restent tout à fait acceptables : Bcrypt et PBKDF2.
Bcrypt est un bon algorithme, suffisamment robuste pour vous offrir une protection de qualité contre les attaques habituelles. C’est vrai aujourd’hui. Par contre si votre attaquant a de grosses capacités (beaucoup d’argent pour acheter beaucoup de GPUs), il s’en accomodera mieux que d’un Scrypt, et ce encore plus dans quelques années.
Concernant PBKDF2, c’est une norme (fixant comment dériver une clé à partir d’un algorithme déjà existant), et pas un algorithme. Cela signifie que sa robustesse est variable selon le choix de l’algorithme qui suit cette norme. Quel que soit l’algorithme, c’est la méthode la moins moderne de toutes celles qu’on présente ici. Cela a une conséquence logique : un bon support. C’est la méthode de hashage spécifique aux mots de passe la plus répandue, et c’est sans doute le mieux que vous pourrez avoir sur un système un peu ancien voir legacy.
En revanche, la norme a été publiée en 2000, à une époque où on ne se posait pas de questions sur l’utilisation de plusieurs cartes graphiques en parallèle.
En plus, les implémentations ne facilitent généralement pas la vie du développeur. Il faut choisir son algorithme PBKDF2 (PBKDF2WithHmacSHA1 ou PBKDF2WithHmacSHA512 ?) et il faut souvent changer le nombre d’itérations de l’algorithme parce que la valeur par défaut est insuffisante. Bref, il ne suffit pas de donner son mot de passe à la fonction pour avoir le résultat hashé et robuste.
Si vous avez besoin d’utiliser PBKDF2, il faut choisir le nombre d’itérations de l’algorithme pour chaque hash. L’idée est de faire autant d’itérations que possible sans trop dégrader les performances de l’application. L’OWASP recommande des temps de calcul d’environ 1s par hash. A vous de tester pour votre plateforme cible.
Aparté sur le changement de méthode de hashage
Au bout d’un certain nombre d’années, les fonctions de hashage (comme l’ensemble de la cryptographie) sont cassées (pour les hash, c’est le plus souvent, avec des collisions, mais parfois aussi avec des attaques plus dangereuses).
Dans quelques années vous devrez donc trouver un moyen de changer votre algorithme de hashage de mots de passe. Cela induit un peu de préparation. Voici une méthode, qui nous semble un bon moyen de changer de méthode de hashage, lorsque l’ancien devient vraiment obsolète :
- Identifier et conserver le fait que vos mots de passe sont hashés avec une ancienne méthode. Dans l’idéal vous pouvez utiliser une fonction de votre langage ou de votre framework qui le propose (exemple en PHP)
- Lorsqu’un utilisateur réussit à s’authentifier, en plus de son authentification, on refait le hashage de son mot de passe avec la nouvelle méthode et on remplace son ancien hash par le nouveau. On met à jour le fait que son mot de passe respecte le standard
- Après un certain temps (et plusieurs relances des utilisateurs…), et si c’est possible, on purge les mots de passe utilisant encore l’ancienne méthode de hash. Ils sont inactifs et leur mot de passe est en danger. On ne supprime pas forcément totalement les utilisateurs, ils peuvent donc encore récupérer leur compte via des fonctionnalités comme "Réinitialiser mon mot de passe".
Cette méthode n’est pas parfaite et induit notamment une purge partielle de votre base de données utilisateurs. Mais elle a l’avantage d’être transparente pour l’utilisateur actif et de faire peu de concessions sur la sécurité de tous vos utilisateurs.
Au final j’utilise quoi ?
Dans 99,9% des cas, vous devriez utiliser ce qui est disponible et bien supporté dans votre langage / techno cible.
Il est capital de se fier à des implémentations qui sont supportées et mises à jour régulièrement pour de la cryptographie. Si possible, on privilégiera les fonctions du langage ou du framework car ce sont les implémentations les mieux maintenues et ce sont souvent de simples bindings aux librairies de cryptographie reconnues (OpenSSL et libsodium notamment).
Globalement, on vous déconseille fortement d’installer des portages des meilleurs algorithmes si votre langage cible ne le propose pas. Si un algorithme acceptable est disponible dans votre technologie, préférez le à une implémentation du meilleur algorithme, car la qualité des implémentations peut être un peu aléatoire.
Enfin, il est indispensable de prendre en compte les problématiques des développeurs et du produit. On souhaite que l’effort pour implémenter et maintenir un bon algorithme soit minime.
Quelques exemples de l’API à utiliser en fonction des technologies utilisées :
- PHP : Argon2 est disponible nativement via la fonction password_hash, utilisez-le. Les frameworks peuvent par conséquent l’utiliser aussi : Symfony, Laravel
- Node : utilisez Scrypt (générez le sel avec randomBytes)
- Java : utilisez la meilleure implémentation pour votre framework : par exemple, Bcrypt pour Spring. Sans framework, utilisez une instance de SecretFactoryKey avec l’algorithme PBKDF2WithHmacSHA512 (générez le sel avec SecureRandom)
- Python : utilisez Scrypt. Pour Django, laissez par défaut avec PBKDF2
- Ruby on Rails : utilisez la gem bcrypt comme recommandé par le framework
Pour finir, n’oubliez pas que nous n’avons parlé que du stockage. Il existe d’autres méthodes complémentaires pour protéger les mots de passe de vos utilisateurs : blocage des comptes, vérification de la robustesse des mots de passe à leur création, ...
Ressources :
https://cheatsheetseries.owasp.org/cheatsheets/Password_Storage_Cheat_Sheet.html