Comment booster son application android grâce à de l’IA
Dans un monde “Mobile First”, la performance est un facteur clé du succès d’une application mobile. Plus celle-ci est performante, plus l’utilisateur y passera du temps. Les bonnes pratiques de développement intègrent des solutions techniques permettant d’optimiser le temps de chargement.
Pourrait-on aller encore plus loin, faire mieux pour l’utilisateur ?
Pour répondre à cette question, nous avons décidé de faire de la prédiction de parcours utilisateur grâce à du machine learning de manière à précharger les données de sa future navigation.
Mon binôme a travaillé sur le développement du modèle de machine learning pendant que j’ai travaillé sur l’intégration de celui-ci dans une application.
Cet article concerne donc l’implémentation de machine learning sur mobile, la partie machine learning sera couverte plus en détail par un futur article de mon binôme qui traitera en particulier des algorithmes de suggestions.
État de l’art du machine learning
De nos jours, il existe deux façons d’implémenter du machine learning sur mobile :
- Modèle hébergé en ligne & (ré)entrainé en ligne
- Modèle hébergé en local & (ré)entrainé en ligne
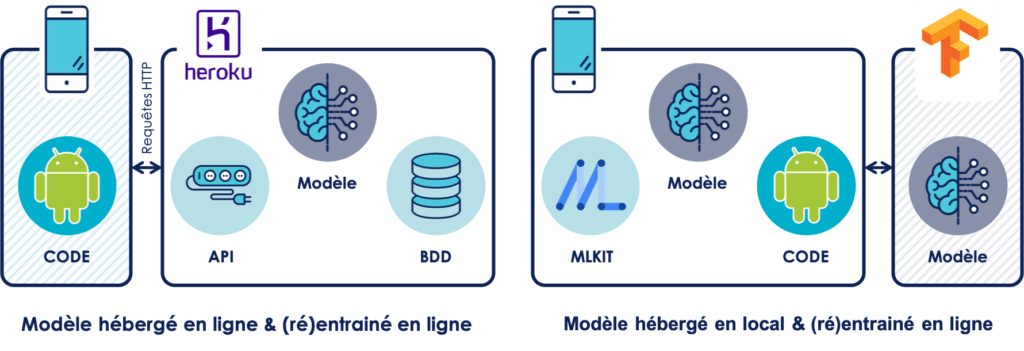
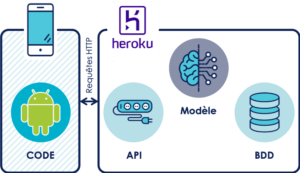
Modèle hébergé en ligne & (ré)entrainé en ligne :
Cette solution est la plus répandue à l'heure actuelle. Le développeur mobile va développer son application sans connaissance préalable concernant le machine learning. Il va simplement intégrer des requêtes REST pour communiquer avec un serveur sur lequel sera hébergé le modèle de machine learning. Le serveur, ainsi que le modèle de machine learning sont implémentés par une tierce personne, un data scientist par exemple.
De manière générale, cette solution comporte les avantages et inconvénients suivants :
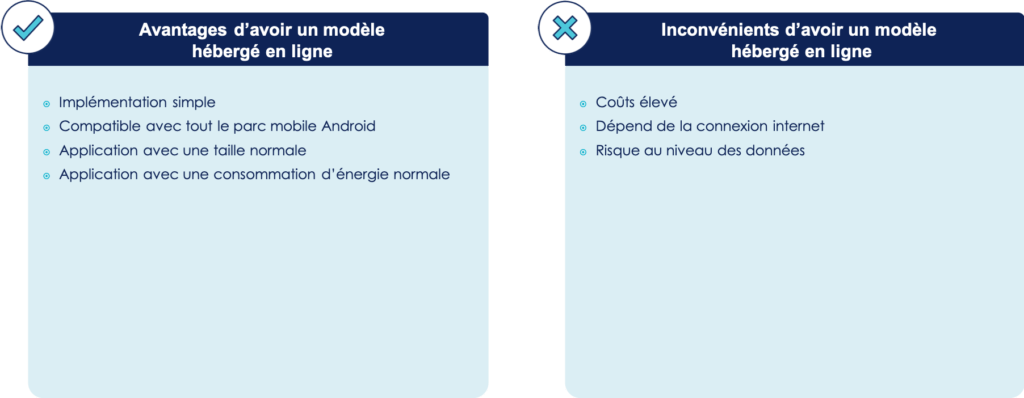
En effet, l’implémentation ne nécessite pas de compétences supplémentaires aux développeurs mobiles. De plus, la mise à jour du modèle de machine learning n’impacte aucunement l’application mobile. Le modèle n’étant pas exécuté sur le téléphone, il n’est pas nécessaire d’avoir un hardware puissant, de ce fait il n’y a aucune restriction de comptabilité concernant le parc mobile Android. Ceci évite aussi la consommation importante d’énergie entrainée par l’exécution d’un modèle de machine learning ; l’autonomie du téléphone n’est donc pas impactée. Enfin, le fait que le modèle soit hébergé en ligne permet à l’application de ne pas être alourdie par le poid de celui-ci.
Cependant, cette solution implique des coûts élevés. En effet, l’hébergement nécessite la présence de serveur, et l’entraînement/exécution du modèle nécessite une ferme de serveur avec une puissance de calcul conséquente afin de traiter toutes les requêtes de prédictions et d’entraînement. La prédiction ne peut se faire qu’en présence d’une connexion internet. Le temps relatif à l’envoi de la requête de prédiction avec l’ID de l’article, le calcul et l’envoi de la prédiction dépend de l’état de la connexion. Enfin, les données étant envoyées et stockées sur un serveur, il y a des risques concernant la fuite et la perte de ces données.
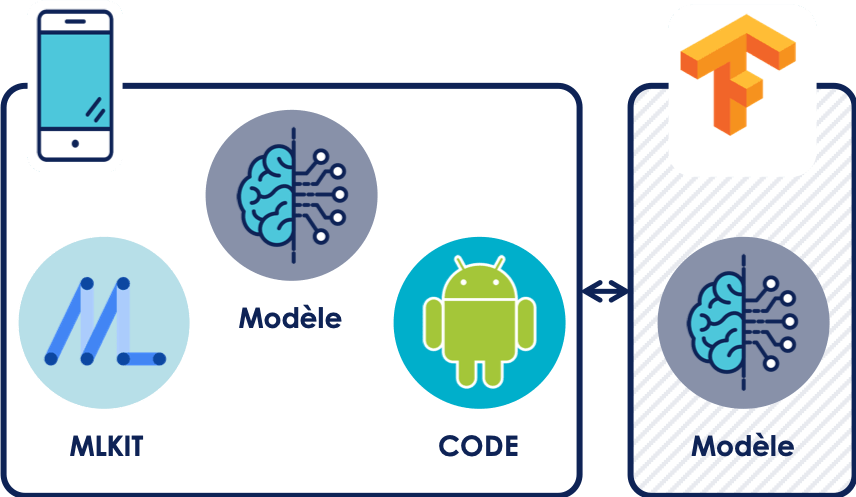
Modèle hébergé en local & (ré)entrainé en ligne :
Cette solution est plus complexe à mettre en place. Cette fois-ci il est nécessaire d’avoir un développeur avec quelques connaissances en machine learning, car le modèle est intégré dans l’application. Il n’est pas présent dans l’application lorsqu’elle vient d’être téléchargée. Cependant MLKit, le framework Android permettant l’intégration de machine learning en local sur un smartphone, va télécharger le modèle lorsque l’utilisateur sera dans des conditions favorables (assez de batterie et téléphone connecté à un réseau WIFI). Il est nécessaire d’héberger le modèle au préalable sur Firebase
De manière générale, cette solution comporte les avantages et inconvénients suivants :
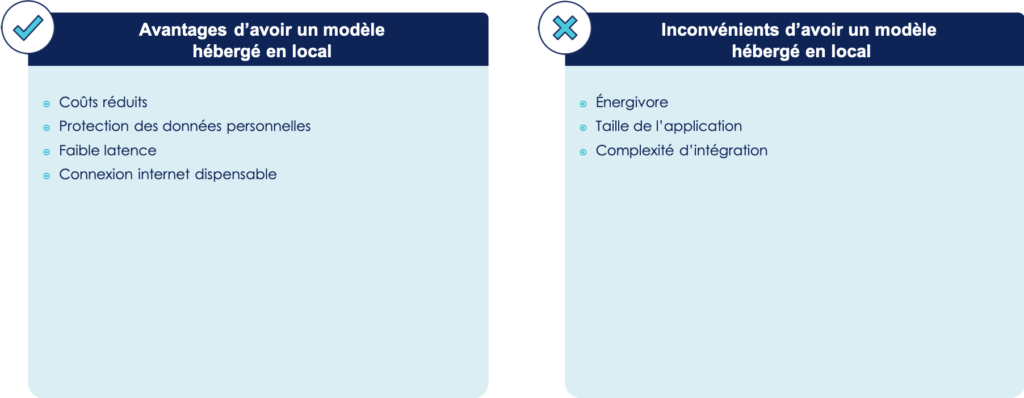
Cette solution évite les coûts élevés impliqués par l’utilisation d’une ferme de serveur car les calculs des prédictions se font directement sur le téléphone. Elle permet aussi d’éviter les risques de pertes/fuites de données, car elles sont stockées uniquement sur le téléphone. Dans le cas d’une utilisation sur un téléphone performant, la latence entre la demande de prédiction et le résultat est faible, elle ne dépend plus du réseau, mais uniquement des capacités du téléphone. Le modèle étant présent en local sur le téléphone, il peut s’exécuter sans la présence d’une connexion internet.
Cependant, la mise en place de cette solution est plus compliquée, elle nécessite des développeurs mobiles ayant des connaissances en machine learning afin qu’ils puissent travailler sur l’intégration du modèle de machine learning dans l’application. De plus, un modèle de machine learning atteint vite une taille conséquente (plusieurs méga octets) ce qui alourdit l’application, et le fait d’exécuter un tel modèle sollicite beaucoup le hardware du téléphone et réduit donc l’autonomie de sa batterie. Enfin, l’exécution du modèle sur le téléphone nécessite un hardware assez puissant pour être compatible avec le modèle, ce qui réduit drastiquement la compatibilité de la fonctionnalité de prédiction de parcours utilisateur.
Quid de la compatibilité du machine learning sur Android ?
Afin de gérer la comptabilité du machine learning avec le parc mobile Android qui est très diversifié, Google a déployé une API nommée Android Neural Networks. Son but est de faire la passerelle entre le hardware du téléphone et le framework de machine learning (MLKit)
[caption id="attachment_84606" align="aligncenter" width="551"] 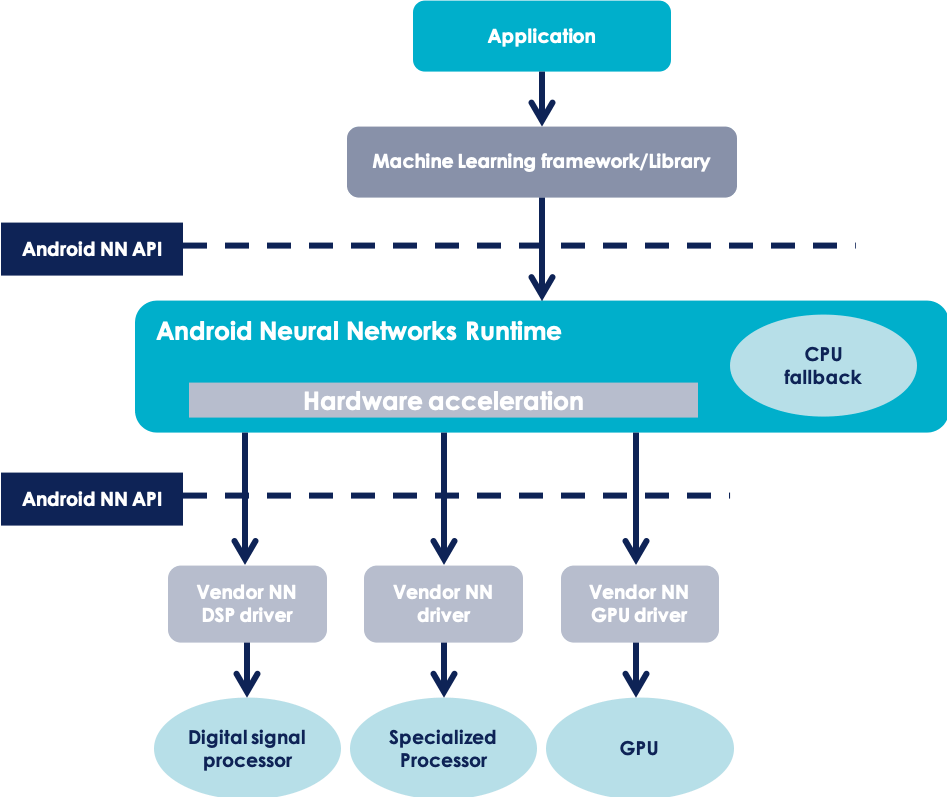
source : https://developer.android.com/ndk/guides/neuralnetworks[/caption]
Comme le montre la Figure 6, l’API Android Neural Networks récupère les données concernant les capacités de calcul du téléphone lors de la phase d’initialisation puis vérifie la compatibilité du téléphone dans la phase suivante. Il vérifie plus exactement que les différentes opérations requises par le modèle peuvent être opérées par le hardware du téléphone. Si c’est bien le cas, le modèle est alors compatible avec le téléphone et peut être exécuté.
[caption id="attachment_84609" align="aligncenter" width="351"] 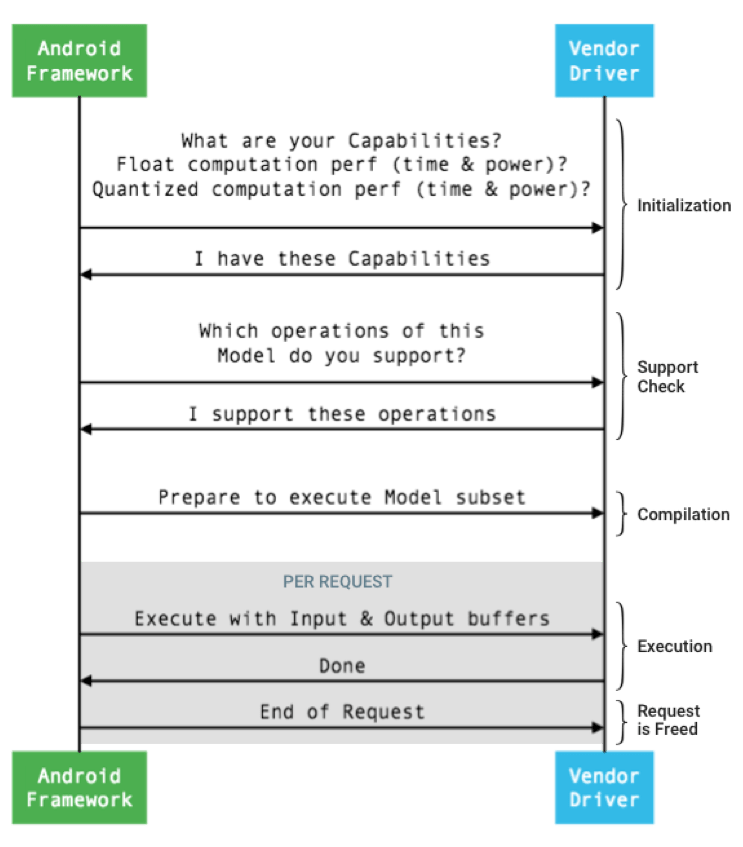
source : https://source.android.com/devices/interaction/neural-networks[/caption]
Illustration du workflow via notre Use Case :
Nous avons travaillé sur l’application du blog Octo. L’idée étant d’utiliser du machine learning afin de pré-charger les articles pouvant intéresser un lecteur pendant que celui-ci est en train de lire de manière à apporter une expérience utilisateur totalement fluide.
Si nous reprenons notre Use Case pour illustrer ces deux architectures, cela donne le workflow suivant :
| Modèle hébergé en ligne & (ré)entrainé en ligne | Modèle hébergé en local & (ré)entrainé en ligne |
| - L’utilisateur clique sur un article, l’application envoi l’ID de l’article à l’API REST du serveur.<br><br>- L’API du serveur transmet l’ID au modèle.<br><br>- L’API récupère la prédiction du modèle et l’envoie à l’application.<br><br>- Pendant que l’utilisateur lit l’article, l’application charge les articles issus de la prédiction.<br><br>- Quand l’utilisateur quitte l’article, l’application envoie des données utilisateur à l’API (temps passé sur l’article, catégorie de l’article etc.…).<br><br>- L’API récupère ces données et les stocke en base de données.<br><br>- Le modèle de machine learning est ré-entrainé grâce aux nouvelles données utilisateurs stockée dans la base de données.<br><br>- Le modèle présent sur le serveur peut être mis à jour sans que cela impacte l’application. | - L’utilisateur clique sur un article, l’ID de l’article est transmis directement au modèle présent sur le téléphone.<br>- Pendant que l’utilisateur lit l’article, l’application charge les articles issus de la prédiction.<br><br>- Quand l’utilisateur quitte l’article, l’application envoie des données utilisateur à l’API (temps passé sur l’article, catégorie de l’article etc.…).<br><br>- L’API récupère ces données et les stocke en base de données.<br><br>- Le modèle de machine learning est ré-entrainé grâce aux nouvelles données utilisateurs stockée dans la base de données.<br>- Si le modèle présent sur l’application a besoin d’être mis à jour, il n’est pas nécessaire de mettre à jour toute l’application, MLKit se charge de mettre à jour le modèle uniquement, si les conditions le permettent (assez de batterie et téléphone connecté à un réseau WIFI). |
Conclusion
Quelque soit le modèle de machine learning que vous voulez intégrer dans votre app, il y a différentes manière de le faire et au moins une qui vous conviendra.
Vous avez le choix entre une approche plus simple via la première solution, ou une approche plus perfectionniste mais plus compliqué via la seconde solution.
Pour notre part nous avons décidé dans un premier temps d’intégrer la première solution pour deux raisons
- Pour une problématique organisationnelle. En effet, Il était plus simple que je travaille de mon côté sur le développement de l’application mobile et de ses features et que mon collègue prépare en parallèle le modèle.
- Pour faciliter l’acquisition des données utilisateur et l'entraînement du modèle.
La deuxième solution comporte des atouts très intéressants mais il est indispensable d’avoir un modèle assez mature afin de l’intégrer. En effet, l’intégration d’un modèle de machine learning en local sur un smartphone nécessite un modèle assez robuste afin de limiter les mises à jour intempestives de celui-ci. L’entraînement d’un modèle directement sur le téléphone permettrait de contourner ce problème mais à l’heure actuelle il n’existe aucune solution permettant de le faire.
Cet article concernait l’implémentation de machine learning sur mobile en tant que développeur Android. Un second article rédigé par mon binôme paraîtra bientôt et présentera en détails la partie machine learning.