Collecte de tickets de caisse : vue sur l'architecture
Suite à notre premier article sur les enjeux métiers que représentent la collecte et l’analyse de la donnée dans le secteur de la grande distribution, nous allons présenter un use case et les problématiques qui y sont associées. Nous verrons comment leur faire face en se basant sur des technologies récentes qui ont déjà fait leurs preuves chez les géants du Web : Kafka, Spark et Cassandra.
Le contexte
Un acteur de la grande distribution souhaite pouvoir remonter et traiter en temps réel des données telles que les tickets de caisse émis, les flux de marchandises entre ses fournisseurs, entrepôts et magasins, et le parcours utilisateur sur son site e-commerce.
Par exemple, il souhaite pouvoir obtenir en temps réel la performance du chiffre d'affaire de chacune des catégories de produits comparée au même jour de la semaine précédente (cf. graphe ci-dessous) de sorte à pouvoir déclencher des actions marketing avec une bonne réactivité.

Nous allons par la suite décrire une architecture qui permet le développement d'une telle fonctionnalité tout en laissant la possibilité de répondre aussi aux cas d'usages liés au suivi du stock, au flux de marchandises ou encore au parcours utilisateur sur le site e-commerce (et Drive).
Voici nos problématiques :
- Flux d’information élevé
Chaque magasin de notre enseigne de 10 000 magasins remonte en moyenne 10 tickets par minute. Dans le cadre de notre étude, nous avons travaillé avec des tickets dé-normalisés d'environ 3 kilo-octets chacun, cela crée un débit de tickets de quelques méga-octets par seconde. Les mouvements de marchandises peuvent quant à eux aussi représenter un débit de cet ordre. Le suivi des actions client sur le site e-commerce (clics, pages vues) peut en revanche remonter un flux de plusieurs dizaines de méga-octets par seconde. En première approche, nous devons traiter un flux global de l'ordre de 100 méga-octets par seconde.
- Grande quantité de données à traiter
Le point précédent amène logiquement à une seconde problématique : la quantité de données à stocker peut devenir considérable au fil du temps. Notre entrepôt de données doit ingérer plusieurs téra-octets de données par an. C’est là que les SGDB relationnels classiques tirent la langue : au delà de quelques téra-octets de données dans sa base, l’exécution de simples requêtes avec jointures, groupements et aggrégats peut devenir un calvaire. On ne parle plus du temps d’aller boire un café, mais bien de revenir le lendemain ! Outre le problème d’espace stockage nécessaire (le cout du stockage ne cesse de chuter), on doit être capable de traiter efficacement de tels volumes de données : si l’on espère être réactif à J+1, quelques heures doivent suffire à l’exécution de nos batchs permettant la correction du calcul du chiffre d’affaire de la journée en direct.
Pour répondre au besoin, notre architecture devra présenter les caractéristiques suivantes :
- Distribuée
A la louche, l’ensemble des données remontées représentera plusieurs dizaines de giga-octets de données par jour. De tels volumes de données nécessitent de la puissance de stockage et de traitement qui peut être au-delà du réalisable pour une seule machine.
- Tolérante à la panne
La chute (panne temporaire, ou perte définitive) d'un ou plusieurs nœuds ne doit pas être fatale pour le traitement des données, et ce pour deux raisons : nous souhaitons de manière indispensable la disponibilité du chiffre d’affaire en temps réel pour pouvoir prendre des décisions de manière rapide et à tout moment, et ce même si une machine est tombée. Nous ne tolérons pas l’échec de nos batchs : si un traitement dure quelques heures, disons 5 heures, la panne d’un noeud en fin de traitement ne doit pas perturber celui-ci, de sorte à pouvoir exploiter effectivement le résultat de nos batchs à J+1.
Peu importe le nœud qui tombe, le système doit continuer de tourner correctement (une baisse des performances due à la diminution des ressources au sein du cluster est en revanche inévitable, hors cloud). On doit aussi éviter tout goulot d’étranglement qui perturberait les performances de notre architecture en cas de sur-activité.
- Scalable horizontalement
Si le volume des données manipulées ou les traitements sur celles-ci deviennent trop conséquents pour un cluster, l'ajout d'un ou plusieurs nœuds au cluster doit répartir la surchage et ramener le système dans un état stable. En effet, nous travaillons aujourd’hui principalement sur nos 10000 magasins physiques. Le rachat d’un groupe concurrent, l’ouverture de magasins à l’étranger, ou bien la recrudescence de notre activité drive/e-commerce ne doit pas remettre en cause l’architecture.
- Disponible plutôt que cohérente
Le théorème CAP nous oblige à ajuster le curseur entre la disponibilité et la cohérence de notre système. Dans notre cas d’utilisation, il est préférable d’avoir nos indicateurs du chiffre d’affaire toujours disponibles, même si ils sont légèrement erronés. Un écart de quelques tickets est en effet tolérable.
Modélisation de la donnée et de son flux :
Chaque ticket de caisse est composé de méta-informations comme le numéro du magasin, l’heure d’émission, le numéro de client fidélisé (si c’est le cas) et de lignes correspondant aux articles achetés (article, quantité, prix unitaire). Un exemple permet d’illustrer un ticket de caisse au format JSON :
{
"magasin": 12345,
"timestamp": "2015-06-10 09:37:55",
"client": 7654321,
"promo emises" : [ 34567, 1233 ],
"promos utilisées" : [ ],
"articles":
[{
"produit": "gel douche",
"categorie": "hygiène du corps",
"prix_u": 2.34,
"qte": 1
},
{
"produit": "parmesan",
"categorie": "alimentaire frais",
"prix_u": 1,94,
"qte": 2
}]
}
Chaque magasin pousse les tickets dans la queue d'un système messager central afin d'être traités. Un tel système permet de découpler les application émettrices des applications réceptrices, mais aussi de prendre en charge les pics de tickets (un samedi à 11h, par exemple) en lissant la charge pour les applications de traitement. Ensuite, le ticket est d'une part stocké dans une base immuable. Parallèlement à cela, il est directement traité par un moteur de calcul pour que l'on puisse en extraire les données voulues (chiffre d'affaire par catégorie). Le résultat de ce traitement au fil de l'eau met à jour la vue offrant les performances du groupe en temps réel. Régulièrement, chaque nuit par exemple, un batch sera lancé pour recalculer le chiffre d’affaire par jour, catégorie, magasin etc.. pour corriger les écarts et prendre en compte les retours SAV.
L'illustration suivante donne une vue générale sur l'architecture :
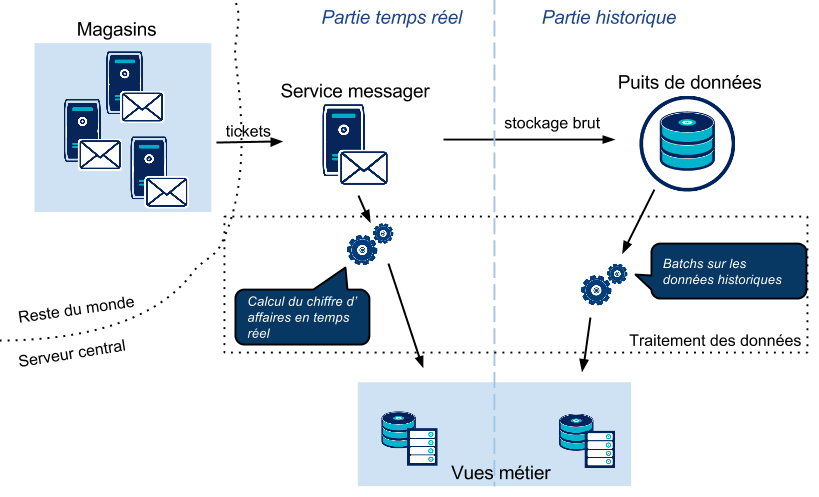
Nous allons maintenant voir avec quelles technologies nous pouvons répondre au problème.
Choix de l’entrepôt de données :
On peut penser à deux manières de stocker les tickets dans la base :
- format JSON :
On stocke le ticket tel quel dans la base et on indexe les champs pertinents, tels que la date et la catégorie, dans notre cas. On peut pour cela utiliser un système de fichiers distribué classique tel que HDFS ou bien une BDD orientée documents telle que Couchbase ou MongoDB.
- format colonnes :
Les tickets de caisse ayant une structure fixe et connue à l’avance, une base orientée colonnes comme Cassandra ou HBase est une solution viable pour notre use case.
Cassandra possède des performances remarquables. En écriture, les tuples sont d'abord ajoutés séquentiellement sur un commitlog ainsi que sur des tables en mémoire, de ce fait les écritures sont en temps constant, avec une latence qui peut être de l’ordre de quelques millisecondes (cela dépend de la topologie du cluster et du niveau de cohérence demandé). Par ailleurs, l’aspect orienté colonnes et le groupement physique des données par clé de partitionnement rend Cassandra compétitive en lecture lors du chargement d’un gros volume de données dans Spark pour effectuer des batchs analytiques. C’est donc sur Cassandra que se portera notre choix de BDD.
A noter qu'il est tout à fait possible de choisir toute autre technologie pour l'entrepôt de données, ou même d'en utiliser plusieurs (Cassandra et HDFS par exemple).
Modélisation des données dans Cassandra
En relationnel, on utiliserait plusieurs tables : l’une pour l'entête des tickets contenant les méta-informations, une autre pour chaque ligne du ticket contenant le produit, une autre qui serait le référentiel des produits etc... Dans le monde du NoSQL, il est usuel de dénormaliser les données : on privilégie la performance en temps de lecture et d'écriture plutôt que la réduction du coût du stockage. De façon simpliste, on pourrait modéliser les tickets ainsi :

La migration d’une BDD relationnelle vers Cassandra nécessite de repenser son schéma de données car la philosophie de Cassandra est celle d’un système pensé pour être distribué, et de ce fait elle est totalement différente d’un SGDB classique. On pensera en effet à modéliser ses tables en fonction des requêtes prévues plutôt qu'en fonction de la structure de la donnée. Dans notre exemple la clé composite choisie ne nous permet de faire qu'un type limité de requêtes : nous avons utilisé comme clé de partitionnement (jour, id_magasin), et comme clé de clustering id_ticket. Ainsi, les filtres possibles sur nos requêtes devront impérativement contenir un jour et un id_magasin. Par exemple, la requête : donne moi tous les tickets achetés le jour 2015-04-12 dans le magasin 345 sera une requête permise, mais pas : donne moi tous les tickets achetés de la catégorie "friandises".
Traitement de la donnée
Dans notre use case, nous avons plusieurs besoins : calculer le chiffre d’affaire du jour courant au fil de l’eau et calculer le chiffre d’affaire de chaque jour précédent pour pouvoir permettre une comparaison. La première opération nécessite du calcul temps réel, tandis que l'autre nécessite un batch à J+1.
Batchs J+1
Apache Spark est un framework de calcul distribué qui généralise MapReduce, il permet de chaîner des jobs tout en gardant les jeux de données intermédiaires en mémoire, ce qui accroît ses performances par rapport aux implémentations de MapReduce classiques. Doté d’un connecteur à Cassandra et d’un écosystème riche permettant notamment de faire du machine learning ou bien du processing temps réel sur de gros volumes de données, cette solution s’avère idéale.
Temps réel
Deux armes sortent du lot : Apache Spark Streaming et Apache Storm. Storm est un framework de type CEP (Complex Event Processing) utilisé pour traiter des évènements (logs, pages vues, alertes...), façon one at a time. Spark Streaming lui est basé sur le coeur de calcul Spark, il effectue ses jobs par micro-batchs.
Dans notre usecase, pour lequel il faut effectuer du calcul à proprement parler, plutôt que de la gestion d’évènements, Spark Streaming est naturellement plus approprié : nous recevons de la donnée numérique structurée (lignes de tickets) que nous allons regrouper et traiter de façon parallèle. On va aussi tirer profit de l'homogénéité de l’écosystème Spark : le code des batchs Spark pourra être réutilisé pour écrire ses jobs Spark Streaming sans même avoir besoin d’en modifier le coeur. C’est ici qu’est toute la puissance de l’écosytème Spark : nous manipulons des RDD (ou Data Frames, ce sont les jeux de données dans Spark) dans les deux cas, nous pourrons donc y appliquer les mêmes opérations, avec le même code. Enfin, Spark possède aussi une API SparkML, pour machine learning, ce qui allonge le champ des usecases possibles.
Flux d'entrée
Il manque maintenant une dernière pierre à l’édifice. Nous avons vu avec quoi stocker et traiter les tickets, mais il manque un système de messagerie pour permettre aux magasins d’alimenter notre duo Spark/Cassandra avec un débit élevé. Apache Kafka est un MOM (message oriented middleware) distribué, scalable, tolérant à la panne et sans single point of failure. Il peut être à la fois utilisé comme un système de messagerie publish/subscribe et comme une queue. Initialement développé par LinkedIn, Kafka connaît une montée en popularité notamment parce qu'il est et qu’il propose des performances redoutables par rapport à ses concurrents. Dans notre cas, il permettra non seulement de découpler les applications clientes (magasins) des applications de traitement, mais aussi de lisser la charge de sorte à ce que Spark Streaming et Cassandra travaillent à un régime optimal.
Requêtes complexes dans Cassandra ?
Comme nous le savons, dans Cassandra côté serveur, les jointures n'existent pas, tout comme les group by ou même les fonctions d'agrégation comme sum, max et min. En fait, nous pouvons uniquement remonter des données de manière brute, sans traitement. Nous avons la possibilité de filtrer les données (clause where), mais ce avec les contraintes dues au concept de clé composite. La mise en place d'index secondaires dans Cassandra est déconseillée car souvent mal comprise par les utilisateurs habitués des SGDB classiques : il faut donc en comprendre le concept et les manipuler avec précaution. Tout cela nous amène à une question : étant données les contraintes rencontrées avec Cassandra, nous est-il possible d'effectuer des requêtes customisées, non prévues lors du design des tables ? Exemple : Donne moi la valeur du chiffre d'affaire par catégorie pour le magasin n°420 le 12 août 2015 .
Cela est possible, en utilisant par exemple Spark. Voici un exemple de code permettant de répondre à une telle requête :
// On définit la structure des tuples que l'on manipulera dans notre DataFrame
case class Produits(categorie : String, chiffreAffaire : BigDecimal)
// On récupère les tuples de la table Cassandra
sc.cassandraTable("grande_distrib","tickets_bruts")
.select("produits")
// On filtre dès que possible au niveau de Cassandra
// de sorte à remonter uniquement le nécéssaire à Spark
.where("jour=? and id_magasin=?", "20150812", "420")
//eclateListeProduits éclate les listes de produits contenues
//dans chacun de nos tuples en plusieurs objets de la classe Produits
.flatMap(eclateListeProduits)
// On "mappe" nos tuples en utilisant la catégorie comme clé
.map(produit => (produit.categorie, produit.chiffreAffaire))
// L'étape de réduction va calculer la somme des valeurs (chiffre
// d'affaire) par clé (catégorie)
.reduceByKey(_ + _)
// On affiche le résultat pour chaque catégorie
.foreach(println)
L'exécution de ce batch prendra au minimum plusieurs secondes (ou minutes, ou heures, en fonction de la volumétrie). Dans tous les cas, un tel batch ne permet pas de répondre à des requêtes avec des temps de l'ordre de la seconde. Il faut alors par avance prévoir les réponses aux requêtes attendues en effectuant des batchs réguliers pour construire les vues ou bien en alimentant continuellement les vues grâce à Spark Streaming. On peut même combiner ces deux techniques : c'est le fondement de la lambda architecture.
Plateforme Kafka-Spark-Cassandra
Voilà donc notre architecture et les technologies associées :
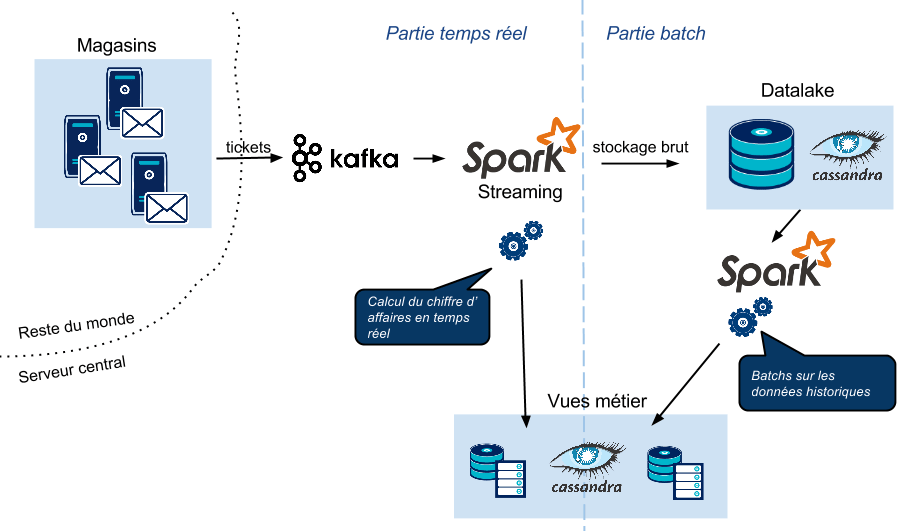
Dans les paragraphes qui suivent, nous allons expliquer le fonctionnement des interfaces entre Kafka et Spark et entre Spark et Cassandra.
De Kafka vers Spark
Les messages sont envoyés par les applications clientes (ici, nos caisses, ou magasins) à des topics auxquels s'abonnent les applications consommatrices. Les topics (dans notre cas, nous utiliserons un topic “tickets”) contiennent un nombre de partitions défini par l'utilisateur. Pour un topic donné, chaque partition est assignée à un broker Kafka (nœud messager). Augmenter le nombre de partitions d'un topic permet d'augmenter le niveau de parallelisme de l'emission et de la consommation des messages du topic. Chaque message est un couple (clé,valeur), avec la clé qui définira quelle partition du topic prendra en charge le message, et la valeur : notre message (ici le ticket).
Spark Streaming va souscrire au topic 'tickets' et récupérer sous forme de flux chaque ticket :
// Le stream est découpé en RDDs réprésentant des fenêtres temporelles de 2 secondes
val ssc = new StreamingContext(sparkConf, Seconds(2))
// On s'abonne au topic « tickets »
val topicsSet = Set("tickets")
// Liste des brokers Kafka
val kafkaParams = Map("metadata.broker.list" -> "kafka1:9092,kafka2:9092")
// On crée le stream Spark à partir du flux Kafka
val lines = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder]( ssc, kafkaParams, topicsSet)
// On peut maintenant développer le calcul du CA...
Le flux est découpé en RDDs, qui est le format de données utilisé par le coeur Spark. Les RDD sont eux aussi divisés en partitions, qui sont composées de tuples. Dans notre cas, un tuple peut représenter un ticket de caisse. Par défault, une partition de RDD est traitée par coeur CPU par « worker » Spark (nœud) : par exemple, 24 partitions, et pas une de plus pourront être traitées sur 3 nœuds workers Spark ayant 8 coeurs chacun. Le connecteur Kafka-Spark propose une interface haut niveau qui va permettre de mapper directement chaque partition des RDD à chaque partition du topic Kafka.
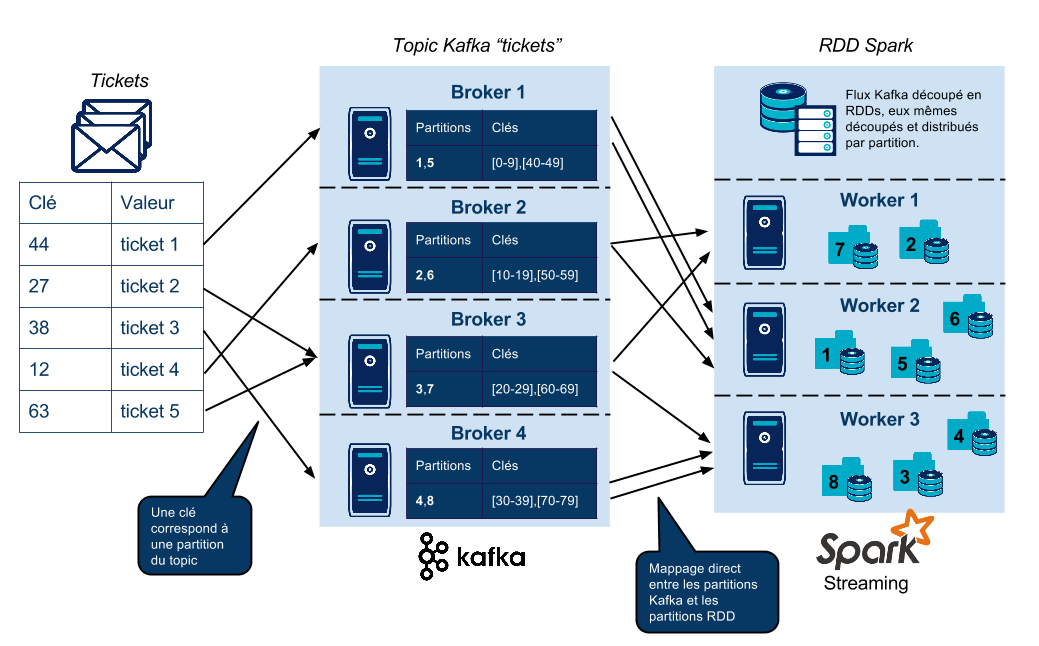
La première opération de notre micro-batch Spark est de récupérer les messages du topic Kafka. Par défaut dans Spark, un coeur CPU est alloué par tâche, or, récupérer les messages d'une partition d'un topic Kafka constitue une tâche. Ainsi, il peut être judicieux de partitionner ses topics Kafka de la façon suivante :
nb(partitions_topic_kafka) = 2 * nb(coeurs_CPU_cluster_spark)
De cette façon, on profite efficacement de nos ressources CPU de notre cluster Spark. En effet, si nb(partitions_topic_kafka) < nb(coeurs_CPU_cluster_spark), la phase de récupération des messages dans Kafka aboutira a un RDD contenant moins de partitions que le nombre de coeurs CPU disponibles. Pour profiter pleinement des ressources CPU dans les opérations suivantes, il faudra repartitionner nos RDD (à la hausse), ce qui aboutit à des shuffle (traffic réseau, à éviter car coûteux en performance). De sorte à réduire les impacts dus à des topics Kafka mal équilibrés ainsi que pour éviter les OutOfMemoryError, on préfère utiliser 2 voire 3 comme facteur de multiplication dans l'équation ci-dessus, comme le suggère la documentation.
On peut aussi tirer profit du mappage des partitions entre Kafka et Spark en adaptant notre clé dès l'émission de nos messages Kafka. Pour une opération telle que reduceByKey(), avoir ses RDD déjà partitionnés avec la bonne clé permet d'éviter des shuffle et donc gagner en performance sur ses jobs.
Une fois nos données par magasin et catégorie disponibles via notre Stream, on peut les persister dans Cassandra.
De Spark vers Cassandra
Parralèlement au traitement « live » de nos tickets, nous les stockons dans notre BDD sous forme brute en utilisant le spark-cassandra-connector. Ce projet développé par Datastax permet d'interfacer Spark facilement et de manière performante avec une base Cassandra.
// On persiste les résultats de nos calculs dans Cassandra
chiffreAffaire.saveToCassandra("grande_distrib","tickets_bruts")
En utilisant les réglages par défaut, cette opération persistera les tickets par batchs en prenant soin de grouper ensemble les tuples ayant la même clé de partition Cassandra. Plus généralement, le connector permet de tirer profit du concept de partitionnement dans Spark et dans Cassandra lors des écritures et lectures car il permet de mapper un groupe de tuples Spark à une partition Cassandra (de manière analogue au connecteur Kafka - Spark).
Conclusion
Nous venons de donner des pistes pour développer une architecture répondant à un use case qui repose sur des technologies open-source distribuées, tolérantes à la panne et scalables. Cet exemple montre le potentiel de la plateforme Kafka-Spark-Cassandra pour la réalisation d'architectures temps réel. Grâce aux fonctionnalités offertes par Spark, nous avons un bel arsenal de traitement de la donnée. De plus en plus utilisé, ce trio connaît des retours d’expérience positifs. Il faut cependant comprendre en profondeur le fonctionnement de chacune de ces technologies pour modéliser correctement ses données, éviter des erreurs et profiter pleinement des ressources de son cluster.