Circuit breaker, un pattern pour fiabiliser vos systèmes distribués (ou microservices) : partie 2
Lors de l'article précédent, nous avons vu quelques solutions possibles pour résoudre la gestion des dépendances (externe ou interne) qui peuvent (et le seront tôt ou tard) défaillantes lors de l’exécution de notre application.
Regardons d'un peu plus près le design pattern circuit breaker.
Une solution possible : le design pattern circuit breaker ?
Le circuit breaker permet de contrôler la collaboration entre différents services afin d’offrir une grande tolérance à la latence et à l'échec.
Pour cela, en fonction d’un certain nombre de critères d’erreur (timeout, nombre d’erreurs, élément dans la réponse), ce pattern permet de désactiver l’envoi de requêtes au service appelé et de renvoyer plus rapidement une réponse alternative de repli (fallback), aussi appelé graceful degradation.
Il agit comme un proxy implémentant une machine à états (Ouvert, Passant (fermé), Semi-ouvert) pour l’apprentissage de l’état du service.
On peut aussi le voir comme un feu tricolore de signalisation.
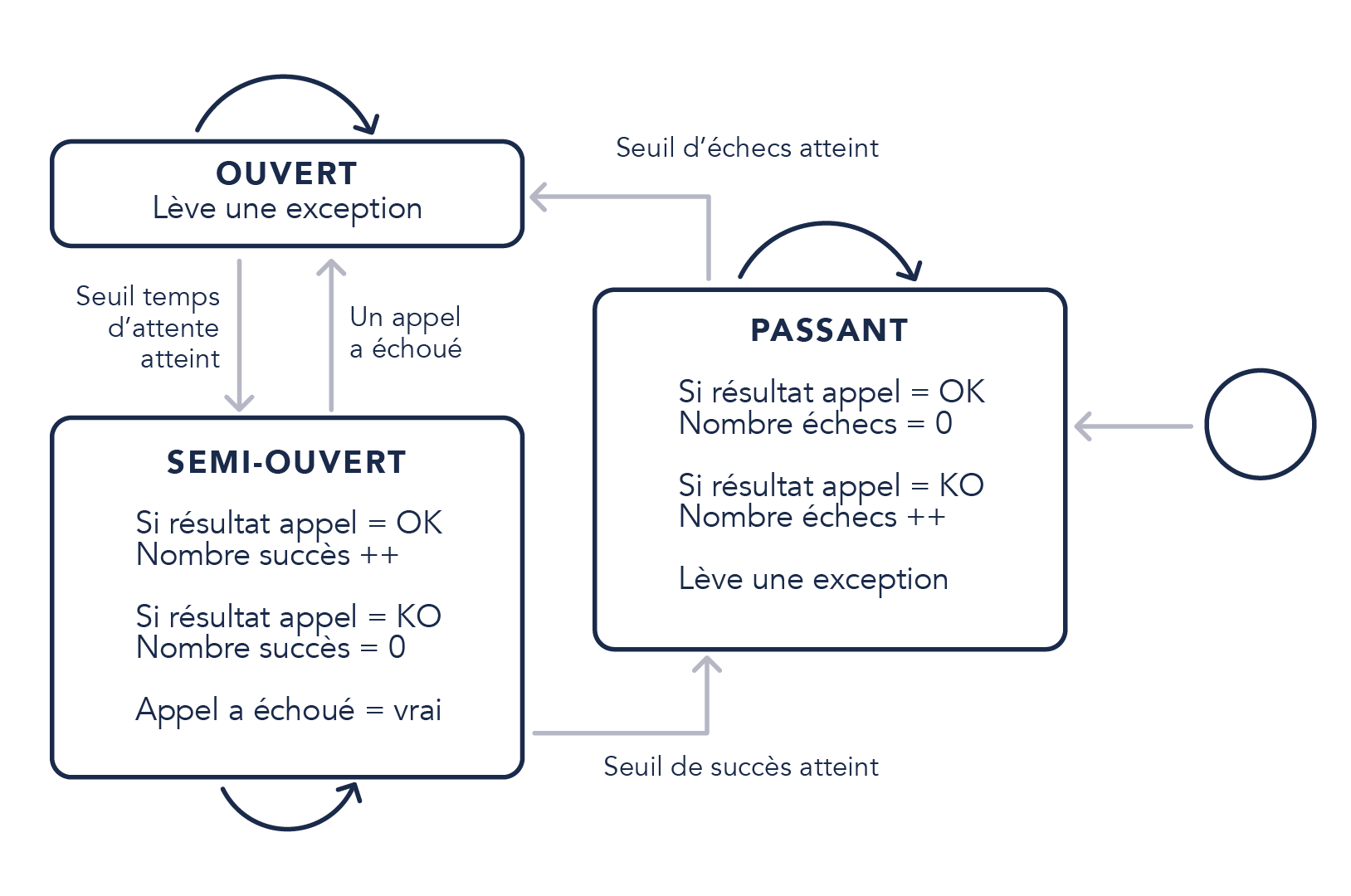
Comme nous pouvons le voir sur le schéma ci-dessus, en temps normal le circuit breaker est en mode passant.
Lorsque le nombre d’échecs successifs (ou toute autre métrique) dépasse un seuil, le circuit s’ouvre pour ne plus laisser passer de requêtes. À ce moment-là, deux mécanismes se déclenchent :
- Mise en place de la réponse alternative de repli
- Activation du processus du passage à l’état semi-ouvert (ici nous déclenchons un minuteur)
Une fois le seuil de passage à l’état semi-ouvert atteint (ici seuil du temps d’attente), le circuit breaker laisse à nouveau passer quelques requêtes et passe dans l’état passant si tout se déroule bien.
Avec un peu d’imagination, nous pouvons envisager une infinité de possibilités :
- Stocker toutes les requêtes en erreur avec le maximum de détail pour les traiter plus tard
- Avoir plusieurs stratégies de réponse alternative en fonction du type d’erreur renvoyé par le service appelé (code “HTTP 503 Service Unavailable”, mauvaise réponse…)
- Piloter le passage d’un état à l’autre à l’aide d’une API (utile par exemple lors de test)
- Avoir des seuils intelligents qui s’adaptent après une période d’apprentissage
- etc.
Toutes ces possibilités nous permettent d’implémenter d’autres patterns tels que :
- Fail Fast
- Échouer rapidement pour réduire l’impact sur l’utilisateur
- Fail Silently
- Échouer de manière transparente pour l’utilisateur (pas de stacktrace…)
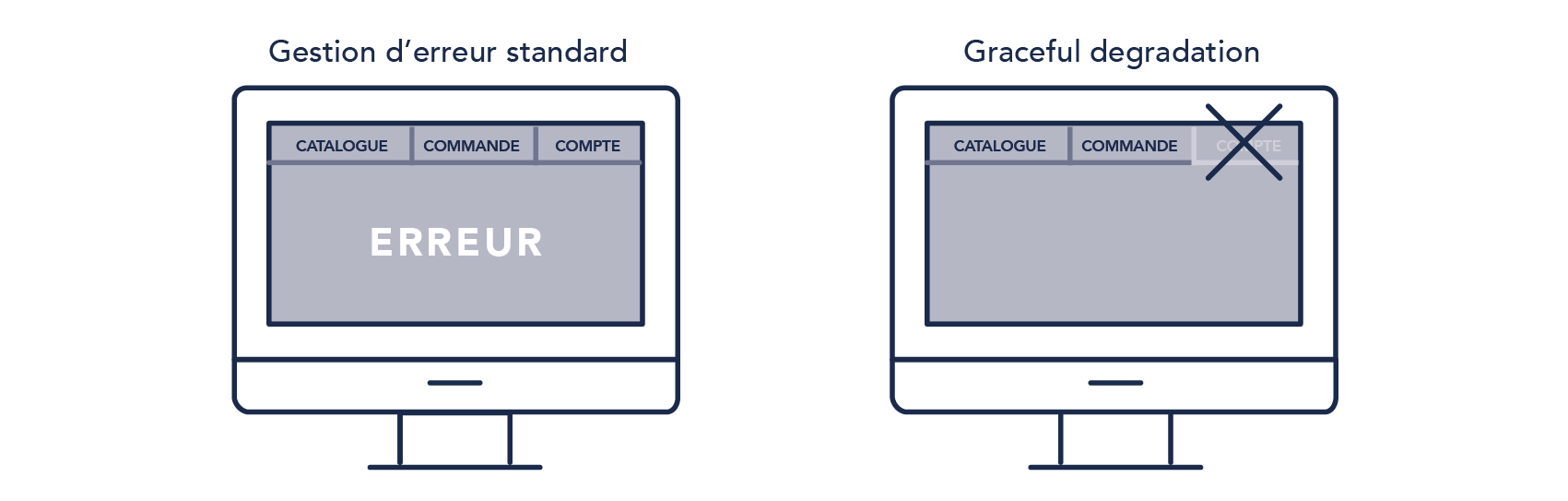
- Graceful degradation
- Adaptation automatique de l’application à une situation dégradée.
- Stop cascading failures
- Éviter l’effet domino
- Timeout
- Retry
Charge à l'architecte de faire preuve de discernement : le plus dur c'est de faire KISS, malgré tout ces beaux patterns qui nous font de l'oeil.
Et dans la vraie vie ?
Bon, c’est bien beau tout ça, mais cela reste de la théorie. Dans ce cas, passons à des cas concrets.
Mais avant d’aller plus loin il est important de rappeler qu’il faut bien connaître le fonctionnel pour implémenter et paramétrer le circuit breaker.
Cas 1 : Fonctionnalité de recherche qui ne répond plus et graceful degradation
Vous êtes aux commandes d’un site d’e-commerce de vente de modèles réduits de planeurs. Tout se passe bien jusqu’au jour où la fonctionnalité de recherche tombe en panne.
Sans circuit breaker et le passage en mode dégradé, point de salut et une course contre la montre commence pour restaurer au plus vite le service coupable. Pendant ce temps vos clients ne peuvent plus faire de recherche et s’en vont chez les concurrents.
- Affichage de la liste des produits les plus achetés avec un petit mot d’excuse et un coupon de réduction pour tenter de retenir les clients
- Ou mieux, afficher la liste des produits approuvés par un spécialiste de renommée mondiale.
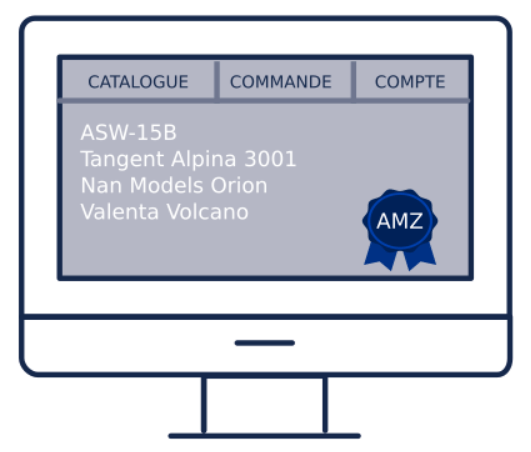
Cas 2 : Affichage du montant de sa carte de fidélité indisponible et graceful degradation
Cette fois-ci vous êtes aux commandes d’un site de gestion de carte de fidélité. Les clients peuvent :
- Voir les dernières transactions
- Voir le montant de sa carte
- Échanger des points contre des cadeaux
- etc.
Pas de chance, le service de récupération du dernier montant de la carte de fidélité tombe en panne.
Sans circuit breaker, le client n’a plus l’information et appelle le support.
Avec le circuit breaker, on affiche la dernière valeur que l’on a mise en cache (par exemple toutes les nuits ou un peu avant le pic de consultation si l’on connaît l’heure...) avec la date de la valeur. Solution qui a été trouvée avec le métier après avoir hésité entre cette solution qui demande un effort d’implémentation et une solution beaucoup plus basique (affichage d’un petit message d’erreur compréhensible par le client).
Cas 3 : Réduction de la consommation des ressources du serveur
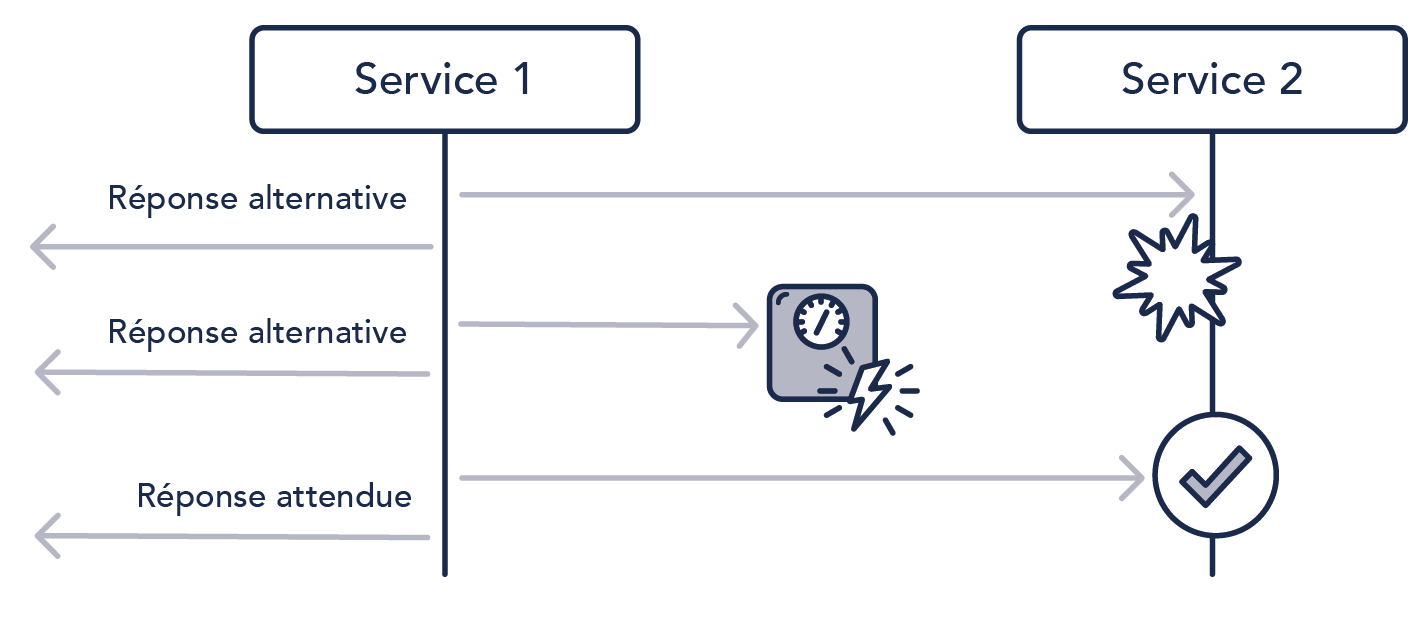
Supposons que nous ayons deux services.
Le service 1 appelle le service 2 qui fait de lourds traitements (calcul mathématique, appel de traitement PL/SQL lourd...) qui finissent tous en erreur à cause d’un bug sur la nouvelle version.
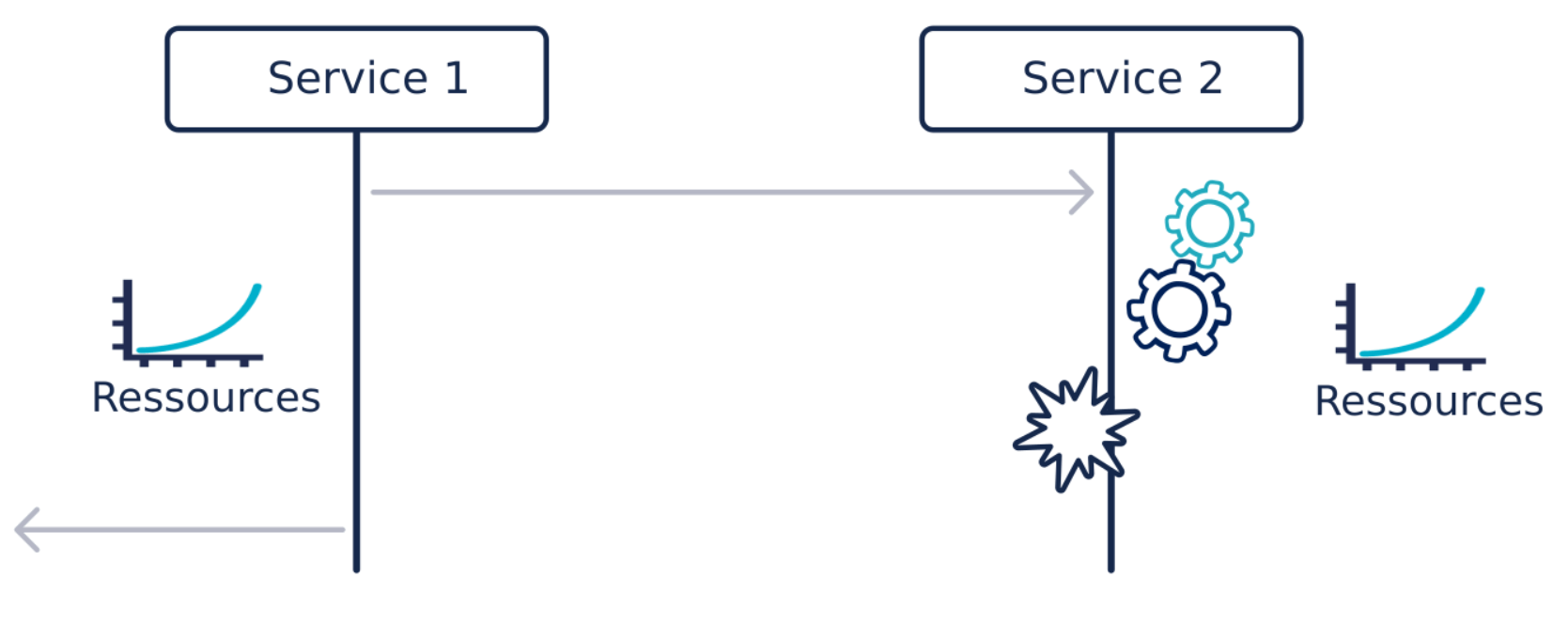
Sans circuit breaker, le service 2 va passer son temps à faire de lourds traitements inutilement et donc consommer des ressources pour rien. Le service 1 va aussi consommer plus de ressources que nécessaire, car il va devoir maintenir des connexions/threads/objets en mémoire le temps d’avoir la réponse négative du service 2.
Si, de plus, l'hébergement est dans le cloud avec un prix à la consommation et qu’on a utilisé des Auto Scaling, la facture risque d’être salée.
Avec le circuit breaker, une fois déclenché, cette surconsommation aurait été évitée en passant en mode dégradé et en désactivant le service 2.
Cas 4 : Stop cascading failures ou comment éviter l’effet domino
L’affichage d’une page de notre application fait appel à plusieurs services.
Pas de chance le service en bout de chaîne (service 4) tombe.
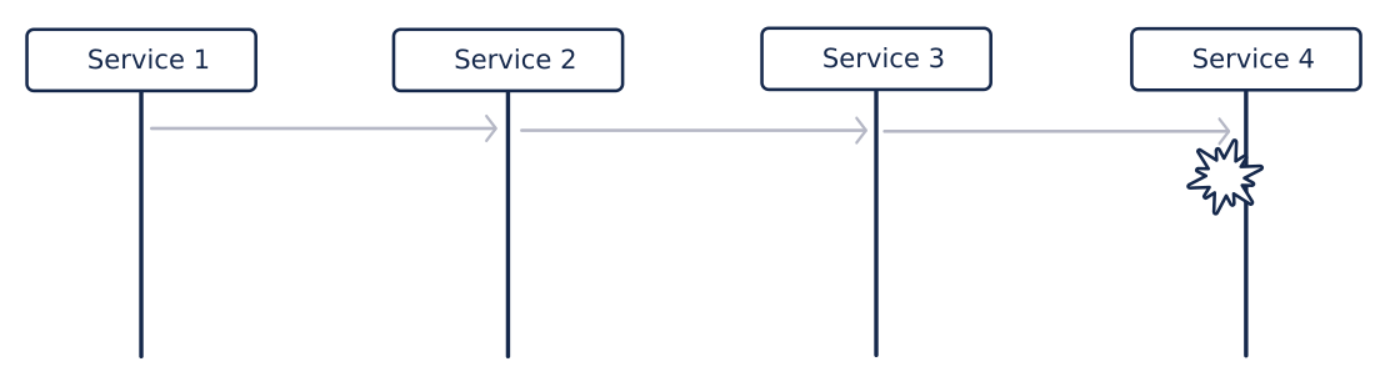
Le service 3 tombe à son tour, car dépendant des réponses du service 4. Les raisons du crash peuvent être nombreuses et diverses :
- Surconsommation de ressource
- Mauvaise gestion des réponses fausses du service 4
- Service 3 et service 4 sur le même serveur qui ne répond plus à cause du crash du service 4
- éviction du service 3 par un répartiteur de charge juste devant, car il ne répond plus correctement
- etc.
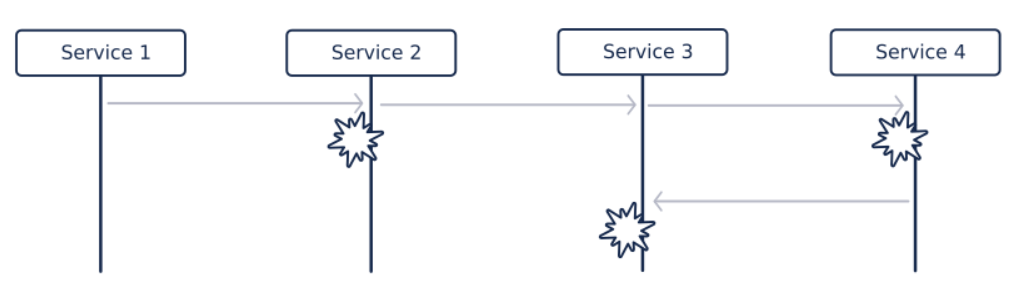
Et ainsi de suite, jusqu’à l’affichage d’une erreur incompréhensible au client.
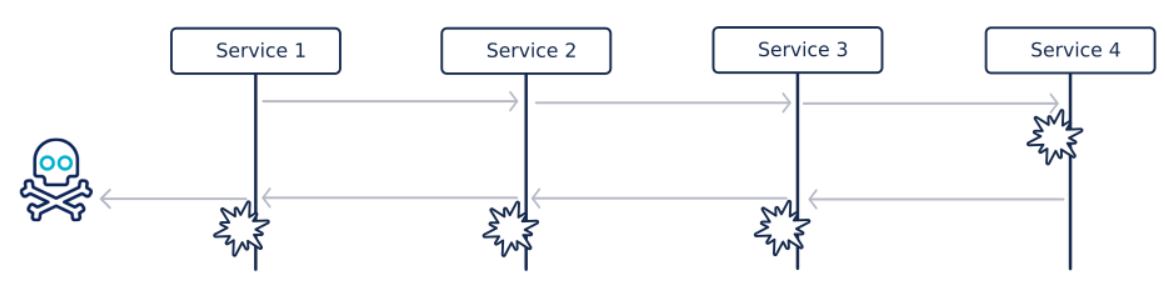
Le circuit breaker aurait évité la propagation et seul le service 4 aurait été impacté.
Dans cet exemple, nous constatons bien l’avantage par rapport aux patterns timeout et retry qui auraient été inutiles, voir auraient empiré la situation.
Un autre pattern intéressant dans ce cas est le bulkhead, voire notre livre blanc pour plus de détails.
Cas 5 : Réduire les temps de réponse et fail fast
Toujours avec la même application, une autre fonctionnalité dépend de plusieurs services.
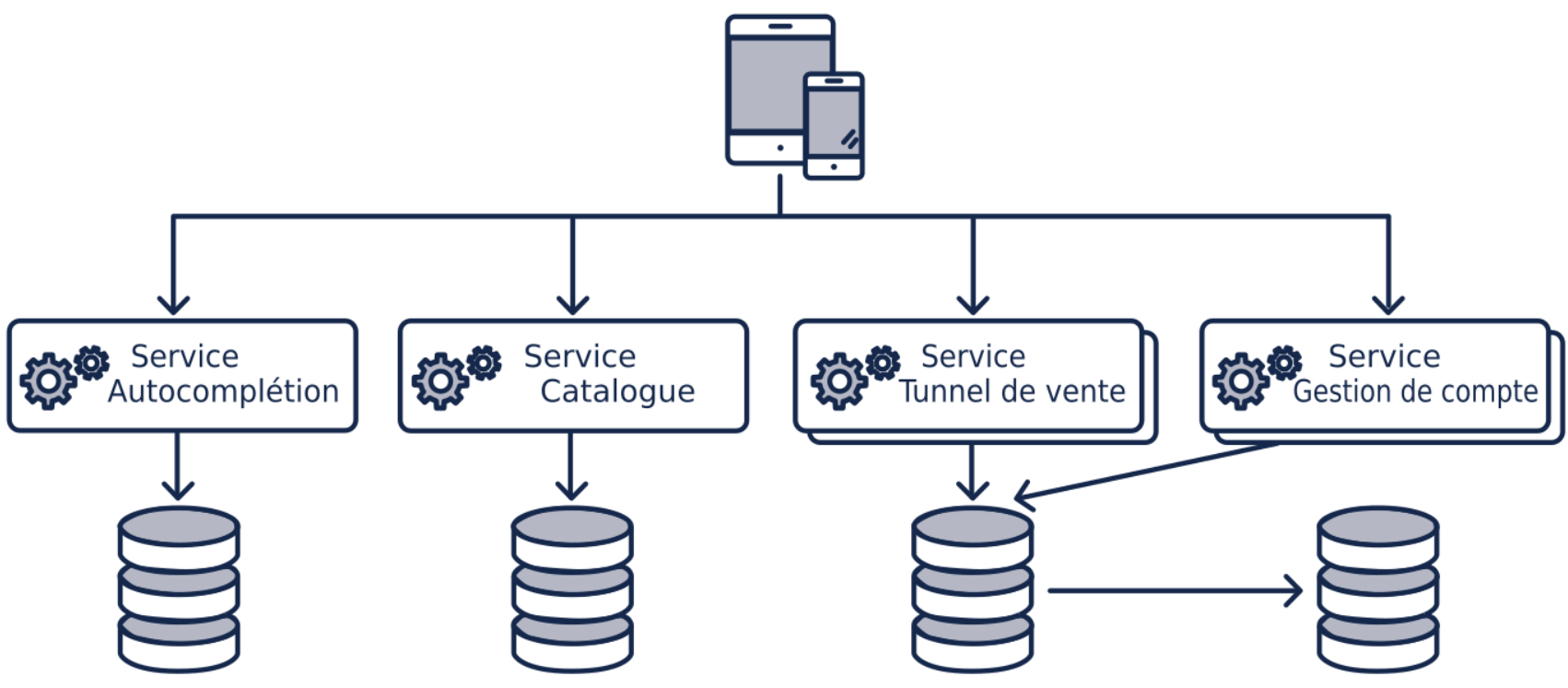
En temps normal tous les services répondent en moins de 500ms et donc notre fonctionnalité à un temps de réponse en dessous de la seconde (l’application met 500ms pour traiter tous les résultats des services).
Un problème intervient sur notre service catalogue qui ne répond plus. La réponse arrive 2s après (réglage du timeout).
Notre temps de réponse est donc maintenant égal au maximum des temps de réponse des services et du temps de traitement.
Ce qui nous donne 2s + 500ms = 2,5s
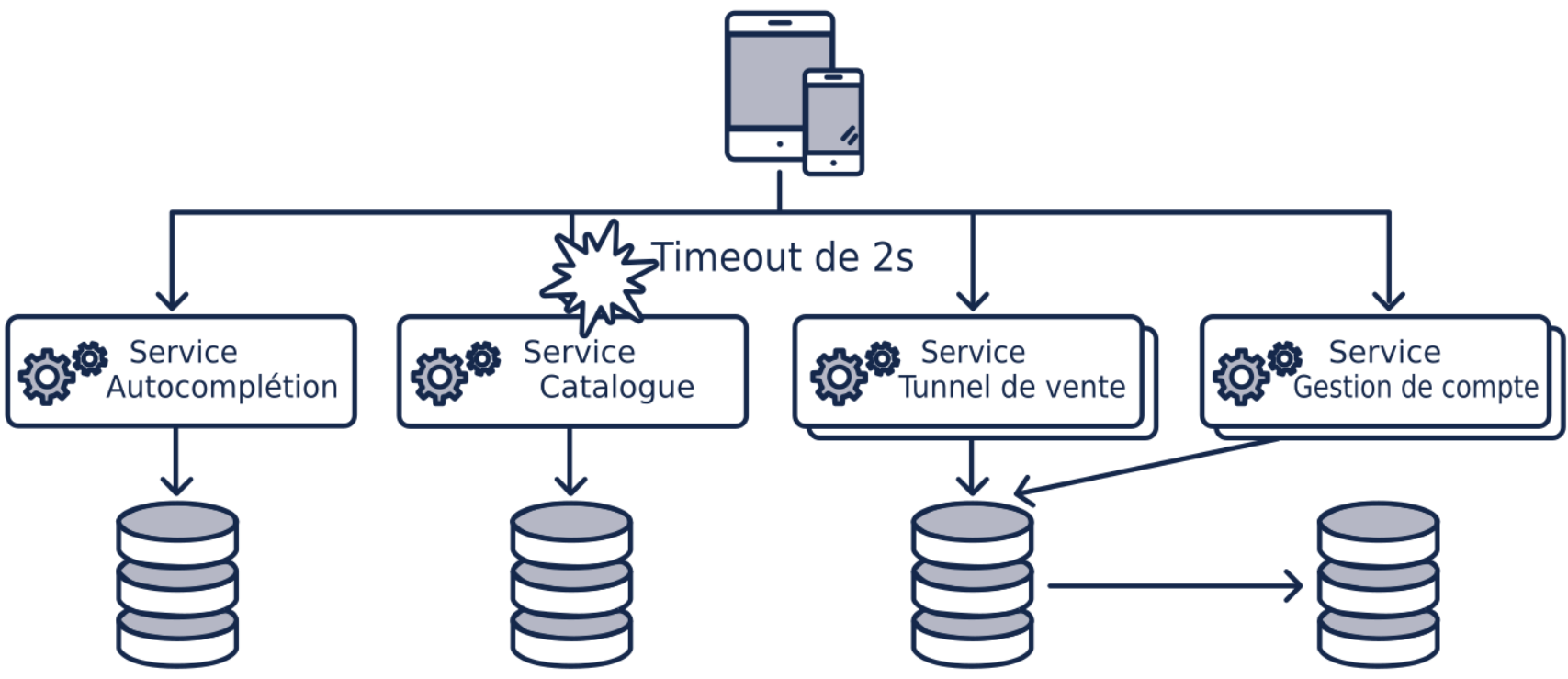
Sans circuit breaker notre fonctionnalité prendra toujours 2,5s pour répondre le temps que le service catalogue soit réparé.
Avec le circuit breaker, une fois ouvert et donc passage en mode dégradé, le temps de réponse descendra à nouveau à 1s. Ici le choix a été fait d’avoir un bon temps de réponse avec un mode dégradé, plutôt qu’un temps de réponse très mauvais avec la bonne réponse.
Conclusion
Maintenant que nous savons comment le design pattern marche et dans quelles situations il peut être utilisé, il nous reste à regarder comment le mettre en oeuvre.
Pour aller plus loin, notre nouveau livre blanc sur le sujet vient de sortir :