Chaos Engineering sur des pannes d’infrastructure
Nous sommes dans un monde qui va de plus en plus vite. La mise en production des applications se fait à une fréquence de plus en plus élevée, ce qui peut entraîner des négligences, par exemple sur l’écriture des tests, les pipelines de test et donc des erreurs sur les environnements de production.
Comment s’assurer que notre système supporte les aléas de la vie réelle (latence réseau, un serveur qui ne répond plus, etc.) ?
Le Chaos Engineering répond justement à cette problématique car il a été conçu de cette manière.
À travers cet article, nous allons voir les bases du Chaos Engineering avec sa définition et son principe, puis ses limites. Nous aborderons également une question fortement liée : comment automatiser les tests de résilience ?
Chaos Engineering, Késako ?
Définition
La définition la plus simple est :
“Chaos Engineering is the discipline of experimenting on a system in order to build confidence in the system’s capability to withstand turbulent conditions in production.” - Source https://principlesofchaos.org
Pour vulgariser un peu cette définition, le Chaos Engineering permet de faire apparaître des erreurs en simulant des événements réels (latence réseau, pertes d’instance, etc.) sur l’environnement de production, car c’est là qu’il y a des données concrètes.
Principe
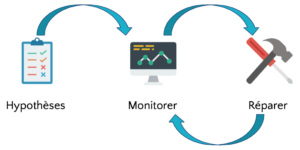
On peut retenir 3 étapes principales dans le principe de Chaos Engineering.
Etape 1 : émettre des hypothèses sur le système en se demandant “qu’est-ce qui pourrait mal tourner dans notre système”
Etape 2 : mettre en place une stack de monitoring qui va surveiller les métriques des hypothèses.
Etape 3 : lancer les expérimentations en commençant par celles qui impactent le moins le système, et réparer s’il y a des erreurs.
Aspects
Le Chaos Engineering repose sur 3 aspects :
- Organisation : le Chaos Engineering est possible si l’organisation qui l’utilise peut en supporter les contraintes (forte réactivité, haute disponibilité, SRE, etc.).
- Infrastructure : le but est de mettre en place le Chaos Engineering sur l’environnement de production, le projet doit être un minimum résilient dans le sens où il faut que le système soit distribué, pour que les expérimentations soient pertinentes.
- Technique : cela correspond aux tests de résilience. Un test de résilience va permettre de simuler des événements réels afin de vérifier le comportement du système et de voir si le service est toujours maintenu.
Limites
Les entreprises ont conscience de l’importance de la résilience dans leurs systèmes mais elles ne peuvent pas toutes se permettre de mettre en place le Chaos Engineering pour plusieurs raisons :
- Pour beaucoup d’entreprises, l’environnement de production est décorrélé du reste et ce sont des équipes dédiées qui le gèrent. Cette frontière entre les équipes de développement et équipes de production empêche la mise en place du Chaos Engineering.
- Les entreprises doivent prendre en compte les risques d’indisponibilité de services liés aux expérimentations du Chaos Engineering. Ces moments d’indisponibilité causent une perte d’argent qui peut être considérable et il faut prendre en compte le coût de l’équipe qui va devoir être très réactive sur la résolution des problèmes.
- Certaines entreprises n’ont soit pas forcément besoin de mettre en place un tel outil, soit parce que le domaine ne s’y prête pas par exemple le domaine bancaire. Néanmoins, il est toujours possible de faire ressortir des problèmes en testant en préprod ce qui est intéressant pour les domaines qui possèdent des fortes contraintes de disponibilité.
Problématique
Comme on peut le voir, le Chaos Engineering est un regroupement de plusieurs aspects et certains ne peuvent pas être traités seuls. L’un des aspects, l’aspect technique, peut être un bon début pour mettre en place ce concept.
Aujourd’hui, nous n’avons pas au quotidien les moyens d’agir sur la totalité des aspects du Chaos Engineering. Cependant, l’aspect technique reste abordable et peut être mis en place sur nos projets, comme un premier pas dans la mise en place du Chaos Engineering. La problématique de comment tester la résilience d’une infrastructure de façon automatique se pose donc, indépendamment des autres aspects.
Afin de répondre à cette nouvelle problématique, nous avons décidé d’implémenter une librairie qui va permettre d’écrire des tests de résilience de manière simple et intuitive, de la même manière qu’on aurait écrit un test unitaire. A ma connaissance, une telle librairie n’existe pas, c’est pourquoi, nous avons voulu faire un PoC avec de fortes hypothèses en utilisant Docker pour l’infrastructure car il permet de simuler toute une infrastructure (noeuds, réseau, etc.).
Librairie
Choix techniques
L’implémentation de la librairie a été fait avec le langage Python. Les raisons qui nous ont poussé à utiliser la plateforme Docker sont :
- La simulation d’une infrastructure : en utilisant un Docker-Compose on peut facilement simuler toute une infrastructure sur une seule machine et facile de mettre en place sur un poste,
- Les use case : pour valider la librairie, nous avons décidé d’utiliser 2 projets (dont un poc Kafka détaillé ci-dessous) dont les infrastructures tournaient sous Docker.
Implémentation
Tout d’abord, nous avons commencé par implémenter des méthodes qui vont permettre d’impacter directement les conteneurs. Pour cela nous avons utilisé un SDK Docker pour Python, https://docker-py.readthedocs.io/en/stable/#. Il permet de récupérer et d’altérer le comportement des conteneurs. 3 méthodes ont été implémentées :
- Kill : permet de Kill ou d’envoyer un signal au conteneur. Par défaut, le signal qui est envoyé est SIGKILL, ça permet de simuler l’arrêt anormal d’une application,
- Stop : permet d’arrêter un conteneur, cette commande a le même comportement que la commande “docker stop”, pour simuler par exemple une application arrêtée humainement par inadvertance,
- Start : permet d’allumer un conteneur, possède le même comportement que “docker start” à l’exception des options.
Ensuite, nous avons implémenté des méthodes qui vont impacter le réseau des conteneurs. Les conteneurs Docker sont sous un OS Linux, et il existe une commande qui permet de modifier les options réseaux, tc (Traffic Control). Nous utilisons “docker exec” pour accéder au contexte du conteneur.
Un exemple d’utilisation : “tc qdisc replace dev eth0 root netem delay 200ms”
- qdisc : permet de modifier le scheduler (Le scheduler va gérer les paquets réseaux, par défaut le scheduler est un FIFO)
- replace : remplace une règle/option (Correspond pour l’exemple à ajouter du délais)
- dev eth0 : application de la règle sur le device eth0 (Correspond simplement au réseau du conteneur Docker)
- root : avoir les droits root
- netem : utilise un émulateur de réseaux pour émuler les propriétés d’un WAN
- delay : latence réseaux
- 200ms : la valeur de la latence réseaux
Il est important aussi de noter que nous avons dû donner l’autorisation NET_ADMIN au conteneur surf lequel nous voulions simuler des problèmes réseaux. Sans cette autorisation, la simulation aurait été caduque En utilisant cette commande, on a pu implémenter 3 méthodes :
- Delay : simule des latences réseaux (plus la valeur du délais est élevée, plus il y a des chances de pertes de paquets),
- Corrupt : simule des données corrompues,
- Loss : simule des pertes de paquets.
La librairie a été implémentée de manière à fournir une API avec une abstraction qui soit suffisamment élevée pour permettre de l’utiliser dans le cadre de tests au format Behaviour Driven Development. Le BDD, https://blog.octo.com/le-bdd/, permet d’écrire des tests complexes dans un langage proche de la langue orale, compréhensibles par tous.
Exemple
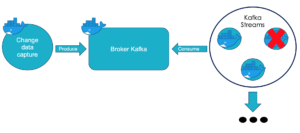
Il y a 2 points importants pour comprendre cet exemple :
- Change Data Capture : est un producer, c’est-à-dire qu’il produit de la donnée et l’envoie dans un broker Kafka.
- Kafka Streams : est un consumer, c’est-à-dire qu’il consomme la donnée présente dans le broker Kafka.
Dans cet exemple, nous allons tout d'abord utiliser 1 conteneur de Kafka Streams afin de faire monter le lag, puis de scaler le nombre de conteneurs à 3, dont un que l'on va kill. La métrique qui va être suivie pour monitorer le fonctionnement du use case illustré ci-dessus est le lag. Le lag est la différence de temps entre le moment où la donnée est produite et le moment où elle est consommée. C'est une métrique très importante pour du streaming. Nous utilisons Prometheus pour la mesure et Grafana qui permet d’illustrer l’évolution du lag, ces outils sont mis en place dans des conteneurs.
Si on prend le scénario suivant :
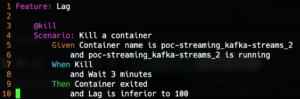
Dans ce scénario, on va vérifier que le conteneur existe et qu’il est bien en marche. Ensuite on exécute la commande Kill, qui va détruire le conteneur en question et attendre 3 minutes. Et en résultat, on vérifie que le conteneur s’est bien arrêté et que le lag est toujours inférieur à 100.
La librairie fournit le @Given et le @When mais pas le @Then, ce qui oblige à implémenter l’assertion que le lag est inférieur à 100.
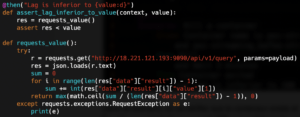
Dans le code ci-dessus, on lance une requête à Prometheus pour récupérer les données liées au lag. Lorsqu’on lance le scénario, on obtient le résultat suivant :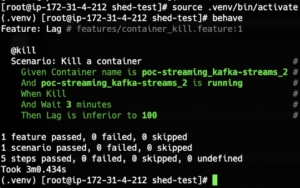
Et sur Grafana on observe la courbe du lag :
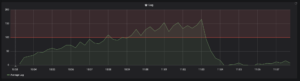
Pour conclure cet exemple, on peut voir que l'écriture d'un scénario est facile et compréhensible par tout le monde. On a bien démontré la faisabilité d'un outil qui permet d'écrire des tests de résilience.
Next Steps
Pour aller plus loin
Ce qui peut être ajouté à la librairie serait des commandes qui permettent :
- de simuler des problèmes d’écriture et de lecture sur le disque,
- de modifier le nom d’un conteneur,
- de modifier ses droits.
Ces ajouts permettraient de constater la réaction du système sur ces changements qui peuvent être causés par inadvertance.
Industrialisation de la librairie
Pour utiliser cette librairie en tant que produit et non plus un simple PoC, il est nécessaire de la rendre compatible avec différentes plateformes cloud, ce qui permettra de l’utiliser quel que soit l’environnement cible.
Il est intéressant de noter que cette librairie pourrait servir à faire un premier pas dans la mise en place du Chaos Engineering, en l’intégrant par exemple dans une CI et à une stack de monitoring. Comparée au Chaos Engineering, la librairie ne pourra pas directement être mise en place dans l’environnement de production mais plutôt dans des environnements qui s’en rapprochent (Pre-prod).
Pour conclure, un tel outil peut être intéressant à intégrer dans vos SI, car il permet d’écrire des tests de résilience qui soient facilement compréhensibles. Le fait de l’intégrer dans la CI avant la mise en production permet de faire un premier pas sans engranger les coûts associés à la mise en place d’une équipe dédiée.