C'est quoi l'architecture de SI ? L'enjeu des frontières entre systèmes
Les nouveaux·elles arrivant·e·s à OCTO me demandent régulièrement comment se mettre à l’architecture de SI.
Une des bases est la compréhension des enjeux liés aux frontières entre systèmes. Il s’agit d’une des questions fondamentales pour construire des systèmes d’information (SI) gouvernables et pérennes.
Elle permet de comprendre les enjeux qui se posent aux architectes SI.
En allant du plus simple au plus complexe, je vais commencer par parler du problème pour un système, puis passer à deux pour terminer à l’échelle du SI.
Qu’est ce qu’une frontière ?
Nous définirons la frontière d’un système (une application, une sous-partie d’un SI…) comme l’ensemble des éléments à connaître et/ou utiliser pour pouvoir le manipuler. Cela couvre les interfaces quel que soit leur type (programmatique, graphique…) et la documentation, voire le fonctionnement interne, si la compréhension de celui-ci est nécessaire pour une bonne utilisation.
Toute la partie du système qui est à l’intérieur de la frontière est une boite noire : les personnes qui utilisent le système n’ont pas à s’en préoccuper.
Si l’utilisation d’un logiciel passe par des interactions humaines (faire une demande d’accès, avoir besoin d’aide car la documentation n’est pas suffisante), elle feront partie de la frontière.
Cette question de la frontière se pose dès qu’un logiciel va communiquer avec un autre, par exemple :
- quand vous développez un système qui expose ses frontières à d’autres ;
- quand vous cherchez la bonne manière d’utiliser un système ;
- quand vous avez à choisir un outil ;
- quand vous avez à définir une stratégie d’exposition pour un logiciel ou un SI.
Si le problème se pose principalement lorsque vous définissez vos propres frontières et donc créez vos propres logiciels, la majorité des exemples de l’article portent sur des outils "sur l’étagère" pour être plus faciles à comprendre.
Qu’est ce qu’une bonne frontière ?
Une bonne frontière répond à trois caractéristiques :
- riche : c’est-à-dire exposant des fonctionnalités les plus avancées possibles ;
- cohérente : c’est-à-dire que les différents éléments de cette frontière ont une logique uniforme entre eux, en particulier un vocabulaire commun, ce qui rend le système facile à comprendre ;
- minimale : c’est-à-dire exposant ces fonctionnalités à travers un nombre minimum de points d’accroche, ce qui la rend plus facile à utiliser et à tester ou à simuler.
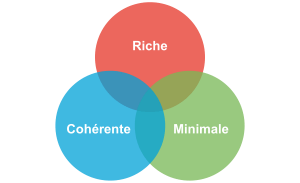
Ces critères ont tendance à s’exclure les uns des autres : par exemple une frontière riche et minimale risque de prendre des raccourcis et d’être incohérente.
L’objectif est de parvenir à avoir le bon équilibre entre les trois, de façon à bénéficier d’une frontière adaptée à votre cas d’utilisation donné.
C’est par exemple le cas des langages ou des protocoles populaires comme SQL ou HTTP : ils correspondent à un juste équilibre entre les trois.
Il n’y a pas de métrique objective permettant de détecter si une frontière est bonne, c’est l’expérience qui permet de le sentir.
Attention : fuite d’abstraction
La frontière fournit une abstraction d’un système : elle dit en gros "ne vous préoccupez pas de toute la fonctionnalité de mon fonctionnement interne, voilà comment vous devez communiquer avec moi et c’est tout ce que vous avez besoin de savoir".
Par exemple, pour utiliser une base de donnée SQL, vous n’avez pas besoin de savoir comment fonctionne son moteur de requêtage, sa manière de stocker les données ou d’utiliser la mémoire. En théorie, vous devez uniquement vous préoccuper d’écrire du SQL selon la norme, de bien structurer et de mettre des index aux bons endroits.
Seulement, les abstractions ont tendance à fuir, c’est-à-dire qu’il est souvent nécessaire de comprendre le fonctionnement interne d’un système pour bien l’utiliser.
La frontière n’est pas donc pas celle qu’on croit.
Quand les systèmes sont bien faits, la fuite est "naturelle", c’est-à-dire qu’elle se produit à des endroits où l’on s’attend à ce qu’elle se produise.
Ainsi, dans une base de donnée persistante, quand la volumétrie devient très importante, il est normal de devoir comprendre comment la base stocke ses informations, afin de pouvoir configurer votre système d’exploitation ou de choisir le système de stockage le mieux adapté comme le type de disque de dur. En fonction de votre usage d’un outil, la frontière peut donc s’étendre.
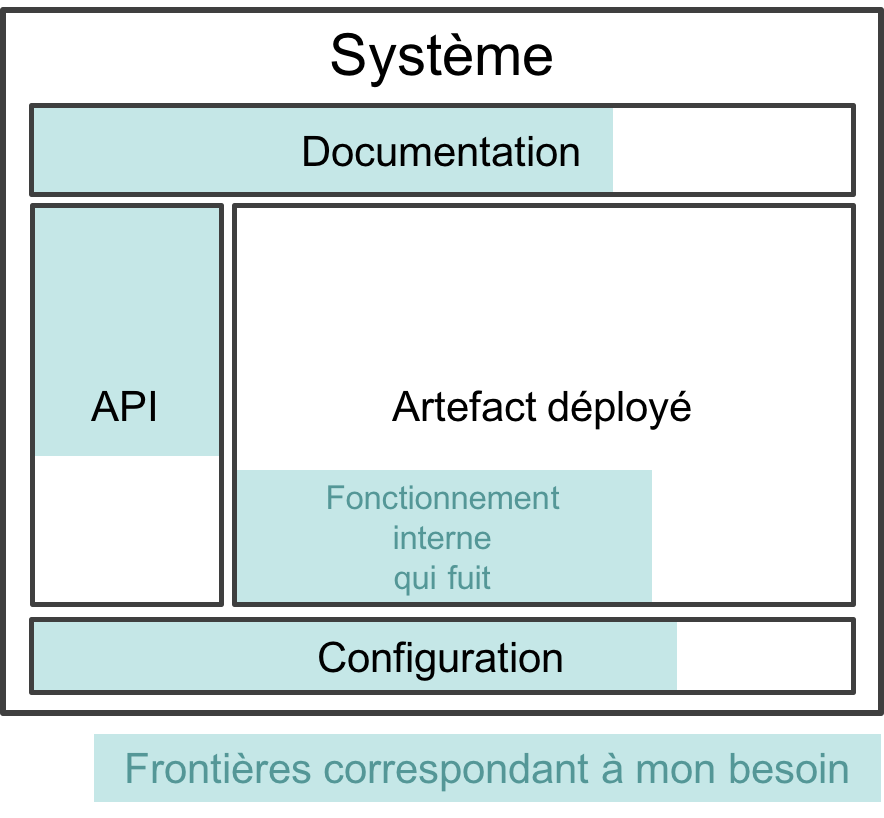
Quand les systèmes sont moins bien conçus ou qu’on tente de détourner leur usage, la fuite peut arriver beaucoup plus tôt, et notamment alors qu’on ne l’attendait pas. C’est par exemple le cas de certains ORM qui vont tout faire pour masquer le SQL généré afin de fournir une API très "objet", et qui vous contraindrons à des contorsions sans fin, par exemple en utilisant des fonctionnalités non documentées, quand on a besoin d’influer sur une requête en particulier.
Un outil peut donc avoir plusieurs frontières en fonction des usages qu’on en fait. Ce qui veut aussi dire qu’un outil d’apparence plus simple qu’un autre peut en réalité être plus compliqué et difficile à utiliser.
Frontières connues et abstractions qui mentent
Quand un certain type de frontière devient connue par les développeur·euse·s, s’appuyer dessus a de la valeur car cela permet de capitaliser sur ce qu’il·elle·s savent déjà. Par exemple, exposer une base de donnée sous forme de SQL permet de pouvoir l’utiliser rapidement en s’appuyant sur ses connaissances SQL plutôt que d’apprendre un nouveau langage.
C’est une question fondamentale lorsque vous créez un nouveau système : mes besoins sont-ils suffisamment différents des solutions existantes pour justifier de les exposer différemment, ou vaut-il mieux utiliser ou étendre une frontière déjà connue, au risque de se brider en rendant plus difficile à utiliser les fonctionnalités spécifiques de ce nouveau système ?
C’est le même type de discussion qui se produit lorsqu’on étudie le choix d’un progiciel, dans une optique build vs. buy : les fonctionnalités du progiciel me permettront-elles de répondre à l’ensemble de mes besoins, ou vaut-il mieux partir sur un développement spécifique ?
Une abstraction est censée masquer un fonctionnement complexe en en donnant une vision simplifiée tout en restant fidèle à la réalité. Dans le cas idéal, lorsque vous avez un besoin qui ne correspond pas à la frontière la plus simple, l’outil vous fournit un autre niveau, plus avancé, mais qui ne remet pas en cause l’existant. C’est le cas par exemple des hints qui existent en SQL pour préciser les index à utiliser ou les appels systèmes Linux pour aiguiller le système de stockage : il s’agit d’une spécialisation des comportements par défaut.
Le problème est quand une abstraction ment, c’est-à-dire que le modèle qu’elle expose ne correspond pas à la réalité sous-jacente. Quand ce type d’abstraction se met à fuir, vous ne retrouvez pas alors avec quelque chose de plus complexe, mais avec quelque chose de complètement différent. Vous devez alors jongler avec deux modèles mentaux : celui qui est mis en avant par l’abstraction et le « vrai » qui correspond à l’implémentation.
Le cas des bases NoSQL qui exposent une surcouche SQL est un exemple connu de ce biais. Souvent cette couche n’expose qu’une sous-partie limitée du SQL, et les développeur·euse·s doivent donc apprendre ou découvrir quelles requêtes SQL fonctionnent et quelles requêtes ne fonctionnent pas, et avec quelles performances. Ensuite cette surcouche ne permet souvent pas d’utiliser toute les fonctionnalités promises par l’outil. Suivant les cas, il faut donc utiliser du SQL, mais pas tout le SQL, ou le langage natif d’interrogation de la base.
En anglais ce problème porte le nom d’impedance mismatch, c’est-à-dire d’inadaptation d’impédance, ce qui signifie que le lien entre le fonctionnement interne et l’abstraction externe n’est pas efficace.
Réutiliser des frontières connues peut donc être intéressant, mais peut donner lieu à des mauvaises surprises.
Assembler deux systèmes
Combiner deux systèmes ou bâtir un système sur un autre d’un type différent est une opération au résultat complexe : vais-je obtenir un système avec les avantages des deux sans aucun des inconvénients, ou au contraire les inconvénients de l’un vont-ils annuler les avantages de l’autre ? Et au final, serai-je en mesure d’exposer le résultat sous forme d’une frontière riche, cohérente et minimale ?
Par exemple : bâtir un système synchrone sur un système asynchrone. L’approche naïve est simple à mettre en œuvre : simuler un appel synchrone en appelant régulièrement le système asynchrone jusqu’à avoir une réponse. Mais comment faire pour pouvoir interrompre le traitement en cours de route, ce qu’on s’attend à pouvoir faire dans le cas d’un « vrai » système synchrone ? Faut-il dans ce cas demander une annulation ? Mais que se passe-t-il si le traitement s’est terminé pendant ce temps ? …
On atteint alors la limite de la solution naïve.
Améliorer ou hybrider ?
Quand une combinaison de deux systèmes fonctionne bien, elle peut avoir deux résultats :
- un sur-ensemble d’un des deux systèmes, c’est-à-dire quelque chose qui répond grosso modo aux même usages que le premier mais avec des fonctionnalités en plus ;
- un système suffisamment différent pour qu’il ne soit pas compatible avec les systèmes originaux.
Prenons le cas d’un outil magique permettant de distribuer des traitements.
Si on l’ajoute à un système de calcul sans stockage de données, il peut permettre d’exécuter un nombre plus important de traitements en parallèle sans supprimer de cas d’usage. Du point de vue de la frontière, le résultat est donc mieux que l’ancien sans effet secondaire : il s’agit d’une amélioration.
Si on l’ajoute à un système de base de données, il peut permettre d’augmenter la vitesse de traitement en sacrifiant la transactionnalité et/ou la cohérence des données. Le nouvel outil n’a donc plus les mêmes usages que l’ancien : il s’agit d’un hybride.
Ainsi quand un éditeur logiciel vous promet un produit miracle qui fait quelque chose que personne d’autre ne propose, la première chose à faire et de vérifier s’il s’agit d’un cas d’amélioration ou d’un cas d’hybridation. Et s’il s’agit d’une hybridation, répond-il bien à votre besoin ou allez-vous atterrir dans un cas limite qui aura l’air de fonctionner mais pas tout à fait ?
Agrandir la frontière
La combinaison de deux systèmes conduit souvent à déléguer certaines choses à l’extérieur, car le système résultant ne saura plus prendre seul certaines décisions.
Par exemple, dans un système distribué, garantir l’unicité d’un message est très compliqué, car cela nécessite une forme de centralisation. Il est donc souvent plus simple que le système appelant s’en occupe car il dispose d’informations supplémentaires qui lui permettent de le faire plus facilement.
Cela risque de créer des incohérences dans la frontière, et des fuites d’abstractions. Il s’agit d’un arbitrage à faire : vaut-il mieux quelque chose de plus riche mais de plus difficile à comprendre, voire de plus difficile à opérer ?
Au final, assembler des systèmes de type différent peut donc être risqué. Pour maîtriser le résultat, le mieux est de choisir des systèmes avec des frontières cohérentes.

Parfois, pour obtenir un résultat intéressant en combinant deux systèmes, la meilleure approche est de commencer par décaper la frontière d’un des deux afin de reconstruire une autre frontière plus propice.
Passer à l’échelle : les frontières dans un SI
Dans un SI, il y a de nombreuses briques logicielles, chacune avec ses besoins propres. De nombreuses fonctionnalités nécessitent de s’appuyer sur d’autres briques.
Il s’agit donc du problème d’assemblage mais à grande échelle. Plus il y a de frontières et plus elles sont communes à de nombreuses applications, plus le problème est compliqué, c’est le couplage.
Il faut donc maîtriser les frontières qui sont exposées. Cela ne signifie pas interdire les échanges entre systèmes, mais faire des choix en fonction de votre contexte.
En plus du nombre de frontières, il faut aussi piloter le nombre de types de frontières.
Par exemple, si vous avez cinq types de bases de données qui ont des garanties différentes, vous aurez peut-être cinq types de services avec des SLAs différents : certains seront transactionnels, certains auront des risques d’incohérences… Et les services qui auront besoin de composer ces services ne sauront pas faire : que se passe-t-il quand j’ai une moitié de donnée pas cohérente mais synchrone et une autre moitié cohérente mais asynchrone ? À l’inverse, si tout le monde expose un même type de frontière, comme des services REST, combiner les services et les SLAs est très simple. Le problème est d’autant plus compliqué que ceux·celles qui paient le prix de la complexité ne sont pas ceux·celles qui développent le système qui expose une frontière, mais ceux qui l’utilisent.
Dans ce cas, l’approche est plus directe : il faut limiter les types de frontières, et donc les types d’outils et/ou de technologies. Comme vu plus haut, cela veut dire qu’en contrepartie certaines choses seront plus difficiles, voire impossibles, mais c’est le prix à payer pour limiter la complexité de votre SI. Cela ne veut pas dire "un seul type d’outil", mais essayer d’en avoir le minimum viable pour vous permettre de répondre à vos besoins.
Pour cela, il faut prendre les choses sous l’angle du·de la client·e : définir quels sont ses besoins et déterminer la frontière qui y répond le mieux.
Quelques lectures
- Designing Data-Intensive Applications : un livre de fond sur les différents types d’outils de base de données en s’intéressant tout particulièrement aux cas d’usages et aux limites de chacun
- End to end arguments in system design : un article fondateur sur la question de la frontière de systèmes informatiques.
- Systemantics : un livre sur le design de système, très intéressant mais un peu déprimant
- Reverse Design: Half-Life : c’est dans ce livre que j’ai trouvé l’approche sur l’hybridation de systèmes