Cache me if you can - 2
Introduction - scope of the article
This series of articles deals with caching in the context of HTTP. When properly done, caching can increase the performance of your application by an order of magnitude. On the contrary, when overlooked or completely ignored, it can lead to some very unwanted side effects caused by misbehaving proxy servers that, in the absence of clear caching instructions, decide to cache anyway and serve stale resources.
In the first part of this series, we argued that caching is the most effective way to increase performance, when measured by the page load time. In this second part, it is time to shift our focus to the mechanisms at our disposal. To put it in another way: how does HTTP caching actually work ?
To answer this question, we decided to consider the case of an empty cache that starts progressively caching and serving resources. As it gradually receives incoming HTTP requests, our cache will start behaving accordingly. Serving the resource from the cache when a fresh copy is available, varying over multiple representations, making a conditional request... This way, we can introduce each concept progressively as we need it.
At first, our empty cache will have no choice but to forward requests to the origin server. This will allow us to understand how origin servers instruct our cache on what to do with the resource, such as if it is allowed to store it, and for how long. For this, we will examine each Cache-Control directive and clarify some of them that have been known to have conflictual meanings.
Second, we will look at what happens when our cache receives a request for a resource it already knows. How does our cache decide if it can re-use a previously stored response ? How does it map a given HTTP request to a particular resource ? To answer these, we will learn about representation variations with the Vary header.
This article is going to focus on knowledge that’s the most valuable from a web developer’s perspective. Therefore, conditional requests are only discussed briefly and will be the focus of another article.
Without further ado, let us start with an overview of what we will be exploring.
The HTTP caching decision tree
Conceptually, a cache system always involve at least three participants. With HTTP, these participants are the client, the server, and the caching proxy.
However, when learning about HTTP caching, we strongly encourage you not to think of the client as your typical web browser because these days, they all ship with their own HTTP caching layer. It makes it difficult to clearly separate the browser from the cache. For this reason, we invite you to think of the client as a headless command line program such as cURL or any application without an embedded HTTP cache.
All precautions aside, let us now deep dive into the subject by taking a look at the following picture: the HTTP caching decision tree.
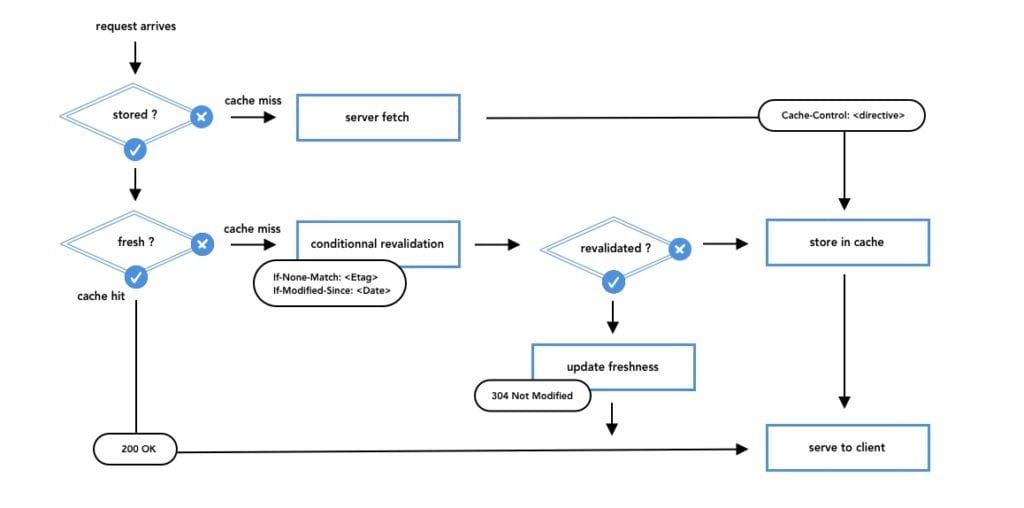
This picture illustrates all the possible paths a request can take every time a client asks for a resource to an origin server behind a caching system. A careful examination of this illustration reveals that there are only four possible outcomes.
Clearly separating these outcomes in our minds is actually very convenient, seeing as each important caching concept (cache instructions, representation matching, conditional requests and resource aging) maps to each one of them.
Let us describe succinctly each one by introducing two important terms relating to the HTTP caching terminology: cache hits and cache misses.
Hits and misses
The first possible outcome is when the cache finds a matching resource, and is allowed to serve it, which, in the caching world, are indeed two distinct things. This outcome is what we commonly call a cache hit, and is the reason why we use caches in the first place.
When a cache hit happens, it completely offloads the origin server and the latency is dramatically reduced. In fact, when the cache hit happens in the browser’s HTTP cache latency is null and the requested resource is instantly available.
Unfortunately, cache hits account only one of the four possible outcomes. The rest of them fall into the second category, also known as cache misses, which can happen for only three reasons.
The first reason a cache miss typically happens is simply when the cache does not find any matching resource in its storage. This is usually a sign that the resource has never been requested before, or has been evicted from the cache to free up some space. In such cases, the proxy has no choice but to forward the request to the origin server, fully download the response and look for caching instructions in the response headers.
The second reason a cache miss can happen is actually just as detrimental, where the cache detects a matching representation, one that it could potentially use. However, the resource is not considered to be fresh anymore - we will see how exactly in the Cache-Control section of this article - but is said to be stale.
In such case, the cache sends a special kind of request, called a conditional request to the origin server. Conditional requests allow caches to retrieve resources only if they are different from the one they have in their local storage. Since only the origin server ever has the most recent representation of a given resource, conditional requests always have to go through the whole caching proxy chain up to the origin server.
These special requests have only two possible outcomes. If the resource has not changed, the cache is instructed to use its local copy by receiving a 304 Not Modified response along with updated headers and an empty body. This outcome, the third one on our list, is called a successful validation.
Finally, the last possible outcome is when the resource has changed. In this case, the origin server sends a normal 200 OK response, as it would if the cache was empty and had forwarded the request. To put it another way, cache misses caused by empty cache and failed validation yield exactly the same HTTP response.
To best visualize these four paths, it is helpful to picture them in a timeline, as illustrated below.
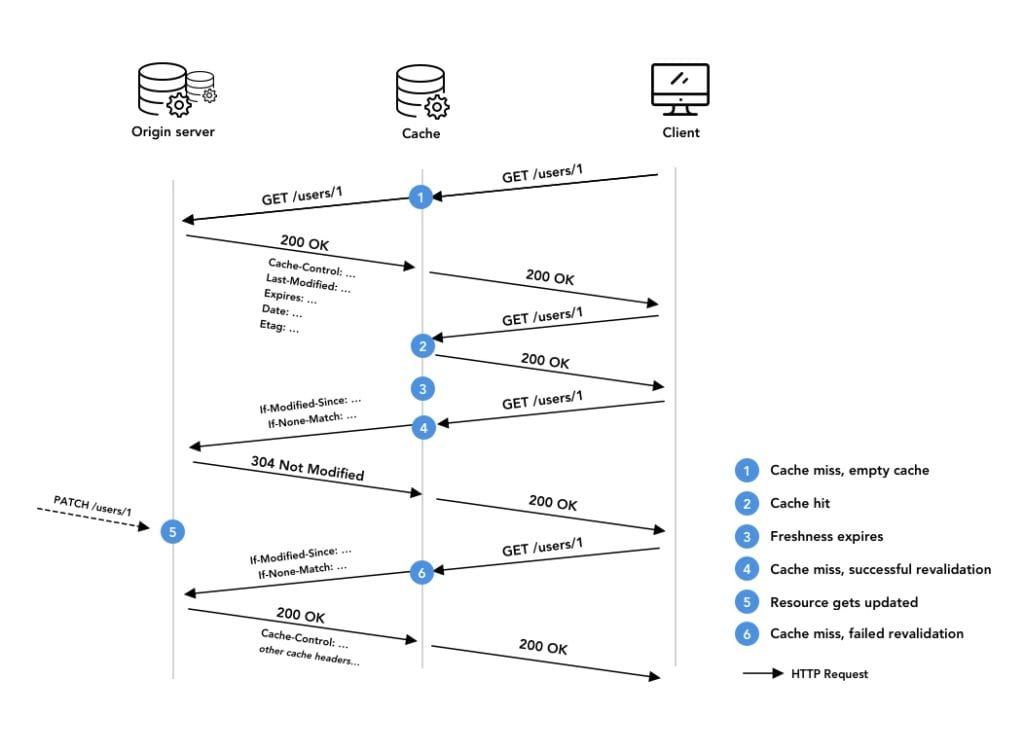
At first, the cache is empty. The flow of requests starts with a cache miss (empty cache outcome). On its way back, the cache would read caching instructions and store the response. All subsequent requests for this particular resource would yield to cache hits, until the resource becomes stale and needs to be revalidated.
Upon a first revalidation, it is possible that the resource has not changed, hence, a 304 Not Modified would be sent.
Then, the resource eventually gets updated by a client, typically with a PUT or a PATCH request. When the next conditional request arrives, the origin server detects that the resource has changed and replies a 200 OK with updated ETag and Last-Modified headers.
Knowing about cache hits and cache misses along with the 4 possible paths that every cacheable request could take, should give you a good overview of how caching works.
Though overviews can only get you so far. In the following section, we will give a detailed explanation of how origin servers communicate caching instructions.
How origin servers communicate caching instructions
Caching HTTP headers: Cache-Control, Expires, Pragma
Origin servers communicate their caching instructions to downstream caching proxies by adding a Cache-Controll header to their response. This header is an HTTP/1.1 addition and replaces the deprecated Pragma header, that was never a standard one.
Cache-Control header values are called directives. The specification defines a lot of them, with various uses and browser-support. These directives are primarily used by developers to communicate caching instructions. However, when present in an HTTP request, clients can also influence the caching decision. Let us now take the time to describe the most useful directives.
max-age
The first important Cache-Control directive to know about is the max-age directive, which allows a server to specify the lifetime of a representation. It is expressed in seconds. For instance, if a cache sees a response containing the header Cache-Control: max-age=3600, it is allowed to store and serve the same response for all subsequent requests for this resource for the next 3600 seconds.
During these 3600 seconds, the resource will be considered fresh and cache hits will occur. Past this delay, the resource will become stale and validation will take over.
no-store, no-cache, must-revalidate
Unlike max-age, the no-store, no-cache and must-revalidate directives are about instructing caches to not cache a resource. However, they differ in subtle ways.
no-store is pretty self-explanatory, and in fact, it does even a little more than the name suggests. When present, a HTTP/1.1 compliant cache must not attempt to store anything, and must also take actions to delete any copy it might have, either in memory, or stored on disk.
The no-cache directive, on the other hand, is arguably much less self-explanatory. This directive actually means to never use a local copy without first validating with the origin server. By doing so, it prevents all possibility of a cache hit, even with fresh resources.
To put it another way, the no-cache directive says that caches must revalidate their representations with the origin server. But then comes another directive, awkwardly named… must-revalidate.
If this starts to get confusing for you, rest assured, you are not alone. If what one wants is not to cache, it has to use no-store instead of no-cache. And if what one wants is to always revalidate, it has to use no-cache instead of must-revalidate.
Confusing, indeed.
As for the must-revalidate directive, it is used to forbid a cache to serve a stale resource. If a resource is fresh, must-revalidate perfectly allows a cache to serve it without forcing any revalidation, unlike with no-store and no-cache. That’s why this header should always be used with a max-age directive, to indicate a desire to cache a resource for some time and when it’s become stale, enforce a revalidation.
When it comes to these last three directives, we find the choice of words to describe each of them particularly confusing: no-store and no-cache are expressed negatively whereas must-revalidate is expressed positively. Their differences would probably be more obvious if they were to be expressed in the same fashion.
Therefore, it is helpful to think about each of them expressed in terms of what is not allowed:
- no-store: never store anything
- no-cache: never cache hit
- must-revalidate: never serve stale
Technically, these directives can appear in the same Cache-Control header. It is not uncommon to see them combined as a comma-separated list of values. A lot of popular websites still seem to behave very conservatively, sending back HTML pages with the following header:
Cache-Control: no-cache, no-store, must-revalidate, max-age=0
When you stumble upon this, the intention behind it is usually pretty clear: the web development team wants to ensure that the resource never gets served stale to anyone.
However, such cache-buster lines are probably not necessary anymore. Past work done in 2017 already showed that browsers are really rather compliant with the specification in respect to Cache-Control response directives. Therefore, unless you’re planning on setting up a caching stack with decades old software, you should be fine using just the directives you need. The most popular combinations will be analyzed in another article.
public, private
The last important directives we haven’t discussed yet are a little bit different, as they control which types of caches are allowed to cache the resources. These are the public and private directives, private being the default one if unspecified.
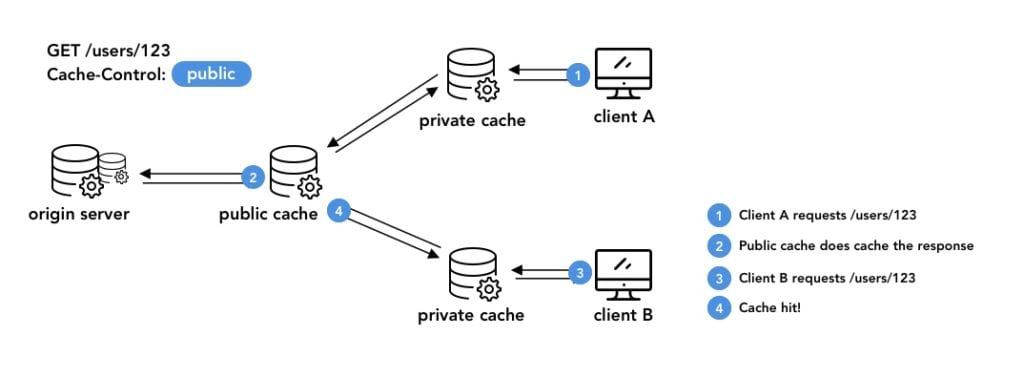
Private caches are the ones that are supposed to be used by a single user. Typically,
this is the web browser’s cache. CDN and reverse-proxies on the contrary, handle requests coming from multiple users.
Why do we need to distinguish these two types of caches ? The answer is straightforward: security, as illustrated by the following example.
Many web applications expose convenience endpoints that rely on information coming from elsewhere than the URL. If two users access their profile by requesting /users/me, at https://api.example/com, and their actual user id is hidden within a Authorization: Bearer 4Ja23ç42…. token, the cache won’t be able to tell these are in fact two very different resources.
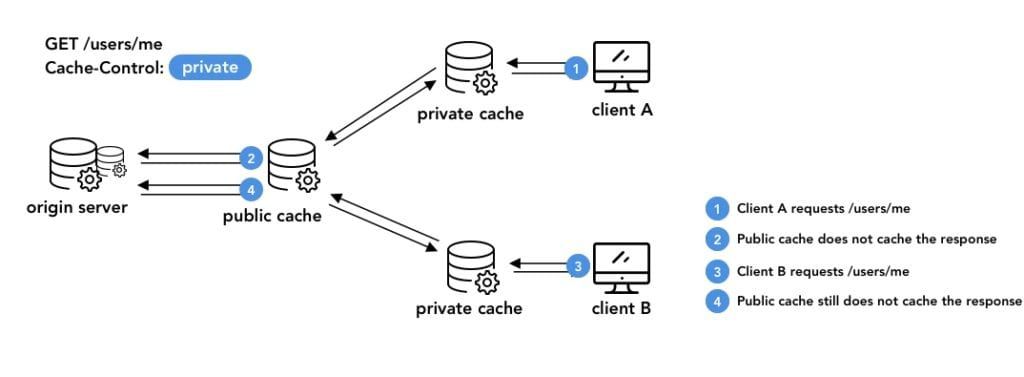
Indeed, when constructing their cache key, caches do not inspect HTTP headers unless specifically instructed to do so, as we shall see in the next section.
s-maxage
The s-maxage directive is like the max-age directive, except that it only applies to public caches, which are also referred to as shared caches (hence the s- prefix). If both directives are present, s-maxage will take precedence over max-age on public caches and be ignored on private ones.
When using this directive, the general rule is to always ensure that s-maxage value is below max-age’s. The reasoning behind this rule is that the closer you are to the origin, the more suitable it is to check frequently what the latest representation is.
Imagine you were to cache for one day in the proxy, and one hour in browsers. Every time a browser would ask a resource to upstream servers, we could know in advance that the proxy will not contact the origin server for at least a day. Therefore, why not put the same TTL directly in the browsers ? As a conclusion, it is a best practice to always leave out a longer TTL in max-age than in s-maxage.
stale-while-revalidate and stale-if-error
These two directives are not technically part of the original specification but are part of an extension which were first described more than 10 years ago. Although their browser support is limited, some popular CDNs have been supported them for more than 5 years!
Though stale-while-revalidate is pretty useful. As the name implies, it allows a cache to “[...] immediately return a stale response while it revalidates it in the background, thereby hiding latency (both in the network and on the server) from clients”.
This caching extension proves really helpful for things like images, where reducing latency is critical for the user experience, and where having a stale version for a few seconds is often better than a painfully downloading image.
As for stale-if-error, it allows a cache to serve a stale version if the origin server returns a 5xx status code. This gives developers a chance to fix potential issues during a grace period where clients are shielded from irritating error pages.
Consider the case of a meteo third-party script. If the meteo server happens to be unreachable for a few minutes, it’s probably best to display a slightly outdated forecast during this lapse of time, than it is to see a portion of the page be blank (or a whole blank page if the code does not handle third-party scripts loading failures)
What we don’t know yet
After examining these Cache-Control directives, we now understand how applications that are distributed on the web, tend to leverage HTTP caching mechanisms in multiple ways, depending on what they need.
Though what we don’t yet understand is what cache softwares actually do with the response they receive. They will most likely have to store it somewhere in order to retrieve it later. That’s the core idea of any caching system afterall.
Under normal circumstances, this certainly looks like what we would call an implementation detail. It should be merely enough to know that resources are indeed stored some way. Yet in this case, learning just a little more is actually critical.
Neglecting the mechanisms that govern how caching softwares map objects from the HTTP responses space to their storage space can have really unexpected consequences, such as serving a brotli encoded chinese document, to a user who does not understand chinese, using a browser unable to decode brotli ¯\_(ツ)_/¯
How caches store and retrieve resources
Caching HTTP headers: Vary
Albeit unlikely to happen, since most browsers can decode brotli - and since most people know how to 說中文 - the previous situation can still easily occur. To understand why this is the case, one must consider how caches store their representations.
By virtue of what they try to achieve, most caching softwares ought to be able to quickly retrieve simple text documents. To do so, a very simple yet powerful strategy is to use a key-value store. This strategy fits well in-memory representations. Therefore, the question one must answer when designing is the following: how to construct a cache key from an HTTP response ?
What we are looking for here is a way to uniquely identify a resource. Conveniently, this is exactly why URIs - Uniform Resource Identifiers - were invented in the first place!
But URIs don’t tell the whole truth about resources. They never describe them entirely, if only for the fact that resources change over time.
Websites get rebranded, new content gets published and users update their profile. Granted, not for the same reasons or at the same frequency, though all resources will eventually change. In fact, the entire Conditional request specification is based on this sole observation: nothing is permanent except change.
Philosophical quotes aside, there is, however, another time-independent reason why resources changes. Indeed, any moment, resources may be available in multiple representations. This is why we have Content-Negociation.
The HTTP request headers Accept, Accept-Language, Accept-Encoding, Accept-Charset (and a few other headers who are not strictly speaking part of content negotiation) add another dimension on which representations can differ. As such, the problem of finding a good cache key becomes more complicated. Since all these representations share the same URI, caches must have a way to distinguish them in order to serve the right representation at each client, honoring content negotiation.
And since only origin servers know what different representations are available, it is again the origin server’s responsibility to indicate to a cache based on which headers it will generate a different representation. To do so, the origin servers must add a Vary header containing the value of the request headers that cause different representations to be generated.
When caches see a response coming from an origin server with, for instance, the header Vary: Accept-Language, it will examine the value of the Accept-Language header, such as fr-FR**,** and use this value to construct a more specific cache-key, perhaps like https://example.net/home.html_fr-FR**.**
The actual implementation strategy is of little importance to us. Altering the cache key might not even be the best way to do it. It somehow has to use the value of the header to differentiate representations.
The Vary header can actually point at more than one header, when resources are available in multiple representations. Selecting a cache key when multiple headers are involved is not really much more complicated than with only one header. The real problem when varying over multiple dimensions is the combinatorial explosion.
Unfortunately, there are no ways around this. If you are to cache and serve your resources in multiple representations, you have to pay the cost of a large storage. If you decide to lower your vary cardinality, some of your users will receive cache hits for responses that won’t match their requests.
On the other hand, if you vary properly on everything, and as you should have, yet do not have enough storage space, chances are your users won’t be seeing cache hits anytime soon.
Now, it is important to know that this is only a problem if you decide to use a public cache, for which two different requests coming from two different users are running the same code, at the proxy level. If you decide to leverage the browser’s cache only, then you can skip the Vary header altogether and serve resources in as many representations as you want. This is because each browser’s cache will only cache representations matching the user’s preferences. This is good news!
But let’s not get ahead of ourselves just yet. As we said, caches use the value of the header as its input to generate a more specific cache key. But what is to say that all these values are well formatted ? Absolutely nothing! This is the rather inconvenient consequence of RFC father’s robustness principle. HTTP servers are indeed very liberal in what they accept.
However there is hope.
Considering the case of an origin server that can only produce a representation in two different languages, caches must be able to regroup incoming Accept-Content values such as fr, fr-FR, fr_FR_.._ into something such as FR. Otherwise, just like before with the combinatorial explosion, the number of representations will explode, but in this case, for a misguided reason.
The process by which all these representations are regrouped is called normalization and is often done at the cache. Many caches offer configuration utilities or their own languages to deal with these situations. Sometimes, the functions are even already written, or snippets can easily be found on the Internet. The following pictures illustrates the process for the infamous User-Agent header.
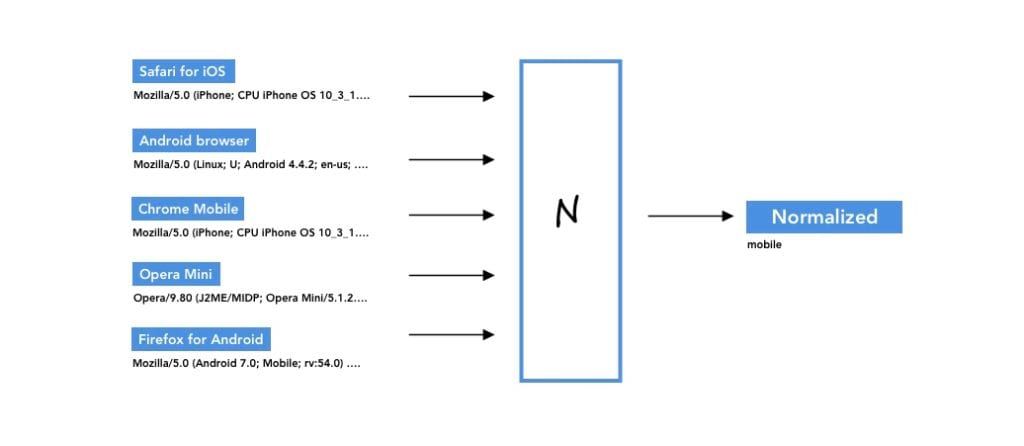
Fastly, a popular CDN, sampled 100 000 requests and found that the Accept-Encoding header was expressed in 44 different ways ! As for the User-Agent header, they found a shy of… 8000 different ones! Without normalization, chances are that the cache will never see any hit.
This wraps up the section about representation variation. At this point, we know how to instruct caches to store our resources, and have learned to leverage the Vary header to prevent accidents from happening when using public caches. We have now covered enough of the specification to be able to cache resources effectively.
Common misconceptions
By now, you should have a thorough understanding of how HTTP caching works. Freshness control, resource’s representations and cache hits are no longer mysterious concepts to you. And if you start to feel empowered by all this knowledge, we have some good news for you: we’ve covered a large portion of the specification, and you now know pretty much all that’s necessary to be up and running.
But make no mistake. Caching is a complex topic.
Experience has shown us that, unless you’re dealing with it on a day-to-day basis, what may be crystal clear today will quickly turn into something rather blurry after a few weeks. Therefore, we decided to conclude this second article by dispelling two common misconceptions that are all too easy to make.
Freshness-control and validation
This might seem obvious after reading the previous sections but it is worth repeating many times. Freshness control and validation (which we have slightly discussed in the beginning) are two very distinct mechanisms that serve two very different purposes, and involve HTTP requests between different pieces.
- Freshness control always happen in a cache and is solely based on time
- Validations always happen in the origin server and are based both on time and on identifiers (ETags)
This is something we find important to remind ourselves. It means that once the cache has received temporal instructions, it can - and best believe it will - serve resources without ever contacting the origin server until the timer expires.
For instance, if you’re web application’s HTML file reaches a browser and the HTTP response happens to include the header Cache-Control: max-age=86400 the browser will happily serve the same version of your app for a day. In this case, the browser would serve it for one day without any possible action from you or anyone, except the user, if one ever decided to flush his browser’s cache.
If you’re thinking everyone can make mistakes, and one day is not so bad, well, brace yourself: the maximum max-age value is… 31536000 seconds! That is to say, one year. This is the reason why HTML files are very dangerous to cache like this, and should generally be declared with Cache-Control: no-cache
Freshness and most recent representation
Another misconception is to believe that cache hits and freshness have anything to do with having the last available version of a resource. This is what we all try to achieve, but one can never truly know if the resource it has been served from a cache is indeed the most up-to-date version. In fact, this holds true even in the absence of cache. It has to do with the nature of distributed applications: other people’s actions can change the things we are interacting with at any time.
When querying the state of the application, the ETag header must always be used to always let the server know what our current understanding of the application’s state is. And if it does not match the server’s, 409 Conflict are expected to be received on the client side.
Conclusion
Along this article, we have described how caching actually works. Now would be a good time to spin up a local dev server and fiddle around with these two core headers : Cache-Control and Vary to see them in action.
We started by giving an overview of how caching works, illustrating the four possible paths that a request can take : the happy path (cache hit) and the 3 possible ways to have a cache miss : empty cache, failed revalidation and successful revalidation. This overview alone gives the possibility to understand how complex caching topologies can fit together.
Then, we went deeper and looked at all the most useful Cache-Control headers, and clarified some subtle differences that are all easily missed.
We also looked at the Vary header and the fundamental difference between resources and representations, to avoid serving the wrong representation to the right client.
Finally, we took some time to review it all through the angle of common misconceptions you might encounter, and hopefully helped you to avoid them.
In the next article, we’ll apply all of this knowledge to set up a local lab environment in which we will set an innocent node.js app on fire with a load-testing tool, right before rescuing it with the help of a popular caching software.
Stay tuned!
To go further:
The official specification about the material we covered (and other things) https://tools.ietf.org/html/rfc7234#section-5.3
Google Web’s Fundamental https://developers.google.com/web/fundamentals/performance/optimizing-content-efficiency/http-caching#defining-optimal-cache-control-policy
About the Cache-Control header:
https://developer.mozilla.org/fr/docs/Web/HTTP/Headers/Cache-Control
About the Vary Header: https://www.smashingmagazine.com/2017/11/understanding-vary-header/ https://www.fastly.com/blog/best-practices-using-vary-header https://www.fastly.com/blog/getting-most-out-vary-fastly https://www.fastly.com/blog/understanding-vary-header-browser