Brève histoire du Prompt Engineering au Harness engineering
Le terme de Prompt Engineering est largement répandu. Vous avez aussi probablement entendu parler du Vibe Coding, et désormais du Harness Engineering, voire même du Agentic Engineering. En réalité vous avez sans aucun doute eu vent de nombreux autres termes. Le développement assisté par GenAI est un sujet jeune et largement exploité par le marketing et les influenceurs, au point que les termes sont employés sans avoir toujours éclairci les frontières entre les concepts. Les distinguer est pourtant la clé du progrès. Sans cela, des termes seront continuellement réinventés, des apprentissages sous un terme ne paraîtront pas transposables sous un autre, ce qui nous poussera à réinventer la roue sans savoir qu'elle existe déjà.
Après une consolidation de notre veille sur le sujet, nous vous proposons de survoler l'histoire de quelques termes de ces dernières années, pour ensuite les articuler entre eux. Et puisque l’essentiel de ces termes est né d’observations, mais souvent aussi d’opinions et d’intérêts, nous allons nous appuyer sur un ensemble d’entre elles.
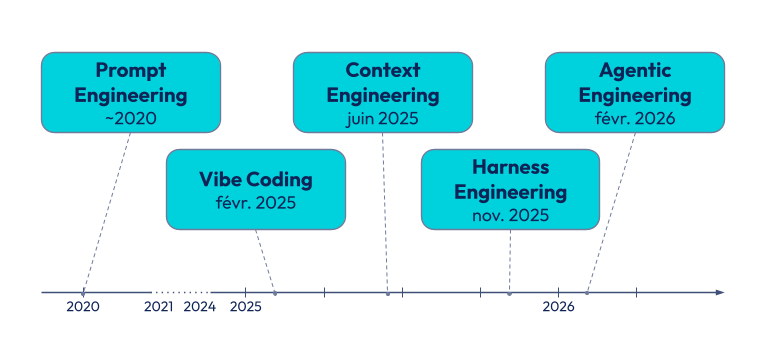
~2020 : Prompt Engineering
Difficile de retrouver la source du terme Prompt Engineering. La pratique d'adapter le prompt pour obtenir une réponse particulière du LLM existait avant la popularisation des modèles Generative Pre-trained Transformer (GPT). En 2018, on trouve déjà un papier de Salesforce Research évoquant une interaction Question-Réponse avec des LLMs. Mais c'est suite à l'apparition de GPT-3 (mai 2023) que le public de l’époque a commencé à s'orienter vers ce terme. Les techniques de "few-shot / in context learning" permettaient déjà, en donnant des exemples, d'orienter les résultats produits.
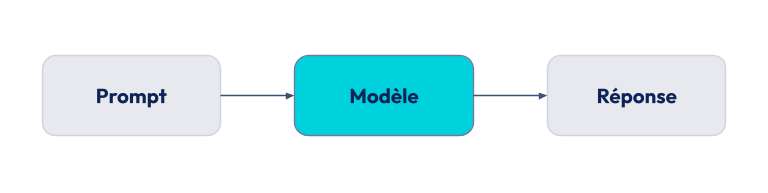
Quelques semaines plus tard, le terme Prompt Programming est apparu sur le blog d'un chercheur, terme qui semble ensuite avoir été reformulé sous le terme Prompt Engineering dans un thread HackerNews associé.
Le principe est le suivant : Les évolutions architecturales des LLMs ont permis de diriger de façon plutôt fiable les résultats produits. La demande peut-être formulée avec des exemples ou une structure et format particuliers. Par la suite, la taille grandissante des modèles a rendu possible des demandes en plusieurs étapes qui ont notamment fait émerger le Chain-of-Thought.
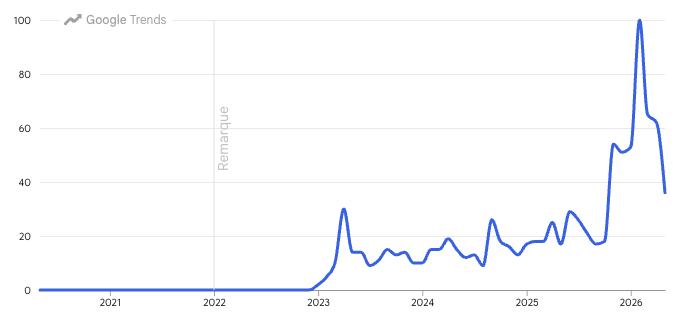
On peut cependant retrouver des apparitions plus fréquentes du terme dès le début 2023 comme le montre ce graphe Google Trends. La même année, les offres d'emploi sur le sujet ont explosé avec des propositions salariales faramineuses.
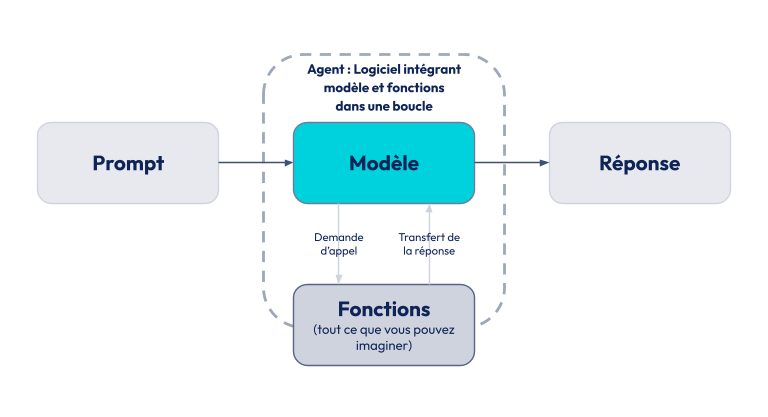
En juin 2023, OpenAI annonçait un élément crucial pour le développement assisté par IA : le function / tool calling. Les modèles gpt-4 et gpt-3.5-turbo ont été spécifiquement entraînés pour produire, à partir de descriptions de fonctions fournies dans le prompt, un output contenant le nom de la fonction visée et les arguments associés. Charge ensuite à un logiciel encapsulant le LLM de capter cet output, d'exécuter réellement la fonction, et de réinjecter le résultat dans le contexte pour que le modèle poursuive son raisonnement. Cette boucle paraît anodine, mais elle déplace une frontière : le LLM, qui n'a aucune capacité d’action propre, peut désormais déclencher des actions dans des systèmes externes (requête API, lecture d'un fichier, recherche web…) puis raisonner sur leur retour. C'est sur ce mécanisme que reposera l'essentiel des évolutions qui suivront : agents, MCP, et plus largement tout ce que le Harness Engineering cherche à structurer.
Février 2025 : Vibe Coding
Apparu dans un tweet de Andrej Karpathy le 3 février 2025, le terme désigne un lâcher prise total sur le "comment" pour se concentrer sur les résultats, au point où l'expertise qui était nécessaire pour produire ces résultats est largement mise de côté. Quelques extraits :
There's a new kind of coding I call "Vibe Coding", where you fully give in to the vibes, embrace exponentials, and forget that the code even exists. It's possible because the LLMs (e.g. Cursor Composer w Sonnet) are getting too good [...] I ask for the dumbest things like "decrease the padding on the sidebar by half" because I'm too lazy to find it [...] I don't read the diffs anymore [...] I just copy paste them in with no comment, usually that fixes it [...] The code grows beyond my usual comprehension [...] It's not too bad for throwaway weekend projects [...] but it's not really coding - I just see stuff, say stuff, run stuff, and copy paste stuff, and it mostly works
Comme l'indique le tweet, cette approche a pu naître car les modèles avaient suffisamment gagné en performance et connaissances pour réaliser une tâche de bout en bout. Et comme l'avait pressenti aussi Karpathy dans ce tweet, la viabilité d'un tel résultat était suffisante pour des projets de petite échelle.
Juin 2025 : Context Engineering
Puis en juin 2025 Tobi Lutke, CEO de Shopify, évoque le nouveau terme de Context Engineering :
I really like the term “context engineering” over prompt engineering.
It describes the core skill better: the art of providing all the context for the task to be plausibly solvable by the LLM.
Il est amplifié quelques jours plus tard par Andrej Karpathy qui paraphrase la définition :
the delicate art and science of filling the context window with just the right information for the next step
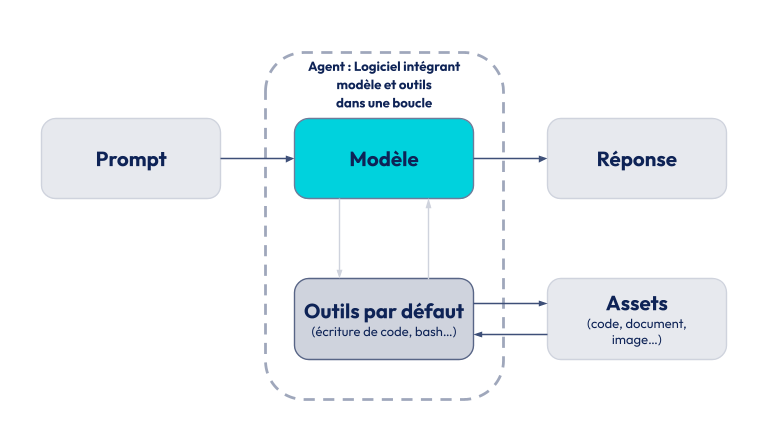
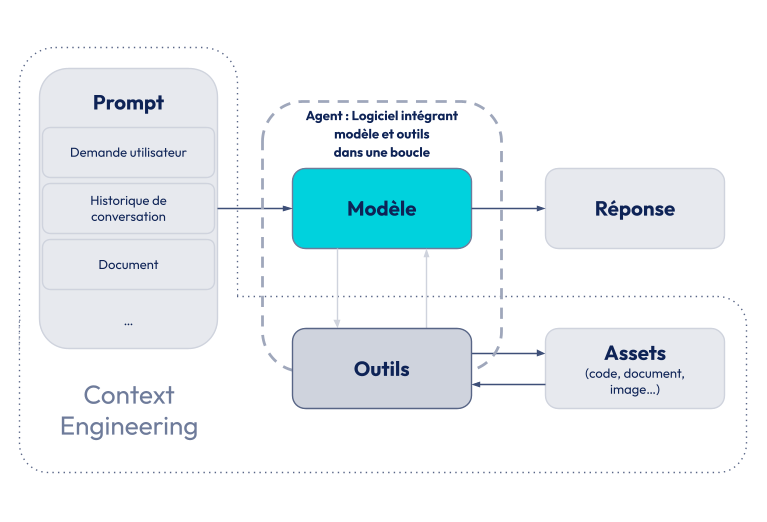
Le principe est le suivant : le LLM est alimenté en contexte par les prompts qu'on lui fournit (ex: demande, outils disponibles, historique de conversation, etc). Avec l'augmentation de la complexité des modèles et de la taille du contexte qu'ils peuvent recevoir, on s'est rendu compte qu'il ne suffisait pas de tout lui donner, mais qu’il fallait sélectionner les bonnes informations pour que son attention soit dirigée sur le nécessaire à la bonne réalisation de sa tâche. Ce prompt est alimenté autant à la main (demande utilisateur) que par des outils en amont et durant les étapes d'appels aux fonctions (ex: MCP).
Harness Engineering et Agentic Engineering
Comme pour d’autres termes de cet article, l’origine de “Harness Engineering” n’a pas été simple à déterminer. Une convergence indépendante reste possible, mais il est aussi possible que tout le monde n'ait pas crédité ses sources d’inspiration. Et entre l’apparition et la popularisation du terme Harness Engineering, celui d’Agentic Engineering a quelque peu brouillé les cartes.
Novembre 2025 : Premières apparitions du Harness Engineering
Le terme “Harness” apparaît très tôt dans les études à propos des agents, car celui-ci est plutôt commun pour désigner un cadre contraignant. On parlait déjà de harnais de tests bien avant l’arrivée de la GenAI. Le terme seul de harnais ne sort donc pas du néant.
L'occurrence la plus lointaine que nous ayons trouvé (et il en existe peut-être bien plus tôt dans les recoins du net) semble venir de Dex Horty le 4 novembre 2025 :
Harness engineering -> How do you engineer the *integration points* of a given agent to get the best results ? You can't do harness engineering without understanding context engineering, and you can't do context engineering without building intuition around LLMs
Quand Dex Horty parle “integration point”, il s’agit des façons d’alimenter le LLM. Comme nous l’avons vu plus tôt : par prompt, ou de façon “autonome” par function calling (l’agent fournit des paramètres, et le système qui l’encapsule lui donne le résultat de l’appel). Ce qu’il dit est que le “Context Engineering” est un prérequis du “Harness Engineering”, c'est-à-dire pour savoir quels moyens techniques il faudrait concevoir pour que l’agent atteigne efficacement ses objectifs. Par exemple, un modèle pourrait mieux agir dans un écosystème technique s’il a accès (tel que par MCP) à la documentation fonctionnelle associée.
Le même mois, le 25 novembre, Vivek Trivedy de LangChain évoque sur son blog :
The Myth of General Purpose Agents. Models are non-fungible in their harness, designing around their spiky intelligence is good harness engineering
Vivek va un cran plus loin en indiquant que le Harness est spécifique à chaque modèle. En effet, chaque agent réagit différemment aux outils et fonctions qu’on lui fournit, pour une raison simple : ils n’ont pas été entraînés de la même façon. Ils n’auront alors pas la même réaction dans ces intéractions.
Février 2026 : Agentic Engineering
Quelques mois plus tard, le 4 février 2026, et un an et un jour après avoir parlé de Vibe Coding, Andrej Karpathy revient sur ce tweet en réaffirmant le type d'activité qu'il y associait.
Today (1 year later), programming via LLM agents is increasingly becoming a default workflow for professionals, except with more oversight and scrutiny. The goal is to claim the leverage from the use of agents but without any compromise on the quality of the software. Many people have tried to come up with a better name for this to differentiate it from Vibe Coding, personally my current favorite "Agentic Engineering":
- "agentic" because the new default is that you are not writing the code directly 99% of the time, you are orchestrating agents who do and acting as oversight.
- "engineering" to emphasize that there is an art & science and expertise to it. It's something you can learn and become better at, with its own depth of a different kind. In 2026, we're likely to see continued improvements on both the model layer and the new agent layer
En somme, l’agent reste un intermédiaire entre le code et le développeur, mais on s’affaire à l’équiper et le spécialiser sur les projets à réaliser. Une perspective qui n’est pas étrangère aux premières définitions du “Harness Engineering”. Dans une interview lors du Sequoia Ascent 2026, il va plus en détail sur ce qu’il entend par “engineering” dans le terme “Agentic Engineering”.
Vibe Coding is fine for prototypes and personal tools. Agentic Engineering is what serious teams need. The agentic engineer does not blindly accept generated code. They design specs, supervise plans, inspect diffs, write tests, create evaluation loops, manage permissions, isolate worktrees, and preserve quality.
Février 2026 : Popularisation du terme Harness Engineering
Plusieurs praticiens au début février 2026 l’ont parallèlement utilisé. Le 5 février, Mitchell Hashimoto, co-fondateur de HashiCorp, pensait improviser le terme. Familier du mot “harnais”, il n'avait probablement pas vu les occurrences citées plus haut :
I don't know if there is a broad industry-accepted term for this yet, but I've grown to calling this "Harness Engineering". It is the idea that anytime you find an agent makes a mistake, you take the time to engineer a solution such that the agent never makes that mistake again [...]
This comes in two forms:
- Better implicit prompting (AGENTS.md). For simple things, like the agent repeatedly running the wrong commands or finding the wrong APIs, update the AGENTS.md (or equivalent). Here is an example from Ghostty. Each line in that file is based on a bad agent behavior, and it almost completely resolved them all.
- Actual, programmed tools. For example, scripts to take screenshots, run filtered tests, etc etc. This is usually paired with an AGENTS.md change to let it know about this existing.
This is where I'm at today. I'm making an earnest effort whenever I see an agent do a Bad Thing to prevent it from ever doing that bad thing again. Or, conversely, I'm making an earnest effort for agents to be able to verify they're doing a Good Thing.
Une définition plus opérationnelle que l'Agentic Engineering, mais bien liée au même type d'activité.
Cela dit, le terme s'est véritablement popularisé lors de la publication d'un article de Ryan Lopopolo sur le blog d'OpenAI le 12 février 2026 : Harness Engineering: leveraging Codex in an agent-first world. Ce que révèle cet article est alors assez frappant : 5 mois de développement sans que l'équipe ne touche à une ligne de code, un produit stable et en production en interne d'OpenAI. On pourrait objecter que les enjeux d'un produit interne sont probablement plus faibles que ceux d'une production client-facing, et qu'un produit accessible au public permettrait des observations plus impartiales que celles d'OpenAI pour juger du résultat. Cependant, ce retour d'expérience expose une démarche plutôt précise lorsqu'elle est croisée avec d'autres articles et interviews à ce sujet, et employable avec d'autres outils que ceux d'OpenAI. On peut donc tenter de la reproduire pour nous faire notre propre avis.
Birgitta Böckeler analyse l'article le 17 février 2026 dans un mémo sur le blog de Fowler. Elle y observe que le succès de l'approche repose sur la contrainte : réduire la taille de l'espace des solutions bénéficie au LLM autant qu’aux humains (stacks techniques réduites, patterns architecturaux imposés, linters...). Elle pointe aussi ce qu'elle perçoit comme un angle mort dans le cas OpenAI : l'absence de vérification fonctionnelle. Et, en effet, Lopopolo précise dans une interview pour Latent Space que même si un smoke test manuel subsiste avant chaque distribution ("we require a bless human approved smoke test of the app before we promote it to distribution"), aucun filet automatisé ne porte sur ce que le produit fait extensivement.
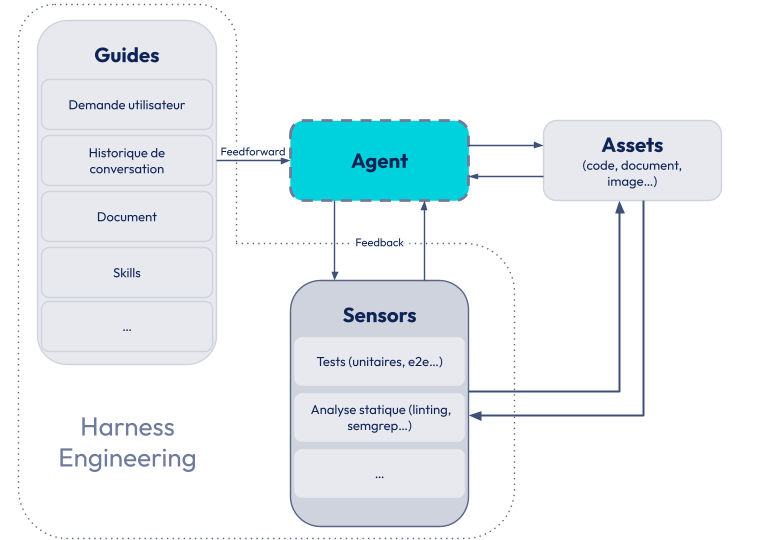
Ce mémo a été suivi quelques semaines plus tard, le 2 avril 2026, par un article explorant plus en largeur ce qu'implique le Harness Engineering : Harness Engineering for Coding Agent Users. En substance, le LLM n'a aucune capacité d’action propre, et doit donc se reposer sur, et/ou est articulé par, un ensemble d'éléments logiciels tels que des outils d'écriture, de lecture, d'exécution, de recherche web, etc. Le Harness Engineering consiste en l'ingénierie de cet écosystème, avec une catégorisation des éléments sur lesquels agir : Guides and Sensors. Les Guides viennent alimenter le LLM, dans le sens où ils vont guider son implémentation pour qu’il réalise correctement la tâche. Tandis que les Sensors permettent de lui donner du feedback sur sa production, par exemple à travers l’exécution d’une suite de tests, d’un linter, voire une review d’un autre agent. Si l'on se rappelle la définition du Context Engineering, ce terme englobait déjà, mais sans les distinguer, ces deux aspects. On vous conseille chaudement de le lire. Ce qu'il apporte, par rapport aux contributions habituelles, c'est une transposition avec un domaine établi de longue date : la cybernétique.
Petite note : dans la définition de Böckeler, les permissions, le sandboxing et la conteneurisation de l’environnement d’exécution, qui vont restreindre les actions de l’agent, sont absents. Alors que dans le cas de l’Agentic Engineering de Karpathy, ces notions sont présentes. La définition de Böckeler est plus concentrée sur les mécanismes systémiques qui orientent les résultats de l’agent, là où celle de Karpathy engloble l’ensemble du système agentique.
Comment démêler tout ça ?
L'Agentic Engineering et le Harness Engineering semblent plus difficiles à distinguer, notamment parce que la définition de Karpathy est assez succincte. On peut cependant s'appuyer sur une définition de ce qu'est un agent pour distinguer les concepts. Dès l'entrée en matière du mémo de Böckeler, elle cite une contribution de Vivek sur le blog de LangChain qui va nous permettre de mettre en musique tous ces termes : Agent = Model + Harness.
Donc :
- Un agent est composé d’un LLM et d’un ensemble d'éléments logiciels
- Développer avec la GenAI, c'est le faire au travers d'un ou plusieurs agents.
- Codex, Claude Code, et d'autres, fournissent des interfaces pour utiliser ces agents sur une sélection plus ou moins ouverte de LLM, et avec un harnais par défaut (mais extensible).
- Le Vibe Coding revient à se reposer essentiellement sur ces agents sans itérer sur une spécialisation du harnais sur la tâche en cours.
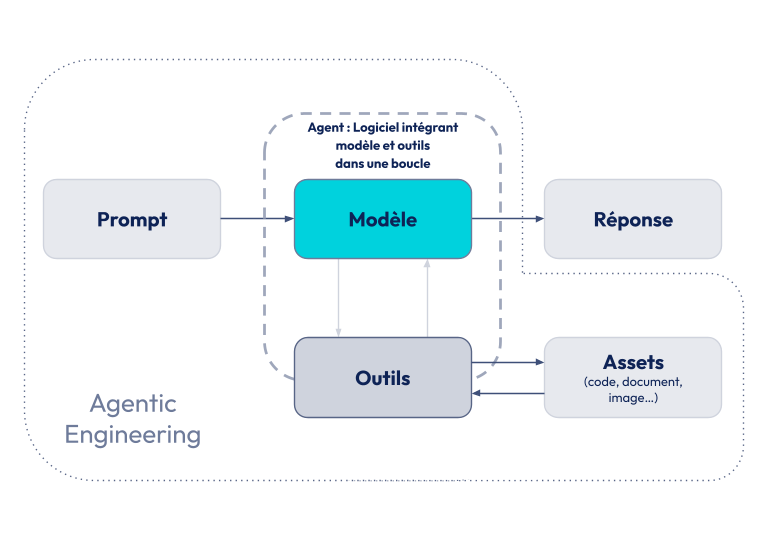
- L'Agentic Engineering consiste à développer par l’intermédiaire d’un agent, mais avec un travail de fond à la fois sur le modèle, le harnais et l’écosystème de façon à ce que les résultats de l'agent soient, de façon fiable, le plus en adéquation avec la cible voulue.
- Le Harness Engineering, lui, se concentre exclusivement sur le harnais de l'agent, sans chercher une quelconque amélioration sur le modèle (ce qui n'est de toute façon pas à la portée de tous).
Le point le plus ambigu dans cette chaîne, ce sont les possibilités d'action sur le modèle que sous-entend l’Agentic Engineering. Parle-t-on simplement d'une sélection de modèles adaptés, ou bien allons-nous jusqu'au fine-tuning, voire l'entraînement ? Au vu de la compatibilité entre les APIs des modèles, et des fonctionnalités prévues dans les interfaces conversationnelles et programmatiques, sélectionner un modèle adapté semble plutôt acquis par la plupart des utilisateurs. En revanche, s'il s'agit de fine-tuning ou d'entraînement, le coût d'entrée (compétences, temps, dépenses...) va fortement limiter la possibilité d'exploiter cette option.
Le poids du harnais sur la performance d'un agent
Maintenant que les frontières sont posées, on va enfin se demander pourquoi tout cela mérite plus d'attention que tous les autres termes marketing dont on a eu vent récemment. Faisons un focus sur le Harness Engineering : à quel point le harnais impacte-t-il la performance des agents ?
L'usage du terme "Harness Engineering" dans les études au sujet de la performance des agents est assez récent. En revanche, en regardant l'usage du terme harness seul, ou d'autres termes concernant les mêmes composants, comme scaffold ou tools / tooling, on trouve déjà de la matière dès 2024.
Une première preuve vient du papier fondateur de SWE-agent (Yang et al., 2024). Les auteurs y comparent, à modèle identique (GPT-4 Turbo) et sur SWE-bench Lite, un simple shell par rapport à leur Agent-Computer Interface (ACI), conçue sur mesure. Le taux d’exercices résolus passe de 11,0% à 18,0% uniquement par redesign des outils mis à disposition de l'agent.
D'autres travaux convergent dans la même direction. AutoCodeRover (Zhang et al., 2024) montre qu'un parcours du code par AST (Abstract Syntax Tree, une représentation des flux d’exécution sous forme d’arbre) plutôt que par lecture de fichiers atteint 19% sur SWE-bench Lite avec GPT-4, performance comparable à SWE-agent (18%) pour un coût d'API d'environ six fois moindre (0,43 $ contre 2,51 $ par tâche). À l'inverse, Agentless (Xia et al., 2024) montre qu'un harnais radicalement plus simple, un pipeline non agentique en trois phases (localisation, réparation, validation), peut surpasser un harnais plus riche : 32% à 0,70 $ par tâche contre 18,3% à 2,53 $ par tâche pour SWE-agent, à modèle égal (GPT-4o). La complexité du harnais est alors aussi un facteur.
Précaution de lecture : ces trois travaux comparent des harnais entiers très différents les uns des autres ; on ne peut pas en déduire qu'un composant particulier apporte systématiquement un même gain. Mais à modèle constant, l'ensemble pointe une même conclusion : le harnais affecte significativement la performance d'un agent.
Vibe Coding ou Harness Engineering ?
Si l'on considère que les actions sur le modèle sont, dans la plupart des situations, limitées à la sélection, on peut se permettre de réduire le problème à Vibe Coding vs Harness Engineering.
Nous avons à disposition deux pratiques qui semblent opposées :
- se reposer sur les performances d’un agent sur étagère, et le laisser libre de nombreuses décisions, pour un résultat rapide mais peu maintenable.
- investir dans l'outillage autour du modèle dès les premières interactions, fixer des contraintes fortes au fur et à mesure, pour obtenir un résultat vérifiable, ce qui permet d’améliorer progressivement la qualité et de garantir une meilleure performance pour les prochaines générations de code.
En prenant du recul sur ces approches, on remarque une dualité déjà bien connue : prototypage et développement. Au final, sous ces termes, il devient évident que le Vibe Coding n'est pas à bannir, et que le Harness Engineering ne doit pas devenir un Golden Hammer.
Mieux encore, il existe probablement un spectre entre ces deux pratiques. On continuera à se servir du prototypage dans les phases de développement, que ce soit pour du tooling ou pour évaluer plusieurs approches. Il ne concerne pas uniquement la première étape d'un produit, mais aussi plusieurs phases au cours de son développement. La GenAI peut grandement apporter sur ces phases intermédiaires, car le temps joue souvent contre une élaboration de l'outillage (en ce sens, la GenAI peut être un accélérateur d’une stratégie orientée DevEx) et aussi contre une évaluation approfondie des différentes options d'architecture d'un projet.
La construction d'un MVP se situe aussi entre les deux : un produit rapidement livré pour tester des hypothèses auprès des utilisateurs, sur la base d'un code suffisamment correct pour qu'on évite le bruit des instabilités, et surtout qu'on puisse continuer à le maintenir dans le temps.
Pour plus de concret sur ce que vous pouvez déjà faire pour vous engager sur la voie du Harness Engineering, on vous invite à consulter notre dernier article : Harnessing des agents, 9 pratiques venant du logiciel.
Futur de ce spectre
Dans la même interview durant la Sequoia Ascent 2026, Karpathy a aussi dit :
Vibe Coding raises the floor [...] Agentic Engineering raises the ceiling.
Tel que décrit dans l'interview, Karpathy semble donner une image assez statique de ce que le sol et le plafond peuvent être. Le Vibe Coding rend le développement plus accessible, l'Agentic Engineering repousse les limites du harnais par défaut. Mais à y regarder d'une façon plus dynamique, la réalité est que les systèmes agentiques "piles incluses" comme Claude Code et Codex n'ont cessé d'évoluer : un sol qui monte. En revanche, le fait que le harnais joue une place aussi prépondérante est plutôt récent et encore peu répandu. C'est probablement ce qui laisse encore penser certains que le Vibe Coding rattraperait l'expertise logicielle humaine. Mais maintenant que les principes du Harness Engineering se popularisent, l'écosystème au sens large en prend conscience, et de nouvelles analyses et études le poussent lui aussi vers le haut, au point d'ailleurs où l'on voit déjà apparaître des prépublications sur l'automatisation de l'évolution du harnais.
Cependant, si on se rappelle la remarque de Böckeler sur la vérification fonctionnelle, on comprendra que quelle que soit la vitesse à laquelle évolueront les harnais par défaut, il restera une frontière infranchissable aux solutions qui s'achètent : il vous faudra spécialiser vos harnais sur le domaine à résoudre. Brooks avait décidément raison : nous n'avons toujours pas trouvé de Silver Bullet. Comme nous le verrons dans de futurs articles, nos professions ont encore de beaux jours devant elles.