Breaking down Continuous Delivery on Power BI
Context
In this blog post we want to share with you how we implemented DevOps practices in a data visualization tool (Power BI) during a delivery project.
What was the aim of this project ? To make it short, we had to automate the process of collection, transformation and visualization of the data for a large organization with entities spread across the world. The foundation has to be built using software craftsmanship practices leading to a cultural change in the development process. The output was an app enabling the business users to assess and benchmark the performance of their business units. To succeed, a team of developers with their own expertise (data engineering, architecture, ops and data visualization) was set-up.
Without knowing it at first, one of the challenges of this project was to understand how to bring a seamless process to the deployment of a data visualization tool and to control the delivery of reports.
We will highlight the ups and downs that we encountered while implementing DevOps for Microsoft Power BI.
One team with different practices
Aside from the inherent mission, we faced two additional challenges:
- The first one resulted from the Covid-19 pandemic which forced the team to work remotely without having the possibility to meet and socialize on a regular basis,
- Secondly, none of the team members had worked together before. Working remotely has affected the teams' understanding of our own practices and expertises.
Therefore, before starting the actual development of the product, we had to learn to know each other, define working principles and compare our working practices.
While discussing the working practices, we discovered that the members in charge of the data restitution had a different set of methodologies. Let's focus on these.
Some data visualization projects require the use of software applications that come with their own specificities (framework and development tools) that can limit the scope of possibilities in development practices. Within this range of possibilities, automation is a major difference. Working with versioned plain text files containing code, automation of testing, automation of deployment, none of these are commonly used by data visualization teams when using editor tools. This specific project was no exception !
Based on this observation, the team held workshops to present Microsoft Power BI and started to investigate how to introduce changes in practices. We have investigated the Accelerate framework(1)(2) and weighed the most beneficial practices we could implement during the project. Under the umbrella of continuous delivery (CD), version control and deployment automation were the most promising capabilities for the project and the team (the goal being to increase their skills and make them autonomous afterwards). Trunk-based development, Continuous delivery would be second points to be addressed. The other capabilities (Continuous integration, Test automation, Test data management, Shift left on security) are not prioritized.

Collaborating around the workflow design
As a backend developer and ops, I am used to work with with Open Source software but not familiar with Power BI. However, all softwares have their own workflow, so let’s focus on that rather than the technology with the Continuous Delivery practices in mind.
The current development workflow
Power BI developers are used to work with a desktop application. From there, they can fetch data from a database, transform it and design reports to be displayed and deploy it on a workspace. The deployment units are *.pbix files sent to the workspace.
Overall, Power BI is a low-code/no-code application. No code is necessary to use the tool however, mastering the DAX and M languages are mandatory to leverage the full potential of the tool.
Let’s not hustle (too much) their habits, but add our own:
- Can we put your sources under control management?
- How do you test your reports and the queries written inside?
- How is the report reviewed? Through pair/mob programming?
“The report’s sources are saved under a single *.pbix file which is also the deployment unit. The reports are saved locally and in the workspace once we’ve deployed them and we usually have a dedicated team that run tests before a release”
How can you ensure that someone else doesn’t overwrite your work by uploading a different version?
“We divide the work so that each report is only under one developer’s charge”
Versioning the work
Power BI files (.pbix) are binaries, which makes it impossible to check-in only changes made to the model or visualizations. The .pbix file is identified as one object, and each modification is processed as a new version of this object.
One way to version the .pbix files is to save them on a shared folder (SharePoint, OneDrive, … you name it). Although this approach might seem good enough to begin with, you won’t be able to rollback easily from one version to another, recovering from accidentally deleting the whole directory is painful.
To address those points, we’ve chosen to put our binaries under Source Control Management, using Git (Git would be the most popular solution as of today). Still, identifying differences between commits is not feasible on non plain text files.
Deployment workflow
Long story short: everything is done manually through the desktop application or UI (https://app.Power BI.com)

Our objective is to apply Continuous Delivery best practices in order to empower, industrialize and scale up the teams, so “Automate or die”!
Power BI exposes a REST API that could be consumed by a CI/CD pipeline. We’re using a PowerShell Commandlet giving some abstraction and still allowing us to make native calls to the REST API if the feature is missing.
After a few workshops we came to this development and deployment workflow :
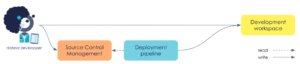
We’ve added two new components to our workflow:
- The Source Control Management (SCM): our versioning system, source of truth and tool to share the work on report among the team
- A pipeline to automate the deployment of all our reports
From a developer perspective, they can still deploy their report manually and we’ve added a new step to the workflow: they have to backup their work in the SCM in order to save and share it. To avoid the overriding of the work in progress, the pipeline has been configured to deploy on demand only (it’s a click on a button from the UI).
Release workflow
“Wanna go into production and make your end-users happy?”
It is done with the same components and handled from a SCM perspective. We took our inspiration from the GitLab Flow : we have 2 persistent branches, each persistent branch is to be deployed on a workspace.
| Branch name | __Workspace n__ame |
| main | development |
| production | production |
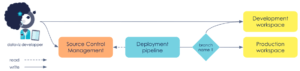
We’ve gained the ability to audit and trace over the version of our released reports. Feature release is strongly coupled with feature deployment into the production workspace. Feature release/deployment is no longer done manually, but only from the pipeline. An update in the SCM on the production branch automatically triggers the pipeline.
From design to implementation, lessons learned
(tips & stuff that went wrong)
Not everything is versionable
Multiple reports can use a “shared dataset”: a .pbix file will contain only the data model (avoiding duplication) and the different reports (stored in different .pbix files) will consume the data stored in the shared dataset :
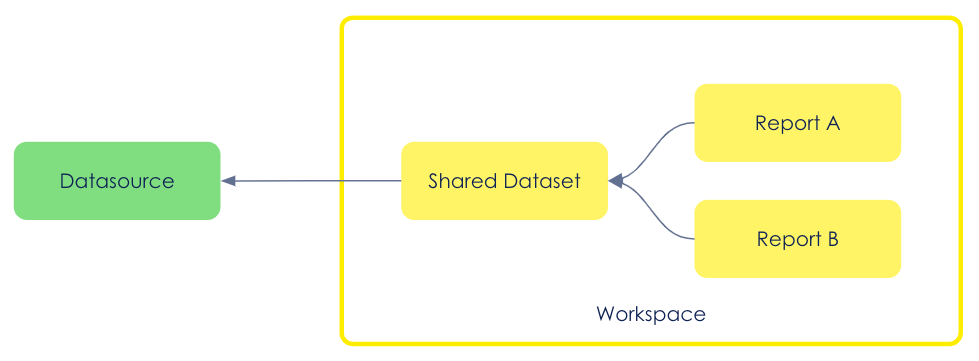
That being said, DO NOT put under version control shared dataset files: they contain the datasource's configuration (database URI, credentials, parameters)… but also cached data!
Each time the data is changed in our datasource, the shared dataset has to be refreshed. Operational data should not be put under version control.
Report configuration is not externalizable
DO NOT delete the development workspace shared dataset.
Reports using a shared dataset also contain the dataset identifier hard coded inside. If you delete the dataset, you can’t redeploy the report without editing the report. The report is strongly coupled with the dataset, the configuration is not externalized nor separated from the code, in contradiction with the third factor of the TwelveFactor App : Store config in the environment.
REST (not so) in peace
REST API calls are only available to a Power BI workspace with premium capacity based 💰.
Power BI Reports APIs are documented with a “Try It” functionality (like a Swagger UI) giving a developer portal experience. While the PowerShell Command encapsulates some of the complexity, we have observed that parallel calls returned in error and debugging is painful due to lack of actionable error logs.
Authentication can be done through two OAuth2 flows:
- Authorization Code Flow (from Microsoft portal)
- Client Credentials Flow (from our pipeline)
In both cases, documentation surrounding it is not self-explanatory. The documentation doesn’t cover authentication implementation. Our pipeline needs a client id and client secret to authenticate and consume Power BI REST endpoints. The code below is the result of trial and error without guidance from the official documentation.

💡Configure your deployment to have report deployment idempotency
Release, behind the scenes
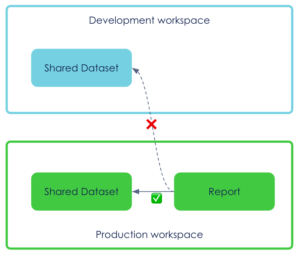
In the following scenario, we want to deploy the same report in two different workspaces using dedicated credentials from the pipeline.
Remember: the dataset ID is hard coded in the report.
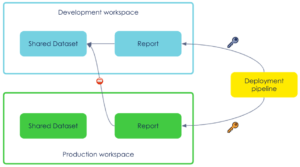
So the green report is linked to the blue dataset but the credentials used to deploy in the green workspace have no permission on the blue workspace (nor should it have any).
Option 1 : make an API call to “rebind” the green report to the green dataset post deployment, leaving a hole in our workspace segregation. The shared dataset must ensure backwards compatibility.
Option 2 : start The Clone Wars 🤖🤖🤖
Apply a clone operation between workspaces, creating a copy of the report AND the dataset in the target workspace.
Adding a cleanup process to avoid dataset duplication and old versions of reports.
The update process will be different from the create process complexifying the pipeline.
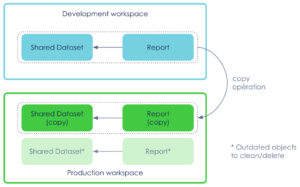
In both cases,
- the production credentials need to have permissions on the development workspace (blue)
- production deployment requires the development workspace to be available
We went with the first option to keep it simple : a single operation is required post deployment (vs clean old report and rebinding other reports to the new shared dataset).
Other existing solutions
Community Extensions
Aside from the method we chose, there are some third party extensions available in the Azure Marketplace that use the PowerShell modules to interact with Power BI Service. The 2 most popular extensions, Macaw and Actions, allow to control Power BI deployment. Both extensions are covering the same perimeter easing the work with Azure pipelines. Actions covers a broader range of possibilities to interact with Power BI.
The table below highlights the different tasks that can be performed by these extensions.
| Tasks | Macaw | __Ac__tions |
| Create or Update Power BI workspace | yes | yes |
| Delete Power BI Workspace | yes | yes |
| Write all workspace info to JSON logfile | yes | no |
| Upload or Update Power BI report | yes | yes |
| Delete Power BI report | yes | no |
| Delete Power BI dataset | yes | no |
| Update the data sources of the specified dataset | yes | no |
| Update the parameters values for the specified dataset | yes | no |
| Update gat__eway__ | no | yes |
| Update a d__atase__t | no | yes |
| __Ce__rtified by Microsoft | Yes | No |
| Last update | Nov. 19 | Dec. 20 |
Please note that these packaged solutions have limitations:
- Only a limited number of tasks are permitted
- At the time of writing this blog post, only the Macaw extension is certified by Microsoft. A security audit might be necessary to comply with your organization
- Only Master account authentications are allowed (username & password) and not SPN (Service Principal)
Leveraging your own PowerShell script will grant you more flexibility during the build & run activities.
The Microsoft Deployment Pipelines
After exploring the solutions using XMLA endpoints to manage and deploy Power BI datasets, we are investigating a functionality released in May 2020: Deployment Pipeline.
In short, this new functionality is a low-code approach enabling to move .pbix files between environments (here, workspaces). How does it work?
- The user will create a development workspace in which the files will be dropped
- Once the development is complete, the user can move the selected files from the development workspace to a test workspace. The operation is done through a click on a button. During this operation, the test workspace is automatically created the first time. Attention, you cannot assign an existing test or production workspace to a pipeline. The user can parameterize a change of server for the data source(s).
- The previous operation can be repeated once more where the selected files will now move from the test workspace to the production workspace. From the production workspace, the user can now update the application by simply clicking on another button
Limitations:
During the implementation of the deployment pipeline, we have noticed two major limitations:
- At the time of this blog post, Microsoft has not yet released an integration with Azure DevOps allowing to integrate the Power BI deployment pipeline in a complete pipeline,
- You cannot assign an existing workspace to the deployment pipeline. Power BI will create a dev workspace into which you will have to move the .pbix files. During the first execution of the pipeline, Power BI will create a test and a production workspace moving the files along the way.
Conclusion
Looking back in the mirror, did we accomplish our goals?
On a technical aspect, we have a bittersweet feeling. Among the two objectives we had (version control and continuous deployment), only the version control has been fully adopted by the Power BI team. Regarding the fully automated continuous deployment using the REST API, we remained at a POC version. With the release of the deployment pipeline by Microsoft, we have decided to leverage this solution in production.
On a cultural aspect, definitely. Cultural change cannot be imposed, cannot be forced nor directly addressed. Cultural transformations are made through practice and the observation of convincing results. We have chosen to focus this blog post on the technical result but these are the fruits of collaboration during workshops and pair programming, acculturation of DevOps/Craft practices. Today, the datavisualization team members act as evangelists in the BI projects they are working on.
What are the lessons learned?
In our opinion, the maturity of Power BI and, more generally, the maturity of packaged tools is the central element of what we have learned.
The maturity is changing rapidly. Implementing a state of art continuous deployment at the time of this project (end of 2020) was not possible. However, Microsoft has upgraded the Power BI REST API in June 2021 allowing the integration of the deployment pipeline with Azure DevOps.
Many data visualization tools were born before the emergence of DevOps, which explains the need to upgrade development practices (from both the software editors and the developers).
It’s only a matter of time before the tools are adjusted and the practices are widespread within the teams. In the meantime, ask yourself : how much do I want to invest in tool customization to implement DevOps practices ?